






基础知识
基本思想:
- 在候选区域中筛选正样本以及负样本,跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
- 使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。然后将每一个预测框看成一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
候选区域:
1.生成锚框
将原始图片划分成m*n个区域,m和n自取。YOLOv3算法在m*n个区域的中心生成一系列锚框
2.生成预测框
因为锚框大小是固定的,不能刚好和物体边界框重合,所以需要在锚框基础上调整生成预测框。
预测框的中心坐标,其中cx和cy是小方块区域左上角的坐标
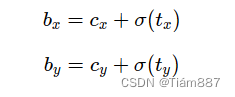
通过下面的公式生成预测框的大小:

Ph和pw是锚框的尺寸,如果参数(tx,ty,tw,th)都等于0,那么预测框与锚框重合
对候选区域进行标注:
锚框的筛选:
- 锚框是否包含物体
- 若是包含了物体,它对应的预测框的中心位置和大小的值(即tx,ty,tw,th)
计算预测框和真实框重合的位置:
将预测框坐标中的bx,by,bh,bw设置为真实框的坐标,即可求解出t的数值
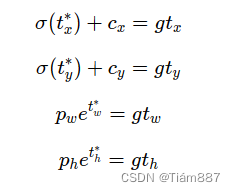
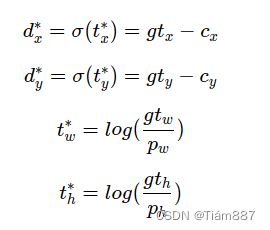
特征提取
通过卷积神经网络提取图像特征。在提取特征的过程中通常会使用步幅大于1的卷积或者池化,导致后面的特征图尺寸越来越小,特征图的步幅等于输入图片尺寸除以特征图尺寸。
多尺度检测(Neck)
如果步幅较大的情况下特征图的尺寸比较小,像素点数目较少,每个像素点的感受野(输出特征图上的每个像素点对应于输入图像上的区域大小。它反映了每个像素点对输入图像的局部信息获取范围。)很大,就比较容易检测到较大的目标。那么为了检测到小目标,就需要在尺寸打的特征图上建立预测输出。若是直接提取可能未经过充分的特征提取,那么就需要通过将高层级的特征图尺寸放大之后跟低层级的特征图进行融合。
检测头设计(计算预测框位置和类别)
