







Improving the transferability of adversarial examples via direction tuning
本文 “Improving the Transferability of Adversarial Examples via Direction Tuning” 针对当前基于迁移的对抗攻击中对抗样本可迁移性不佳的问题,提出方向调整攻击(DTA)和网络剪枝方法,有效提升了对抗样本的可迁移性,为对抗攻击与防御研究提供了新方向。
摘要-Abstract
In the transfer-based adversarial attacks, adversarial examples are only generated by the surrogate models and achieve effective perturbation in the victim models. Although considerable efforts have been developed on improving the transferability of adversarial examples generated by transfer-based adversarial attacks, our investigation found that, the big convergence speed deviation along the actual and steepest update directions of the current transfer-based adversarial attacks is caused by the large update step length, resulting in the generated adversarial examples can not converge well. However, directly reducing the update step length will lead to serious update oscillation so that the generated adversarial examples also can not achieve great transferability to the victim models. To address these issues, a novel transfer-based attack, namely direction tuning attack, is proposed to not only decrease the angle between the actual and steepest update directions in the large step length, but also mitigate the update oscillation in the small sampling step length, thereby making the generated adversarial examples converge well to achieve great transferability on victim models. Specifically, in our direction tuning attack, we first update the adversarial examples using the large step length, which is aligned with the previous transfer-based attacks. In addition, in each large step length of the