







Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples
- 摘要-Abstract
- 引言-Introduction
- 方法概述-Approach Overview
- 机器学习中对抗样本的可迁移性-Transferability Of Adversarial Samples In Machine Learning
- 通过知识迁移学习分类替代模型-Learning Classifier Substitutes By KnowledgeTransfer
- 远程机器学习分类器的黑盒攻击-Black-box Attacks Of Remote Machine Learning Classifiers
- 对抗样本制作-Adversarial Sample Crafting
- 讨论和相关工作-DISCUSSION AND RELATED WORK
本文 “Transferability in Machine Learning: from Phenomena to Black - Box Attacks using Adversarial Samples” 主要研究机器学习中对抗样本的可迁移性,提出了针对多种机器学习模型的黑盒攻击方法,并通过实验验证了其有效性,强调了现有机器学习系统在面对此类攻击时的脆弱性,为后续研究机器学习的安全性提供了重要参考。
摘要-Abstract
Many machine learning models are vulnerable to adversarial examples: inputs that are specially crafted to cause a machine learning model to produce an incorrect output. Adversarial examples that affect one model often affect another model, even if the two models have different architectures or were trained on different training sets, so long as both models were trained to perform the same task. An attacker may therefore train their own substitute model, craft adversarial examples against the substitute, and transfer them to a victim model, with very little information about the victim. Recent work has further developed a technique that uses the victim model as an oracle to label a synthetic training set for the substitute, so the attacker need not even collect a training set to mount the attack. We extend these recent techniques using reservoir sampling to greatly enhance the efficiency of the training procedure for the substitute model. We introduce new transferability attacks between previously unexplored (substitute, victim) pairs of machine learning model classes, most notably SVMs and decision trees. We demonstrate our attacks on two commercial machine learning classification systems from Amazon (96.19% misclassification rate) and Google (88.94%) using only 800 queries of the victim model, thereby showing that existing machine learning approaches are in general vulnerable to systematic black-box attacks regardless of their structure.