预测框本身需要网络输出(5+C)个实数来表证他是否包含物理,位置和形状尺寸以及属于每个类别的概率。如果在每个小方块区域都生成了K个预测框,则所有预测框一共需要输出的预测数目是:[K(5+C)]*m*n
需要将像素点 (i,j)与第i行第j列的小方块区域所需要的预测值关联起来,每个小方块区域产生K个预测框,每个预测框需要 (5+C)个实数预测值,则每个像素点相对应的要有 K(5+C)个实数。为了解决这一问题,对特征图进行多次卷积,并将最终的输出通道数设置为 K(5+C),即可将生成的特征图与每个预测框所需要的预测值巧妙的对应起来。
代码分析

 将卷积层、批归一化层和激活函数封装为一个模块,方便构建和调用
将卷积层、批归一化层和激活函数封装为一个模块,方便构建和调用
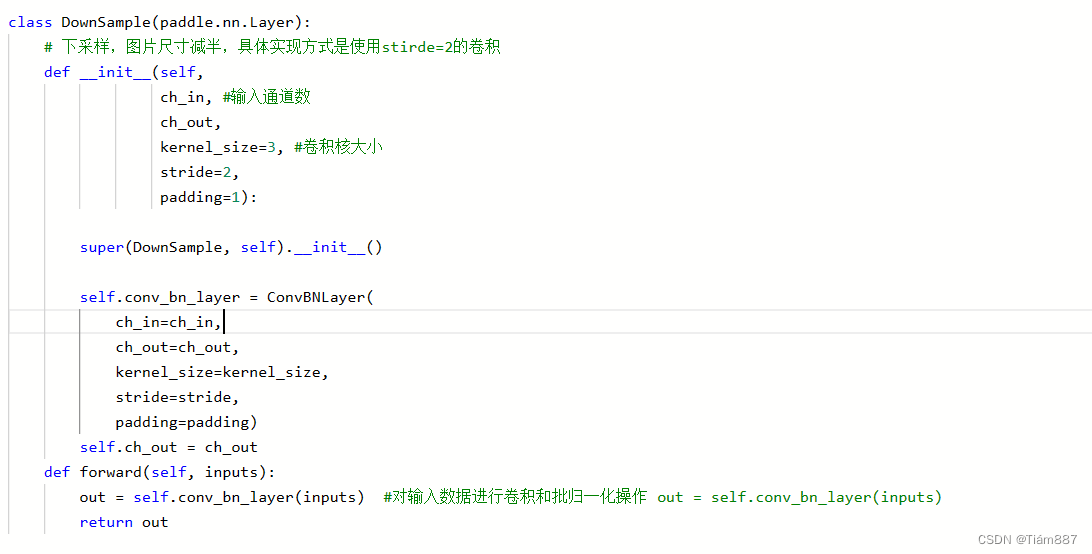
用于实现下采样操作,即将图片的尺寸减半。
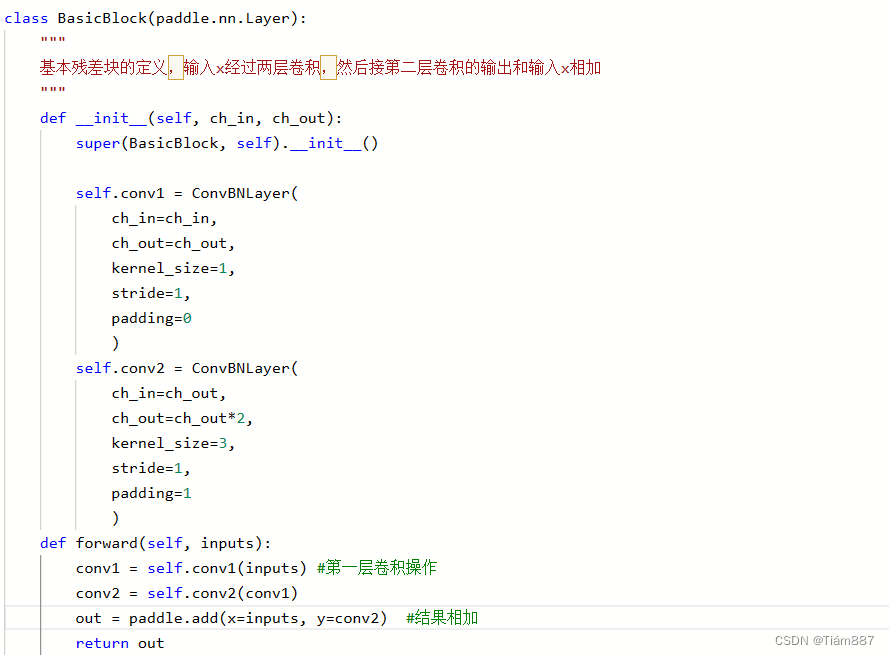
用于实现基本残差块的功能,输入经过两层卷积,然后将第二层卷积的输出与输入相加。

用于添加多层残差块,组成 Darknet53 网络的一个层级。通过添加多个残差块来增加网络的深度和复杂性,从而提高特征的表达能力。
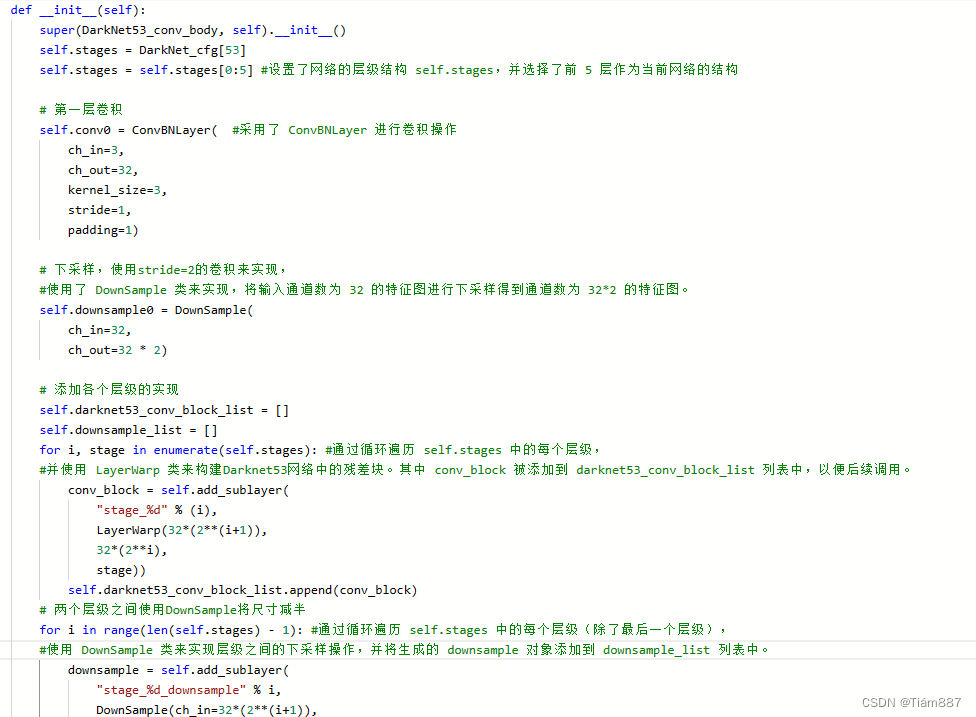
构建了Darknet53网络的卷积部分,包括了多个卷积层和下采样层,同时利用残差块构建了整个Darknet53网络的卷积主体部分。
