






1. penalty:正则化项
可选参数范围: l1,l2,elasticnet,None,默认为l2正则化
正则化目的:防止模型过拟合
2. dual 是否进行对偶问题求解
对偶问题是约束条件相反、求解方向也相反的问题,当数据集过小而特征较多时,求解对偶问题能一定程度降低运算复杂度,其他情况建议保留默认参数取值。
3. tol 与 max_iter:迭代停止条件
tol是指当来那个轮迭代损失差小于tol时,停止,default=0.0001
max_iter指当迭代次数达到max_iter时,停止,default=100
4. C:经验风险和结构风险在损失函数中的各权重

C越大,经验风险越大,结构风险就小
经验风险:指的是你想要调整的loss;结构风险:指的是模型结构复杂度;从这里不难看出实际结构风险的规避靠的就是正则化手段,而经验风险靠的就是一轮一轮梯度下降优化来减小。
5. fit_intercept:线性方程中是否存在截距项
6. class_weight:各类样本权重
class_weight其实代表各类样本在进行损失函数计算时的数值权重,例如假设一个二分类问题,0、1两类的样本比例是2:1(样本不均衡问题),此时可以输入一个字典类型对象用于说明两类样本在进行损失值计算时的权重,例如输入:(0:1,1:3},则代表1类样本的每一条数据在进行损失函数值的计算时都会在原始数值上*3。而当我们将该参数选为 balanced 时,则会自动将这个比例调整为真实样本比例的反比,以达到平衡的效果。
7. solver:损失函数求解方法
除了最小二乘法和梯度下降以外,还有非常多的关于损失函数的求解方法,而选择损失函数的参数,就是solver参数,但不同的超参数组合可能适用的solver不一样,详见可以去下面官网截图
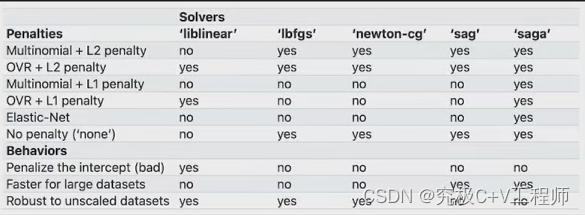
8. multi_class:选择何种多分类问题求解
一般选择auto,可选OVR和MVM,OVR即one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
而MvM则相对复杂,这里举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
9. L1_ratio:弹性网过程中,结构风险占的权重
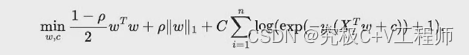















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









