







前言
本文将对kmeans介绍,算法理解,基础操作,手机分类模型,图像切割,半监督算法等实战案例去学习kmeans算法
一、K-means简介
K均值聚类(k-means clustering)是一种常见的无监督机器学习算法,可用于将数据集划分为多个不同的聚类。该算法的基本思想是:将数据集分成k个簇(cluster),每个簇的中心点是簇中所有点的均值。通过迭代的方式不断优化每个簇的中心点,使得同一簇内的点距离中心点最小,不同簇之间的距离最大。
二、算法实现
K均值聚类算法是一种基础的聚类算法。其基本思想是将n个样本分为k个簇,通过最小化每个簇内样本与簇中心的距离来优化簇内的样本分布。该算法的数学实现基于迭代的思想,包括以下几个步骤:
- 初始化:随机选择k个点作为中心点。
- 分配:对于每个样本点,计算其与k个中心点的距离,将其分配到距离最近的中心点所在的簇中。
- 更新:对于每个簇,重新计算其中心点的坐标。
- 重复执行步骤2和3,直到收敛或者达到预定的迭代次数。
三、参数
在开始案例之前,我们先认识几个参数,方便我们学习
from sklearn.cluster import KMeans
KMeans初始化参数:
- n_clusters:指定聚类的个数,即将数据分成几个簇。通常需要根据实际问题和数据特点来确定簇的个数,可以通过经验、调参和可视化等方式来确定。默认值为8。
- init:指定簇中心点的初始化方式。可以选择k-means++(默认值)、random或者自定义。k-means++会优先选择离已有中心点距离较远的点作为新中心点,可以加速算法收敛。random是随机选择初始中心点,速度快但效果可能较差。自定义需要用户手动指定初始中心点。
- n_init:指定算法运行的次数,即从不同的初始中心点开始运行算法,选择最优的一组簇。默认值为10。
- max_iter:指定算法的最大迭代次数。默认值为300。
- tol:指定算法的收敛阈值。当两次迭代的簇中心点之间的距离小于阈值时,认为算法已经收敛,可以停止迭代。默认值为1e-4。
- random_state:指定随机数生成器的种子,用于确定初始中心点的随机选择方式。默认为None,表示使用默认的随机数生成器。
Kmeans常用的方法
- cluster_centers_:表示每个簇的中心点。它是一个二维数组,每行表示一个簇的中心点坐标,其中行数等于聚类数目k。
- labels_:表示每个样本点所属的簇标签。它是一个一维数组,长度等于输入数据的样本数目。labels_[i]表示第i个样本点所属的簇标签。
- transform(X):将数据X转换为新的空间,新空间的每个维度表示该数据点到簇中心点的距离。它返回一个二维数组,每行表示一个样本点到各个簇中心点的距离,其中行数等于输入数据的样本数目。
- inertia_:表示聚类的误差平方和(SSE,Sum of Squared Errors)。它是一个标量,表示所有样本点到其所属簇中心点距离的平方和。inertia_越小,表示聚类效果越好。
- n_iter_:表示KMeans算法迭代的次数。
- score(X):返回数据X的负的平均畸变程度,即数据到其最近的簇中心点的距离的平方和的相反数。越接近0表示聚类效果越好。
四、实战案例
1.手机分类
该数据为不同手机品牌性能,价格,容量等特征值,我们为了方便,只取价格和性能这两个特征值分类
- 数据提取处理
import pandas as pd
import numpy as np
dr=pd.read_csv('python.csv')
dr=pd.DataFrame(dr)
#将co_perf和price改为float类型
dr['co_perf'].astype('float')
dr['price'].astype('float')
#先去除重复多余数据
dr=dr.drop_duplicates(keep='first')
# print(df)
# df=df.drop('model',axis=1)
#判断是否有无穷大的数
# print(np.isfinite(df).any)
"""检测到有无穷大的值对其进行处理"""
dr.replace(np.inf,0,inplace=True)
dr
- 数据观察
import matplotlib.pyplot as plt
import matplotlib
# matplotlib.use('TkAgg')
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X=dr[['co_perf','price']].values.reshape(dr.shape[0],2)
X
plt.plot(X[:,0],X[:,1],'b.')