许多机器学习模型容易受到对抗样本的攻击:这些对抗样本是经过特殊构造的输入,目的是使机器学习模型产生错误的输出。影响一个模型的对抗样本往往也会影响另一个模型,即使这两个模型的架构不同,或者是在不同的训练集上进行训练的,只要它们都是为执行相同任务而训练的。因此,攻击者可以训练自己的替代模型,针对替代模型构造对抗样本,然后将这些样本迁移到目标模型上,而他们对目标模型的了解可能非常少。最近的研究进一步开发出一种技术,该技术利用目标模型作为 “Oracle” 来为替代模型标记合成训练集,这样攻击者甚至无需收集训练集就能发起攻击。我们利用蓄水池采样扩展了这些最新技术,大幅提高了替代模型的训练效率。我们引入了针对此前未探索过的(替代模型、目标模型)机器学习模型类别对的新型可迁移性攻击,其中最值得注意的是支持向量机和决策树。我们仅通过对目标模型进行800次查询,就对亚马逊(误分类率达96.19%)和谷歌(误分类率达88.94%)的两个商业机器学习分类系统进行了攻击演示,从而表明现有的机器学习方法通常都容易受到系统性黑盒攻击,无论其结构如何。
“Oracle” 可以翻译为 “应答器”,其只负责回答有效的询问,而不暴露更多信息。其就是一个“黑盒子”,只能看到输入和输出,而看不到其内部计算过程.
引言-Introduction
机器学习领域中,许多模型存在安全隐患,易受对抗样本的攻击。这部分内容主要阐述了对抗样本的危害、可迁移性以及本文针对该现象的研究工作与成果,具体如下:
- 对抗样本的危害:诸多机器学习算法对对抗样本敏感。攻击者通过细微调整合法输入(输入扰动),利用学习算法训练时的缺陷,使模型输出错误结果。这种攻击手段可用于破坏欺诈检测、绕过内容或恶意软件检测、误导自主导航系统等,严重威胁相关应用的安全性。
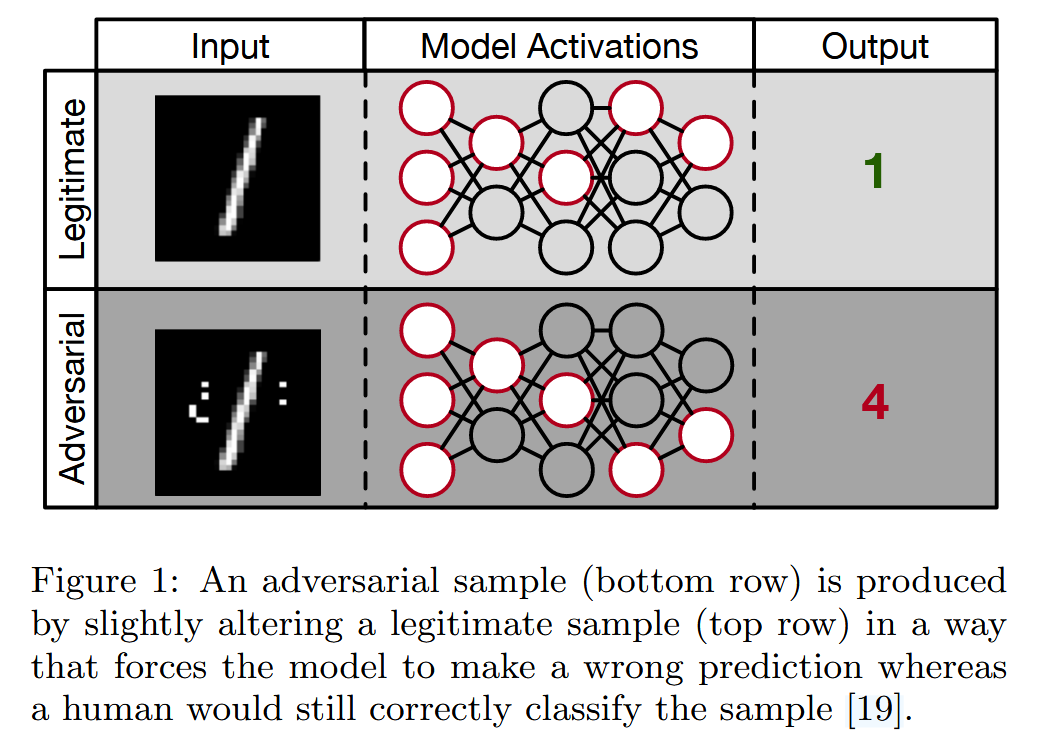
图1:对抗样本(底部一行)是通过对合法样本(顶部一行)进行轻微改变而生成的,这种改变会迫使模型做出错误预测,而人类仍能正确分类该样本。 - 对抗样本的可迁移性及应用:对抗样本具有可迁移性,即针对特定模型 f f f 生成的对抗样本,常常也能误导其他模型 f ′ f' f′,即使这些模型架构不同或训练集各异,只要执行相同任务就可能受到影响。这一特性催生了基于Oracle的黑盒攻击。如Papernot等人利用目标“受害者” DNN生成的输入和标签,训练本地DNN,随后用本地网络生成的对抗样本成功攻击原目标DNN。攻击者在这个过程中,对目标模型的架构和参数一无所知,仅能通过神谕获取输入对应的输出。
- 本文的研究工作与成果:本文围绕对抗样本可迁移性展开研究,开发并验证了一种适用于多种机器学习模型的广义黑盒攻击算法。研究涵盖神经网络(DNNs)、逻辑回归(LR)、支持向量机(SVM)、决策树(DT)、最近邻(kNN)和集成模型(Ens.)等多种模型类型,探究它们内部及相互之间的对抗样本可迁移性。研究成果包括:为SVM和DT这两种不可微模型引入对抗样本构造技术;将替代模型的学习从深度学习拓展到LR和SVM领域,并证明能以高于80%的准确率学习匹配多种模型标签的替代模型;通过引入新超参数和蓄水池采样技术,提升了替代模型学习的精度,降低了计算成本;对亚马逊和谷歌的商业分类器进行黑盒攻击,仅用800次查询,就让亚马逊和谷歌的模型分别出现96.19%和88.94%的误分类率,表明现有机器学习方法普遍易受黑盒攻击。
方法概述-Approach Overview
该部分围绕针对机器学习分类器的黑盒攻击设计,阐述了相关方法及核心概念,具体内容如下:
- 对抗样本可迁移性的定义
- 生成对抗样本的优化问题:为生成能误导模型 f f f 的对抗样本 x ∗ → \overrightarrow{x^{*}} x∗,需解决优化问题 x ∗ ⃗ = x ⃗ + δ x ⃗ \vec{x^{*}}=\vec{x}+\delta_{\vec{x}} x∗=x+δx,其中 δ x ⃗ = a r g m i n z ⃗ f ( x ⃗ + z ⃗ ) ≠ f ( x ⃗ ) \delta_{\vec{x}}=arg min _{\vec{z}} f(\vec{x}+\vec{z}) \neq f(\vec{x}) δx=argminzf(x+z)=f(x) ,但由于部分模型的特性,该问题不一定有封闭解,不过已有多种方法可找到近似解。
