






完成使用 Gradio 作为前端,Qwen3 作为大模型,vLLM 作为推理引擎来部署一个支持多表查询的 Text2SQL 系统。
系统架构概述
-
Gradio: 提供用户友好的 Web 界面
-
Qwen3: 通义千问的最新开源大模型,擅长文本到SQL转换
-
vLLM: 高效的大模型推理引擎,支持连续批处理和PagedAttention
一、创建数据库表
创建新的数据库并添加三张表(家庭联系表、身体状况表、学生成绩表):
import pymysql
# 替换为你的MySQL root密码
MYSQL_PASSWORD = '12345678'
connection = pymysql.connect(
host='localhost',
user='root',
password=MYSQL_PASSWORD
)
try:
with connection.cursor() as cursor:
# 创建数据库
cursor.execute("CREATE DATABASE IF NOT EXISTS school_system")
cursor.execute("USE school_system")
# 1. 创建家庭联系表
cursor.execute("""
CREATE TABLE IF NOT EXISTS family_contact (
id INT AUTO_INCREMENT PRIMARY KEY,
father_name VARCHAR(50) NOT NULL,
mother_name VARCHAR(50) NOT NULL,
father_phone VARCHAR(20) NOT NULL,
mother_phone VARCHAR(20) NOT NULL
)
""")
# 2. 创建身体状况表
cursor.execute("""
CREATE TABLE IF NOT EXISTS physical_condition (
id INT AUTO_INCREMENT PRIMARY KEY,
height DECIMAL(5,2) COMMENT '身高(cm)',
weight DECIMAL(5,2) COMMENT '体重(kg)',
age INT COMMENT '年龄',
gender ENUM('男','女') NOT NULL,
body_fat DECIMAL(4,2) COMMENT '体脂百分比',
blood_sugar DECIMAL(4,2) COMMENT '血糖(mmol/L)'
)
""")
# 3. 创建学生成绩表
cursor.execute("""
CREATE TABLE IF NOT EXISTS student_score (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
chinese INT COMMENT '语文',
math INT COMMENT '数学',
english INT COMMENT '英语',
physics INT COMMENT '物理',
chemistry INT COMMENT '化学',
biology INT COMMENT '生物',
history INT COMMENT '历史',
geography INT COMMENT '地理',
politics INT COMMENT '政治',
total_score INT COMMENT '总分'
)
""")
# 插入家庭联系表数据
family_data = [
('王强','李梅','13800138000','13900139000'),
('李军','张华','13600136000','13700137000'),
('张勇','陈丽','13500135000','13400134000'),
('陈一刚','周敏','13200132000','13300133000'),
('刘辉','杨娟','13100131000','13000130000'),
('杨明','赵芳','14700147000','14800148000'),
('吴俊','孙燕','14900149000','15000150000'),
('赵刚','钱丽','15100151000','15200152000'),
('孙林','何娜','15300153000','15400154000'),
('周建','徐慧','15500155000','15600156000'),
('郑华','马丽','15700157000','15800158000'),
('冯峰','朱婷','15900159000','16000160000'),
('田军','高敏','16100161000','16200162000'),
('贺伟','郭玲','16300163000','16400164000'),
('钟明','罗霞','16500165000','16600166000'),
('姜云涛','唐瑶','16700167000','16800168000'),
('段勇','谢红','16900169000','17000170000'),
('侯军','卢芳','17100171000','17200172000'),
('袁刚','黄琴','17300173000','17400174000'),