update, multiple examples sampled by using a small step length. The average gradient of these sampled examples is then used to reduce the angle between the actual and steepest update directions, as well as mitigates the update oscillation by eliminating the oscillating component. By doing so, our direction tuning attack can achieve better convergence and enhance the transferability of the generated adversarial examples. In addition, a network pruning method is proposed to smooth the decision boundary, thereby further decreasing the update oscillation and enhancing the transferability of the generated adversarial examples. The experiment results on ImageNet demonstrate that the average attack success rate (ASR) of the adversarial examples generated by our method can be improved from 87.9% to 94.5% on five victim models without defenses, and from 69.1% to 76.2% on eight advanced defense methods, in comparison with that of latest gradient-based attacks.
在基于迁移的对抗攻击中,对抗样本仅由替代模型生成,并在目标模型中实现有效扰动。尽管在提高基于迁移的对抗攻击所生成对抗样本的可迁移性方面已经做出了大量努力,但我们的研究发现,当前基于迁移的对抗攻击在实际更新方向和最速更新方向上存在较大的收敛速度偏差,这是由较大的更新步长导致的,从而使得生成的对抗样本无法很好地收敛。然而,直接减小更新步长会导致严重的更新振荡,使得生成的对抗样本对目标模型也无法实现很高的可迁移性。
为了解决这些问题,我们提出了一种新的基于迁移的攻击方法——方向调整攻击(direction tuning attack)。该方法不仅能在大步长情况下减小实际更新方向和最速更新方向之间的夹角,还能在小采样步长时减轻更新振荡,从而使生成的对抗样本能够很好地收敛,在目标模型上实现较高的可迁移性。具体来说,在我们的方向调整攻击中,我们首先使用大步长更新对抗样本,这与之前的基于迁移的攻击方法一致。此外,在每次大步长更新中,我们使用小步长采样多个样本。然后,利用这些采样样本的平均梯度来减小实际更新方向和最速更新方向之间的夹角,并通过消除振荡分量来减轻更新振荡。通过这种方式,我们的方向调整攻击能够实现更好的收敛效果,并提高生成的对抗样本的可迁移性。
此外,我们还提出了一种网络剪枝方法,用于平滑决策边界,从而进一步减小更新振荡,提高生成的对抗样本的可迁移性。在ImageNet上的实验结果表明,与最新的基于梯度的攻击方法相比,我们的方法生成的对抗样本在五个无防御的目标模型上的平均攻击成功率(ASR)可以从87.9% 提高到94.5%,在八种先进防御方法上的平均攻击成功率可以从69.1% 提高到76.2%.
引言-Introduction
