






Boosting Adversarial Transferability across Model Genus by Deformation-Constrained Warping
本文 “Boosting Adversarial Transferability across Model Genus by Deformation-Constrained Warping” 提出变形约束扭曲攻击(DeCoWA)策略,通过对输入样本进行约束弹性变形,有效提升跨模型属对抗样本的可迁移性,在多种模态数据攻击任务中取得优异效果。
摘要-Abstract
Adversarial examples generated by a surrogate model typically exhibit limited transferability to unknown target systems. To address this problem, many transferability enhancement approaches (e.g., input transformation and model augmentation) have been proposed. However, they show poor performances in attacking systems having different model genera from the surrogate model. In this paper, we propose a novel and generic attacking strategy, called DeformationConstrained Warping Attack (DeCoWA), that can be effectively applied to cross model genus attack. Specifically, DeCoWA firstly augments input examples via an elastic deformation, namely Deformation-Constrained Warping (DeCoW), to obtain rich local details of the augmented input. To avoid severe distortion of global semantics led by random deformation, DeCoW further constrains the strength and direction of the warping transformation by a novel adaptive control strategy. Extensive experiments demonstrate that the transferable examples crafted by our DeCoWA on CNN surrogates can significantly hinder the performance of Transformers (and vice versa) on various tasks, including image classification, video action recognition, and audio recognition.
由代理模型生成的对抗样本通常对未知目标系统表现出有限的可迁移性。为了解决这个问题,人们提出了许多提高可迁移性的方法(例如,输入变换和模型增强)。然而,在攻击与代理模型属于不同模型属的系统时,这些方法的表现不佳。在本文中,我们提出了一种新颖且通用的攻击策略,称为变形约束扭曲攻击(DeCoWA),它可以有效地应用于跨模型属攻击。具体来说,DeCoWA首先通过一种弹性变形(即变形约束扭曲,DeCoW)来增强输入样本,以获取增强输入的丰富局部细节。为了避免随机变形导致全局语义严重失真,DeCoW通过一种新颖的自适应控制策略进一步约束扭曲变换的强度和方向。大量实验表明,我们的DeCoWA在CNN代理模型上生成的可迁移样本可以显著削弱Transformer在各种任务(包括图像分类、视频动作识别和音频识别)中的性能(反之亦然)。
引言-Introduction
该部分内容从研究背景出发,阐述现有研究不足,通过实验揭示CNN和ViT的差异,进而提出新方法,具体如下:
- 研究背景与挑战:过去十年,深度神经网络在信号识别和分类领域成绩斐然,但都面临对抗样本的安全威胁。目前许多研究致力于生成具有可迁移性的对抗样本以攻击黑箱场景中的目标系统,不过大多集中于CNN架构间或Vision Transformers(ViTs)间的可迁移性提升,缺乏在更广泛实际场景(跨模型属)中实现强可迁移性的有效攻击方法。不同模型属间架构差异大、提取特征不同,使得跨模型属攻击极具挑战性。
- CNN和ViT的差异:通过两个简单实验揭示CNN和ViT在特征依赖上的差异。一是模糊图像局部细节,发现ResNet-50(CNN模型)分类准确率显著下降,而DeiT-B(ViT模型)更具鲁棒性;二是用局部图像特征作为输入,ResNet-50能利用局部细节获得较高准确率。这表明Transformer和CNN模型都主要基于全局特征预测,但CNN模型常过度拟合局部模式。