plt.show()
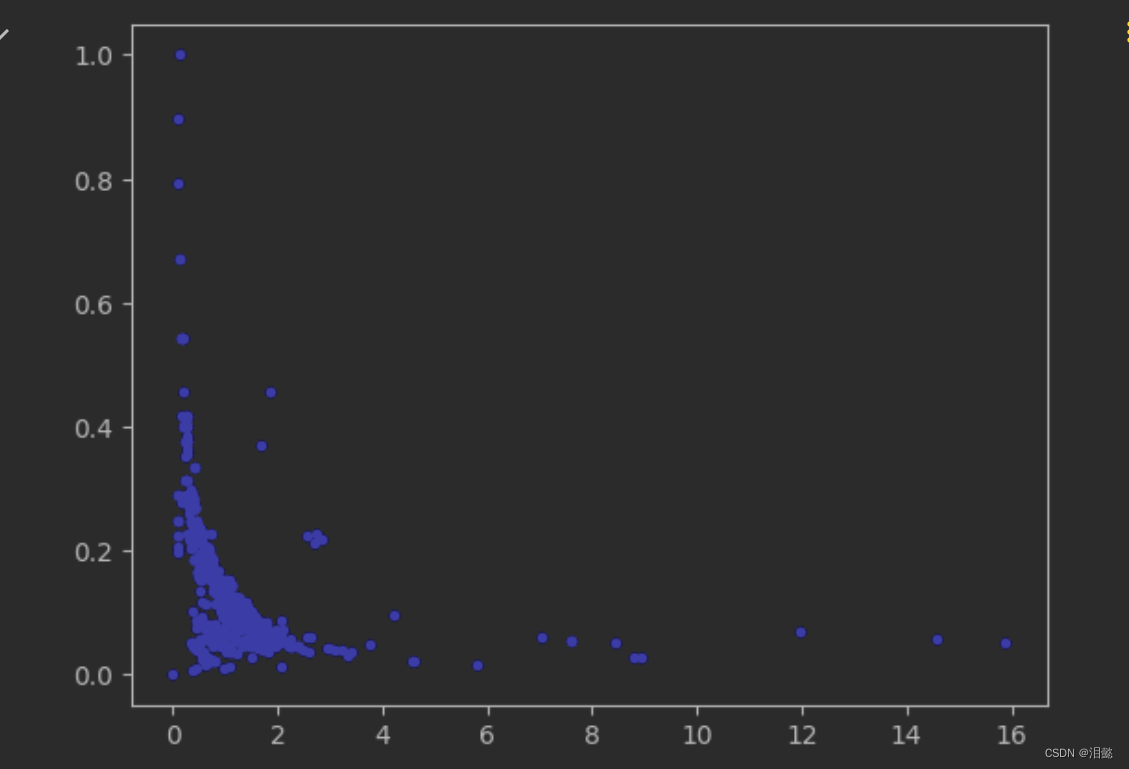
可以观察这个数据大部分是在左下脚那一簇,大致可能分为3到4,这个后面我们可以通过实验观察,到底 n_clusters为多少比较好,另外一个问题两个特征值范围差别比较大,我们标准化一下
from sklearn.preprocessing import StandardScaler
std=StandardScaler()
X=std.fit_transform(X)
- 不同n_clusters的模型训练
现在我们不确定可以选择多少个簇,我们可以通过不同的尝试,得到不同的score分数,看如何选择一个较好的簇的数量
def plt_modal(modal,n_cluster):
#绘制簇中心
centiods=modal.cluster_centers_
plt.scatter(centiods[0],centiods[1],marker='X',c='red',linewidths=0.2)
labels=modal.labels_
plt.scatter(X[:,0],X[:,1],c=labels,s=4,alpha=0.3)
plt.title(f'n_cluster:{n_cluster}')
n_clusterses=(2,3,4,5,6,7,8,9,10)
modal_sorces=[]
for i,n_clusters in enumerate(n_clusterses):
modal=KMeans(n_clusters=n_clusters)
modal.fit(X)
plt.subplot(331+i)
plt_modal(modal,n_clusters)
modal_sorces.append(modal.score(X))
plt.show()
plt.plot(range(2,11),modal_sorces)
plt.show()
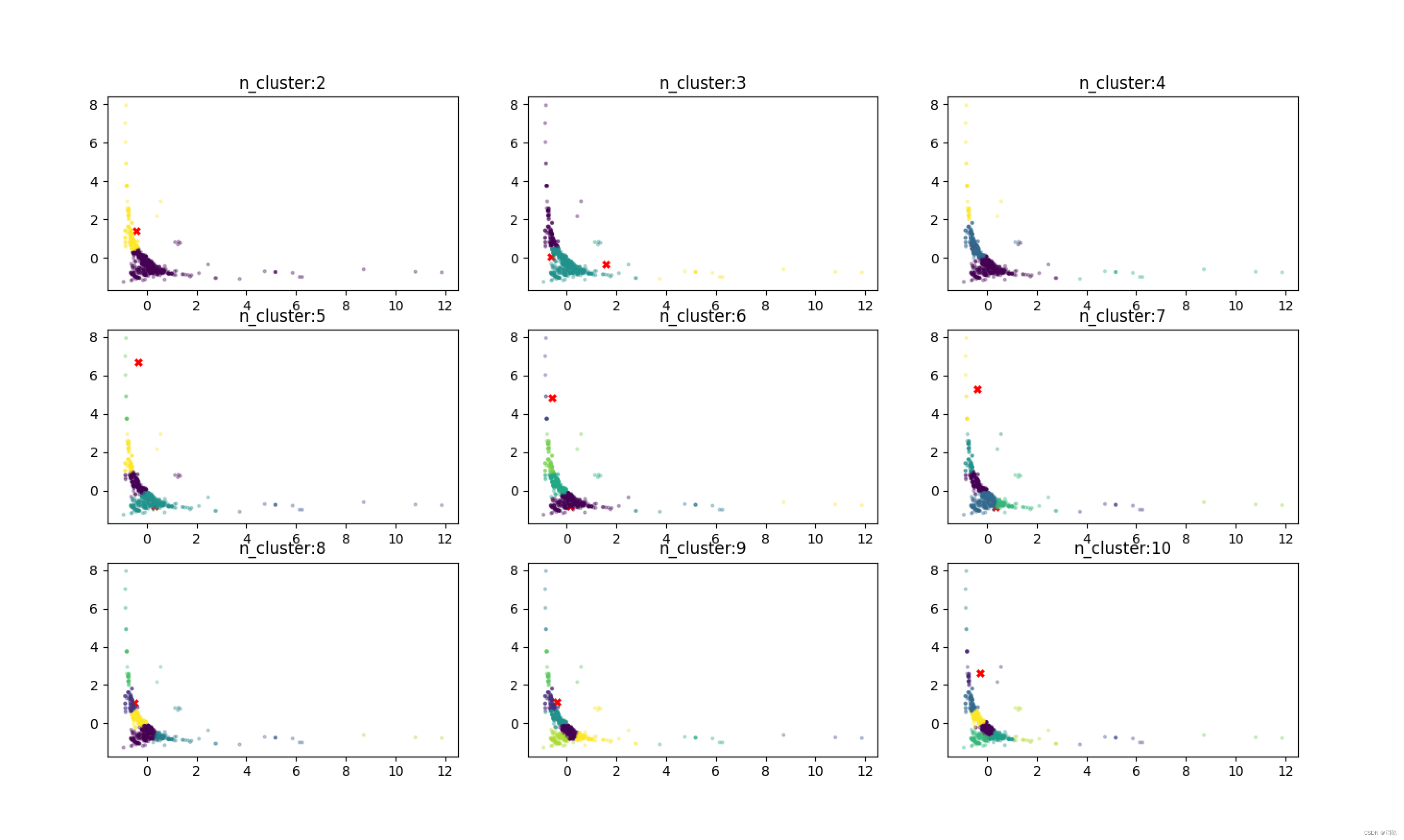
这个图是不同簇数量的分类情况

这个图是不同簇类score方法的得分情况,KMeans模型的score方法返回数据集X的平均畸变程度的相反数。畸变程度指的是每个样本点到它所属簇中心点的距离的平方。畸变程度越小,说明聚类效果越好。因此,score的值越接近0,说明聚类效果越好。
一般来说,我们在使用KMeans聚类算法时,会尝试不同的聚类数目,然后选择score最小的聚类数目。这是因为随着聚类数目的增加,模型可以更好地拟合数据,畸变程度也会逐渐降低。但当聚类数目增加到一定程度时,模型的拟合能力会降低,畸变程度也会开始增加,这时我们就需要在拟合能力和简洁性之间寻找平衡,选择score最小的聚类数目作为最终模型的聚类数目。