这部分主要介绍了研究背景、现有问题以及研究内容与贡献,具体如下:
- 研究背景:深度神经网络(DNN)的线性特性使其对未知扰动敏感,威胁基于DNN的关键应用。基于迁移的对抗攻击通过在无需目标模型知识的情况下生成对抗样本,可提升训练模型的鲁棒性,增强相关应用的可靠性,其中提高对抗样本的可迁移性至关重要。目前基于迁移的攻击可分为梯度基攻击、输入变换方法、特征重要性感知攻击、模型特定攻击和模型多样化方法,对梯度基攻击的研究对提升基于迁移攻击的效率很关键。
- 现有问题:当前梯度基攻击方法(如I-FGSM、MI-FGSM等)存在更新步长过大的问题,导致实际更新方向与最速更新方向的收敛速度偏差大,使生成的对抗样本无法很好地收敛,可迁移性差。而直接减小步长会引发严重的更新振荡,同样降低对抗样本的可迁移性,如MI-FGSM和NI-FGSM攻击在减小步长时,攻击成功率下降。
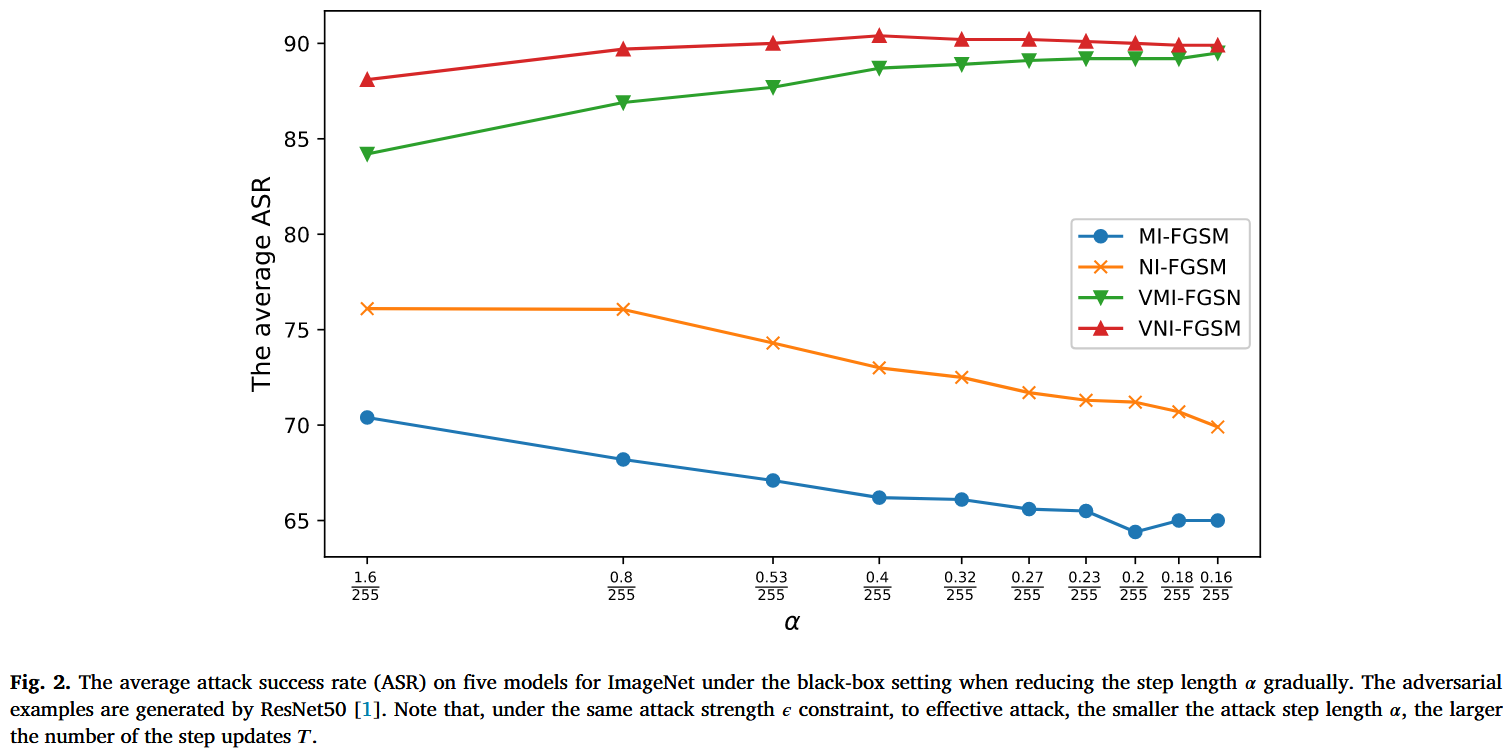
图2. 在黑盒设置下,逐步减小步长α时,ImageNet数据集上五个模型的平均攻击成功率(ASR)。对抗样本由ResNet50生成。请注意,在相同的攻击强度 ϵ ϵ ϵ 约束下,为实现有效攻击,攻击步长 α α α 越小,步长更新次数 T T T 越大 。 - 研究内容与贡献:提出方向调整攻击(direction tuning attack),在大更新步长中嵌入小采样步长,减少实际方向与最速方向的夹角,减轻更新振荡,提高对抗样本的可迁移性;提出网络剪枝方法,通过修剪冗余或不重要神经元平滑决策边界,进一步减少更新振荡,增强对抗样本可迁移性;经ImageNet实验验证,与最新梯度基攻击相比,所提方法生成的对抗样本在无防御的五个目标模型上,平均攻击成功率(ASR)从87.9%提升到94.5%,在八种先进防御方法上从69.1%提升到76.2%。当与其他攻击方法结合时,平均ASR可从95.4%提升到97.8%。

图1. 最新基于梯度的攻击方法与我们的方法之间的对比。对抗样本由ResNet50生成。第四列表示方向调优攻击与网络剪枝方法相结合所生成的对抗样本。
相关工作-Related Work
这部分内容主要介绍了可迁移对抗攻击和对抗防御两方面的相关工作,具体如下:
- 可迁移对抗攻击
- 攻击方法分类:可分为五类。基于梯度攻击(如MI-FGSM、NI-FGSM、VMI-FGSM和VNI-FGSM等)从优化方法角度稳定梯度方向提升对抗样本可迁移性;特征重要性感知攻击(如FIA、NAA)通过破坏DNN中间特征改善可迁移性;输入变换方法(如DIM、TIM、SIM、Admix)利用数据增强避免对抗样本陷入不良局部最优;模型特定攻击(如SGM、LinBP)针对模型架构特点生成高可迁移性对抗样本;模型多样化方法(如MB、大几何邻域方法)通过微调预训练替代模型收集多样模型来提升可迁移性。
- 其他相关方法:反向对抗扰动(RAP)将基于迁移的攻击视为min-max问题寻找平坦最小点;Self-Ensemble和Token Refinement用于增强视觉Transformer的对抗可迁移性;Dynamic cues用于增强从基于视觉Transformer的图像模型到视频模型的对抗可迁移性。
- 本文方法与现有方法差异:本文的方向调整攻击在每次更新迭代中增加内循环采样模块,用小步长采样 K K K 个样本的平均梯度更新对抗样本,有效提高梯度对齐程度,增强可迁移性,且该方法可与其他类型基于迁移的攻击方法结合进一步提升效果。
- 对抗防御:对抗训练是最有效的防御方法,通过用生成的对抗样本优化网络参数提高DNN鲁棒性,但会大幅降低自然准确率。输入处理是另一类防御方法,包括输入变换和输入净化,在不改变DNN参数的情况下使不可感知的扰动无效。为验证本文方法对对抗防御的强可迁移性,实验中选择先进防御方法进行评估。
预备知识-Preliminaries
表 1
符号说明

