









目标检测评估全解析:从核心指标到高质量测试集构建

目标检测技术在计算机视觉领域发挥着至关重要的作用,无论是自动驾驶、安防监控,还是医学影像处理,目标检测算法的性能评估都需要依赖一系列精确且科学的评估指标。而测试集的构建,更是决定着模型评估的最终效果。本文将详细解析目标检测的核心评估指标、数据集划分的科学方法、测试集构建的原则与质量标准。
一、目标检测的核心评估指标(Core Evaluation Metrics)

1. IoU:检测定位的基石

交并比(Intersection over Union,IoU)是目标检测中最基础的定位度量。它用来衡量预测框与真实框的重叠度,计算公式如下:
I o U = 预测框 ∩ 真实框 预测框 ∪ 真实框 IoU = \frac{{\text{{预测框}} \cap \text{{真实框}}}}{{\text{{预测框}} \cup \text{{真实框}}}} IoU=预测框∪真实框预测框∩真实框
IoU值越高,表示预测框与真实框的重叠部分越多,模型的检测定位越精确。

2. Precision & Recall:精准与覆盖的博弈

从上图可以看出,精度和召回率可以用盲盒抓球来通俗理解:
精度看抓的准不准,召回率看抓的全不全(关于精度下面有更准确直观的解释)
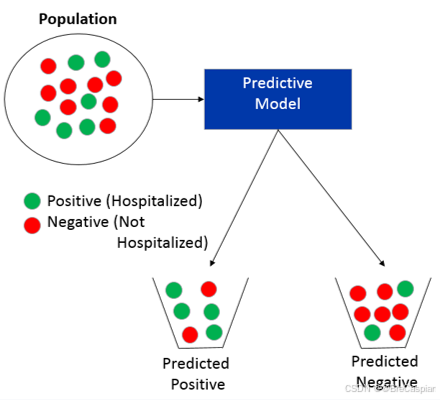
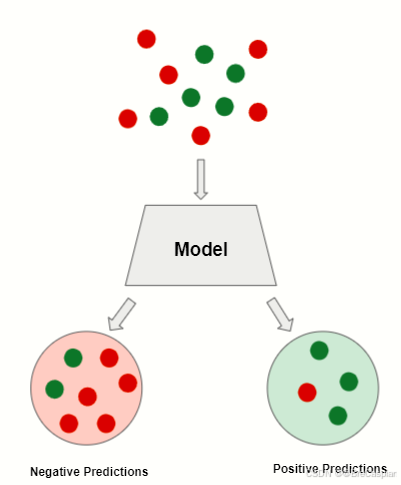

-
精确率 (Precision, P):预测为正样本的准确率,公式为:
P = T P T P + F P P = \frac{{TP}}{{TP + FP}} P=TP+FPTP
其中,TP(True Positives)为真正例,FP(False Positives)为假正例。
-
召回率 (Recall, R):真实正样本的检出覆盖率,公式为:
R = T P T P + F N R = \frac{{TP}}{{TP + FN}} R=TP+FNTP
其中,FN(False Negatives)为假负例。


PR曲线(Precision-Recall Curve) 直观展示了精确率与召回率的动态关系,帮助评估模型在不同阈值下的性能表现。

3. mAP:多维度性能评估
mAP:mean Average Precision,平均精度均值,即AP(Average Precision)的平均值,它是目标检测算法的主要评估指标。目标检测模型通常会用速度和精度(mAP)指标描述优劣,mAP值越高,表明该目标检测模型在给定的数据集上的检测效果越好。
- mAP@50:表示IoU为0.5时的平均精度(Average Precision)。
- mAP@50-95:表示IoU从0.5到0.95(步长为0.05)之间的平均精度,相对于mAP@50更加严格,通常用于更全面的评估。
既然mAP是AP(Average Precision)的平均值,那么首先要了解AP的定义和计算方法。要了解AP的定义,首先需要区别什么是精(Precision),什么是准(Accuracy)?


Trueness (准确性):描述测量值与真实值(参考值)之间的接近程度。换句话说,如果你多次测量同一个对象,所有的测量值都接近真实值,则说明测量系统具有较高的 Trueness即"Accuracy"。
Precision (精密度):描述多个测量值之间的一致性,即多次测量的结果是否接近。一个系统的测量值如果重复性强,分布紧密,则其精密度较高。
了解了Accuracy和Precision便可以计算AP和mAP:


这些指标帮助从多个维度衡量目标检测模型的准确性、召回能力以及综合性能。
二、数据集划分的科学方法(Dataset Splitting Strategies)
数据集划分对于训练和评估一个高效的目标检测模型至关重要。以下是常见的划分比例与策略:
1. 典型划分比例
- 训练集 (Training Set):通常占70%。
- 验证集 (Validation Set):通常占15%。
- 测试集 (Test Set):通常占15%。
2. 数据划分策略对比
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 留出法 (Hold-out) | 简单快速 | 小数据集效果不稳定 | 大数据集(>10万样本) |
| K折交叉验证 (K-Fold CV) | 充分利用数据 | 计算成本高 | 小数据集(<1万样本) |
| 分层抽样 (Stratified Sampling) | 保持类别分布 | 需要详细标注信息 | 类别不均衡数据 |