如果单单从score看的话,可能会分成10以上的类别,但也不是越大越好,对于手机的分类,一般我们可以分成这样4类
高价低配
低价高配
高价高配
低价低配
为此我们可以吧n_clusters=4去观察情况
modal=KMeans(n_clusters=4,random_state=42)
modal.fit(X)
#%%
dr['label']=modal.labels_
centrids=modal.cluster_centers_
for i,centrid in enumerate(centrids):
plt.scatter(x=dr['co_perf'][dr.label==i],
y=dr['price'][dr.label==i]
,s=8,label=i)
# #
plt.xlabel('co_perf')
plt.ylabel('price')
plt.legend()
plt.show()
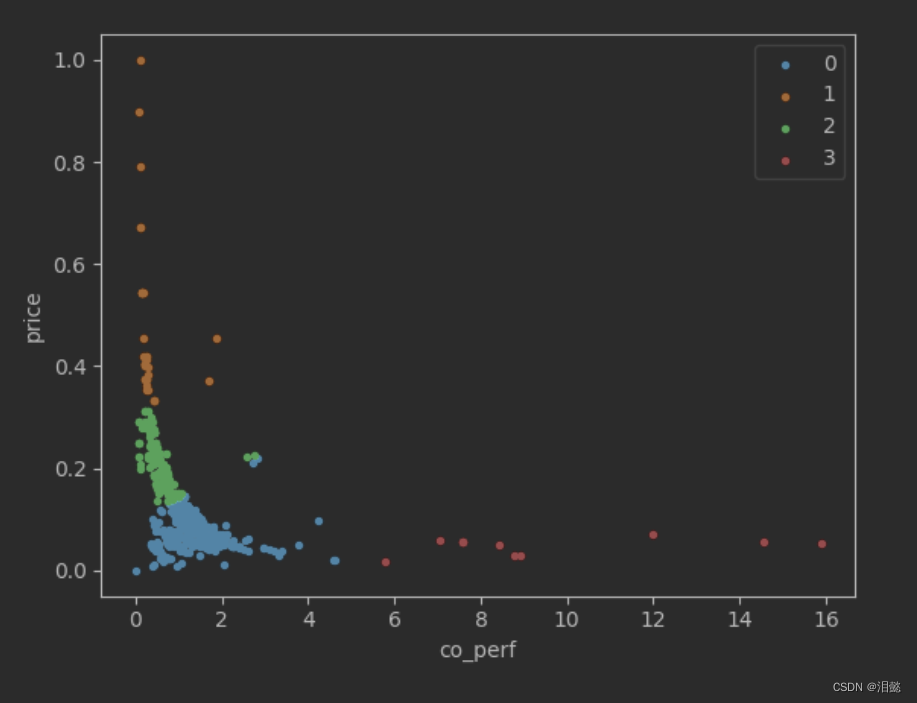
从图中我们看到价格和性能能相匹配的还是占大部分,我们打印观察一下
0类就是低价低配
1类就是高价低配
2类也有点低价低配或者高价高配的感觉,不好评估
3类就是妥妥的低价高配
可能数据来源问题,好像高价高配的没有欸
- 观察评估
我们主要观察一下那些性价比比较高和一些高价低配的,我们先看一下性价比之光有哪些
print(dr['price'].describe())
print(dr['co_perf'].describe())
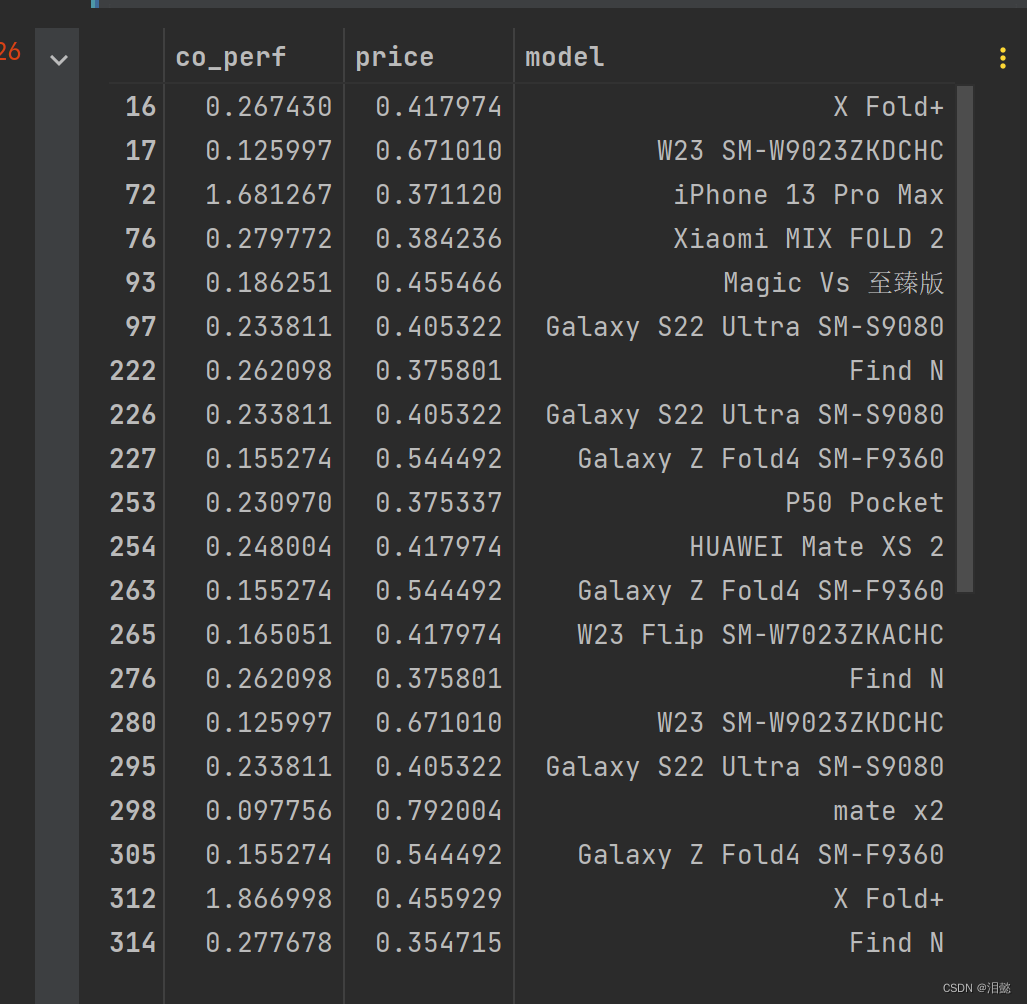
modalist=dr[['co_perf','price','model']][dr.label==3]
modalist
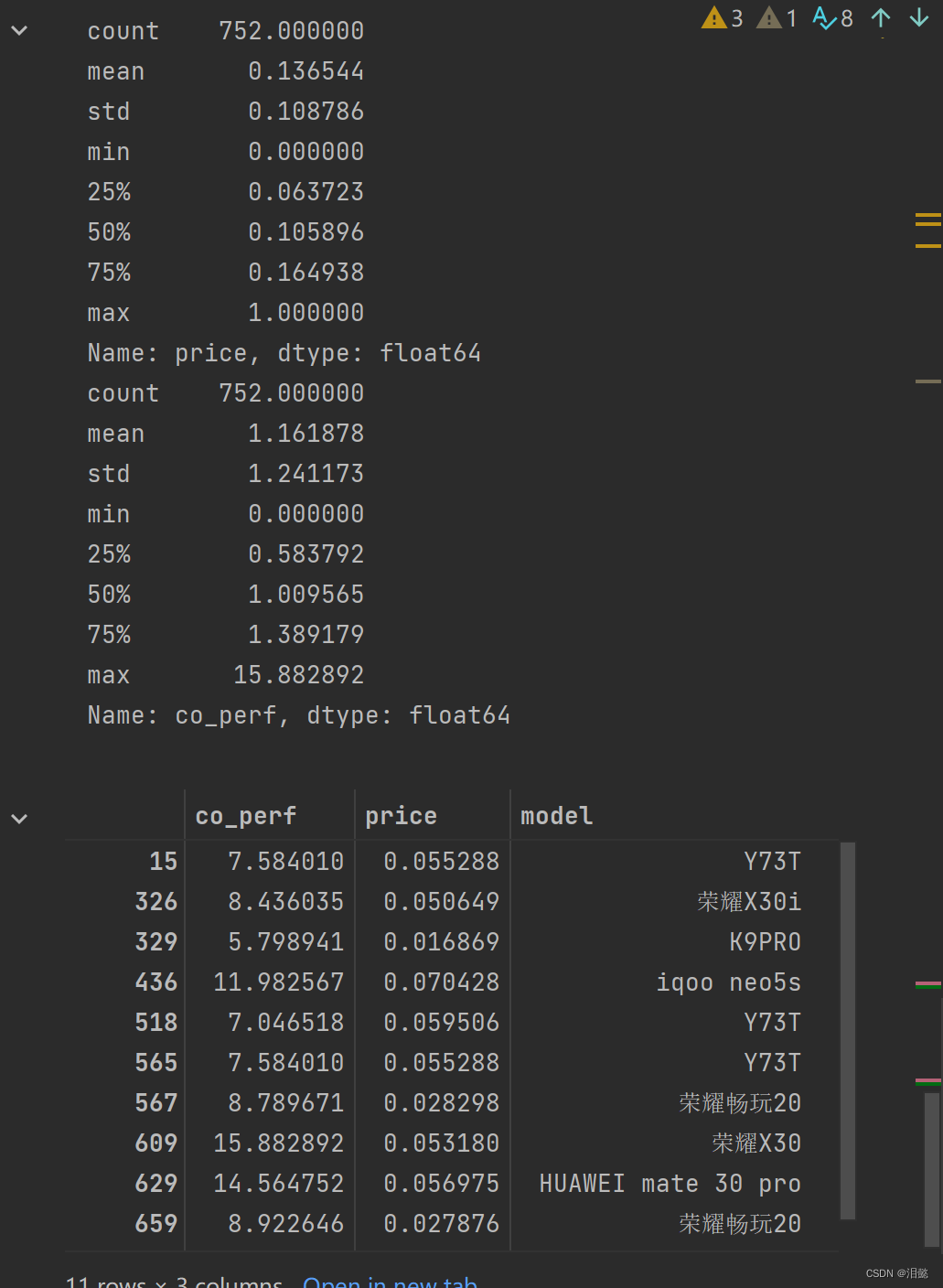
由于我没用过这些手机,不知道是否高价低配,但是如果从平均数据看,还是有点信服力。
我们再看看高价低配的有哪些
modalist=dr[['co_perf','price','model']][dr.label==1]
modalist
最后我们统计一下各类别的品牌数量
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False#用来正常显示负号
def plt_show(X,y,i):