该部分主要介绍了对抗攻击的相关定义、基于梯度的攻击方法以及特征重要性感知攻击,为后续理解文章提出的新方法做铺垫:
- 对抗攻击的定义:对抗攻击旨在基于干净样本 x x x 生成对抗样本 x a d v x^{adv} xadv,需满足 ∥ x − x a d v ∥ p < ϵ \left\|x - x^{adv}\right\|_{p}<\epsilon x−xadv p<ϵ,且 x a d v x^{adv} xadv 能误导分类器 f f f 的预测,即 f ( x ; θ ) ≠ f ( x a d v ; θ ) f(x ; \theta) ≠ f(x^{adv} ; \theta) f(x;θ)=f(xadv;θ)。其中 f ( x ; θ ) f(x ; \theta) f(x;θ) 表示基于DNN的分类器, L ( x , y ; θ ) L(x, y ; \theta) L(x,y;θ) 是其损失函数, ϵ \epsilon ϵ 和 ∥ ⋅ ∥ p \|\cdot\|_{p} ∥⋅∥p 分别代表攻击强度和 p p p - 范数距离,本文设定 p = ∞ p=\infty p=∞ 。
- 基于梯度的攻击方法
- FGSM:是最早有效的基于梯度的攻击方法,通过一步更新最大化损失 L ( x a d v , y ; θ ) L(x^{adv}, y ; \theta) L(xadv,y;θ),公式为 x a d v = x + ϵ ⋅ s i g n ( ∇ x L ( x , y ; θ ) ) x^{adv}=x+\epsilon \cdot sign\left(\nabla_{x} L(x, y ; \theta)\right) xadv=x+ϵ⋅sign(∇xL(x,y;θ))。
- I - FGSM:是FGSM的迭代版本,在每次更新中使用小步长进一步最大化损失函数,公式为 x t + 1 a d v = C l i p x ϵ { x t a d v + α ⋅ s i g n ( ∇ x t a d v L ( x t a d v , y ; θ ) ) } x_{t + 1}^{adv}=Clip_{x}^{\epsilon }\{ x_{t}^{adv}+\alpha \cdot sign(\nabla _{x_{t}^{adv}}L(x_{t}^{adv},y;\theta ))\} xt+1adv=Clipxϵ{xtadv+α⋅sign(∇xtadvL(xtadv,y;θ))}。
- MI - FGSM:在I - FGSM基础上引入动量,避免在生成对抗样本时陷入不良局部最优,涉及公式 g t + 1 = μ 1 ⋅ g t + ∇ x t a d v L ( x t a d v , y ; θ ) ∥ ∇ x t a d v L ( x t a d v , y ; θ ) ∥ 1 g_{t + 1}=\mu_{1} \cdot g_{t}+\frac{\nabla_{x_{t}^{adv}} L\left(x_{t}^{adv}, y ; \theta\right)}{\left\| \nabla_{x_{t}^{adv}} L\left(x_{t}^{adv}, y ; \theta\right)\right\| _{1}} gt+1=μ1⋅gt+ ∇xtadvL(xtadv,y;θ) 1∇xtadvL(xtadv,y;θ) 和 x t + 1 a d v = C l i p x ϵ { x t a d v + α ⋅ s i g n ( g t + 1 ) } x_{t + 1}^{adv}=Clip_{x}^{\epsilon }\{ x_{t}^{adv}+\alpha \cdot sign\left(g_{t + 1}\right)\} xt+1adv=Clipxϵ{xtadv+α⋅sign(gt+1)}。