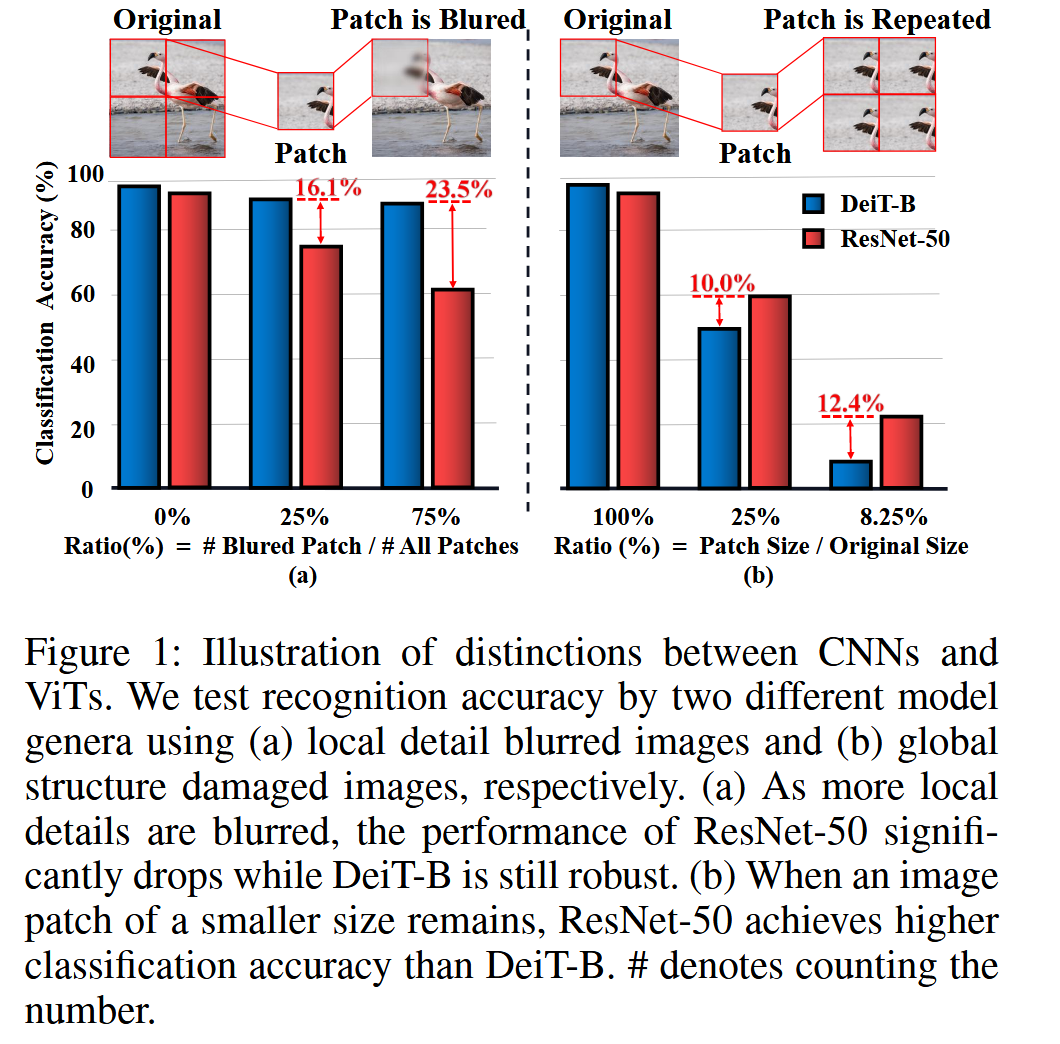
图1:卷积神经网络(CNNs)和视觉Transformer(ViTs)之间差异的示意图。我们分别使用(a)局部细节模糊的图像和(b)全局结构受损的图像,对两种不同模型属的识别准确率进行测试。(a)随着更多局部细节被模糊,ResNet-50的性能显著下降,而DeiT-B仍然表现稳健。(b)当保留较小尺寸的图像补丁时,ResNet-50比DeiT-B实现了更高的分类准确率。“#”表示计数。 - 现有方法的问题:现有提高对抗样本可迁移性的方法,如模型增强,虽能模拟相似架构的决策空间,但因针对特定模型属设计,忽略不同模型属的通用不变特征,在跨模型属攻击中效果不佳。而且以往的变换技术多关注全局内容,忽视局部区域重要性。
- 提出新方法:基于上述分析,从输入变换角度出发,发现弹性变形可调整局部形状和内容,获取更多局部模式和通用特征。因此提出变形约束扭曲(DeCoW)这一输入变换方法,并将其集成到基于梯度的攻击方法中,形成变形约束扭曲攻击(DeCoWA),以提升跨模型属的对抗可迁移性。
相关工作-Related Work
该部分主要从三个方面梳理和分析了已有研究,分别阐述了CNN和Transformer的特性差异、基于变形的数据增强方法以及可迁移对抗攻击在CNN和Transformer模型上的研究进展,为后续提出的方法做了理论和研究基础的铺垫,具体内容如下:
- CNN和Transformer的特性:CNN的卷积层类似高通滤波器,擅长捕捉图像高频分量,对琐碎细节和噪声更敏感;Transformer的多头自注意力机制(MSAs)类似低通滤波器,对物体形状的偏向更强,且层间表示更一致。这些特性差异有助于理解不同模型属对抗迁移性低的问题。
- 基于变形的数据增强:数据增强是提升模型泛化能力的有效手段,像仿射变换、强度变换、混合图像等方法被广泛应用于模型训练。弹性变形能改变物体形状或姿态,也逐渐应用于模型训练中。
- 可迁移对抗攻击
- 针对CNN的可迁移攻击:研究成果丰富,包括基于梯度的增强方法、方差调整方法、基于知识的方法、基于生成模型的方法以及输入增强方法等。例如,MIM利用动量项保持梯度方向,NIM通过Nesterov动量改进,还有从频域等不同角度增强输入的方法。
- 针对Transformer的可迁移攻击:随着ViT的流行,相关研究不断涌现,如提出自集成(SE)和token细化(TR)策略、设计Pay No Attention(PNA)和PatchOut技巧、利用部分编码器块、提出面向架构的可迁移攻击框架(ATA)以及token梯度正则化(TGR)等方法来提升对抗样本在不同ViT模型间的可迁移性。
方法-Methodology
预备知识和通用范式-Preliminary and A Unified Paradigm
该部分为后续研究构建了理论和方法基础,先以图像分类模型为例阐述对抗样本生成的优化问题,再介绍在黑盒场景下借助代理模型生成对抗样本的常见做法,最后给出融入数据变换的统一范式,具体内容如下:
- 对抗样本生成的优化问题:以图像分类模型为示例,设分类器为 M ϕ : x → y M_{\phi}: x \to y Mϕ:x→y, x x x 是干净输入, y y y 是真实标签。目标是生成对抗样本 x a d v = x + δ x^{adv}=x+\delta xadv=x+δ,让分类器做出错误决策,同时限制攻击强度,将 x a d v x^{adv} xadv 约束在以 x x x 为中心、半径为 ϵ \epsilon ϵ 的 ℓ p \ell_{p} ℓp 范数球内,本文采用 ℓ ∞ \ell_{\infty} ℓ∞ 范数球约束。因此,对抗样本的生成可表示为一个优化问题 a r g m a x x a d v L ( M ϕ ( x a d v ) , y ) , s . t . ∥ δ ∥ ∞ ≤ ϵ \underset{x^{adv}}{arg max } \mathcal{L}\left(\mathcal{M}_{\phi}\left(x^{adv}\right), y\right), s.t. \| \delta\| _{\infty} \leq \epsilon xadvargmaxL(Mϕ(xadv),y),s.t.∥δ∥∞≤ϵ,其中 L \mathcal{L} L 是常用于分类模型的交叉熵损失。
- 黑盒场景下的解决方法:在黑盒场景中,由于目标模型 M ϕ M_{\phi} Mϕ 的参数未知,无法直接优化上述问题。常用的解决办法是通过代理模型 S θ S_{\theta} Sθ 生成对抗样本,利用对抗样本的可迁移性误导目标模型。