print(X)
print(y)
plt.pie(X,labels=y)
plt.title(f'{i}类别')
plt.subplots_adjust(left=0.01)#控制子图间距
for i in range(4):
data=dr[dr['label']==i].brand.value_counts().to_dict()
plt.subplot(221+i)
plt_show(list(data.values()),list(data.keys()),i)
plt.show()
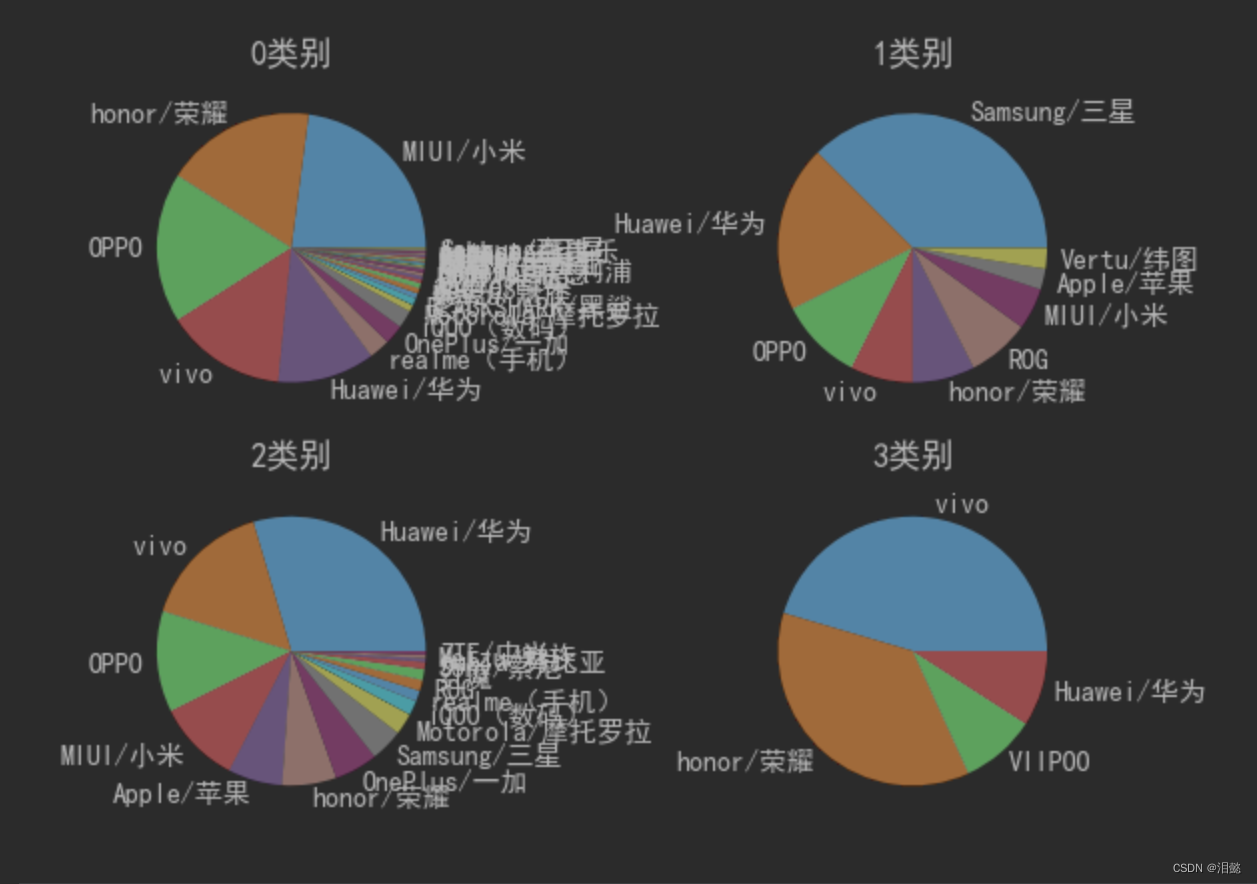
上面的结果由于数据来源以及性能评分来源未知,仅参考方法就行
2.图像分割
K均值聚类算法可以将图像中的像素点分为不同的簇,从而实现图像分割
- 数据准备
一张我在大观楼拍的湖景照片
import numpy as np
import os
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from matplotlib.image import imread
plt.rcParams['axes.labelsize']=14
plt.rcParams['xtick.labelsize']=12
plt.rcParams['ytick.labelsize']=12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(24)
#%%
image=imread('2.jpg')
plt.imshow(image,cmap=None)
plt.show()

查看shape
image.shape
(3000, 4000, 3)
表示(高度,宽度,颜色通道数)
为了方便计算,我们需要重塑图像将图像转换为一个NumPy数组,方便后面我们的机器学习
X=image.reshape(-1,3)
X.shape
但是发现图片尺寸太大,这里我们需要对图片进行缩小,不然后面机器学习中运行时间太长(体验过)
from PIL import Image
image=Image.open('2.jpg')
width,heght=image.size
rate=0.1
image=image.resize((int(width*rate),int(heght*rate)))
plt.imshow(image,cmap=None)
plt.show()
image.size
image.save('new.png')