- NI - FGSM:在MI - FGSM基础上添加前瞻操作,进一步避免对抗样本陷入不良局部最优,计算前瞻对抗样本 x t n e s = x t a d v + α ⋅ μ 1 ⋅ g t x_{t}^{nes}=x_{t}^{adv}+\alpha \cdot \mu_{1} \cdot g_{t} xtnes=xtadv+α⋅μ1⋅gt,并在计算梯度时进行相应替换。
- VMI - FGSM和VNI - FGSM:分别在MI - FGSM和NI - FGSM基础上添加方差调整,稳定梯度方向以减少更新振荡,VMI - FGSM中梯度 g t + 1 g_{t + 1} gt+1 的计算会加入方差 v t v_{t} vt ,VNI - FGSM则在此基础上结合了NI - FGSM的前瞻操作特点。
- 特征重要性感知攻击(FIA):由于DNN最后几层存在过拟合,FIA通过破坏中间特征来提高生成的对抗样本的可迁移性。它可被视为一种基于梯度的攻击,只是损失函数替换为 L F I A ( x , y ; θ ) = ∑ ( Δ ⊙ f i ( x ; θ ) ) L_{FIA}(x, y ; \theta)=\sum\left(\Delta \odot f_{i}(x ; \theta)\right) LFIA(x,y;θ)=∑(Δ⊙fi(x;θ)),通过最小化该损失函数生成对抗样本。
我们的方法-Our Approach
该部分主要阐述了研究方法的动机、方向调整攻击以及网络剪枝方法,具体如下:
- 动机:在基于迁移的对抗攻击中,小步长更新易使对抗样本陷入不良局部最优,如MI-FGSM和NI-FGSM攻击在减小步长时攻击成功率下降;而大步长更新虽能避免局部最优,但会导致实际与最速更新方向的收敛速度偏差大,影响对抗样本收敛和可迁移性。基于此,研究思考如何利用小步长提升对抗样本可迁移性。通过定义最速收敛速度和收敛速度偏差,并证明定理1(当 α 2 > α 1 \alpha_{2}>\alpha_{1} α2>α1 时, V x α 2 − ∥ ∇ x L ( x , y ; θ ) ∥ 2 ≥ V x α 1 − ∥ ∇ x L ( x , y ; θ ) ∥ 2 ≥ 0 V_{x}^{\alpha_{2}}-\left\|\nabla_{x} L(x, y ; \theta)\right\|_{2} ≥V_{x}^{\alpha_{1}}-\left\|\nabla_{x} L(x, y ; \theta)\right\|_{2} \geq0 Vxα2−∥∇xL(x,y;θ)∥2≥Vxα1−∥∇xL(x,y;θ)∥2≥0),明确了大步长会增大收敛速度偏差。为解决该问题,提出方向调整攻击和网络剪枝方法。
- 方向调整攻击
- 基本思想:在当前基于迁移的攻击中,大步长导致实际与最速更新方向偏差大。方向调整攻击(DTA)通过在每次更新中添加内循环,在大步长更新中嵌入多个小采样步长。利用小步长采样多个样本,用这些样本的平均梯度进行对抗样本更新,以减小实际与最速更新方向夹角,减轻更新振荡。此外,将方差调整集成到DTA中得到VDTA,改变了梯度计算方式,进一步稳定更新方向。

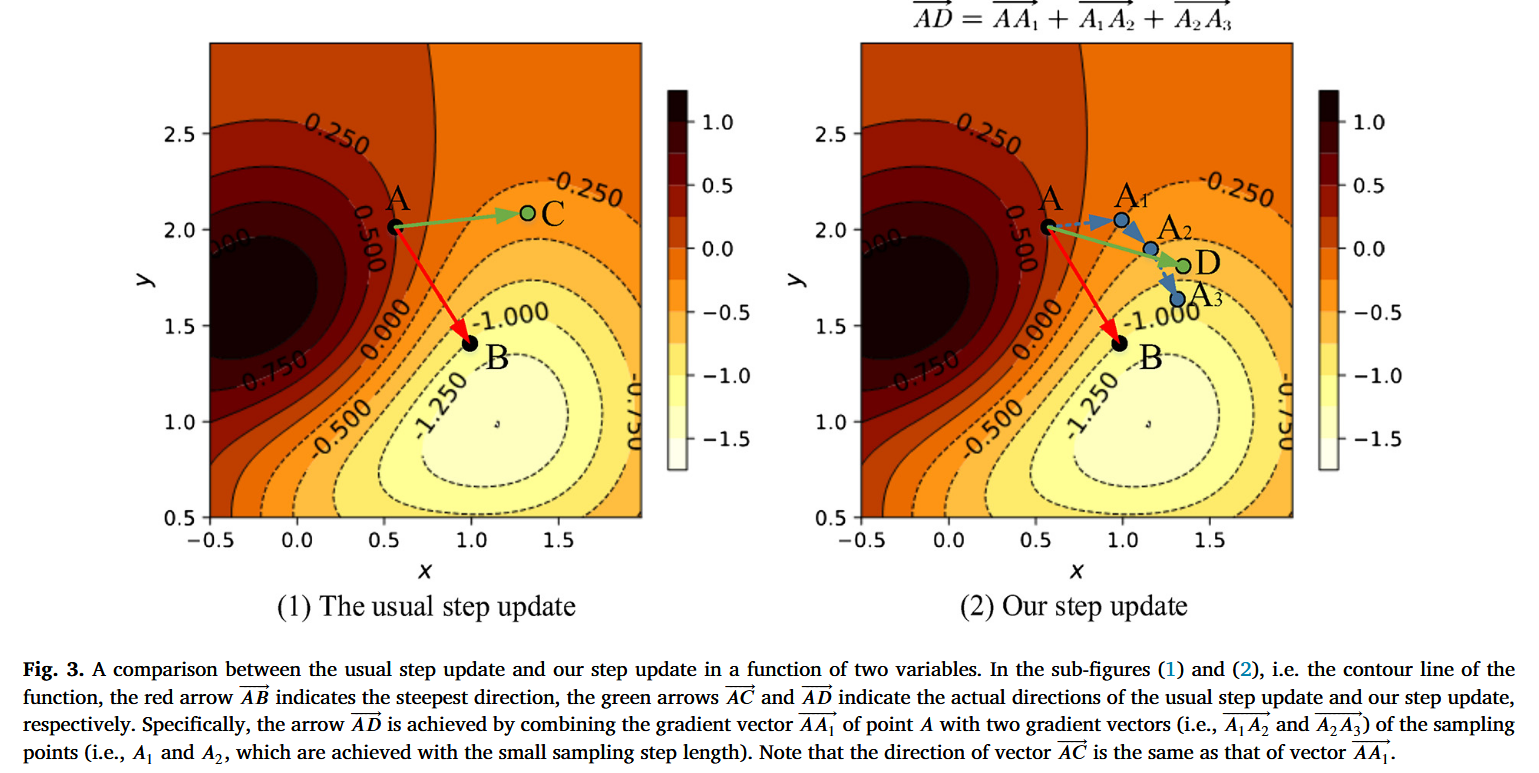
图3. 双变量函数中常规步长更新与我们所采用步长更新的对比。在子图(1)和(2)中,即函数的等高线图里,红色箭头AB表示最陡方向,绿色箭头 A C → \overrightarrow{AC} AC 和 A D → \overrightarrow{AD} AD 分别表示常规步长更新和我们所采用步长更新的实际方向。具体而言,箭头 A D → \overrightarrow{AD} AD 是通过将点A的梯度向量 A A 1 ‾ \overline{AA_{1}} AA1 与采样点(即通过小采样步长得到的 A 1 A_{1} A1 和 A 2 A_{2} A2)的两个梯度向量(即 A 1 A 2 ‾ \overline{A_{1}A_{2}} A1A2 和 A 2 A 3 ‾ \overline{A_{2}A_{3}} A2A3)相结合而得到的。