('文辉','吴兰','17500175000','17600176000')
]
cursor.executemany(
"INSERT INTO family_contact (father_name, mother_name, father_phone, mother_phone) VALUES (%s, %s, %s, %s)",
family_data
)
# 插入身体状况表数据
physical_data = [
(175,70,20,'男',18,5.5),
(168,55,19,'女',22,5.2),
(180,75,21,'男',16,5.8),
(172,68,20,'男',17,5.3),
(165,52,18,'女',20,5),
(178,73,22,'男',19,5.6),
(160,50,19,'女',21,5.1),
(173,66,20,'男',18,5.4),
(170,64,21,'男',19,5.7),
(162,53,18,'女',20,5.2),
(176,71,22,'男',18,5.5),
(166,56,19,'女',21,5.3),
(182,78,23,'男',17,5.9),
(174,69,20,'男',18,5.4),
(164,51,18,'女',20,5),
(177,72,21,'男',19,5.6),
(163,54,19,'女',21,5.2),
(171,67,20,'男',18,5.3),
(167,58,18,'女',20,5.1),
(179,74,22,'男',17,5.7)
]
cursor.executemany(
"INSERT INTO physical_condition (height, weight, age, gender, body_fat, blood_sugar) VALUES (%s, %s, %s, %s, %s, %s)",
physical_data
)
# 插入学生成绩表数据
score_data = [
('王小明',85,92,88,78,82,75,80,77,83,790),
('李华',78,89,90,85,88,82,76,84,86,818),
('张敏',90,83,86,91,87,88,82,85,89,841),
('陈刚',82,95,80,88,90,86,83,80,81,825),
('刘芳',76,82,84,79,83,78,75,77,80,774),
('杨威',88,90,82,92,89,87,84,86,85,843),
('吴静',91,86,89,84,85,83,81,88,87,824),
('赵鹏',80,93,81,87,92,84,80,83,82,812),
('孙悦',79,85,87,76,80,77,78,79,81,772),
('周琳',84,88,91,82,86,85,83,84,88,825),
('郑浩',86,91,83,89,88,86,82,85,84,836),
('冯雪',77,84,88,75,81,74,76,78,80,773),
('田甜',92,87,85,90,89,88,84,86,87,848),
('贺磊',81,94,82,86,91,85,81,82,83,815),
('钟莹',78,83,86,79,84,77,75,78,81,771),
('姜涛',87,90,84,91,88,86,83,85,84,838),
('段丽',90,86,89,85,87,84,82,86,88,837),
('侯宇',83,92,81,88,90,87,80,83,82,816),
('袁梦',76,85,88,77,82,76,78,79,80,771),
('文轩',88,91,85,90,89,88,84,86,87,848)
]
cursor.executemany(
"INSERT INTO student_score (name, chinese, math, english, physics, chemistry, biology, history, geography, politics, total_score) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)",
score_data
)
connection.commit()
print("数据库school_system创建成功!三张表及示例数据已初始化完成!")
except Exception as e:
print(f"执行出错: {e}")
finally:
connection.close()
二、模型部署
下载Qwen3模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-1.7B')三、 本地部署Dify
注意:v100显卡会出现不适配,不推荐使用
1. 安装 Docker
ubuntu 22.04 docker 安装&使用_ubuntu22.04 安装docker-CSDN博客
2. 安装vllm
pip install -U xformers torch torchvision torchaudio triton --index-url https://download.pytorch.org/whl/cu121
pip install modelscope vllm