- 图像处理
我们的图像有多种颜色构成的, kmeans聚类就是将有相关的的颜色区域分类
我们选择颜色数量也可以说是簇数量,进行训练与可视化比较 ( 256 , 128 , 64 , 32 , 16 , 8 , 4 , 2 ) (256,128,64,32,16,8,4,2) (256,128,64,32,16,8,4,2)
from sklearn.cluster import KMeans
image=imread('./new.png')
X=image.reshape(-1,3)
n_colors=(256,128,64,32,16,8,4,2)
images_=[]
for colors in n_colors:
kmeans=KMeans(n_clusters=colors,random_state=42,init='random')
kmeans.fit(X)
segemented_img=kmeans.cluster_centers_[kmeans.labels_]
images_.append(segemented_img.reshape(image.shape))
plt.figure(figsize=(10,6))
plt.subplot(331)
plt.imshow(image)
plt.title('original image')
for idx,n_cluster in enumerate(images_):
plt.subplot(332+idx)
plt.imshow(images_[idx])
plt.title('{}cloros'.format(n_colors[idx]))
plt.show()

颜色数量从256到2,大家可以明显看到还是切割的很成功。
五、kmeans半监督学习实现
半监督学习是指使用有标签和无标签的数据进行学习的一种机器学习方法,常用于在数据集中标记较少的情况下提高模型的准确性。在kmeans聚类算法中,也可以使用半监督学习的方法来提高聚类的准确性也可以提高标签值值较少的数据模型训练准确性。
一般的思路用法为
- 对未标记的数据进行聚类,得到每个数据点所属的簇。
- 选择每个簇中最代表性的几个样本,手动将其标记。
- 将这些标记传播到同一簇中的其他样本,得到一个半标记的数据集。
- 使用半标记的数据集来训练一个分类器,以进行预测。
下面将会采用kmeans半监督算法优化逻辑回归去实现下面的手写数字集模型优化案例
- 核心
通过kmeans分类将每个簇中距离最近的样本的标签传播到该簇的的部分样本中,然后将这些传播后的样本作为有标签样本,用于训练逻辑回归分类器,提高模型准确率,适用于标签值数量较少的模型中