- 可迁移性的量化指标:为便于讨论,将对抗样本可迁移性形式化定义为 Ω X ( f , f ′ ) = ∣ { f ′ ( x ⃗ ) ≠ f ′ ( x ⃗ + δ x ⃗ ) : x ⃗ ∈ X } ∣ \Omega_{X}\left(f, f'\right)=\left|\left\{f'(\vec{x}) \neq f'\left(\vec{x}+\delta_{\vec{x}}\right): \vec{x} \in X\right\}\right| ΩX(f,f′)=∣{f′(x)=f′(x+δx):x∈X}∣,其中集合 X X X 代表模型 f f f 和 f ′ f' f′ 解决任务的期望输入分布。同时,将对抗样本可迁移性分为两种类型:一是同技术可迁移性,指相同机器学习技术训练但参数初始化或数据集不同的模型间的可迁移性;二是跨技术可迁移性,涉及不同机器学习技术训练的模型间的可迁移性。
- 研究假设及验证方式
- 假设1:同技术和跨技术对抗样本可迁移性在机器学习技术空间中普遍显著。为验证该假设,使用MNIST数据集训练多种模型,涵盖DNN、LR、SVM、DT、kNN等。在实验的第一部分,测量同技术对抗样本可迁移性,即对每种机器学习技术,在不同数据子集上训练多个模型,计算模型间对抗样本的误分类比例;在第二部分,测量跨技术对抗样本可迁移性,针对所有可能的机器学习技术对训练的模型,计算对抗样本在不同技术模型间的误分类比例。
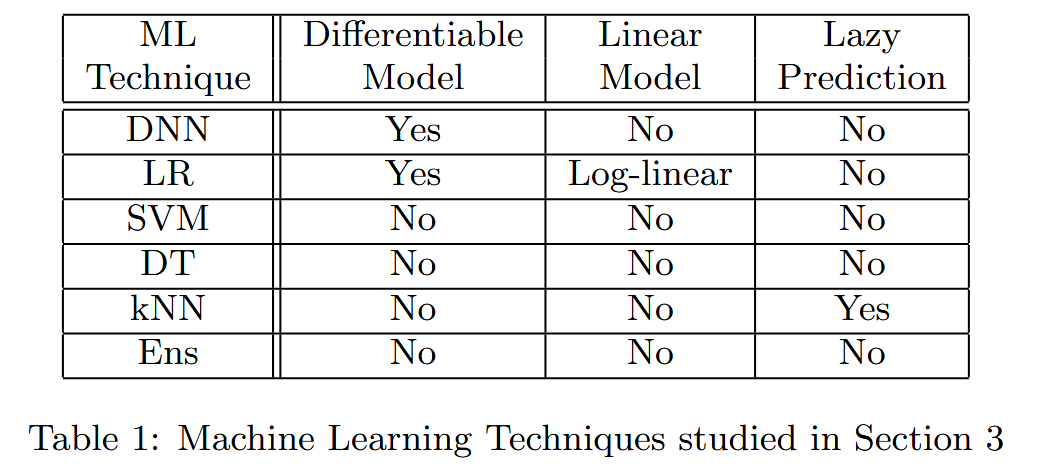
表1:第3节研究的机器学习技术 - 假设2:在实际场景中,可对任何未知的机器学习分类器进行黑盒攻击。为验证该假设,分两步进行。首先在第4节中,通过精心选择输入并查询分类器标签,将任何机器学习分类器的泛化知识迁移到替代模型中;然后在第5节中,对亚马逊和谷歌托管的商业机器学习分类器进行黑盒攻击。在验证过程中,采用Oracle威胁模型,即攻击者仅能观察模型对所选输入的预测标签,而对模型的架构和参数一无所知。
- 假设1:同技术和跨技术对抗样本可迁移性在机器学习技术空间中普遍显著。为验证该假设,使用MNIST数据集训练多种模型,涵盖DNN、LR、SVM、DT、kNN等。在实验的第一部分,测量同技术对抗样本可迁移性,即对每种机器学习技术,在不同数据子集上训练多个模型,计算模型间对抗样本的误分类比例;在第二部分,测量跨技术对抗样本可迁移性,针对所有可能的机器学习技术对训练的模型,计算对抗样本在不同技术模型间的误分类比例。
机器学习中对抗样本的可迁移性-Transferability Of Adversarial Samples In Machine Learning
该部分主要通过实验研究了机器学习中对抗样本的可迁移性,包括同技术可迁移性和跨技术可迁移性,旨在验证假设一同技术和跨技术对抗样本可迁移性在机器学习技术空间中是普遍存在的强现象,具体内容如下:
- 实验设置
- 数据集:选用MNIST手写数字数据集,该数据集在机器学习和安全领域研究广泛,其维度适合研究中的多种机器学习技术,任务是将图像分类到0 - 9这10个数字类别中,包含50,000个训练样本、10,000个验证样本和10,000个测试样本,图像编码为28x28的灰度像素向量。
- 机器学习模型:选取DNN、LR、SVM、DT、kNN这五种机器学习技术。DNN因其先进性能被选,LR因其简单性,SVM因其训练时选择决策边界的边际约束可能带来的稳健性,DT因其不可微性,kNN因其为惰性分类模型。使用Theano和Lasagne训练DNN、LR和kNN模型,用scikit - Learn训练线性SVM和DT。
- 同技术可迁移性
- 实验方法:通过将训练集划分为5个不相交的子集A、B、C、D、E(各10,000个样本),对每种机器学习技术分别训练5个不同模型。用合适的对抗样本算法从测试集中生成10,000个样本,调整相关参数使生成的对抗样本能让模型几乎完全误分类,如设置快速梯度符号法的输入变化参数 ε = 0.3 \varepsilon = 0.3 ε=0.3 ,SVM算法的 ε = 1.5 \varepsilon = 1.5 ε=1.5 。
- 实验结果:所有模型都在一定程度上易受同技术对抗样本可迁移性影响。LR模型最脆弱,对抗样本在模型间的迁移率超94%;DNN模型迁移率至少49%;SVM、DT和kNN模型相对更稳健,这可能是因为SVM训练时对超平面决策边界的选择有明确约束,而DT和kNN的稳健性源于其不可微性。
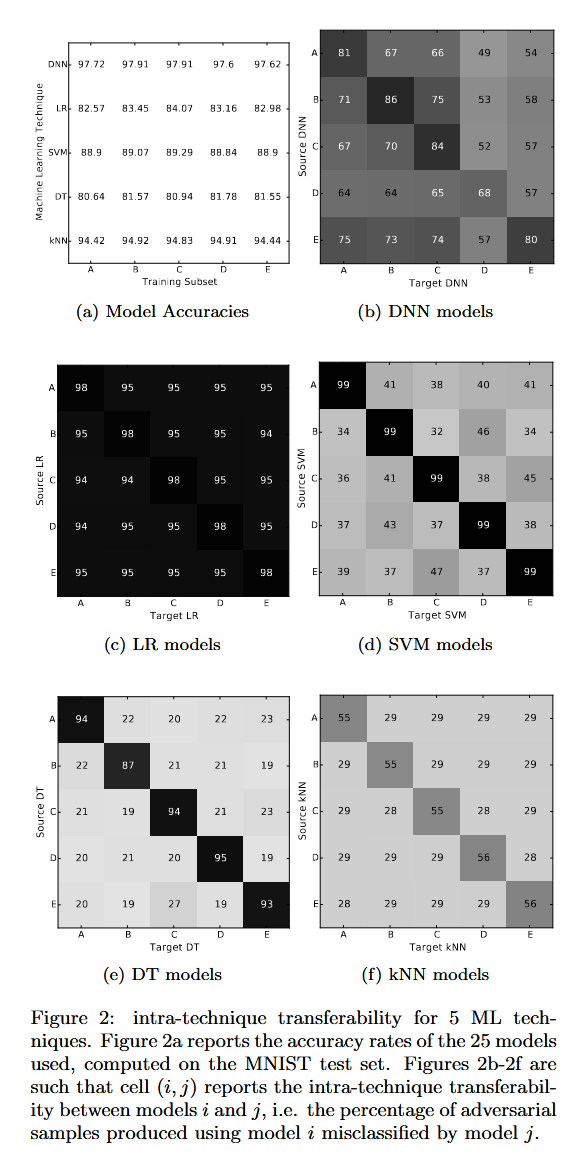
图2:5种机器学习技术的同技术可迁移性。图2a报告了所使用的25个模型在MNIST测试集上计算出的准确率。图2b - 2f中,单元格 ( i , j ) (i, j) (i,j) 报告了模型 i i i 和模型 j j j 之间的同技术可迁移性,即使用模型 i i i 生成的对抗样本被模型 j j j 误分类的百分比。
- 跨技术可迁移性