请注意,向量 A C ‾ \overline{AC} AC 的方向与向量 A A 1 ‾ \overline{AA_{1}} AA1 的方向相同。 - 效果分析:通过对比不同攻击在ImageNet上实际与最速梯度方向夹角的余弦值,结果表明DTA能显著减小该夹角,VDTA的余弦值更高,且夹角余弦值越高,攻击成功率越高。同时,从数学角度分析了DTA的准确更新方向和振荡减少特性,其更新公式既能保证类似小步长更新的准确方向,又能通过减轻振荡保持足够的移动距离。
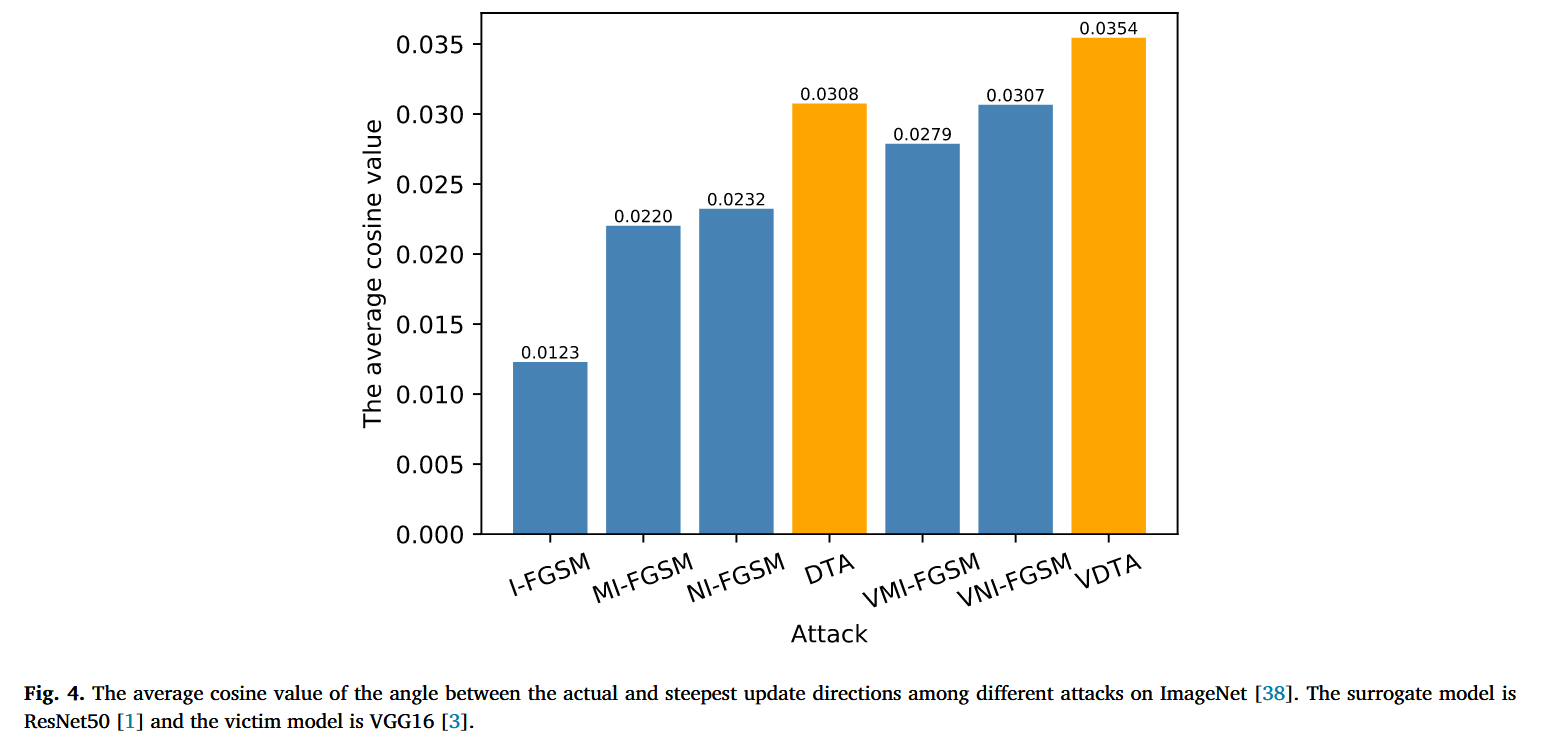
图4. ImageNet数据集上不同攻击方式中,实际更新方向与最陡更新方向之间夹角的平均余弦值。替代模型为ResNet50,目标模型为VGG16。
- 基本思想:在当前基于迁移的攻击中,大步长导致实际与最速更新方向偏差大。方向调整攻击(DTA)通过在每次更新中添加内循环,在大步长更新中嵌入多个小采样步长。利用小步长采样多个样本,用这些样本的平均梯度进行对抗样本更新,以减小实际与最速更新方向夹角,减轻更新振荡。此外,将方差调整集成到DTA中得到VDTA,改变了梯度计算方式,进一步稳定更新方向。
- 网络剪枝方法
- 基本思想:网络剪枝可压缩神经网络并维持性能,研究发现其还能增强对抗样本可迁移性。该方法通过修剪DNN中冗余或不重要的神经元,平滑决策边界,从而提升对抗样本可迁移性。通过引入评估指标 I i , j I_{i, j} Ii,j 来衡量神经元重要性,为节省计算时间,利用反向梯度通过一次前馈估计所有神经元的重要性,且仅对DNN的最后一个特征层进行修剪。
- 效果分析:选择最后一个特征层修剪,是因为其分类精度高,特征相关性小,修剪后不影响正确分类,还能简化分类边界,进一步减小生成对抗样本时的更新振荡,增强对抗样本可迁移性。
实验-Experiments
该部分通过在ImageNet数据集上进行实验,验证了方向调整攻击和网络剪枝方法的有效性,具体内容如下:
-
实验设置
- 数据集:从ImageNet验证集中随机选取1000张干净图像,这些图像能被所有测试模型正确分类。
- 模型:使用6个自然训练模型(VGG16/19、ResNet50/152、MobileNet-v2、Inception-v3)作为测试模型,其中VGG16和ResNet50作为替代模型;还使用8个先进防御模型评估攻击方法的可迁移性。
- 基线:选取5种基于梯度的攻击方法(I-FGSM、MI-FGSM、NI-FGSM、VM(N)I-FGSM )作为基线,同时将本文方法与特征重要性感知攻击(FIA)、多种输入变换方法(DIM、SIM、TIM)、SGM和More Bayesian(MB)结合,评估兼容性。
- 指标:以黑盒设置下多个目标模型上的平均攻击成功率(ASR)衡量攻击的可迁移性。
- 超参数:设置最大扰动 ϵ = 16 / 255 \epsilon=16 / 255 ϵ=16/255、迭代次数 T = 10 T = 10 T=10、步长 α = 1.6 / 255 \alpha = 1.6 / 255 α=1.6/255 等超参数,其他方法也设置相应超参数。
-
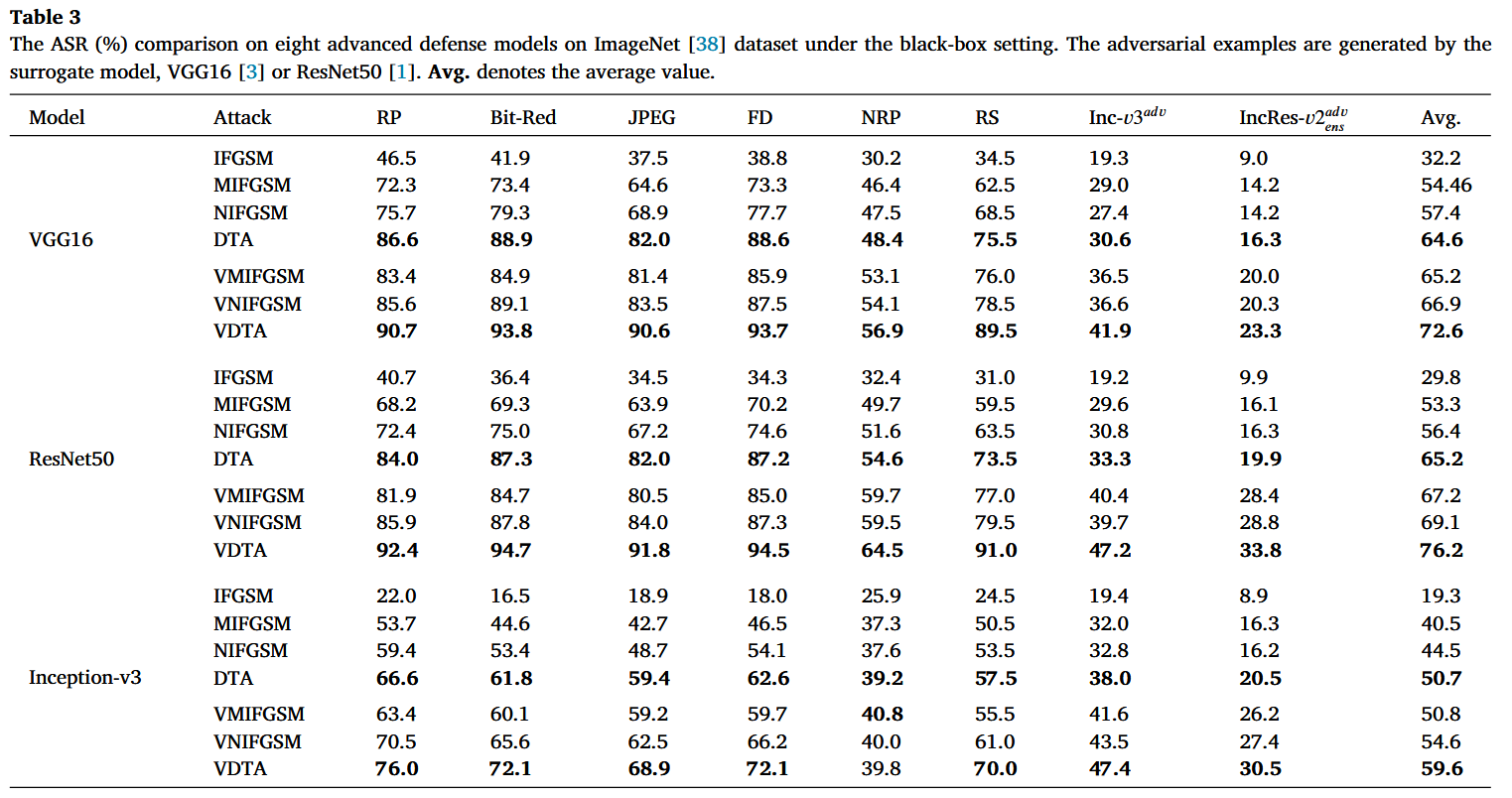
方向调整攻击的可迁移性:以VGG16、ResNet50和Inception-v3为替代模型生成对抗样本,攻击6个自然训练的目标模型和8个先进防御模型。结果显示,DTA在所有目标模型上的ASR显著高于I-FGSM及其变体;VDTA在集成方差调整后,平均ASR比其他攻击更高。这表明本文方法对先进防御模型有很好的泛化能力。
表2
ImageNet数据集上六个模型的攻击成功率(ASR,%)对比。对抗样本由替代模型VGG16或ResNet50制作。 ∗ ∗ ∗ 表示白盒设置下的攻击成功率。“Average”指除 ∗ ∗ ∗ 之外的平均值。