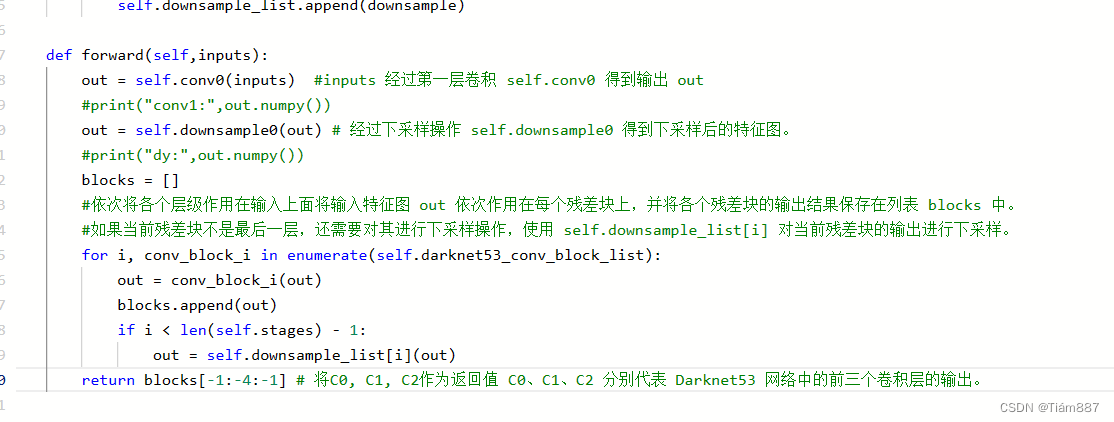
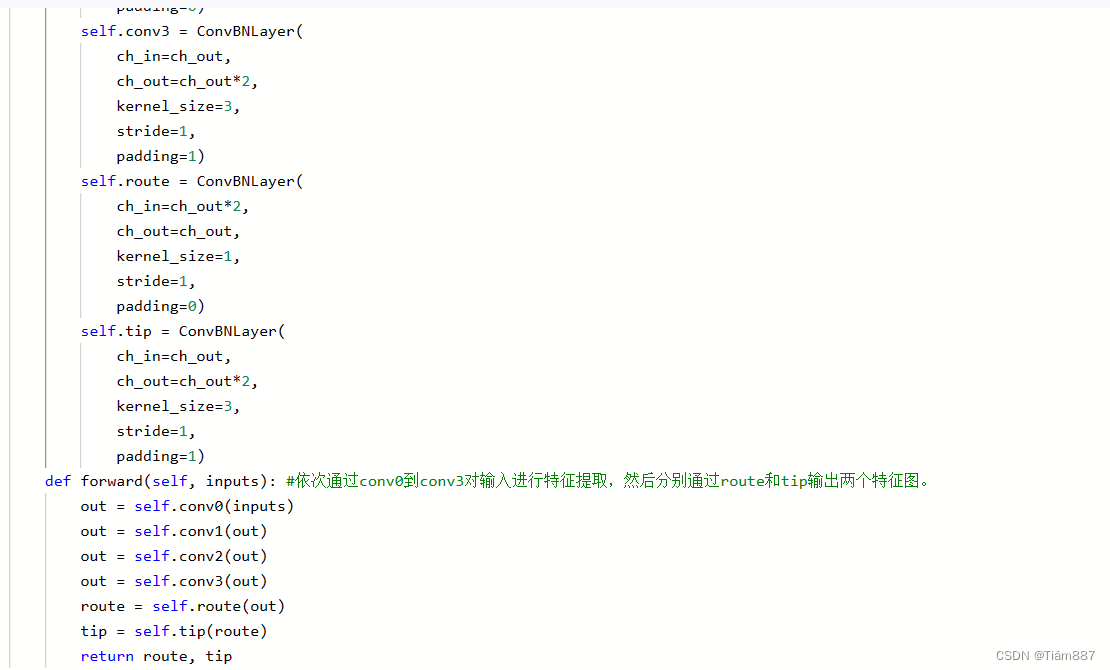
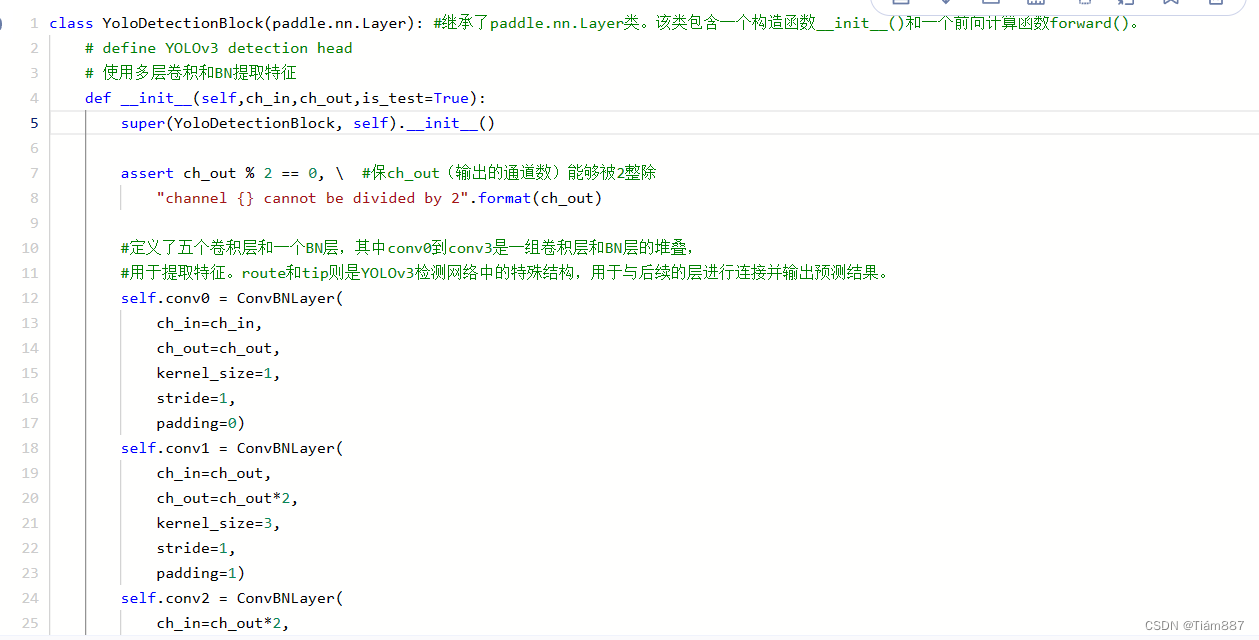
检测头模块实现
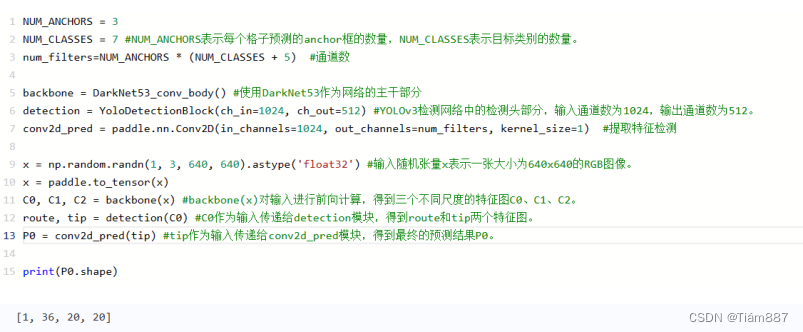
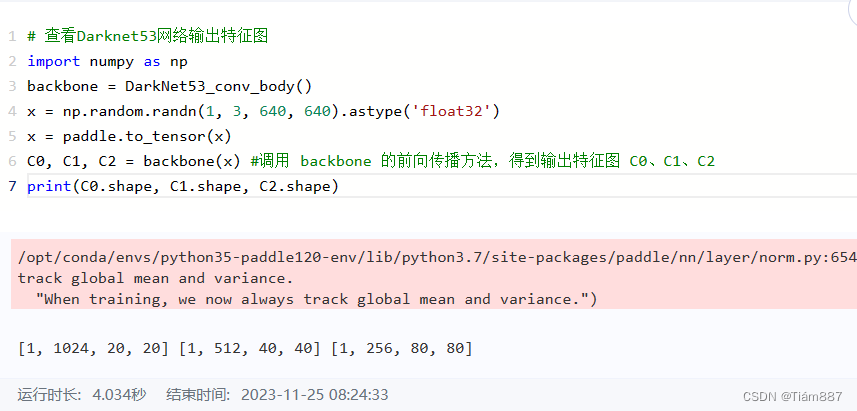
YOLOv3检测网络的搭建过程。由特征图C0生成特征图P0,P0的形状是 [1,36,20,20] 。每个小方块区域生成的锚框或者预测框的数量是3,物体类别数目是7,每个区域需要的预测值个数是 3×(5+7)=36,正好等于P0的输出通道数。