- 实验方法:研究涉及之前的五种模型,并新增一个集成模型。集成模型由5个不同技术的模型(DNN、LR、SVM、DT、kNN)作为专家组成,根据多数专家的决策输出分类结果。为确保结果可比,调整可参数化的对抗样本生成算法,使生成的样本具有相似的扰动幅度,用L1范数衡量,如使DNN、LR和SVM生成的对抗样本平均L1范数为11.5% ,但DT攻击无法匹配该范数,其平均L1范数为1.05% 。构建跨技术可迁移性矩阵,记录不同技术训练的模型间对抗样本的误分类比例。
- 实验结果:跨技术可迁移性是一个普遍但不均衡的现象。决策树最易受影响,误分类率在47.20% - 89.29% ;DNN相对最具弹性,误分类率在0.82% - 38.27% ;集成模型对由LR模型生成的对抗样本误分类率达44.14%,这可能是由于其基础专家模型易受对抗样本影响。综上,所有研究的机器学习技术都易受两种类型的对抗样本可迁移性影响,跨技术可迁移性降低了攻击者使模型误分类的知识门槛。
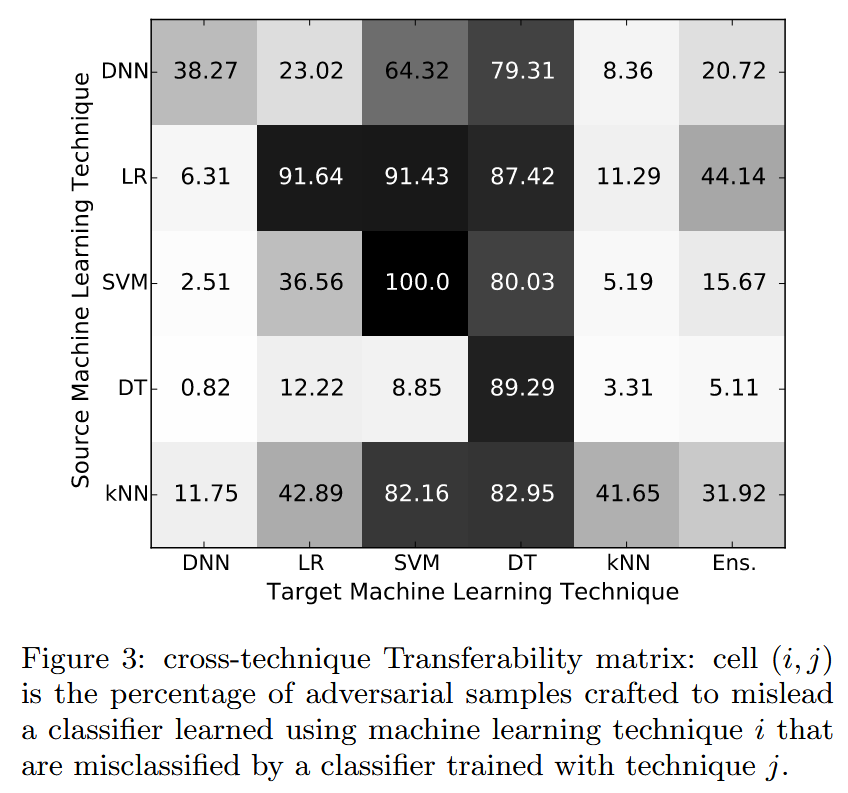
图3:跨技术可迁移性矩阵:单元格 ( i , j ) (i, j) (i,j) 表示为误导使用机器学习技术 i i i 训练的分类器而生成的对抗样本,被使用技术 j j j 训练的分类器误分类的百分比。
通过知识迁移学习分类替代模型-Learning Classifier Substitutes By KnowledgeTransfer
用于替代模型的数据集增强-Dataset Augmentation for Substitutes
该部分主要介绍了用于训练替代模型的数据集增强方法,旨在解决在仅能查询目标分类器标签的情况下,如何有效训练替代模型以逼近目标分类器的问题,具体内容如下:
- 基于Jacobian的数据集增强:在训练替代模型时,目标分类器被视为“Oracle”,攻击者仅能通过查询其对选定输入的预测标签获取信息,对分类器其他信息一无所知。基于Jacobian的数据集增强技术,先收集少量具有代表性的初始替代训练集,通过查询“Oracle”获得标签后训练第一个替代模型。由于训练样本少,该模型性能可能不佳。为选择额外训练点,利用公式 S ρ + 1 = { x ⃗ + λ ρ ⋅ s g n ( J f [ O ~ ( x ⃗ ) ] : x ⃗ ∈ S ρ ) } ∪ S ρ S_{\rho+1}=\left\{\vec{x}+\lambda_{\rho} \cdot sgn\left(J_{f}[\tilde{O}(\vec{x})]: \vec{x} \in S_{\rho}\right)\right\} \cup S_{\rho} Sρ+1={x+λρ⋅sgn(Jf[O~(x)]:x∈Sρ)}∪Sρ,其中 S ρ S_{\rho} Sρ 和 S ρ + 1 S_{\rho+1} Sρ+1 是前后两代训练集, λ ρ \lambda_{\rho} λρ 是调整增强步长的参数, J f J_{f} Jf 是替代模型 f f f 的Jacobian矩阵, O ˉ ( x ⃗ ) \bar{O}(\vec{x}) Oˉ(x) 是“Oracle”对样本 x ⃗ \vec{x} x 的标签。通过多次交替增强训练集和训练新的替代模型实例,可使替代DNN逼近目标DNN。
- 周期性步长调整:Papernot等人最初使用固定步长参数 λ ρ \lambda_{\rho} λρ,而本文提出周期性步长调整方法。引入迭代周期 τ \tau τ,步长 λ ρ = λ ⋅ ( − 1 ) ⌊ ρ τ ⌋ \lambda_{\rho}=\lambda \cdot(-1)^{\left\lfloor\frac{\rho}{\tau}\right\rfloor} λρ=λ⋅(−1)⌊τρ⌋,在经过 τ \tau τ 次迭代后,步长乘以 -1 。这样可以提高替代模型对“Oracle”的逼近质量,通过与原始分类器“Oracle”匹配的标签数量来衡量。实验表明,周期性步长调整能让替代模型更准确地逼近目标,如训练替代DNN时,使用周期性步长在 ρ = 9 \rho = 9 ρ=9 次迭代时,与DNN“Oracle”匹配的标签比例比固定步长时更高。
- 蓄水池采样:在实际环境中,攻击者对“Oracle”的标签查询次数受限。引入蓄水池采样技术,在基于Jacobian的数据集增强过程中,随机选择
κ
\kappa
κ 个样本进行增强,防止每次增强迭代时对“Oracle”的查询次数呈指数增长。在迭代
ρ
>
σ
\rho>\sigma
ρ>σ 时,从之前的训练集
S
ρ
−
1
S_{\rho - 1}
Sρ−1 中用蓄水池采样选择
κ
\kappa
κ 个输入在
S
ρ
S_{\rho}
Sρ 中进行增强,确保每个输入被选中增强的概率相等。使用蓄水池采样后,对“Oracle”的查询次数从
n
⋅
2
ρ
n \cdot 2^{\rho}
n⋅2ρ 减少到
n
⋅
2
σ
+
κ
⋅
(
ρ
−
σ
)