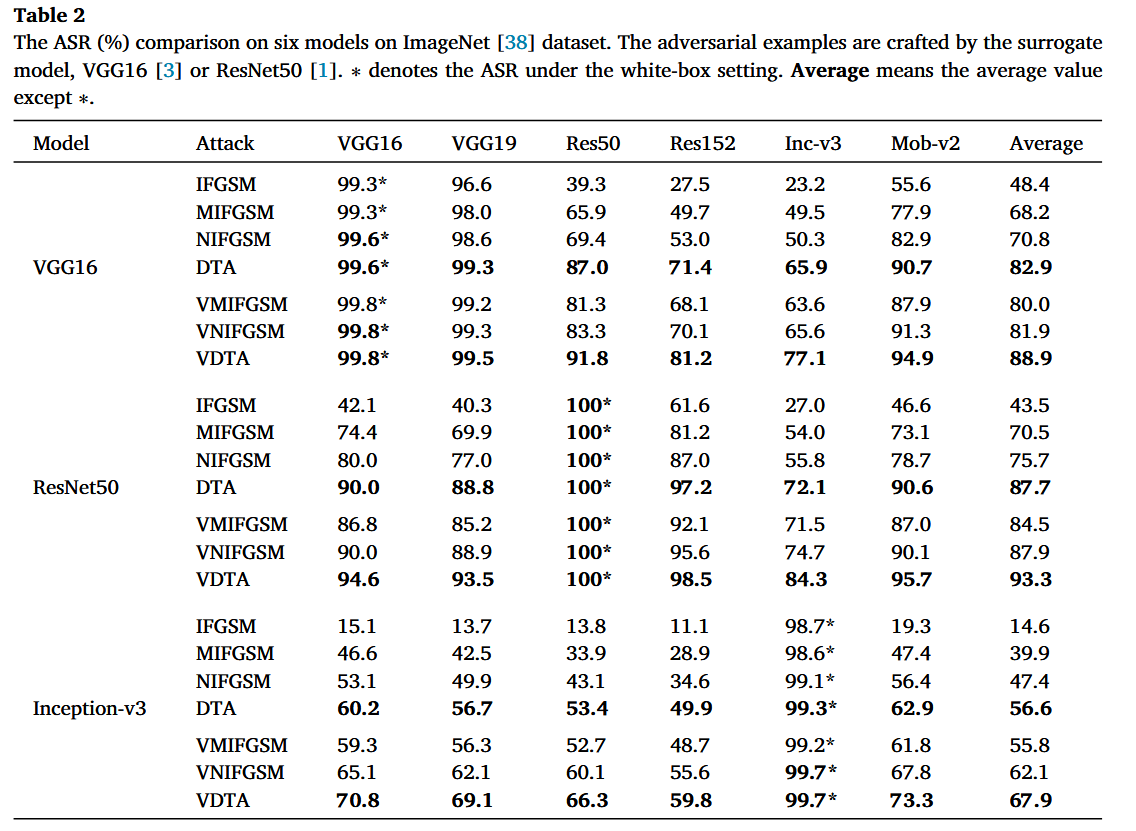
表3
在ImageNet数据集上,黑盒设置下针对8种先进防御模型的攻击成功率(ASR,%)对比。对抗样本由替代模型VGG16或ResNet50生成。“Avg.” 表示平均值。
-
网络剪枝方法的有效性:探究网络剪枝方法对DTA和VDTA的影响,结果表明使用网络剪枝方法后,DTA和VDTA在黑盒设置下的平均ASR分别进一步提高了1.6%和1.2%,证明了网络剪枝方法能增强对抗样本的可迁移性。
表4
ImageNet数据集上六个模型在使用或不使用网络剪枝方法时的攻击成功率(ASR,%)对比。对抗样本由替代模型ResNet50生成。 ∗ * ∗ 表示白盒设置下的攻击成功率。“Average”表示除 ∗ * ∗ 之外的平均值。

-
方法的兼容性:将本文方法与其他攻击方法结合实验,结果表明:与FIA结合时,DTA和VDTA能助力FIA取得最高ASR,且DTA计算梯度次数更少,耗时更短;与输入变换方法结合时,方向调整攻击与各方法兼容性良好,网络剪枝方法可进一步提升对抗样本可迁移性,部分组合还具有高可迁移性和低耗时的优势;与SGM结合时,本文方法兼容性更好,能提升平均ASR,不过网络剪枝方法在与VDTA结合时可能因过度修剪无法提升可迁移性;与MB结合时,DTA可有效将MB的可迁移性从94.8%提升到97.7%,而NI-FGSM会降低MB的可迁移性。
表5
在ImageNet数据集的六个模型上,使用特征重要性感知攻击(FIA)损失而非交叉熵损失时的攻击成功率(ASR,%)对比。对抗样本由替代模型ResNet50生成。 ∗ * ∗ 表示白盒设置下的攻击成功率。“Average”表示除 ∗ * ∗ 之外的平均值。

表6
ImageNet数据集上六个模型的攻击成功率(ASR,%)对比。基于梯度的攻击分别由多样化输入方法(DIM)、尺度不变方法(SIM)和变换不变方法(TIM)增强。对抗样本由替代模型ResNet50生成。 ∗ * ∗表示白盒设置下的攻击成功率。“Avg.” 表示除 ∗ * ∗ 之外的平均值。
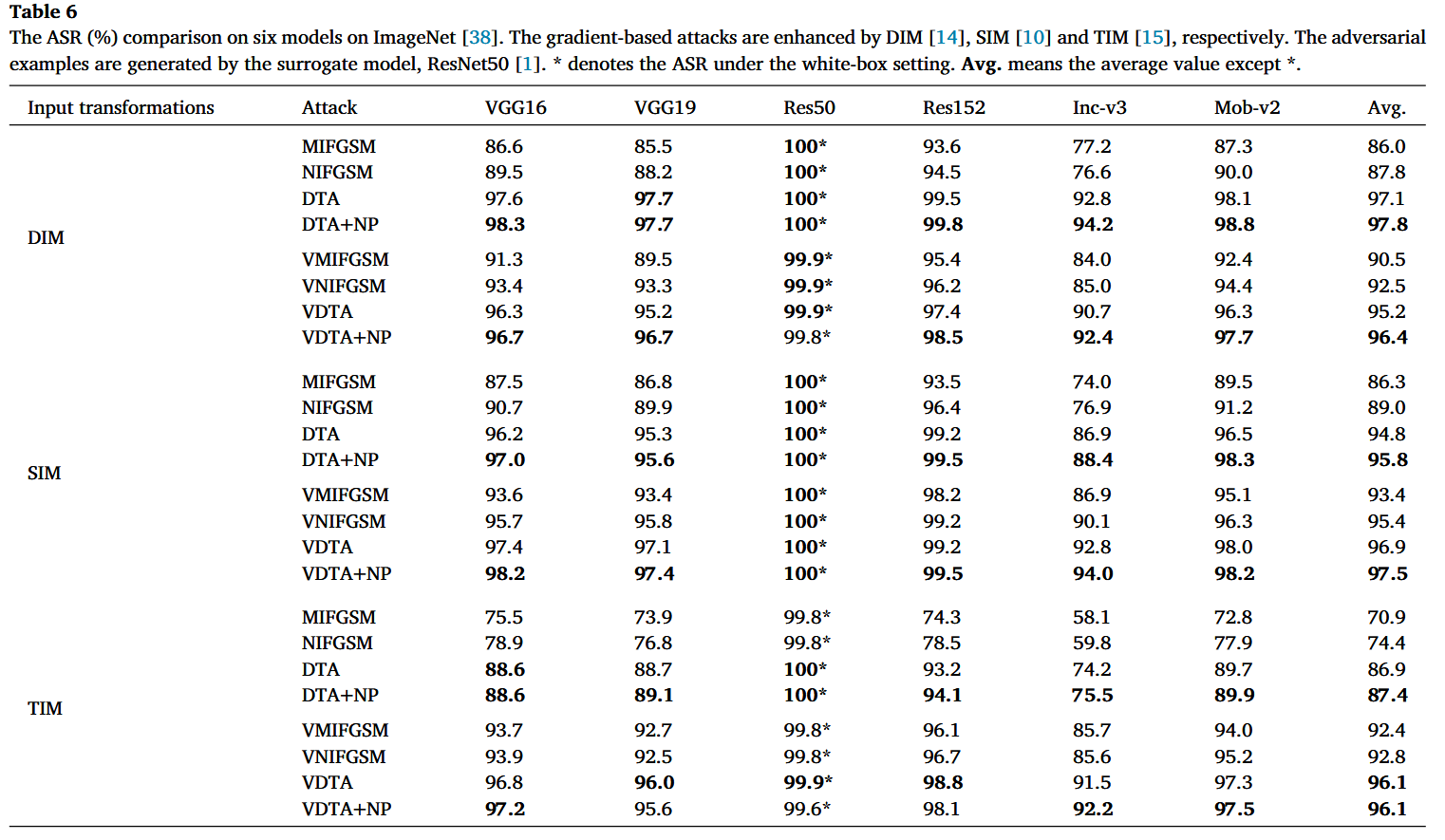
表7
ImageNet数据集上六个模型的攻击成功率(ASR,%)对比。基于梯度的攻击分别通过SGM进行了增强。对抗样本由替代模型ResNet50生成。 ∗ * ∗ 表示白盒设置下的攻击成功率。“Average”指除 ∗ * ∗ 之外的平均值。
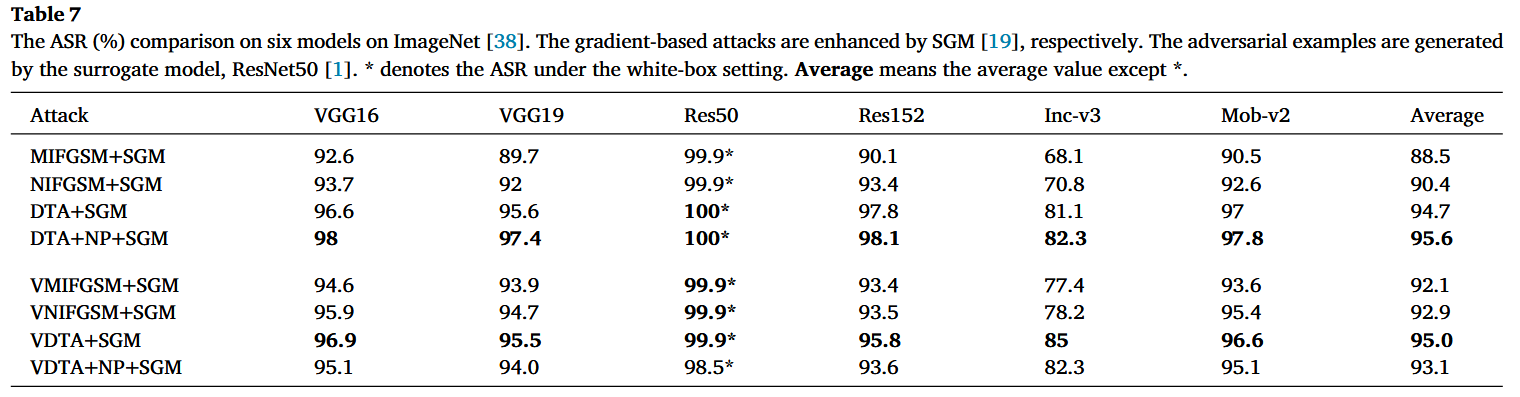
表8
ImageNet上六个模型的攻击成功率(ASR,%)对比。基于梯度的攻击分别通过更多贝叶斯方法(MB)进行增强。对抗样本由替代模型ResNet50生成。 ∗ * ∗ 表示白盒设置下的ASR。“Average”表示除 ∗ * ∗ 之外的平均值。

-
敏感性分析:分析方向调整攻击中参数K和 μ 2 \mu_{2} μ2、网络剪枝方法中参数 γ \gamma γ 对平均ASR的影响。结果显示,DTA和VDTA在大多数 K K K 和 μ 2 \mu_{2} μ2 组合下可迁移性高于NI-FGSM和VNI-FGSM,且随着 K K K 增大可迁移性增强,结合适度的 μ 2 \mu_{2} μ2 可达到最佳效果;网络剪枝方法中,当 γ ∈ [ 0 , 0.9 ] \gamma \in[0,0.9] γ∈[0,0.9] 时,平均ASR随 γ \gamma γ 增大而上升,最终确定DTA中 K = 10 K = 10 K=10、 μ 2 = 0.0 \mu_{2}=0.0 μ2=0.0,VDTA中 K = 10 K = 10 K=10、 μ 2 = 0.8 \mu_{2}=0.8 μ2=0.8,网络剪枝方法中 γ = 0.9 \gamma = 0.9 γ=0.9.