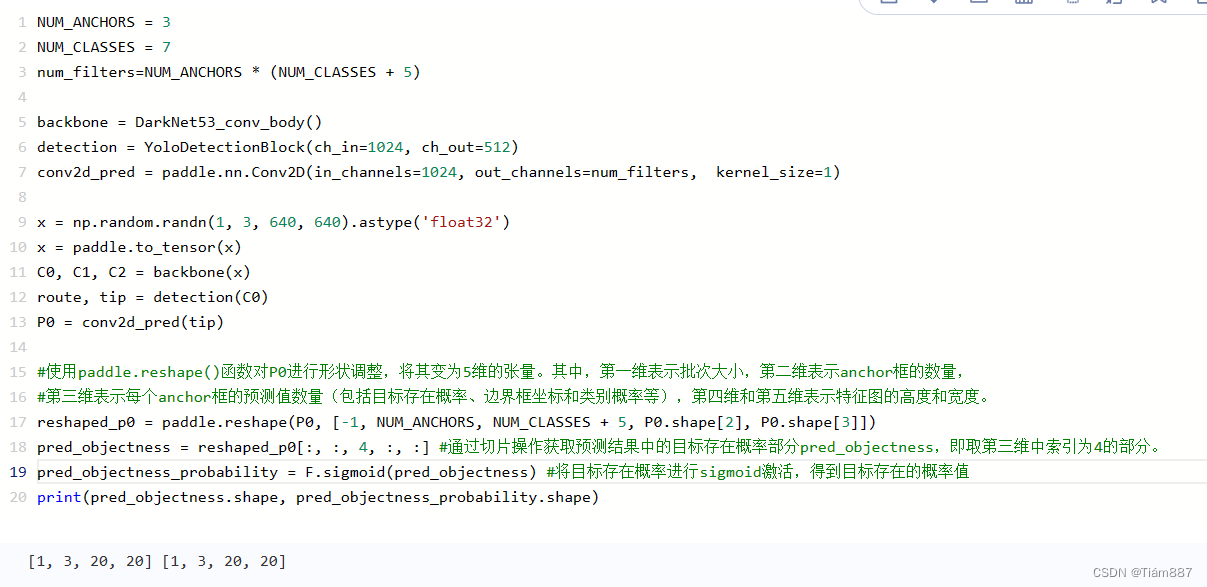
基于上一步,对预测结果P0进行了形状的调整,并计算了目标存在的概率
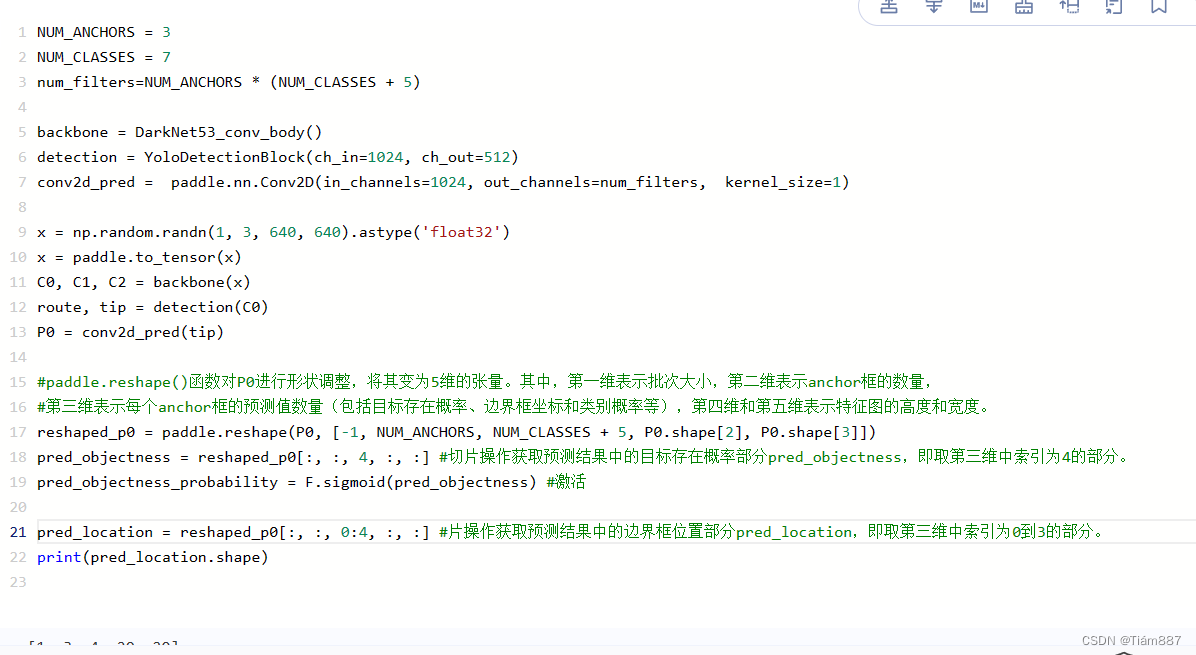
基于上一步,主要是对预测结果P0进行了形状的调整,并计算了目标边界框的位置。

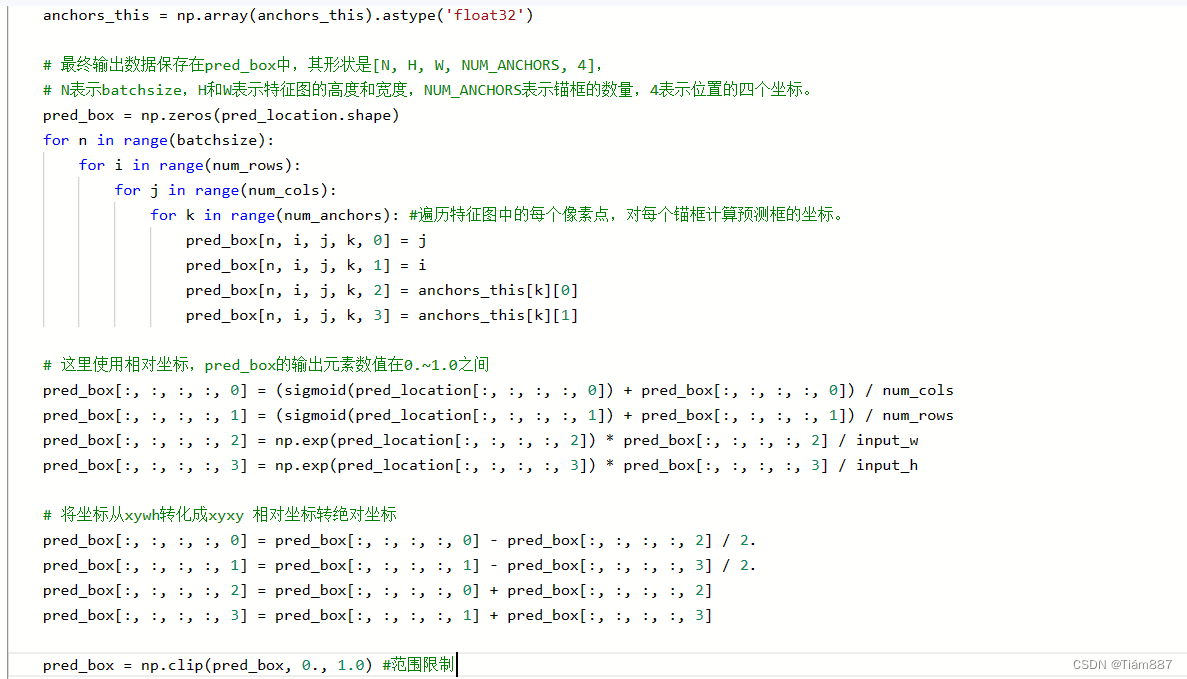
将神经网络输出的特征图转化为预测框的坐标
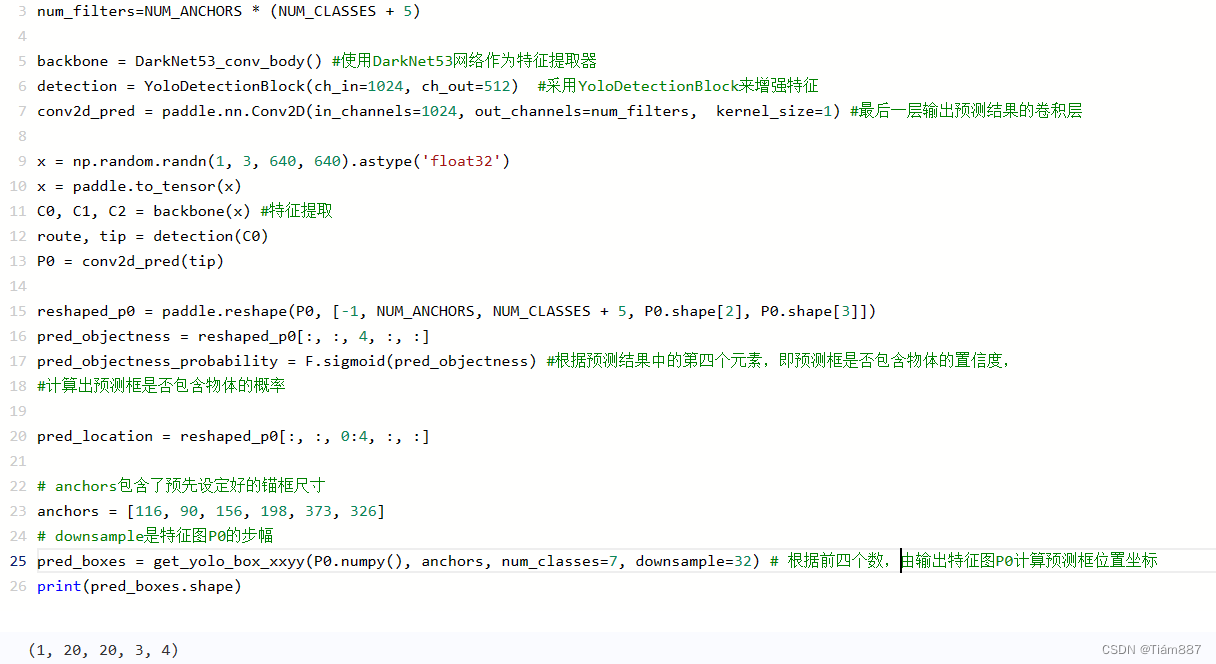

目标检测模型中的预测过程

上采样模块,用于将输入特征图的尺寸放大。