依据I - FGSM方法,在第 ( t + 1 ) (t + 1) (t+1) 次优化迭代时,对抗样本可表示为 x t + 1 a d v = C l i p x ϵ { x t a d v + α ⋅ s i g n ( ∇ x t a d v L ( S θ ( x t a d v , y ) ) ) } x_{t+1}^{adv}=Clip_{x}^{\epsilon}\left\{x_{t}^{adv}+\alpha \cdot sign\left(\nabla_{x_{t}^{adv}} \mathcal{L}\left(\mathcal{S}_{\theta}\left(x_{t}^{adv}, y\right)\right)\right)\right\} xt+1adv=Clipxϵ{xtadv+α⋅sign(∇xtadvL(Sθ(xtadv,y)))} ,其中 C l i p x ϵ { ⋅ } Clip_{x}^{\epsilon}\{\cdot\} Clipxϵ{⋅} 用于约束攻击强度, α \alpha α 是步长, s i g n ( ) sign() sign() 是符号函数, ∇ x t a d v L ( S θ ( x t a d v , y ) ) \nabla_{x_{t}^{adv}} L(S_{\theta}(x_{t}^{adv}, y)) ∇xtadvL(Sθ(xtadv,y)) 是损失的梯度。
- 统一范式:若利用数据变换 T ( ⋅ ) T(\cdot) T(⋅) 提升对抗样本的可迁移性,可将上述公式修改为更通用的范式 x t + 1 a d v = C l i p x ϵ { x t a d v + α ⋅ s i g n ( ∇ x t a d v L ( S θ ( T ( x t a d v ) , y ) ) ) } x_{t+1}^{adv}=Clip_{x}^{\epsilon}\left\{x_{t}^{adv}+\alpha \cdot sign\left(\nabla_{x_{t}^{adv}} \mathcal{L}\left(\mathcal{S}_{\theta}\left(\mathcal{T}\left(x_{t}^{adv}\right), y\right)\right)\right)\right\} xt+1adv=Clipxϵ{xtadv+α⋅sign(∇xtadvL(Sθ(T(xtadv),y)))},该范式为后续研究中各种数据变换方法的应用提供了统一框架。
普通扭曲变换-Vanilla Warping Transformation (VWT)
该部分提出了普通扭曲变换(VWT),用于替换数据变换 T ( ⋅ ) T(\cdot) T(⋅) 以生成对抗样本,主要内容包括:
- VWT的提出:由于扭曲变换能实现数据局部细节和内容的更多样性,所以提出由随机噪声图 ξ \xi ξ 控制的VWT来替代公式中的 T ( ⋅ ) T(\cdot) T(⋅).
- VWT的实现:依据TPS(Thin Plate Spline,薄板样条插值)算法核心,设置用于 x x x 和 y y y 方向坐标偏移的插值函数 Φ x \Phi_{x} Φx 和 Φ y \Phi_{y} Φy。手动设定两组控制点,原始控制点 O ∈ R M × 2 O \in \mathbb{R}^{M ×2} O∈RM×2 ,通过对其轻微扰动得到目标控制点 P = O + ξ P = O + \xi P=O+ξ ,其中 ξ ∈ R M × 2 \xi \in \mathbb{R}^{M ×2} ξ∈RM×2 从均匀分布中随机采样。利用这两组控制点获取 Φ x \Phi_{x} Φx 和 Φ y \Phi_{y} Φy 的TPS系数,最终通过插值实现变换 T v ( x t a d v [ m , n ] ; ξ ) = x t a d v [ m + Φ x ( m ) , n + Φ y ( n ) ] \mathcal{T}_{v}\left(x_{t}^{adv}[m, n] ; \xi\right)=x_{t}^{adv}\left[m+\Phi_{x}(m), n+\Phi_{y}(n)\right] Tv(xtadv[m,n];ξ)=xtadv[m+Φx(m),n+Φy(n)] , ( m , n ) (m,n) (m,n) 为 x t a d v x_{t}^{adv} xtadv 上像素坐标, x t a d v [ m , n ] x_{t}^{adv}[m, n] xtadv[m,n] 为对应像素值。
- 基于VWT生成对抗样本:将VWT融入对抗样本生成的优化目标中,得到 m a x ∥ δ ∥ ∞ ≤ ϵ L ( S θ ( T v ( x t a d v ; ξ ) , y ) ) max _{\| \delta\| _{\infty} \leq \epsilon} \mathcal{L}\left(\mathcal{S}_{\theta}\left(\mathcal{T}_{v}\left(x_{t}^{adv} ; \xi\right), y\right)\right) max∥δ∥∞≤ϵL(Sθ(Tv(xtadv;ξ),y)) ,以此来生成对抗样本。
变形约束扭曲-Deformation-Constrained Warping (DeCoW)
该部分提出DeCoW,通过优化VWT解决随机变形问题,确保增强样本语义一致性,还介绍了其在视频和音频数据中的应用,具体如下:
- 提出DeCoW的原因:经典扭曲变换(VWT)的变形幅度和方向依赖于均匀分布的随机噪声图,可能导致图像区域或视频、音频片段过度变形,破坏全局语义。因此需要对变形变量进行约束,提出DeCoW。
- DeCoW的实现:通过最小化一个与VWT优化目标相反的目标函数来优化初始的随机噪声
ξ
\xi
ξ ,即
ξ
^
=
a
r
g
m
i
n
ξ
L
(
S
θ
(
T
