







题目描述
实验内容与任务 三支足球队A, B, C两两之间各赛一场,总共需要赛三场,分别是A对B, A对C, B对C。对一支球队来说,一场比赛的结果可能是胜、平、负之一。 假设每场比赛的结果以某种概率取决于两队的实力,而球队实力为一个0- 3之间的整数。现已知前两场比赛结果是A战胜了B,A和C战平,请预测最 后一场比赛B对C的结果。
贝叶斯模型
贝叶斯网路
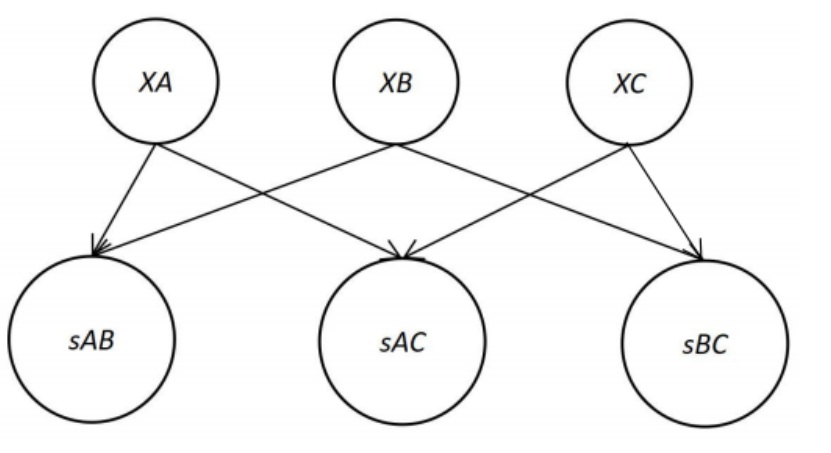
贝叶斯的条件概率表

实验任务
为求P(sBC|sAB = 0, sAC = 1)
精确推理
数学式表达

伪代码思路

初始化 Q(X) 为空。
对于 X 的每个取值 xi,执行以下步骤:
a. 创建扩展 exi,将观测值 e 扩展为 X = xi 的情况。即将已知的前两场比赛结果添加到扩展中,形成 exi。
b. 计算 Enumerate-All(vars, exi) 的具体值,即在给定扩展 exi 的条件下,枚举计算所有变量 vars 的联合概率分布。
c. 将计算得到的值赋给 Q(xi)。
返回 Q(X),即最后一场比赛 B 对 C 的结果的概率分布。
这个算法通过递归地枚举所有变量的取值,并乘以相应的条件概率,计算了在给定扩展 exi 的条件下,所有变量 vars 的联合概率分布。
本次实验中:
- 查询变量X是sBC
- 变量E是sAB和sAC
- 变量E的观测值初始值e是sAB=0,sAC=1
- bn:含有变量vars的贝叶斯网络
- e x i e^{xi} exi :sAB=0,sAC=1,sBC=0
如果变量集合 vars 是空集,则返回 1.0,表示概率为 1。
从 vars 中选择一个变量 V。
如果变量 V 在观测值 e 中有观测值,则将其对应的取值 v 赋给变量 V。
递归调用 Enumerate-All(Rest(vars), e),其中 Rest(vars) 表示去除变量 V 后的剩余变量集合。
1. 如果变量 V 在观测值 e 中有观测值,则返回 P(v | parents(V)) × Enumerate-All(Rest(vars), e)。
2. 如果变量 V 在观测值 e 中没有观测值,则执行以下步骤:
初始化结果总和 sum 为 0。
对于变量 V 的每个可能取值 v,执行以下步骤:
将变量 V 的取值 v 添加到扩展 ex 中。
递归调用 Enumerate-All(Rest(vars), ex),其中 ex 是观测值 e 在 V = v 的扩展。
将递归调用的结果乘以 P(v | parents(V))。
将乘积加到结果总和 sum 中。
返回结果总和 sum。
- XA,XB,XC变量观察值e中没有观察值,需要累加求和。
代码实现
- 由于本次实验较简单,直接采取for循环,没有采用递归

算法复杂度
Enumerate-All(vars, e) 函数的时间复杂度取决于变量集合 vars 的大小和贝叶斯网络的结构。
假设变量集合 vars 包含 n 个变量,贝叶斯网络的结构对于每个变量有固定的父节点集合大小。
在最坏情况下,对于每个变量 V,需要枚举其所有可能的取值。假设变量 V 有 d 个可能的取值。
因此,在递归过程中,每个变量的枚举操作都需要进行 d 次。
考虑递归调用的层数,递归的层数取决于变量集合的大小,即 n。
因此,总的时间复杂度可以表示为 O(d^n)。
本次实验中 vars含有三个变量,n==3 分别是XA,XB,XC。
每个变量V有四个可能的取值。