四、创建 text2sql 的 Gradio 应用
如果使用云服务器请先确认暴露端口
以闪电云为例:
sudo apt install rinetd
echo "0.0.0.0 8880 127.0.0.1 9000" > /etc/rinetd.conf
sudo systemctl restart rinetd创建一个 app.py 文件,包含以下内容:
import gradio as gr
import pymysql
from vllm import LLM, SamplingParams
import json
# 数据库配置
DB_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': '12345678',
'database': 'school_system'
}
# vLLM 配置
MODEL_NAME = "/root/.cache/modelscope/hub/models/Qwen/Qwen2.5-1.5B-Instruct" # 根据你实际部署的模型调整
llm = LLM(model=MODEL_NAME)
sampling_params = SamplingParams(temperature=0.1, top_p=0.9, max_tokens=512)
# 数据库连接
def get_db_connection():
return pymysql.connect(**DB_CONFIG)
# 获取数据库 schema 信息
def get_schema_info():
schema_info = []
conn = get_db_connection()
cursor = conn.cursor()
# 获取表信息
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
for table in tables:
table_name = table[0]
# 获取表结构
cursor.execute(f"SHOW CREATE TABLE {table_name}")
create_table = cursor.fetchone()[1]
schema_info.append(f"表 {table_name} 的结构:\n{create_table}\n")
conn.close()
return "\n".join(schema_info)
# 执行 SQL 查询
def execute_sql(sql_query):
try:
conn = get_db_connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_query)
if sql_query.strip().lower().startswith("select"):
result = cursor.fetchall()
else:
conn.commit()
result = {"message": f"执行成功,影响行数: {cursor.rowcount}"}
return result
except Exception as e:
return {"error": f"SQL 执行错误: {str(e)}"}
finally:
conn.close()
# 生成 SQL 查询
def generate_sql(prompt):
schema_info = get_schema_info()
system_prompt = f"""你是一个专业的SQL生成器,请根据以下数据库结构和用户问题生成正确的MySQL查询语句。
数据库结构:
{schema_info}
要求:
1. 只返回SQL语句,不要包含解释或其他内容
2. 确保SQL语法正确
3. 多表查询时使用合适的JOIN语句
4. 使用表名.列名的形式避免歧义
5. 如果用户问题涉及统计计算,使用合适的聚合函数
示例:
问题: 查询所有学生的姓名和数学成绩
回答: SELECT name, math FROM student_score
"""
full_prompt = f"{system_prompt}\n问题: {prompt}\n回答:"
outputs = llm.generate([full_prompt], sampling_params)
generated_sql = outputs[0].outputs[0].text.strip()
# 清理生成的SQL,去除可能的Markdown符号
if generated_sql.startswith("```sql"):
generated_sql = generated_sql[6:-3].strip()
elif generated_sql.startswith("```"):
generated_sql = generated_sql[3:-3].strip()
# 只取第一条SQL语句(遇到换行或"问题:"就截断)
for line in generated_sql.splitlines():
line = line.strip()
if line and not line.startswith("问题:") and not line.startswith("回答:"):
# 只要不是空行、不是"问题:"或"回答:",就返回
return line