n \cdot 2^{\sigma}+\kappa \cdot(\rho-\sigma)
n⋅2σ+κ⋅(ρ−σ) ,且实验显示这种方法不会显著降低替代模型的质量。

深度神经网络替代模型-Deep Neural Network Substitutes
该部分主要研究了深度神经网络(DNN)作为替代模型的性能,通过实验验证其对不同类型机器学习分类器的逼近能力,具体内容如下:
- 实验目的与设置:在之前研究基础上,进一步验证将基于Jacobian的增强技术用于训练DNN替代模型的通用性,对5种不同类型(DNN、LR、SVM、DT、kNN)的机器学习分类器进行实验。这些分类器作为“Oracle”,均在50,000样本的MNIST训练集上训练。实验以MNIST测试集的前100个样本作为初始替代训练集,使用 λ = 0.1 \lambda = 0.1 λ=0.1 ,分别采用三种训练方式:基于Jacobian的普通增强、周期性步长( τ = 3 \tau = 3 τ=3 )的增强、周期性步长( τ = 3 \tau = 3 τ=3 )且结合水库采样( σ = 3 \sigma = 3 σ=3 , κ = 400 \kappa = 400 κ=400 )的增强。替代DNN的架构与前文相同。训练进行10次增强迭代( ρ ≤ 9 \rho ≤9 ρ≤9 )。
- 实验结果与分析
- 整体逼近效果:从图4a可看出,一般来说,所有替代DNN在经过10次增强迭代后,都能成功逼近相应“Oracle”。除决策树(DT)“Oracle”外,与MNIST测试集标签的匹配比例约为77% - 83% ,DT“Oracle”的匹配比例仅为48% ,这可能是因为决策树的不可微性。即便kNN采用惰性分类(训练时不学习模型,预测时找最近训练样本),替代DNN也能对其“Oracle”进行逼近。
- 改进措施的影响:从表2前三行数据可知,周期性步长改进能显著提高替代DNN对目标“Oracle”的逼近准确性。例如,对于DNN“Oracle”,经过9次迭代,采用周期性步长训练的替代DNN匹配标签比例为89.28% ,普通替代DNN仅为78.01%;对于SVM“Oracle”,相应比例分别为83.79%和79.68%。蓄水池采样虽使匹配标签数比仅用周期性步长时少,但仍优于普通替代DNN。如逼近DNN“Oracle”时,普通替代DNN匹配7801个标签,周期性步长的为8928个,周期性步长结合蓄水池采样的为8290个。这表明蓄水池采样在减少查询次数的同时,能保持一定的替代模型质量。
逻辑回归替代模型-Logistic Regression Substitutes
该部分主要探讨了逻辑回归(LR)作为替代模型的性能表现,对比其与深度神经网络(DNN)替代模型的优劣,具体内容如下:
- 选择LR作为替代模型的原因:由于跨技术迁移性并非特定于基于DNN生成的对抗样本,且LR在跨技术迁移性方面表现出色(除针对DNN自身外,其跨技术迁移率高于DNN),所以LR是作为替代模型的合适候选。同时,多类逻辑回归与深度神经网络常用的softmax层类似,便于计算其Jacobian矩阵,这使得基于Jacobian的数据集增强技术易于应用于多类逻辑回归。
- 实验设置与过程:重复前文中关于DNN替代模型的实验,但此次训练多类逻辑回归替代模型来匹配分类器神谕的标签,其他实验设置保持不变。
- 实验结果与分析
- 逼近质量:从图4b可看出,LR替代模型的逼近质量不如DNN替代模型,标签匹配比例有所降低。然而,对于LR和SVM神谕,LR替代模型的性能与DNN替代模型具有竞争力。但对于决策树神谕,LR替代模型的表现依旧不佳,匹配率仅略高于40%。
- 改进措施的影响:从表2后三行数据可知,周期性步长调整对LR替代模型同样有效,能提高其对目标神谕的逼近准确性。例如,在 ρ = 9 \rho = 9 ρ=9 次迭代时,针对LR“Oracle”训练的带有周期性步长的LR替代模型,标签匹配率达到84.01%,而普通LR替代模型仅为72.00%;对于SVM“Oracle”,相应的匹配率分别为82.19%和71.56%。蓄水池采样能够减少查询次数,且对替代模型质量影响有限,匹配的标签数介于普通替代模型和带有周期性步长的替代模型之间。例如,逼近SVM“Oracle”时,普通替代模型匹配71.56%的标签,带有周期性步长的替代模型匹配82.19%,带有周期性步长且采用蓄水池采样的替代模型匹配79.20%。
- 与DNN替代模型的比较:LR替代模型具有两个优势。一是其达到渐近匹配率的速度更快,仅需 ρ = 4 \rho = 4 ρ=4 次增强迭代(对应1600次“Oracle”查询),而DNN替代模型通常需要更多迭代次数;二是LR模型的计算成本更低。基于这些优势,在某些特定场景下,LR替代模型可能比DNN替代模型更具应用价值,尤其是在对计算资源和时间要求较高的情况下。
