






参考文章:
目录
一、分类型模型评判的指标
在分类型模型评判的指标中,常见的方法有如下三种:
- 混淆矩阵(也称误差矩阵,Confusion Matrix)
- ROC曲线
- AUC面积
1.混淆矩阵
混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。
| 混淆矩阵 | 真实值 | ||
| Positive | Negative | ||
| 预测值 | Positive | TP | FP |
| Negative | FN | TN | |
2.ROC曲线
ROC曲线全称为受试者工作特征曲线(Receiver Operating Characteristic Curve)。虽然听上去很高端,但是ROC其实非常容易理解。一句话说,ROC就是一张图上的曲线,我们通过曲线的形状来判定模型的好坏。
那么要想了解一个曲线代表什么意思,首先最好搞明白曲线的横轴与纵轴分别代表什么。
下图中显示的是两条ROC曲线,一条蓝色,一条红色。他们分别对应两个不同的模型。我们可以看到,图中横轴写着“False positive rate”,纵轴写着“True positive rate”。

3.AUC面积
AUC的英文叫做Area Under Curve,即曲线下的面积,不能再直白。它就是值ROC曲线下的面积是多大。每一条ROC曲线对应一个AUC值。AUC的取值在0与1之间。
AUC = 1,代表ROC曲线在纵轴上,预测完全准确。不管Threshold选什么,预测都是100%正确的。
0.5 < AUC < 1,代表ROC曲线在45度线上方,预测优于50/50的猜测。需要选择合适的阈值后,产出模型。
AUC = 0.5,代表ROC曲线在45度线上,预测等于50/50的猜测。
0 < AUC < 0.5,代表ROC曲线在45度线下方,预测不如50/50的猜测。
AUC = 0,代表ROC曲线在横轴上,预测完全不准确。
二、混淆矩阵简介:
混淆矩阵(Confusion Matrix)是一个二维表格,常用于评价分类模型的性能。
| 混淆矩阵 | 预测值1 | 预测值0 |
| 真实值1 | TP | FN |
| 真实值0 | FP | TN |
其中,TP表示真正例(True Positive),FN表示假反例(False Negative),FP表示假正例(False Positive),TN表示真反例(True Negative)。
- 个人的理解是,混淆矩阵分别从模型预测结果和样本的角度对模型作出了评判:
- 从模型预测结果来看:被预测为xx物体的样本中,有多少真的是这个物体;
- 从样本角度来看:xx样本有多少被模型正确的识别出来。
- 这分别是准确率(Precision)和召回率(Recall)。
混淆矩阵的重要性在于,可以通过计算其中的四个元素,得到各种评价指标,如精确度(Accuracy)、(Sensitivity):就是召回率(Recall)、准确率(Precision)和 F1 值等。
三级指标
这个指标叫做F1 Score。他的计算公式是:

其中,P代表Precision,R代表Recall。
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
三、混淆矩阵的实例
当分类问题是二分问题是,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同样适用。
以下面的混淆矩阵为例:

通过混淆矩阵,我们可以得到如下结论:
Accuracy
在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
以猫为例,我们可以将上面的图合并为二分问题:
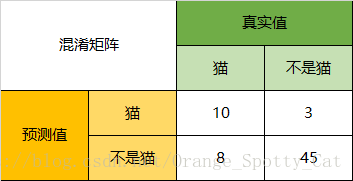
Precision(精确率)
Precision(猫)= 预测正确的猫 / 猫的预测总数=10/13 = 76.9%
Recall(召回率)
Recall(猫)= 识别正确的猫样本 / 猫的样本总数=10/18 = 55.6%
Specificity(灵敏度)
Specificity(猫)=模型认为不是猫的数量 / 实际上不是猫的数量= 45/48 = 93.8%。
F1-Score
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
同样,我们也可以分别计算猪与狗各自的二级指标与三级指标值。
四、混淆矩阵代码实现
confusion_matrix()函数,它是Python中的sklearn库提供的输出矩阵数据的方法:
def confusion_matrix(y_true, y_pred, labels=None, sample_weight=None):
参数意义:
y_true: 是样本真实分类结果,y_pred: 是样本预测分类结果
y_pred:预测结果
labels:是所给出的类别,通过这个可对类别进行选择
sample_weight : 样本权重
1. 直接打印出每一个类别的分类准确率
# 显示混淆矩阵
def plot_confuse(model, x_val, y_val):
# 获得预测结果
predictions = predict(model,x_val)
#获得真实标签
truelabel = y_val.argmax(axis=-1) # 将one-hot转化为label
cm = confusion_matrix(y_true=truelabel, y_pred=predictions)
plt.figure()
# 指定分类类别
classes = range(np.max(truelabel)+1)
title='Confusion matrix'
#混淆矩阵颜色风格
cmap=plt.cm.jet
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
# 按照行和列填写百分比数据
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, '{:.2f}'.format(cm[i, j]), horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
2.打印具体的分类结果的数值
# 显示混淆矩阵
def plot_confuse_data(model, x_val, y_val):
classes = range(0,6)
predictions = predict(model,x_val)
truelabel = y_val.argmax(axis=-1) # 将one-hot转化为label
confusion = confusion_matrix(y_true=truelabel, y_pred=predictions)
#颜色风格为绿。。。。
plt.imshow(confusion, cmap=plt.cm.Greens)
# ticks 坐标轴的坐标点
# label 坐标轴标签说明
indices = range(len(confusion))
# 第一个是迭代对象,表示坐标的显示顺序,第二个参数是坐标轴显示列表
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.title('Confusion matrix')
# plt.rcParams两行是用于解决标签不能显示汉字的问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 显示数据
for first_index in range(len(confusion)): #第几行
for second_index in range(len(confusion[first_index])): #第几列
plt.text(first_index, second_index, confusion[first_index][second_index])
# 显示
plt.show()














 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