- 导入模块和加载数据集
from sklearn.cluster import k_means
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X,y=load_digits(return_X_y=True)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)
X_train.shape
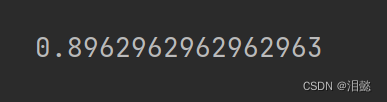
- 我们先用没有优化的逻辑回归的手写数字集模型进行训练分类与评估
lables=100
log_reg=LogisticRegression(random_state=42,multi_class='multinomial',solver='lbfgs')
log_reg.fit(X_train[:lables],y_train[:lables])
score=log_reg.score(X_test,y_test)
score
这是通过训练100个手写数字集,模型得分为
然后使用kmeans聚类训练得到实例到簇中心的距离
k=100
kmeans=KMeans(n_clusters=k,random_state=42)
X_dit=kmeans.fit_transform(X=X_train)
对每个簇,找到距离簇中心最近的实例的索引。
import numpy as np
dit_index=np.argmin(X_dit,axis=0)
dit_index.shape
然后通过索引,找出在训练集中的位置,并可视化出来
X_rep_dits=X_train[dit_index]
X_rep_dits
#%%
import matplotlib.pyplot as plt
plt.figure(figsize=(8,4))
for index,X_rep_dit in enumerate(X_rep_dits):
plt.subplot(10,10,index+1)
plt.imshow(X_rep_dit.reshape(8,8),cmap='binary')
plt.axis('off')
plt.show()

这些就是100个离100个簇最近的实例数字
我们然后为这些打上标签(因为这次的数据集有点特殊,我就偷下懒直接拿标签就行)
y_pre_dits=np.array(y_train[dit_index])
y_pre_dits