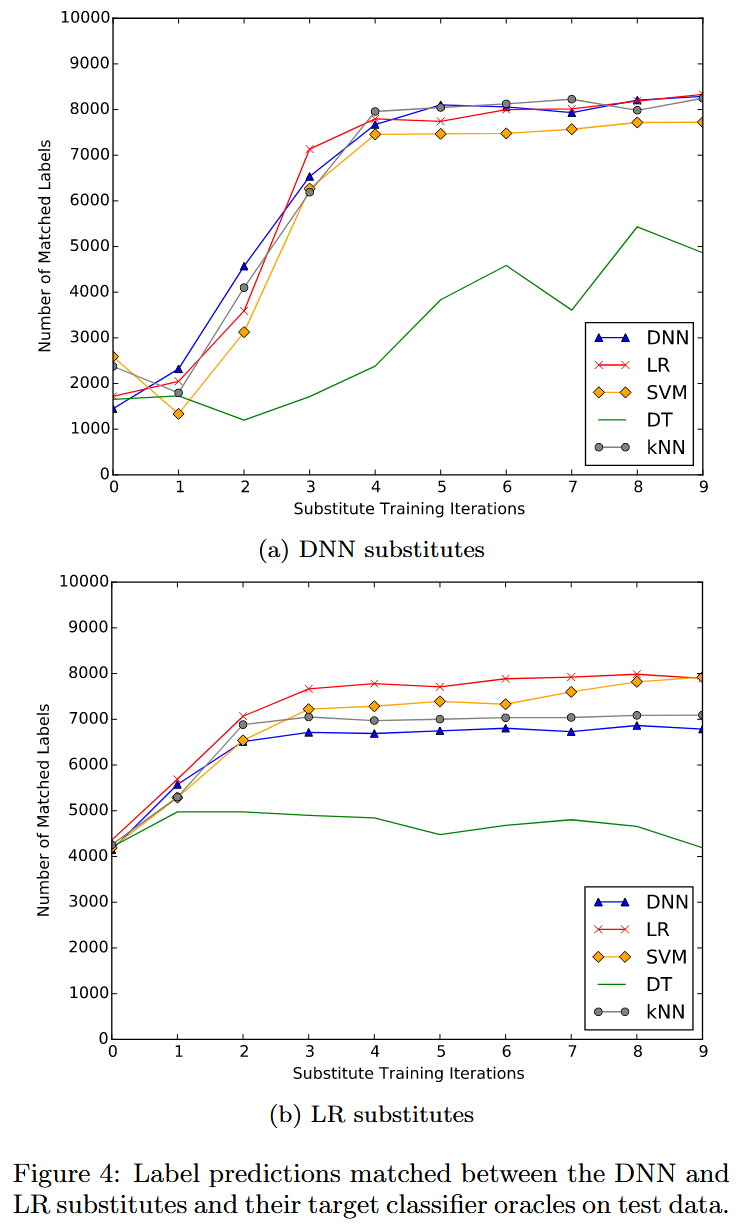
图4:深度神经网络(DNN)和逻辑回归(LR)替代模型与它们的目标分类器“Oracle”在测试数据上的标签匹配情况。
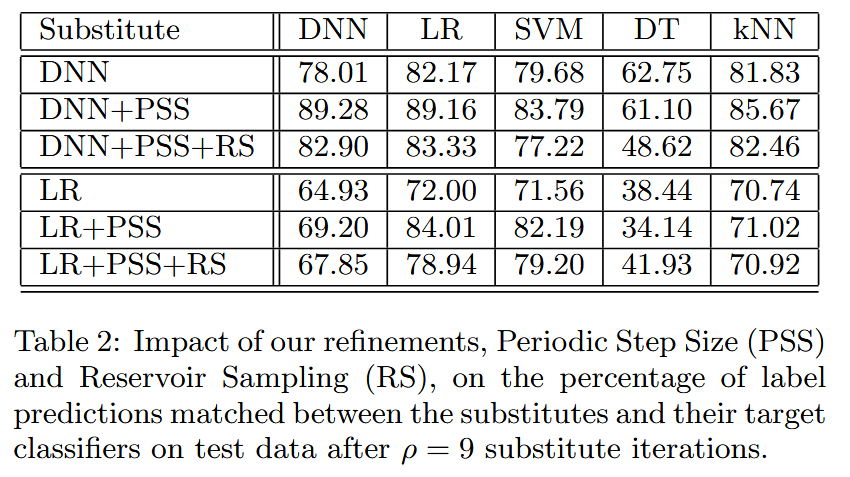
表2:在替代模型迭代
ρ
=
9
\rho = 9
ρ=9 次后,我们所做的改进(周期性步长调整(PSS)和蓄水池采样(RS))对替代模型与目标分类器在测试数据上标签预测匹配百分比的影响。
支持向量机替代模型-Support Vector Machines Substitutes
该部分聚焦于支持向量机(SVM)作为替代模型的可行性研究,主要涵盖新数据集增强技术的提出、实验验证及结果分析,具体内容如下:
- SVM - 基于的数据集增强技术:鉴于SVM生成的对抗样本在跨技术迁移性方面表现突出,使其成为黑盒攻击中替代模型的潜在选择。为训练SVM逼近目标分类器,提出一种类似Jacobian - 基于的数据集增强的新方法。该方法根据SVM的特性,通过公式 S ρ + 1 = { x ⃗ − λ ⋅ w ⃗ [ O ‾ ( x ⃗ ) ] ∥ w ⃗ [ O ‾ ( x ⃗ ) ] ∥ x ⃗ : x ⃗ ∈ S ρ } ∪ S ρ S_{\rho + 1}=\left\{\vec{x}-\lambda \cdot \frac{\vec{w}[\overline{O}(\vec{x})]}{\| \vec{w}[\overline{O}(\vec{x})]\| } \vec{x}: \vec{x} \in S_{\rho}\right\} \cup S_{\rho} Sρ+1={x−λ⋅∥w[O(x)]∥w[O(x)]x:x∈Sρ}∪Sρ 选择新的训练点,在与输入标签对应的二元SVM子分类器的决策边界超平面正交方向上选取新点,且通常将参数 λ \lambda λ 设置为较低值,以在决策边界附近寻找样本。
- 实验验证及结果:重复之前关于DNN和LR替代模型的实验,训练18个不同的SVM模型来匹配分类器标签。实验结果显示,SVM难以通过上述数据集增强技术以及周期性步长和水库采样等改进方法,实现对非SVM目标分类器的知识迁移。例如,SVM替代模型对SVM“Oracle”标签的匹配率为79.80%,但对DNN和LR“Oracle”标签的匹配率仅分别为11.98%和11.97% ,使用改进方法后这些数值也未得到明显提升。这可能是由于SVM训练的特殊性以及其学习的决策边界的独特性质导致的,文章指出未来需要研究其他增强技术来进一步确认这一结论。
- 总结与结论:综合评估DNN、LR和SVM作为替代模型逼近分类器“Oracle”的能力,发现DNN和LR替代模型的预测结果与目标“Oracle”的匹配度更高,而SVM替代模型表现较差。所有实验仅需MNIST测试集中100个样本的知识,表明学习替代模型无需了解目标分类器的类型、参数或训练数据,在现实的对抗威胁模型下是可行的。
远程机器学习分类器的黑盒攻击-Black-box Attacks Of Remote Machine Learning Classifiers
该部分主要介绍了针对远程机器学习分类器的黑盒攻击,通过对亚马逊和谷歌平台的实验,验证了黑盒攻击的可行性,具体内容如下:
- 攻击方法
- 攻击原理:利用对抗样本的同技术和跨技术可迁移性,以及学习分类器替代模型的方法进行攻击。攻击者先在本地训练替代模型来逼近远程分类器,通过向目标分类器(“Oracle”)查询标签获取信息,训练过程采用周期性步长和水库采样优化。之后使用与替代模型对应的对抗样本生成算法,生成能误导替代模型的样本,再利用对抗样本的可迁移性,将这些样本用于攻击远程分类器。
- 攻击场景拓展:此前研究利用深度学习训练替代模型和目标分类器进行攻击,而本文将攻击拓展到使用未知技术的机器学习即服务平台,如亚马逊网络服务和谷歌云预测平台,以验证攻击的通用性。
- 攻击亚马逊Web服务分类器
- 准备工作:在亚马逊机器学习服务平台上,上传MNIST训练集的CSV编码版本(像素值截断为8位小数),选择多类模型类型,保持默认配置训练模型,该模型在MNIST测试集上准确率为92.17% 。激活实时预测功能后,使用Python API提交预测查询。
- 攻击过程与结果:训练DNN和LR两种替代模型,每种模型分别使用普通数据集增强和改进后的增强方法(周期性步长和水库采样)。以使用快速梯度符号法(
ε
=
0.3
\varepsilon = 0.3
ε=0.3)生成的10,000个对抗样本对亚马逊模型进行攻击,测量误分类率。结果显示,使用LR替代模型,经过800次查询(
ρ
=
3
\rho = 3