v
(
x
t
a
d
v
;
ξ
)
)
,
y
)
\hat{\xi}=\underset{\xi}{arg min } \mathcal{L}\left(\mathcal{S}_{\theta}\left(\mathcal{T}_{v}\left(x_{t}^{adv} ; \xi\right)\right), y\right)
ξ^=ξargminL(Sθ(Tv(xtadv;ξ)),y) 。通过反向传播梯度进行迭代更新 ,公式为
ξ
^
=
ξ
−
β
⋅
∇
ξ
(
L
(
S
θ
(
T
v
(
x
t
a
d
v
;
ξ
)
,
y
)
)
\hat{\xi}=\xi-\beta \cdot \nabla_{\xi} (\mathcal{L} (\mathcal{S}_{\theta}(\mathcal{T}_{v}\left(x_{t}^{adv} ; \xi\right), y))
ξ^=ξ−β⋅∇ξ(L(Sθ(Tv(xtadv;ξ),y)),
β
\beta
β 为学习率。得到优化后的
ξ
^
\hat{\xi}
ξ^ 后,更新控制点
P
′
=
O
+
ξ
^
P' = O + \hat{\xi}
P′=O+ξ^ ,进而得到新的插值函数
Φ
^
x
′
\hat{\Phi}_{x}'
Φ^x′ 和
Φ
^
y
′
\hat{\Phi}_{y}'
Φ^y′ ,实现样本增强
T
d
c
(
x
a
d
v
t
[
m
,
n
]
;
ξ
^
)
=
x
t
a
d
v
[
m
+
Φ
^
x
′
(
m
)
,
n
+
Φ
^
y
′
(
n
)
]
\mathcal{T}_{d c}\left(x^{a d v_{t}}[m, n] ; \hat{\xi}\right)=x_{t}^{a d v}\left[m+\hat{\Phi}_{x}'(m), n+\hat{\Phi}_{y}'(n)\right]
Tdc(xadvt[m,n];ξ^)=xtadv[m+Φ^x′(m),n+Φ^y′(n)]。最终定义新的攻击损失为
m
a
x
∥
δ
∥
∞
≤
ϵ
m
i
n
ξ
L
(
S
θ
(
T
v
(
x
t
a
d
v
;
ξ
)
,
y
)
)
max _{\| \delta\| _{\infty} \leq \epsilon} min _{\xi} \mathcal{L}\left(\mathcal{S}_{\theta}\left(\mathcal{T}_{v}\left(x_{t}^{a d v} ; \xi\right), y\right)\right)
max∥δ∥∞≤ϵminξL(Sθ(Tv(xtadv;ξ),y)) ,通过这种最大最小优化,既能实现期望的增强以增加局部细节多样性,又能限制弹性变形,保持图像全局语义。
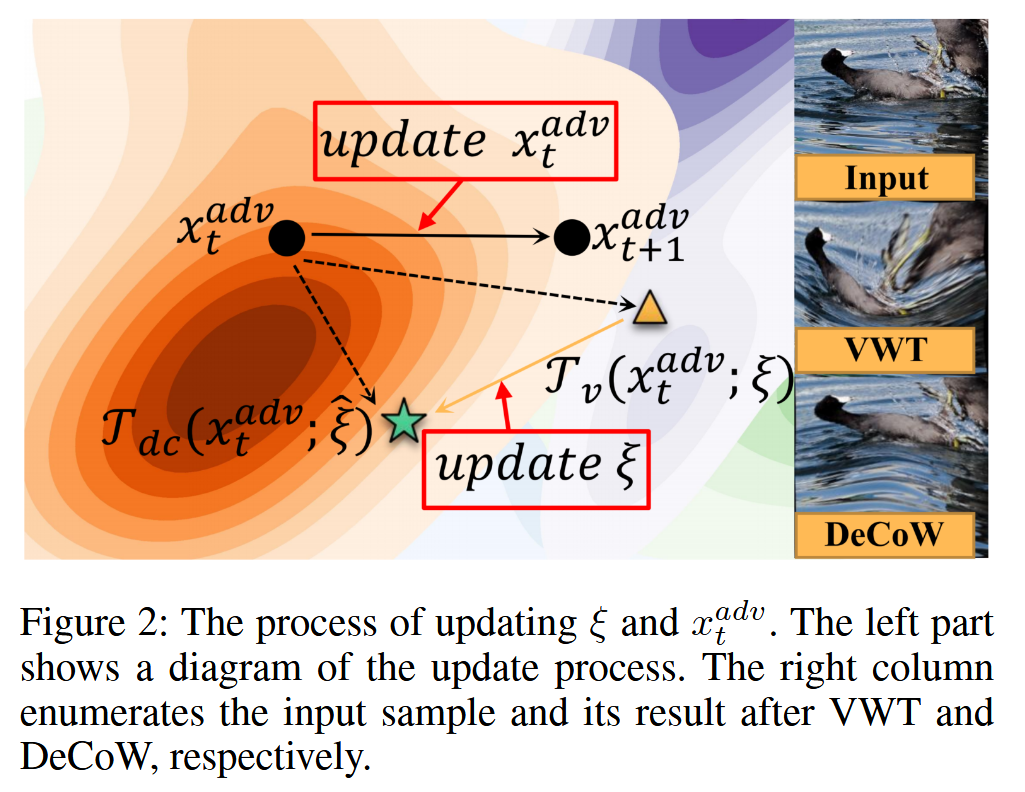
图2:更新 ξ ξ ξ 和 x t a d v x_{t}^{adv} xtadv 的过程。左边部分展示了更新过程的示意图。右边一列分别列举了输入样本以及经过普通扭曲变换(VWT)和变形约束扭曲(DeCoW)后的结果。 - DeCoW在视频和音频中的应用:作为通用方法,DeCoW可应用于视频和音频数据。处理视频时,先在余弦函数内采样连续随机噪声,为噪声赋予周期先验信息和相互关系,得到 ξ τ = { ξ τ ( 1 ) , ξ τ ( 2 ) , … , ξ τ ( K ) } \xi_{\tau}=\left\{\xi_{\tau}^{(1)}, \xi_{\tau}^{(2)}, \ldots, \xi_{\tau}^{(K)}\right\} ξτ={ξτ(1),ξτ(2),…,ξτ(K)} , K K K 为视频帧数。用公式(8)对 ξ τ \xi_{\tau} ξτ 进行初始更新得到 ξ ^ τ \hat{\xi}_{\tau} ξ^τ ,再采用动量积累方式进一步更新 ξ ^ \hat{\xi} ξ^ ,公式为 ξ ^ τ ( i + 1 ) = d ⋅ ξ ^ τ ( i ) + ( 1 − d ) ⋅ ξ ^ τ ( i + 1 ) \hat{\xi}_{\tau}^{(i+1)}=d \cdot \hat{\xi}_{\tau}^{(i)}+(1-d) \cdot \hat{\xi}_{\tau}^{(i+1)} ξ^τ(i+1)=d⋅ξ^τ(i)+(1−d)⋅ξ^τ(i+1) , d d d 为超参数,从而实现对视频片段的连续DeCoW操作,利用相邻帧间的时间信息。
攻击算法-Attack Algorithm
该部分提出了Deformation-Constrained Warping Attack(DeCoWA)算法,将DeCoW集成到MI-FGSM方法中,通过多次变形操作增强对抗样本的迁移性,具体步骤如下:
- 集成DeCoW和MI-FGSM:DeCoWA算法将DeCoW与MI-FGSM(Momentum Iterative Fast Gradient Sign Method)相结合。在每次获取对抗梯度 g ′ g' g′ 时,需要进行一次最大化-最小化操作。通过最小化操作更新随机噪声 ξ \xi ξ 得到 ξ ^ \hat{\xi} ξ^ ,再基于 ξ ^ \hat{\xi} ξ^ 通过最大化操作推导对抗梯度 g ′ g' g′.
