







处理的必要
在上一次的博客中,我们写了如何对网站的数据进行爬取。这是其中一篇爬取到的结果:
可以看到,从网站上爬取到的数据虽然全部文本格式的内容,但是很杂乱,很多的地方都多了莫名其妙的空格。所以我们需要对数据进行一定的处理,使文本看起来稍微规范化一些
处理的过程
首先空格是必须要全部删去的,很多地方添加了莫名其妙的空格。
# 去除所有空格和全角空格
text_without_spaces = text.replace(" ", "").replace(" ", "")
通过这段代码几乎就可以把全部的空格给除去了。
然后我们需要将文件号和后面的相关信息进行分行操作,那么怎么进行分行呢?
我们可以发现,每个文本中都详细信息的开头都是“当事人”这个字符串,所以我们可以通过匹配第一个出现的“当事人”字符串然后在它的前面添加换行符来实现。
# 查找第一个出现的 "当事人" 的位置
index = text_without_spaces.find("当事人")
# 插入换行符
if index != -1:
text_end_1 = text_without_spaces[:index] + "\n" + text_without_spaces[index:]
else:
text_end_1 = text_without_spaces
这样以后,我们的处理还是不够的,我们还需要把相关信息和文书正文给分开。具体怎么分呢?
观察发现每个文书正文的开始都有一段字符串“(案件来源、调查经过及采取行政强制措施的情况)”,这段字符串就是我们分开相关信息和正文的核心逻辑!
index_next = text_end_1.find("(案件来源、调查经过及采取行政强制措施的情况)")
if index_next != -1:
text_end_2 = text_end_1[:index_next] + "\n" + text_end_1[index_next:]
else:
text_end_2 = text_end_1
这样就很好的完成了文本的数据处理!
结果如下:
这样看起来就比之前的文本内容好了许多!
自动化的实现
这样处理好单个文本肯定是不够的,现在我们需要对文本进行批量化处理,处理逻辑大致如下:
# 设置2024文件夹路径
folder_path = 'F:/python_code/2024'
# 遍历2024文件夹中的所有txt文件
for filename in os.listdir(folder_path):
if filename.endswith('.txt'):
file_path = os.path.join(folder_path, filename)
# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
# 处理文本
processed_text = process_text(text)
# 将处理后的内容保存回文件或另存为新文件
new_file_path = os.path.join(folder_path, 'processed_' + filename)
with open(new_file_path, 'w', encoding='utf-8') as file:
file.write(processed_text)
print("处理完成。")
循环遍历2024文件夹下的所有txt文件,然后读取文件的内容,
def process_text(text):
# 去除所有空格和全角空格
text_without_spaces = text.replace(" ", "").replace(" ", "")
# 查找第一个出现的 "当事人" 的位置
index = text_without_spaces.find("当事人")
# 插入换行符
if index != -1:
text_end_1 = text_without_spaces[:index] + "\n" + text_without_spaces[index:]
else:
text_end_1 = text_without_spaces
index_next = text_end_1.find("(案件来源、调查经过及采取行政强制措施的情况)")
if index_next != -1:
text_end_2 = text_end_1[:index_next] + "\n" + text_end_1[index_next:]
else:
text_end_2 = text_end_1
return text_end_2
这就是其中调用的process_text函数,
最后将文件保存为'processed_' + filename。
这是对2024文件的处理,然后再依次对2019-2023年的文件进行一次处理即可!
最后的最后,我们可以把2024文件夹中不以‘processed_’开头的文件删除即可
import os
# 设置2024文件夹路径
folder_path = 'F:/python_code/2024'
# 遍历2024文件夹中的所有txt文件
for filename in os.listdir(folder_path):
if filename.endswith('.txt') and not filename.startswith('processed_'):
file_path = os.path.join(folder_path, filename)
os.remove(file_path)
print(f"已删除文件: {filename}")
print("删除完成。")
结果如下: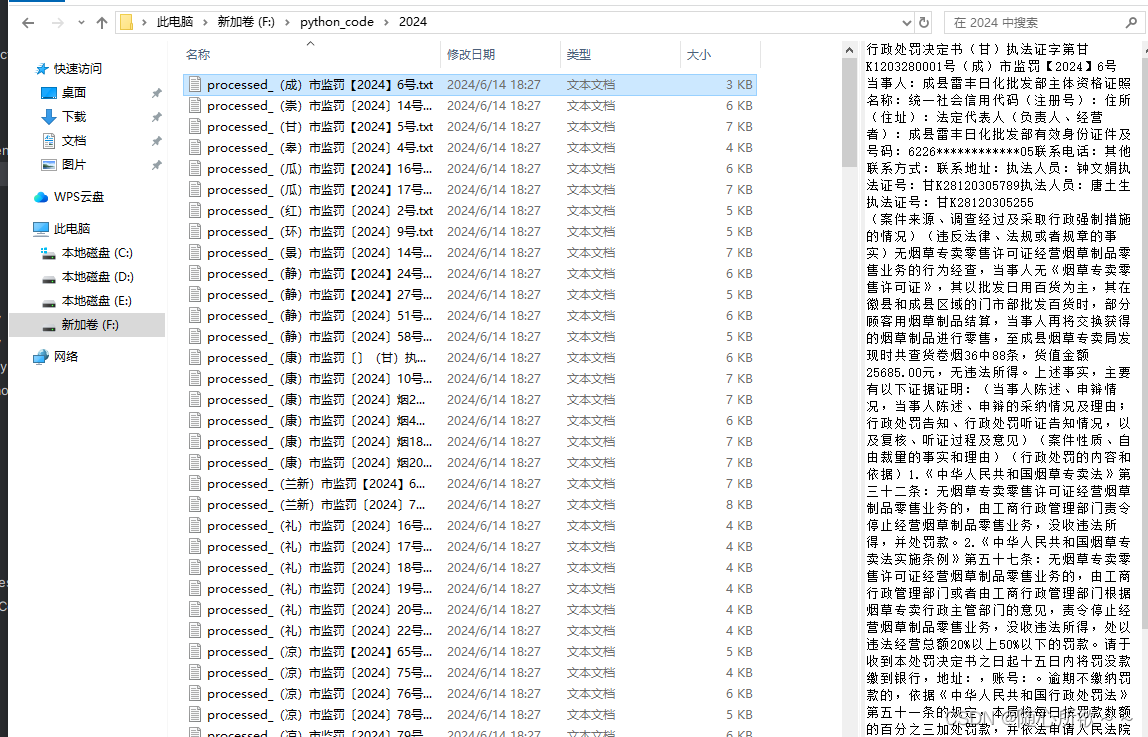

















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