ρ=3)训练后,攻击亚马逊模型的误分类率达96.19%。原因是亚马逊机器学习服务使用的是“行业标准”多项逻辑回归模型,LR易受同技术和跨技术对抗样本迁移影响。此外,改进方法对DNN替代模型有效,可减少查询次数并提高对抗样本迁移性,对LR替代模型因收敛快无明显积极影响。
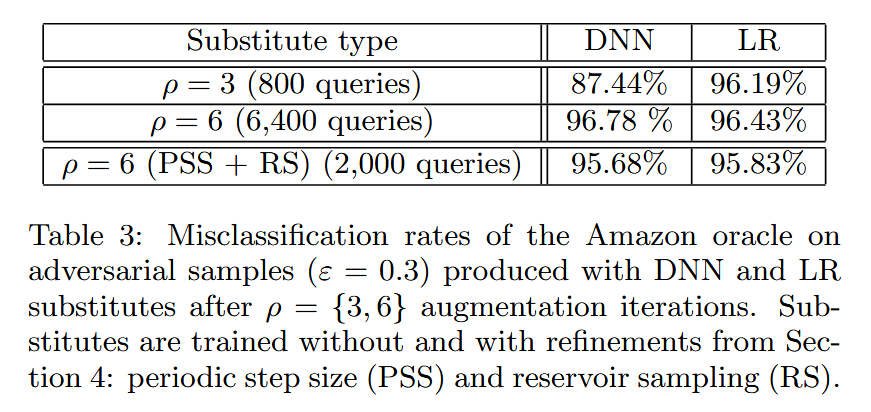
表3:在进行了 ρ = 3 \rho = 3 ρ=3、 6 6 6次增强迭代后,由深度神经网络(DNN)和逻辑回归(LR)替代模型生成的对抗样本( ε = 0.3 \varepsilon = 0.3 ε=0.3)对亚马逊“Oracle”模型造成的误分类率。替代模型分别在不使用以及使用第4节中所述的改进方法(周期性步长(PSS)和水库采样(RS))的情况下进行训练。
- 攻击谷歌云预测分类器
- 准备工作:在谷歌云平台上,上传与亚马逊训练相同的MNIST训练数据CSV文件,激活预测API并训练模型,模型在MNIST测试集上准确率为92%。使用谷歌云Python API连接实验设置与预测API,进行查询。
- 攻击过程与结果:同样训练DNN和LR替代模型及两种变体进行攻击实验。结果表明,谷歌模型对对抗样本有一定抗性,但仍易受攻击,使用LR替代模型,800次查询训练后,误分类率为88.94%。使用改进方法后,DNN替代模型误分类率为91.57%,LR替代模型为97.72%,证明改进方法可减少查询次数并提高误分类率。
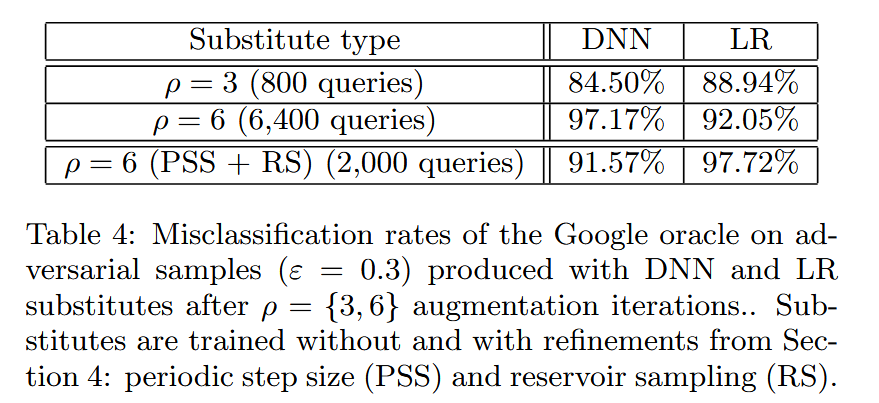
表4:在进行了 ρ = 3 \rho = 3 ρ=3、 6 6 6次增强迭代后,由深度神经网络(DNN)和逻辑回归(LR)替代模型生成的对抗样本( ε = 0.3 \varepsilon = 0.3 ε=0.3)对谷歌“Oracle”模型造成的误分类率。替代模型分别在不使用以及使用第4节中所述的改进方法(周期性步长(PSS)和水库采样(RS))的情况下进行训练。
- 防御措施探讨:尝试将对抗样本添加到MNIST训练集重新训练谷歌模型,新模型在测试集上准确率为91.25%,但新的DNN替代模型生成的对抗样本仍能使新模型高比例误分类( ρ = 3 \rho = 3 ρ=3 时误分类率94.2%, ρ = 6 \rho = 6 ρ=6 时100%),说明此防御无效。可能原因是谷歌预测API使用浅层次技术训练模型,但无法验证。由于无法控制谷歌云的训练过程,无法部署其他防御机制(如防御蒸馏),也无法对其模型安全提出更多建议。
对抗样本制作-Adversarial Sample Crafting
该部分介绍了针对不同机器学习模型的对抗样本构造方法,具体如下:
- 深度神经网络(DNNs):DNN通过多层神经元学习高维输入的层次化表示来完成分类任务。可利用快速梯度符号法构造对抗样本,即计算 δ x ⃗ = ε s g n ( ∇ x ⃗ c ( f , x ⃗ , y ) ) \delta_{\vec{x}}=\varepsilon sgn\left(\nabla_{\vec{x}} c(f, \vec{x}, y)\right) δx=εsgn(∇xc(f,x,y)) ,其中 f f f 是目标DNN, c c c 是相关成本, y y y 是输入的正确标签, ε \varepsilon ε 控制扰动幅度。当构造的对抗样本 x ∗ → = x ⃗ + δ x ⃗ \overrightarrow{x^{*}}=\vec{x}+\delta_{\vec{x}} x∗=x+δx 被模型 f f f 误分类,且扰动 δ x ⃗ \delta_{\vec{x}} δx 难以被人察觉时,对抗样本构造成功。
- 多类逻辑回归:多类逻辑回归将逻辑回归扩展到多分类问题,通过梯度下降或牛顿法学习参数。同样可使用快速梯度符号法构造对抗样本,与DNN不同的是,该方法在逻辑回归中能找到最具破坏性的扰动(依据最大范数)。
- 最近邻:k最近邻(kNN)算法是惰性学习的非参数分类器,本文中 k k k 设为1。使用快速梯度符号法构造对抗样本时,为使模型可微,采用平滑变体,将 a r g m i n argmin argmin 操作替换为 s o f t − m i n soft - min soft−min ,即 f : x ⃗ ↦ [ e − ∥ z ⃗ − x ⃗ ∥ 2 2 ] z ⃗ ∈ X ∑ z ⃗ ∈ X e − ∥ z ⃗ − x ⃗ ∥ 2 2 ⋅ Y f: \vec{x} \mapsto \frac{\left[e^{-\| \vec{z}-\vec{x}\| _{2}^{2}}\right]_{\vec{z} \in X}}{\sum_{\vec{z} \in X} e^{-\| \vec{z}-\vec{x}\| _{2}^{2}}} \cdot Y f:x↦∑z∈Xe−∥z−x∥22[e−∥z−x∥22]z∈X⋅Y.