然后用这些代表性标签,再去训练
log_reg=LogisticRegression(multi_class='multinomial',solver='lbfgs',random_state=42)
log_reg.fit(X_rep_dits,y_pre_dits)
score=log_reg.score(X_test,y_test)
score
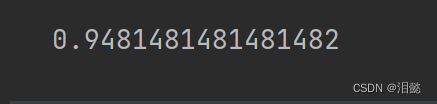
可以看到,模型得到了明显的优化
现在我们使用这些代表性数字的标记来对数据进行标记传播,这意味着将这些标记分配给与它们最接近的数据点。通过这种方式,我们将大量未标记的数据点转化为部分标记的数据。
y_train_propagated = np.empty(len(X_train), dtype=np.int32)
for i in range(k):
y_train_propagated[kmeans.labels_==i] = y_pre_dits[i]
log_reg = LogisticRegression(random_state=42)
log_reg.fit(X_train, y_train_propagated)
使用代表性数字的标记来初始化一个大小为len(X_train)的数组,然后,我们使用K-Means聚类算法得到每个数据点所属的簇,并将该簇的代表性数字的标记分配给该簇中的所有数据点。
然后我们选择范围,这个范围相当重要,这里我们选择26,代表与每个簇中与代表标签也就是簇中心距离的26%的其他标签
closet=26#选择簇最近的26%样本
X_clusrer_dist=X_dit[np.arange(len(X_train)),kmeans.labels_]
for i in range(k):
in_cluter=(kmeans.labels_==i)
clusetr_dist=X_clusrer_dist[in_cluter]
cotoff_distance=np.percentile(clusetr_dist,closet)#得到前26%
abover_citoff=(X_clusrer_dist>cotoff_distance)
X_clusrer_dist[in_cluter & abover_citoff]=-1
- X_clusrer_dist数组计算每个训练样本到所有聚类中心的距离,其中kmeans.labels_数组指示每个训练样本属于哪个聚类,
- 对于每个聚类,找到它内部样本到聚类中心的距离的分位数。这里使用np.percentile()函数计算。