算法复杂度是O(4^n)
以图形化展示
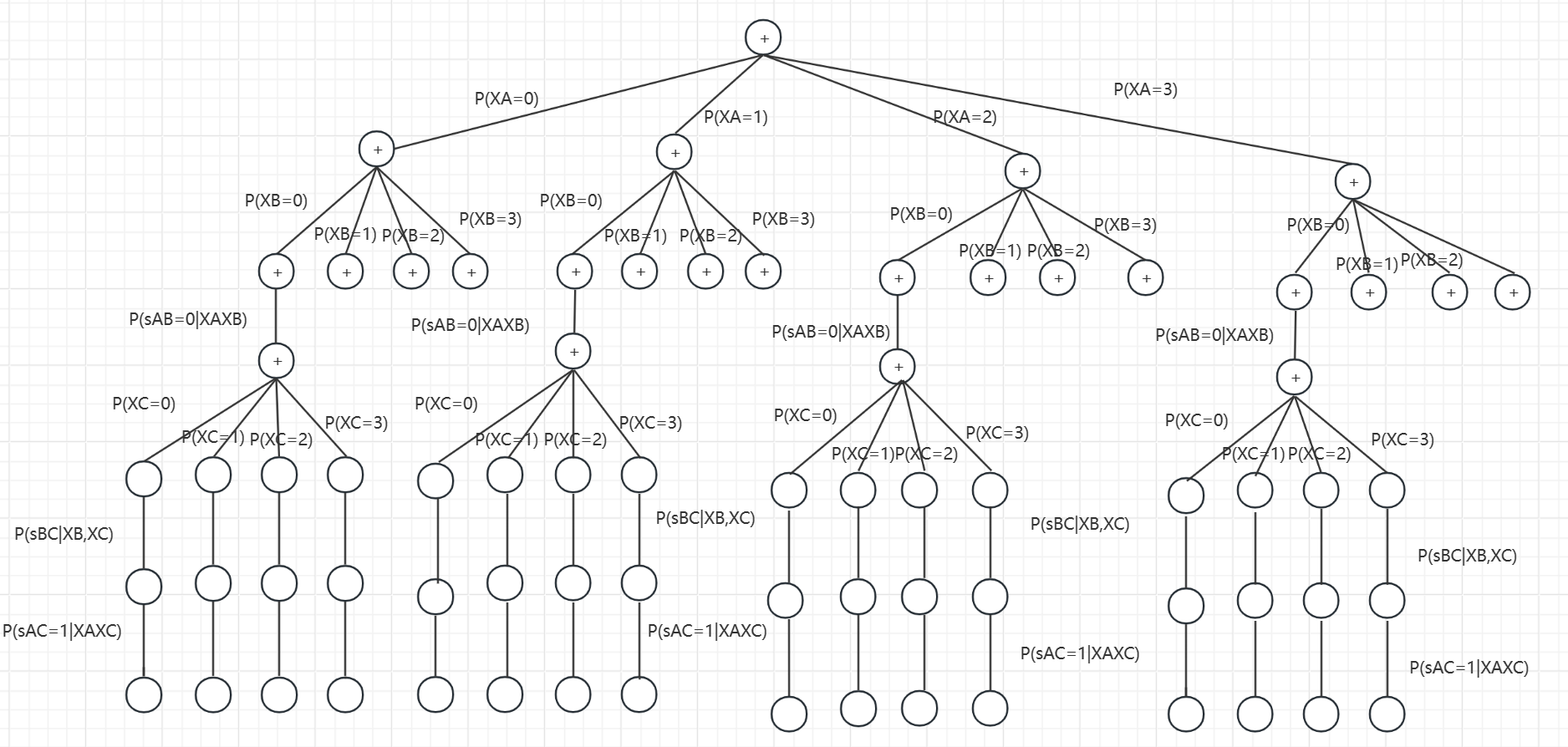
- 可以发现P(sAB=0|XAXB),P(sBC|XB,XC),P(sAC=1|XAXC)计算了多次,大大加大了时间复杂度以及计算量。
运行结果
胜平负:[0.124, 0.284, 0.592]
拒绝采样方法
概念
拒绝采样(rejection sampling)是从给定的易于采样分布中生成难以采样分布样本的通用方法。
拒绝采样方法按贝叶斯网络结点的顺序对所有变量进行采样,获得一个事件。经过N次采样后,对所有采样事件进行统计,获得查询结果。
数学式表达

注:

伪代码思路

- 遍历所有的变量,并且随机选择一个,返回事件X


- 得到的事件x与证据E的观察值对比,如果相等,存入到C
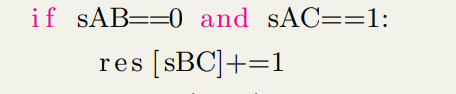
代码实现

算法复杂度
本次实验中算法复杂度是O(n)
拒绝采样的计算复杂度取决于样本数量和拒绝率。
与精确推理的区别
拒绝采样是一种近似采样方法,它通过生成样本并拒绝不符合条件的样本来逼近联合分布的采样。相对于精确解,拒绝采样存在一定的差距。
采样偏差:拒绝采样的结果可能存在采样偏差,即生成的样本并不完全符合联合分布。由于拒绝了一部分样本,采样结果可能无法完全反映真实的联合分布。
拒绝率:拒绝采样中的拒绝率直接影响了采样效率和精度。如果拒绝率较高,意味着很多样本被丢弃,采样效率会降低。为了降低拒绝率,可以调整拒绝常数,但这可能会导致采样结果的偏差增加。
计算复杂度:拒绝采样的计算复杂度取决于样本数量和拒绝率。如果样本数量很大或者拒绝率很高,计算复杂度可能会增加,导致采样时间增加。

















 2642
2642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