不同的数据划分方法适用于不同的数据集规模和应用场景。
三、测试集的重要性与构建原则(The Importance of Test Set and Construction Principles)
这里有一个问题需要注意:无论你是否使用K折交叉验证,测试集都是你无法绕过的。使用 K 折交叉验证是对模型的训练集和验证集进行多次的划分,通过多轮训练,模型的每一轮验证集都会用作一次评估,从而为每一轮的模型性能提供评价,最终再求出平均值,帮助你评估模型的表现并调优参数。测试集通常在 K 折交叉验证后的最后阶段用于最终评估模型的泛化性能。
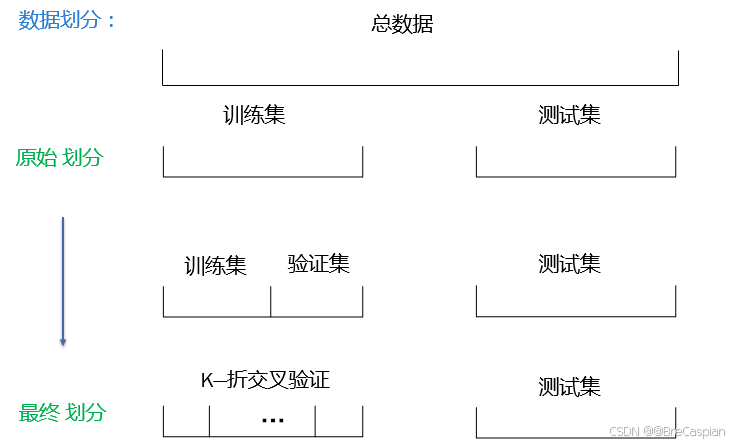
1. 为什么测试集是模型评估的黄金标准?
- 泛化能力检验:测试集是唯一能够反映模型在未知数据上表现的评估集。
- 避免过拟合陷阱:测试集避免模型对训练数据的记忆性学习,从而确保模型具有较好的泛化能力。
- 技术选型依据:测试集为不同模型架构的最终对比提供了基准。
2. 高质量测试集的六大构建原则
构建高质量测试集需要遵循以下六个原则:
- 数据采集 (Data Collection):确保数据来源的多样性与代表性。
- 数据清洗 (Data Cleaning):去除噪声与异常数据,保证数据的质量。
- 专家标注 (Expert Annotation):邀请领域专家进行高质量标注,避免标注误差。
- 多轮校验 (Multi-stage Validation):通过多轮标注验证,确保标注的一致性和准确性。
- 平衡性检查 (Balance Check):确保测试集中各类别样本的均衡性。
- 场景覆盖验证 (Scenario Coverage):保证测试集涵盖了所有可能的应用场景。
3. 测试集质量标准矩阵
| 维度 | 标准要求 | 检测方法 |
|---|---|---|
| 代表性 | 覆盖所有实际应用场景 | 特征分布可视化对比 |
| 多样性 | 包含20+种干扰类型 | 数据增强鲁棒性测试 |
| 平衡性 | 最小类别样本量>100 | 类别分布直方图分析 |
| 标注精度 | 边界框误差<2像素 | 标注一致性检验(Kappa>0.9) |
| 抗干扰能力 | 包含5%对抗样本 | 噪声注入测试 |
| 时效性 | 每季度更新20%内容 | 版本变更记录 |
四、测试集质量问题的诊断与优化(Diagnosing and Improving Test Set Quality)
1. 常见质量问题诊断流程
质量问题可能来自多个方面,如标注错误、样本偏差或场景缺失。典型的诊断流程包括:
- 低mAP -> 原因分析:
- 标注错误:需要进行重新标注。
- 样本偏差:通过数据增强方法来扩展样本。
- 场景缺失:补充遗漏的应用场景。
2. 质量提升四步法
- 标注校准:采用双盲标注和仲裁机制。
- 样本扩充:通过GAN生成困难样本来增强数据集的多样性。
- 分布对齐:使用KL散度(KL Divergence)控制数据分布的差异,确保训练数据与测试数据的一致性。
- 动态更新:建立持续集成(CI/CD)测试平台,确保测试集与时俱进。
五、工业级最佳实践(Industry Best Practices)
1. 多维度评估体系实现
使用Python等工具构建多维度的评估体系,以下是一个基本实现示例:
class DetectionEvaluator:
def __init__(self, dataset):
self.metrics = {
'mAP@50': COCOmAP(iou_thres=0.5),
'mAP@75': COCOmAP(iou_thres=0.75),
'mAP@50-95': COCOmAP(iou_thres=np.arange(0.5, 1.0, 0.05)),
'precision': Precision(conf_thres=0.25),
'recall': Recall(conf_thres=0.25)
}
def evaluate(self, predictions):
return {k: metric(predictions) for k, metric in self.metrics.items()}
2. 典型测试集对比分析
| 数据集 | 样本量 | 类别数 | 标注类型 | 核心优势 |
|---|---|---|---|---|
| COCO2017 | 200,000+ | 80 | 实例分割 (Instance Segmentation) | 多尺度、遮挡场景丰富 |
| PASCAL VOC2012 | 11,530 | 20 | 边界框 (Bounding Box) | 经典基准、标注精准 |
| OpenImages V6 | 9,000,000 | 600 | 层次化标签 (Hierarchical Labels) | 大规模、多样性突出 |
| DOTA-v2 | 11,268 | 18 | 旋转框 (Rotated Box) | 航拍图像、小目标密集 |

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