- 然后,选择距离当前聚类中心最近的一定比例的样本。这里选择距离分位数之上的样本,使用abover_citoff数组来标记。
- 最后,将距离分位数(26%)之上的样本的距离设为-1,以便在下一个聚类中心被处理时忽略它们。
整个过程的目的是选择距离聚类中心最近的一部分样本,使它们成为代表该聚类的样本。这些样本将被用于标记传播算法,以帮助对未标记的样本进行分类。在这里,closet被设置为26,这意味着每个聚类中最接近聚类中心的26%的样本将被选择为代表性样本。
partially_propagated = (X_clusrer_dist != -1)
x_train_partially_propaged=X_train[partially_propagated]
y_train_partially_propaged=y_train[partially_propagated]
上述代码中,我们把远离中心26%的数据设置为-1,然后得到索引,将前26%设置为代表样本
标签
最后训练
log_reg = LogisticRegression(random_state=42)
log_reg.fit(x_train_partially_propaged,y_train_partially_propaged)
log_reg.score(X_test,y_test)
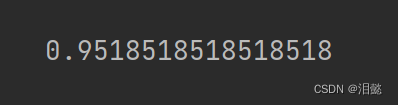
可见还是有部分的提高,范围值可以自己设置,直到找到最优的。
总结
Kmeans聚类算法在实际应用中有着广泛的应用,例如:
市场细分:商家可以使用K均值聚类算法将顾客分为不同的簇,并为每个簇制定不同的营销策略;
图像分割:K均值聚类算法可以将图像中的像素点分为不同的簇,从而实现图像分割;
自然语言处理:K均值聚类算法可以将文本分为不同的簇,从而实现文本聚类和主题分类。
半监督学习:允许我们在没有足够的标记数据的情况下,利用未标记数据来提高分类器或者模型的准确性。
除了K均值聚类算法之外,还有一些其他的聚类算法,例如层次聚类、谱聚类,密度聚类等。在实际应用中,需要根据数据集的特点和需求选择合适的聚类算法。
kmeans算法虽然简单应用广泛有一定的缺点,无法处理任意形状的簇,所以在下一节我将介绍监督算法中DBSCAN算法。
由于本人水平有限,上述有何错误,欢迎指正
我会继续学习,推出更多有趣的东西
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