- 多次变形增强模型特征:在攻击过程中,对对抗样本 x t a d v x_{t}^{adv} xtadv 应用多次扭曲变换,公式为 g ‾ t + 1 = 1 N ∑ j = 0 N g j ′ = 1 N ∑ j = 0 N ∇ x t a d v L ( S θ ( T d c ( x t a d v ; ξ ^ j ) ) , y ) \overline{g}_{t+1}=\frac{1}{N} \sum_{j=0}^{N} g_{j}'=\frac{1}{N} \sum_{j=0}^{N} \nabla_{x_{t}^{adv}} \mathcal{L}\left(\mathcal{S}_{\theta}\left(\mathcal{T}_{d c}\left(x_{t}^{adv} ; \hat{\xi}_{j}\right)\right), y\right) gt+1=N1∑j=0Ngj′=N1∑j=0N∇xtadvL(Sθ(Tdc(xtadv;ξ^j)),y) ,其中 N N N 是对抗扭曲变换的次数。多次变换能够从不同方向增强模型特征,提高代理模型的多样性。
- 更新增强动量和对抗样本:基于多次变换得到的梯度 g ‾ t + 1 \overline{g}_{t+1} gt+1,更新增强动量 g t + 1 = μ ⋅ g t + g ‾ t + 1 ∥ g ‾ t + 1 ∥ 1 g_{t+1}=\mu \cdot g_{t}+\frac{\overline{g}_{t+1}}{\left\| \overline{g}_{t+1}\right\| _{1}} gt+1=μ⋅gt+∥gt+1∥1gt+1 ,其中 μ \mu μ 是衰减因子。最后,根据更新后的增强动量 g t + 1 g_{t+1} gt+1,更新对抗样本 x t + 1 a d v = C l i p x ϵ { x t a d v + α ⋅ s i g n ( g t + 1 ) } x_{t+1}^{adv}=Clip_{x}^{\epsilon}\left\{x_{t}^{adv}+\alpha \cdot sign\left(g_{t+1}\right)\right\} xt+1adv=Clipxϵ{xtadv+α⋅sign(gt+1)} , α \alpha α 是步长, C l i p x ϵ Clip_{x}^{\epsilon} Clipxϵ 是将攻击强度约束在 ϵ \epsilon ϵ -球内的操作。
实验-Experiments
该部分通过在图像分类、视频识别和音频识别领域进行实验,验证了DeCoWA攻击策略的有效性,具体内容如下:
- 图像分类攻击实验
- 实验设置:使用ImageNet兼容数据集评估DeCoWA。选择Inception-v3和ResNet-50作为代理模型,攻击多个ViT变体;同时也进行了CNN对CNN的同源模型属攻击实验,选取ResNet101、VGG19、DenseNet121和EfficientNet作为目标模型。对比方法包括DIM、TIM、SIM、Admix和S 2 ^{2} 2IM,所有方法都集成了MIFGSM。设置了统一的攻击参数,如扰动预算 ϵ = 16.0 \epsilon = 16.0 ϵ=16.0 ,迭代次数 T = 10 T = 10 T=10 等。
- 实验结果:在CNN攻击ViT的实验中,DeCoWA表现优异。以Inception-v3为代理模型时,其平均攻击性能比现有最佳方法S
2
^{2}
2IM高出14.65%以上。在CNN攻击CNN的实验中,DeCoWA在所有设置下都实现了最佳的可迁移性,优于其他先进方法。
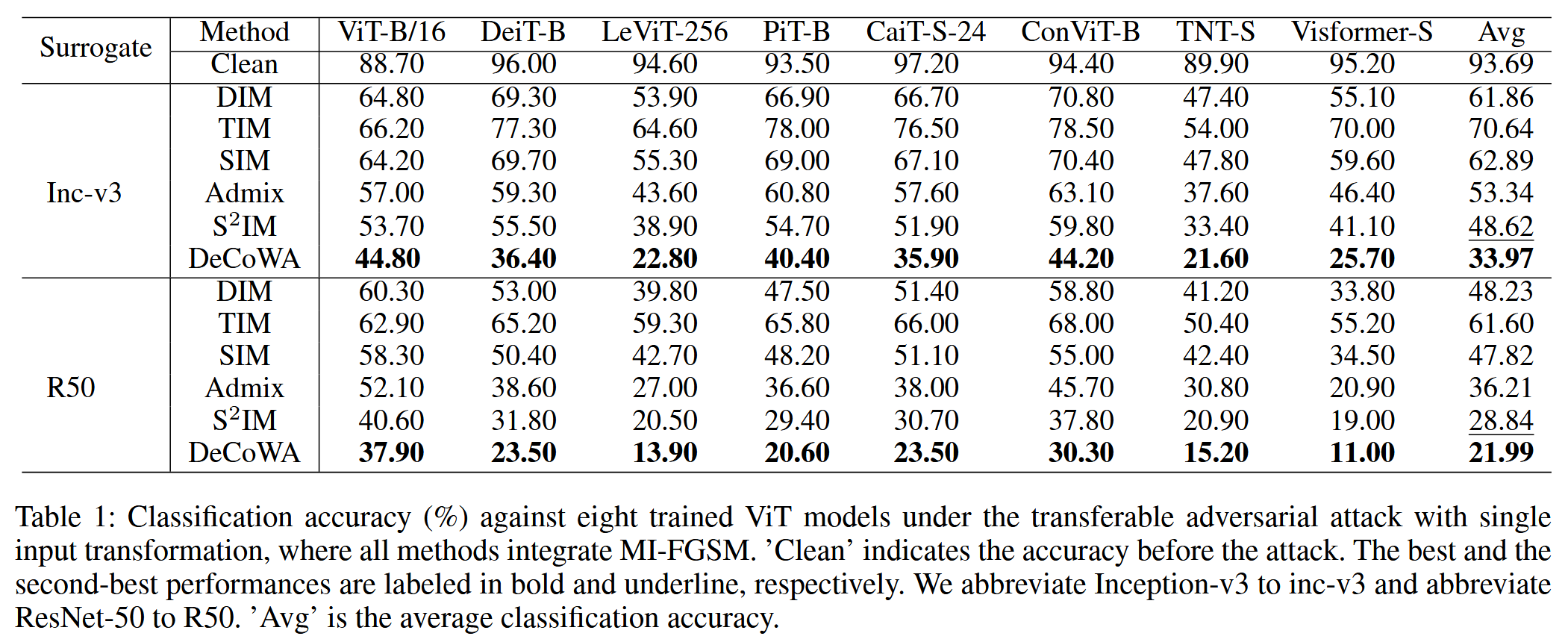
表1:在单输入变换的可迁移对抗攻击下,针对八个训练好的ViT模型的分类准确率(%)。所有方法都集成了MI-FGSM。“Clean”表示攻击前的准确率。最佳和次佳性能分别用加粗和下划线标注。我们将Inception-v3缩写为inc-v3,将ResNet-50缩写为R50。“Avg”是平均分类准确率。
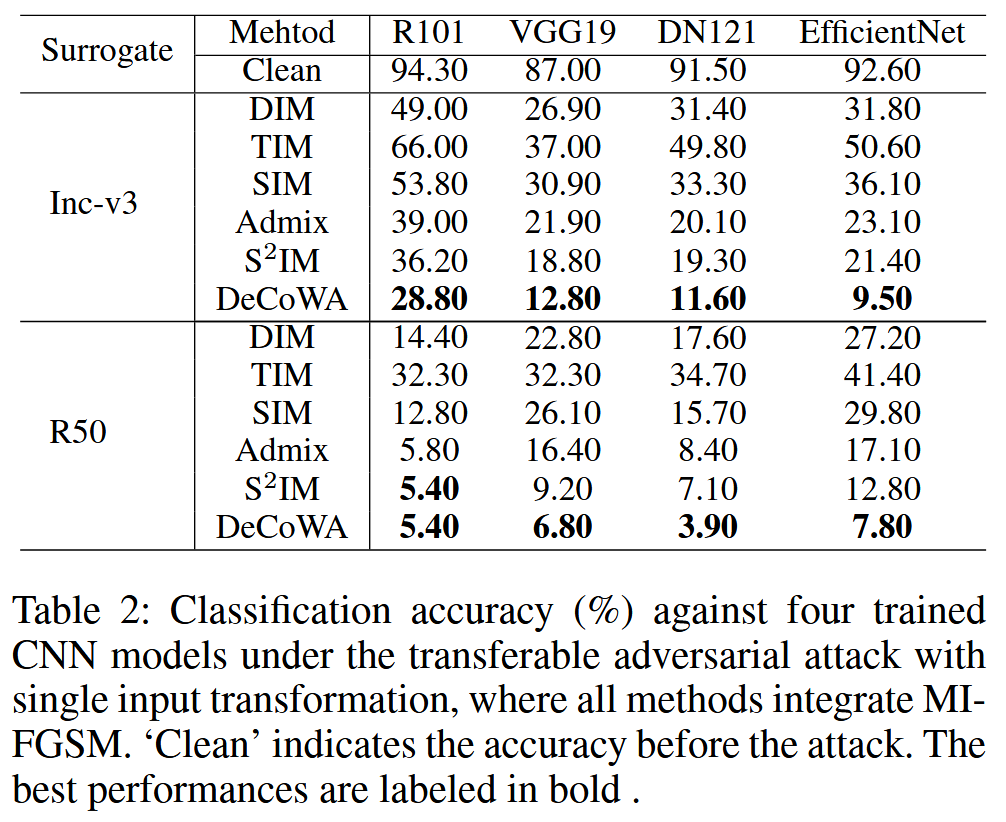