- 多类支持向量机:多类线性支持向量机采用one - vs - the - rest策略,为每个类别训练一个二元SVM分类器。提出一种新算法,通过在与正确分类的样本对应的二元SVM分类器的权重向量
w
⃗
[
k
]
\vec{w}[k]
w[k]正交的方向上扰动合法样本,构造对抗样本,公式为
x
∗
⃗
=
x
⃗
−
ε
⋅
w
k
⃗
]
∥
w
k
⃗
∥
\vec{x^{*}}=\vec{x}-\varepsilon \cdot \frac{w \vec{k}]}{\left\| \vec{w_{k}}\right\| }
x∗=x−ε⋅∥wk∥wk] ,
ε
\varepsilon
ε 为输入变化参数,控制扰动程度。
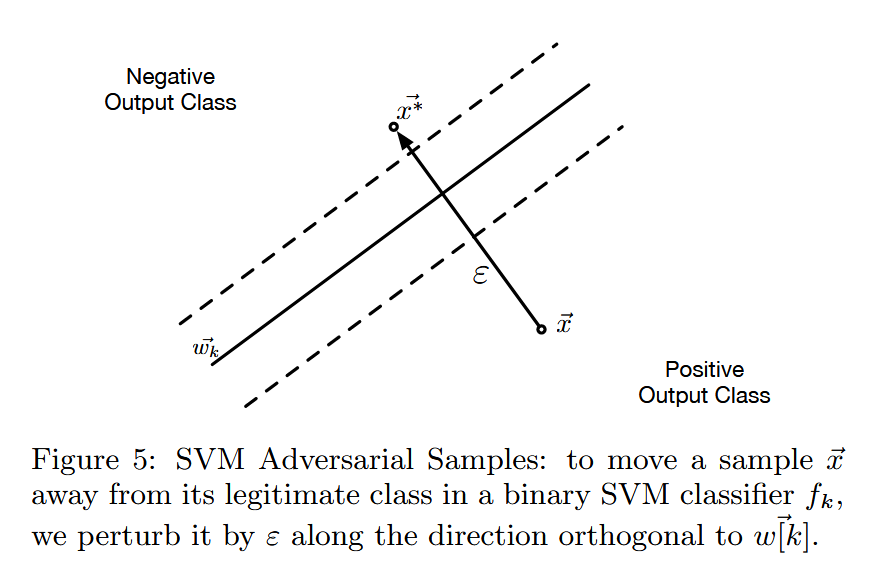
图5:支持向量机对抗样本:在二元支持向量机分类器 f k f_{k} fk 中,为了使样本 x ⃗ \vec{x} x 远离其真实类别,我们沿着与 w [ k ] → w \overrightarrow{[k]} w[k] 正交的方向对其进行 ε \varepsilon ε 大小的扰动。 - 决策树:决策树通过递归划分输入域进行分类。提出一种针对决策树的对抗样本构造算法,利用决策树的结构,寻找与原始预测叶节点附近不同类别的叶节点,根据从原始叶节点到对抗叶节点路径上的条件修改样本,使决策树误分类。算法不明确最小化扰动,但实践中发现扰动涉及的特征比例极小。
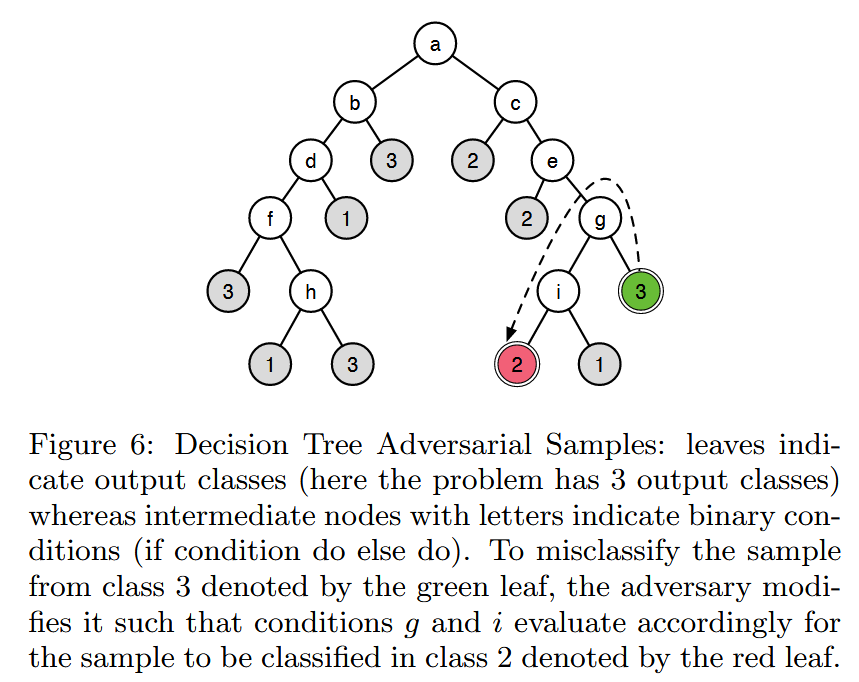
图6:决策树对抗样本:叶节点表示输出类别(在此问题中有3个输出类别),而带有字母的中间节点表示二元条件(即满足条件执行一种操作,不满足执行另一种操作)。为了将绿色叶节点所代表的类别3样本误分类,攻击者对其进行修改,使得条件9和条件 i i i 按相应方式进行评估,从而将该样本分类到红色叶节点所代表的类别2中。

讨论和相关工作-DISCUSSION AND RELATED WORK
该部分主要讨论了机器学习模型易受对抗样本攻击的原因,阐述了本文工作与相关研究的联系与区别,并指出当前防御机制的不足,具体内容如下:
- 机器学习模型易受攻击的原因:机器学习模型在完成训练后对未知输入进行标签预测,其依据是训练过程中从输入-标签对中提取的知识。然而,由于训练算法的不完善、许多模型底层组件的线性特性以及训练数据量有限且可能无法代表整个合理输入域等因素,使得众多机器学习模型在面对对抗样本时存在安全隐患,即便在合法输入上表现良好,也容易受到输入对抗性操纵的影响。
- 本文工作与相关研究的联系:本文工作基于一种针对黑盒深度学习分类器的实用攻击方法展开。通过学习近似目标分类器决策边界的替代模型,缓解了以往攻击中对目标模型架构和参数的依赖。学习替代模型属于知识迁移的范畴,即把一个模型学到的泛化知识迁移到另一个模型中。本文将该方法进行了扩展,使其能够针对任何机器学习分类器,并通过使用逻辑回归训练替代模型以及利用水库采样减少查询次数,降低了计算成本。
- 与其他研究的区别:以往该领域的安全评估工作大多假设攻击者已知模型架构和参数,而本文的威胁模型考虑的是模型部署后,攻击者在测试阶段希望使模型误分类的情况,且攻击者对模型内部信息知之甚少。此外,其他一些威胁模型,如针对已知训练数据的二元SVM中毒攻击和已知基础模型的异常检测系统中毒攻击等,在本文中未涉及,仍有很大研究空间。
- 当前防御机制的不足:本文研究发现,文献中提出的一些防御机制,如用对抗样本训练模型,效果不佳。对于像蒸馏这样的防御方法,由于无法访问目标机器学习模型,本文无法进行部署测试。文章推测这些防御机制失效的原因可能是像亚马逊和谷歌服务中使用的逻辑回归等浅层模型的局限性,但无法证实谷歌模型的具体情况。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