# 如果没找到合适的SQL,返回空字符串
return ""
# 处理用户查询
def process_query(user_input):
# 生成SQL
sql_query = generate_sql(user_input)
# 执行SQL
if sql_query:
result = execute_sql(sql_query)
print("SQL:", sql_query)
print("Result:", result)
print("Result type:", type(result))
return sql_query, result
else:
return "未能生成SQL", "请尝试更清晰地描述您的查询需求"
# Gradio 界面
with gr.Blocks() as demo:
gr.Markdown("# 学校管理系统 Text2SQL 查询")
gr.Markdown("使用自然语言查询学生信息、成绩和家庭联系信息")
with gr.Row():
with gr.Column():
user_input = gr.Textbox(label="输入您的问题", placeholder="例如: 查询数学成绩大于90分的男生姓名和母亲电话")
submit_btn = gr.Button("提交")
with gr.Column():
sql_output = gr.Textbox(label="生成的SQL语句")
result_output = gr.JSON(label="查询结果")
submit_btn.click(
process_query,
inputs=user_input,
outputs=[sql_output, result_output]
)
gr.Examples(
examples=[
["查询总分最高的前5名学生姓名和总分"],
["查询身高超过175cm的男生的姓名和数学成绩"],
["查询父母电话相同的学生的姓名"],
["查询体脂率低于20%的女生的姓名、年龄和英语成绩"],
["查询数学成绩高于平均分的学生的姓名、数学成绩和母亲姓名"]
],
inputs=user_input
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=9000)启动应用
python app.py
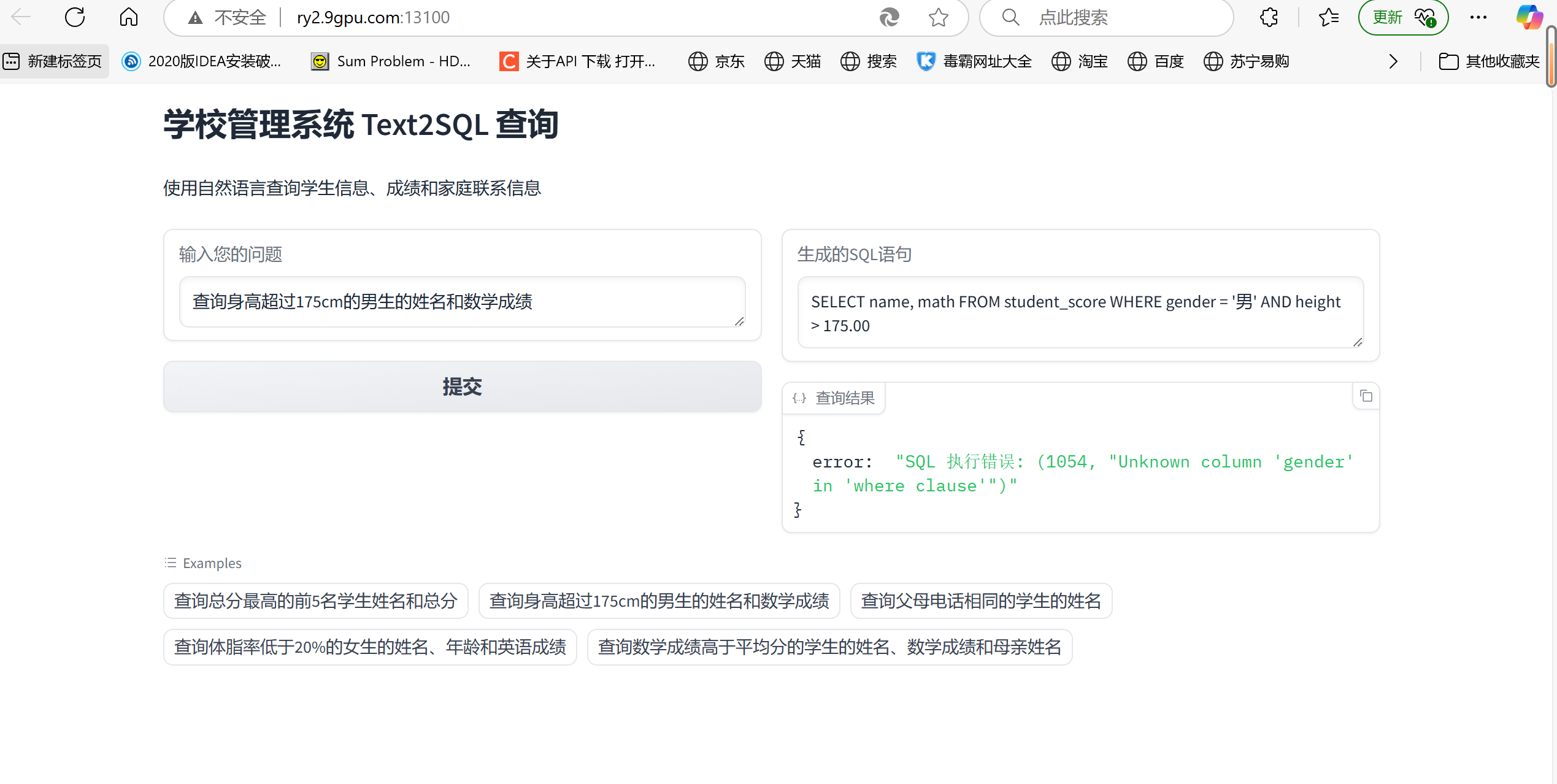
优化后app.py代码:
import gradio as gr
import pymysql
from vllm import LLM, SamplingParams
import json
# 数据库配置
DB_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': '12345678',
'database': 'school_system'
}
# vLLM 配置
MODEL_NAME = "/root/.cache/modelscope/hub/models/Qwen/Qwen2.5-1.5B-Instruct" # 根据你实际部署的模型调整
llm = LLM(model=MODEL_NAME)
sampling_params = SamplingParams(temperature=0.1, top_p=0.9, max_tokens=512)
# 数据库连接
def get_db_connection():
return pymysql.connect(**DB_CONFIG)
# 获取数据库 schema 信息
def get_schema_info():
schema_info = []
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
for table in tables:
table_name = table[0]
cursor.execute(f"SHOW FULL COLUMNS FROM {table_name}")
columns = cursor.fetchall()
schema_info.append(f"表 {table_name} 字段:")
for col in columns:
# col[0]: 字段名, col[1]: 类型, col[8]: 注释
comment = f" -- {col[8]}" if col[8] else ""
schema_info.append(f" - {table_name}.{col[0]}: {col[1]}{comment}")
schema_info.append("") # 空行分隔
conn.close()
return "\n".join(schema_info)
# 执行 SQL 查询
def execute_sql(sql_query):
try:
conn = get_db_connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql_query)
if sql_query.strip().lower().startswith("select"):
result = cursor.fetchall()
else:
conn.commit()