表2:在单输入变换的可迁移对抗攻击下,四个训练好的CNN模型的分类准确率(%)。所有方法都集成了MIFGSM。“Clean”表示攻击前的准确率。最佳性能以粗体显示。
- 视频识别攻击实验
- 实验设置:利用Kinetics400数据集评估DeCoWA对视频识别模型的攻击效果。选择I3D、SlowFast、TimesFormer和Swin Transformer这四个模型进行测试。对每个视频选取32个连续帧构建输入剪辑,共得到3个输入剪辑。对比方法有BIM、DIM和SIM。
- 实验结果:DeCoWA能够以时间序列的方式处理连续帧,在攻击视频识别模型方面优于其他输入变换方法,对ViT模型的增强效果更显著,攻击性能更强。
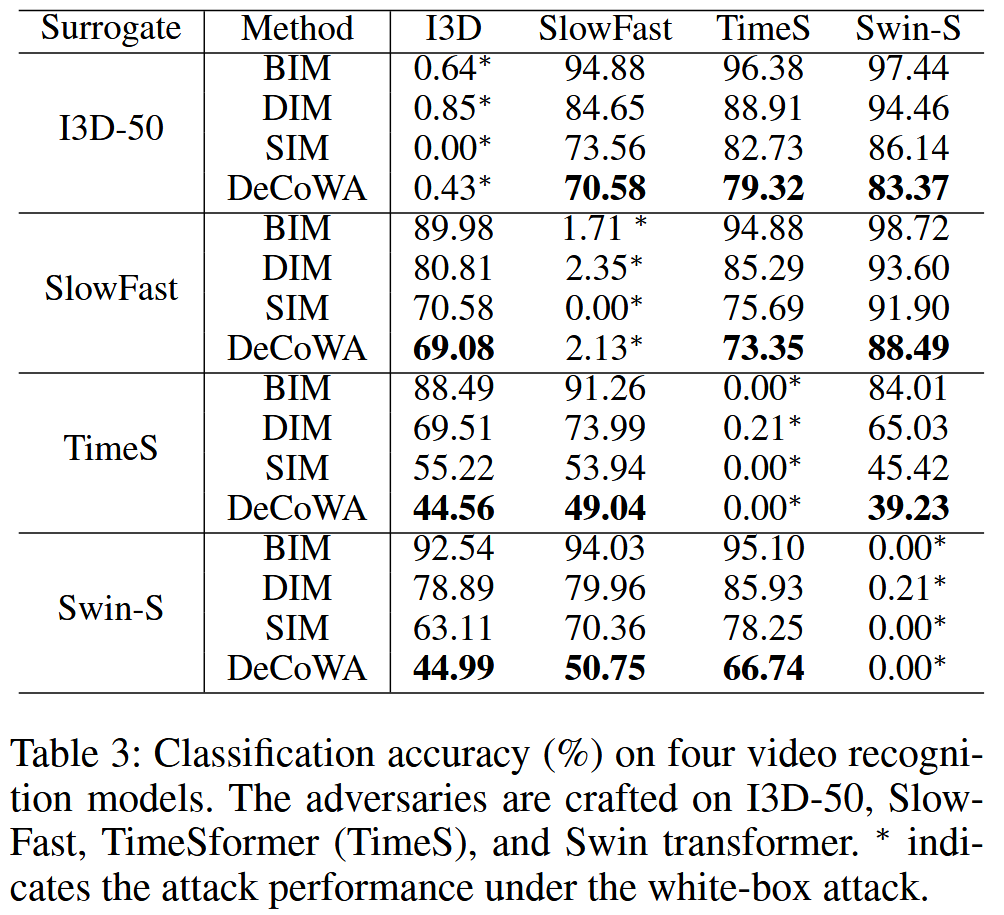
表3:四个视频识别模型的分类准确率(%)。对抗样本是在I3D - 50、SlowFast、TimeSformer(TimeS)和Swin Transformer上生成的。 ∗ ∗ ∗ 表示白盒攻击下的攻击性能。
- 音频识别攻击实验
- 实验设置:使用四个声学场景分类模型(Baseline、PANN、ERGL和RGASC)和从验证集中选取的2,518个音频进行评估。对比方法为BIM和SI-FGSM。由于DIM的图像变换方法无法直接处理语音信号,所以未参与对比,而DeCoWA可轻松处理语音信号。
- 实验结果:DeCoWA在生成更通用的扰动方面始终优于现有方法,为攻击音频识别系统提供了新途径。
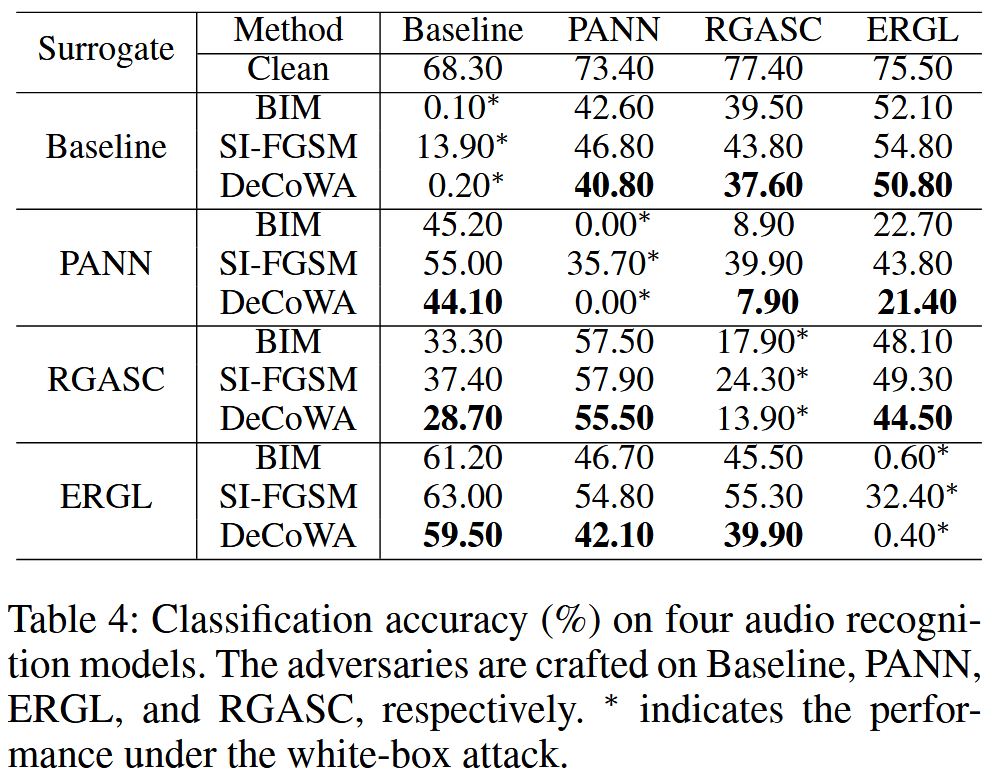
表4:四个音频识别模型的分类准确率(%)。对抗样本分别在基线模型(Baseline)、PANN、ERGL和RGASC上生成。 ∗ ∗ ∗ 表示白盒攻击下的性能。
- 可视化分析
- Grad-CAM可视化:通过对ResNet-50和ViT-B的Grad-CAM可视化发现,DeCoW能使ResNet-50像ViT-B/16一样关注物体的全局外观,表明DeCoW是一种通用变换,可探索目标系统更多的关注区域,缩小CNN和ViT之间的差距。