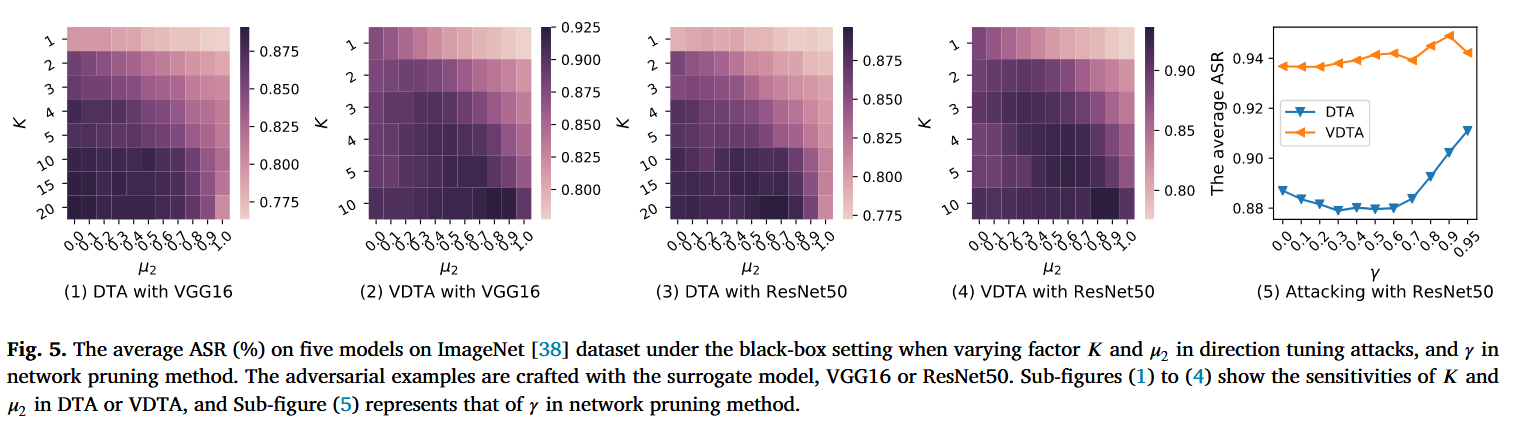
图5. 在基于迁移的攻击中,改变方向调整攻击中的因子 K K K 和 μ 2 \mu_{2} μ2 以及网络剪枝方法中的 γ \gamma γ 时,ImageNet数据集上五个模型在黑盒设置下的平均攻击成功率(ASR,%)。对抗样本由替代模型VGG16或ResNet50生成。子图(1)至(4)展示了DTA或VDTA对 K K K 和 μ 2 \mu_{2} μ2 的敏感性,子图(5)展示了网络剪枝方法中 γ \gamma γ 的敏感性。 -
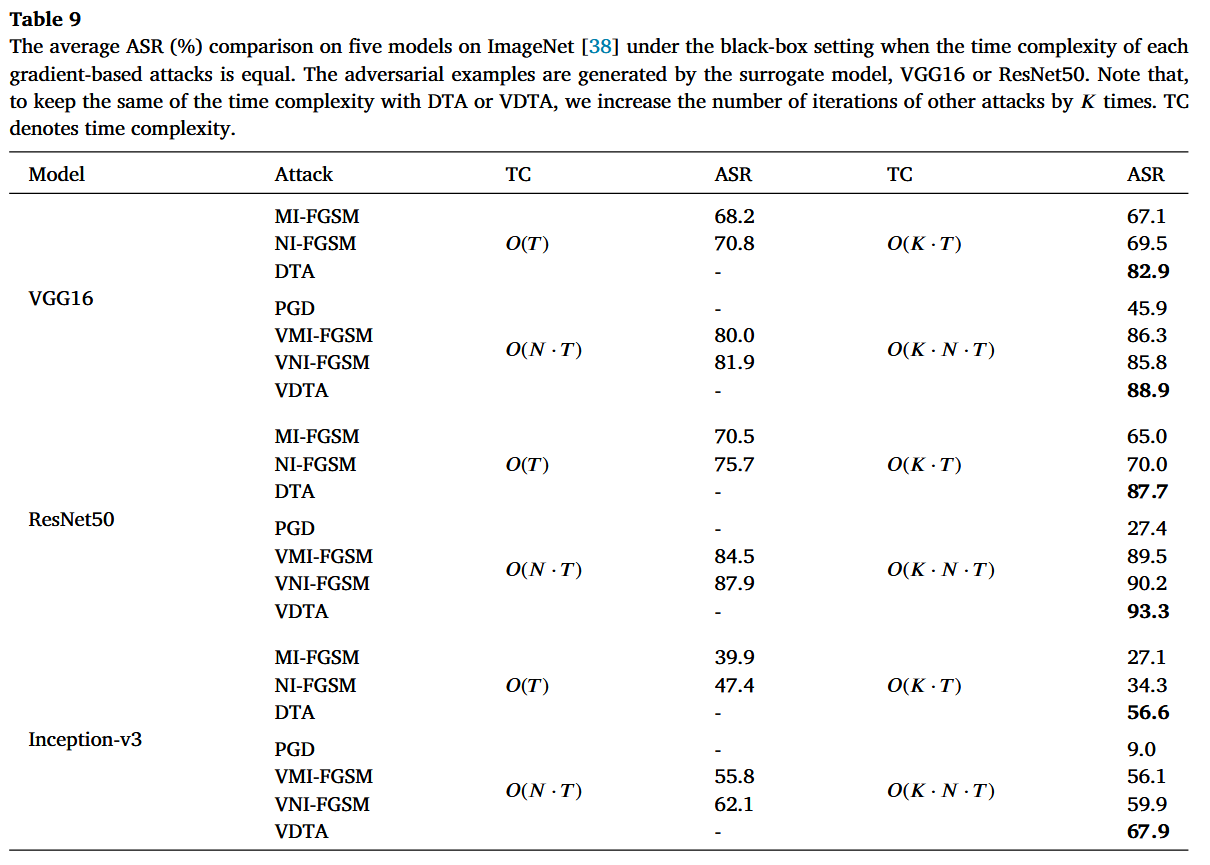
时间复杂度分析:DTA和VDTA的时间复杂度分别为 O ( K ⋅ T ) O(K \cdot T) O(K⋅T) 和 O ( K ⋅ N ⋅ T ) O(K \cdot N \cdot T) O(K⋅N⋅T),高于部分现有攻击。但在相同时间复杂度下,VDTA的可迁移性显著更高,其计算成本可接受。
表9
在ImageNet上的五个模型上,当每种基于梯度的攻击的时间复杂度相同时,黑盒设置下的平均攻击成功率(ASR,%)对比。对抗样本由替代模型VGG16或ResNet50生成。请注意,为了使其他攻击的时间复杂度与DTA或VDTA相同,我们将其他攻击的迭代次数增加 K K K 倍。TC表示时间复杂度。
结论-Conclusion
在结论部分,作者总结了研究成果、方法效果、兼容性及研究意义,具体如下:
- 研究成果:提出方向调整攻击和网络剪枝方法来提升对抗样本的可迁移性。方向调整攻击通过在大更新步长中嵌入小采样步长,减小实际与最速更新方向夹角并降低更新振荡;网络剪枝方法通过稳定更新方向、平滑分类边界,进一步消除更新振荡。
- 方法效果:在ImageNet数据集上的扩展实验表明,所提方法能显著提升对抗样本在有防御和无防御场景下的可迁移性。与最新的基于梯度的攻击相比,使用本文方法生成的对抗样本在五个无防御的目标模型上,平均攻击成功率(ASR)从87.9%提升到94.5%;在八个先进防御方法上,平均ASR从69.1%提升到76.2%。
- 兼容性:实验结果显示该方法与其他类型的攻击具有良好的兼容性,结合使用时能够进一步提高对抗样本的可迁移性。例如,当与多种输入变换、特征重要性感知攻击、模型特定攻击和模型多样化方法结合时,生成的对抗样本平均ASR可从95.4%提升到97.8%。
- 研究意义:本文方法通过合理增加时间消耗实现了良好的可迁移性,这为对抗防御领域设计更强大的防御方法提供了有益参考,有助于对抗防御社区针对强可迁移性攻击设计出更具鲁棒性的防御策略。


















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