result = {"message": f"执行成功,影响行数: {cursor.rowcount}"}
return result
except Exception as e:
return {"error": f"SQL 执行错误: {str(e)}"}
finally:
conn.close()
# 生成 SQL 查询
def generate_sql(prompt):
schema_info = get_schema_info()
system_prompt = f"""你是一个专业的SQL生成器,请根据以下数据库结构和用户问题生成正确的MySQL查询语句。
数据库结构:
{schema_info}
要求:
1. 只返回SQL语句,不要包含解释或其他内容
2. 确保SQL语法正确
3. 多表查询时使用合适的JOIN语句
4. **所有字段都必须用表名.字段名的形式书写**
5. 如果用户问题涉及统计计算,使用合适的聚合函数
示例:
问题: 查询所有学生的姓名和数学成绩
回答: SELECT student_score.name, student_score.math FROM student_score
问题: 查询身高超过175cm的男生的姓名和数学成绩
回答: SELECT student_score.name, student_score.math FROM student_score JOIN physical_condition ON student_score.id = physical_condition.id WHERE physical_condition.height > 175 AND physical_condition.gender = '男'
"""
full_prompt = f"{system_prompt}\n问题: {prompt}\n回答:"
outputs = llm.generate([full_prompt], sampling_params)
generated_sql = outputs[0].outputs[0].text.strip()
# 清理生成的SQL,去除可能的Markdown符号
if generated_sql.startswith("```sql"):
generated_sql = generated_sql[6:-3].strip()
elif generated_sql.startswith("```"):
generated_sql = generated_sql[3:-3].strip()
# 只取第一条SQL语句(遇到换行或"问题:"就截断)
for line in generated_sql.splitlines():
line = line.strip()
if line and not line.startswith("问题:") and not line.startswith("回答:"):
return line
return ""
# 处理用户查询
def process_query(user_input):
# 生成SQL
sql_query = generate_sql(user_input)
# 执行SQL
if sql_query:
result = execute_sql(sql_query)
print("SQL:", sql_query)
print("Result:", result)
print("Result type:", type(result))
return sql_query, result
else:
return "未能生成SQL", "请尝试更清晰地描述您的查询需求"
# Gradio 界面
with gr.Blocks() as demo:
gr.Markdown("# 学校管理系统 Text2SQL 查询")
gr.Markdown("使用自然语言查询学生信息、成绩和家庭联系信息")
with gr.Row():
with gr.Column():
user_input = gr.Textbox(label="输入您的问题", placeholder="例如: 查询数学成绩大于90分的男生姓名和母亲电话")
submit_btn = gr.Button("提交")
with gr.Column():
sql_output = gr.Textbox(label="生成的SQL语句")
result_output = gr.JSON(label="查询结果")
submit_btn.click(
process_query,
inputs=user_input,
outputs=[sql_output, result_output]
)
gr.Examples(
examples=[
["查询总分最高的前5名学生姓名和总分"],
["查询身高超过175cm的男生的姓名和数学成绩"],
["查询父母电话相同的学生的姓名"],
["查询体脂率低于20%的女生的姓名、年龄和英语成绩"],
["查询数学成绩高于平均分的学生的姓名、数学成绩和母亲姓名"]
],
inputs=user_input
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=9000)

















 63
63

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