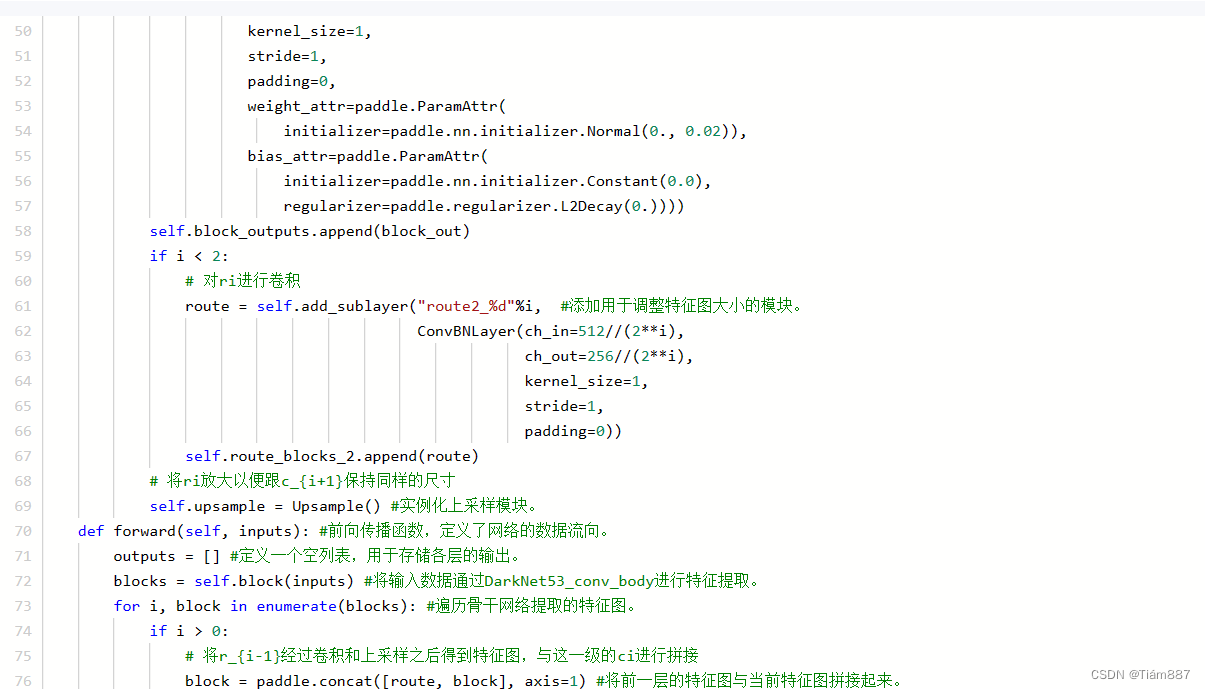
实现了一个完整的YOLOv3模型,包括了特征提取、预测输出以及获取预测结果的功能
实验小结
通过本次实验,我对YOLOv3目标检测算法的设计思想有了更深入的理解。该算法通过将目标检测任务转化为回归问题,并采用多尺度检测策略,能够实现高效准确的目标检测。同时,该算法的网络结构和模块设计也为提取特征、生成预测结果提供了良好的支持。然而,该算法在处理小目标和密集目标时可能存在一定的挑战,需要在实际应用中进一步优化和改进。















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