图3:对两个训练好的模型ResNet-50和ViT-B/16进行Grad-CAM可视化。(a)至(b):ResNet-50和ViT-B/16对原始图像的可视化结果。(c)至(e):ResNet-50对采用SI、Admix、S 2 I ^{2}I 2I方法处理后的图像的可视化结果。(f):ResNet-50对经我们的DeCoW处理后的图像的可视化结果。 - 不同输入变换可视化:与其他输入变换方法对比,DeCoW更能改变局部形状和轮廓,增加局部多样性,而其他方法大多只能对全局内容进行有限改变。
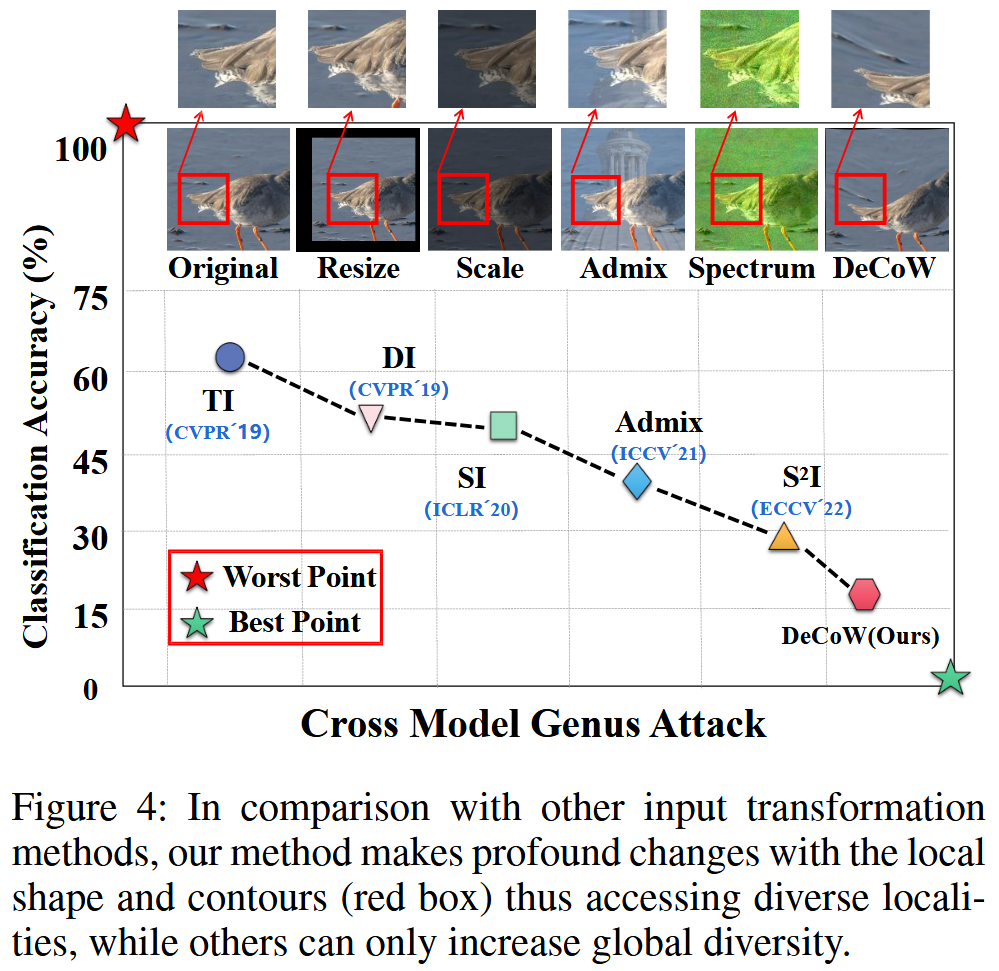
图4:与其他输入变换方法相比,我们的方法对局部形状和轮廓(红色框)进行了显著改变,从而能够探索多样的局部区域,而其他方法只能增加全局的多样性。
- Grad-CAM可视化:通过对ResNet-50和ViT-B的Grad-CAM可视化发现,DeCoW能使ResNet-50像ViT-B/16一样关注物体的全局外观,表明DeCoW是一种通用变换,可探索目标系统更多的关注区域,缩小CNN和ViT之间的差距。
结论与展望-Conclusion and Outlook
该部分总结了研究成果并对未来研究方向做出展望,具体内容如下:
- 研究结论:强调跨模型属攻击任务应得到更多关注,提出的变形约束扭曲攻击(DeCoWA)是一种通过对输入样本应用约束弹性变形,来模拟不同模型属的多样化模型,进而提升跨模型属对抗样本可迁移性的新技术。大量实验证实了DeCoWA在多种模态数据(图像、视频、音频)跨模型属攻击任务中的优越性,其能有效降低目标模型在不同任务中的性能,可作为未来跨模型属攻击研究对比的有力基线。
- 未来展望:未来研究将聚焦于跨数据分布攻击。在这种攻击场景中,攻击者仅能访问基于不同数据分布训练的代理模型,且代理模型与目标系统的模型属不同。这将进一步拓展对抗攻击研究的边界,探索在更具挑战性的场景下提升对抗样本可迁移性的方法。


















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











