






介绍
深度学习中,参数优化是一个很重要的概念,为什么这么说?首先你需要指导你的预测结果跟你实际结果的偏差吧?那么你想要保证你的偏差最小,如何保证你的偏差最小,就需要优化算法。一般流程是什么,我们可以叫优化算法是正向传播过程,每次正向传播完,我们都反向传播算去他们的梯度,之后继续循环,直到目标函数条件满足,停止,得到目前的权重参数。
一、梯度下降(SGD)
深度学习之神!我称之为,大部分我所看到的用的基本都是这个
规定:必须为凸函数(实际就是一个凹着的函数)(标准定义:给定任意两个点,函数的取值在两点之间的取值,总是小于此两点),否则可能造成局部最优解的问题。维度不能太高,不然会出现“维度灾难”得问题。
公式:
这个公式什么意思呢,首先梯度,主要指的是在某一点下降最快的方向,在这里指的是每一步跨出去的大小,
为上一步的位置,那么i+1指的是下一步的位置,在这里不难看出为什么要求函数是凸函数了,如果你不是凸函数,那么当梯度为0时,那么
,不难看出梯度将不再更新。图示的话就是下面这个图,你会看到梯度从A点逐渐下降下降到了最终B点,这样损失就会最小。
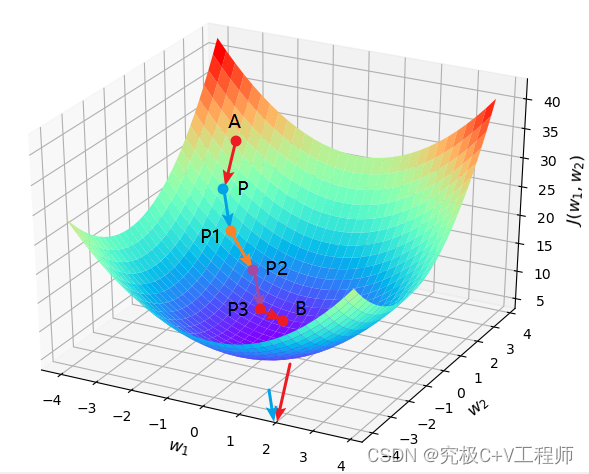
但是这种我前面也说了需要保证,函数是凸函数,如果不是凸函数那怎么办?
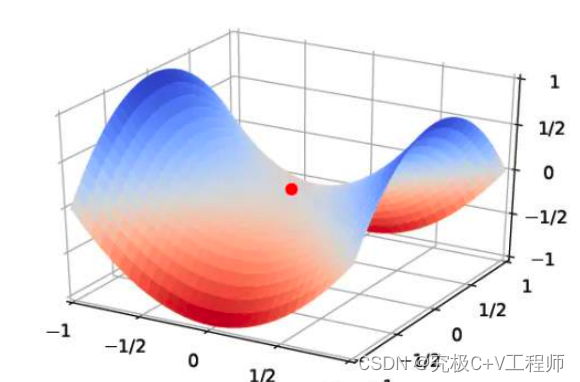
一般四种方式,1. 把非凸函数变成凸函数,2. 去探寻新的算法(momentum),3.使用周期性的学习率调整、或者自适应学习率(AdaGrad、 RMSprop、终极缝合怪Adam) 4.你的初始位置规定好一点直接把这个区域给跨过去(网格搜索),
如果数据量很高怎么办?一般利用mini-batch(常用)、随机梯度下降、批量梯度下降来解决证问题。
二、非凸优化问题
2.1 动量法
为什么提出动量法,譬如之前我的坡度很大,那么这时候下降就很快,但由于我不知道前面的路是什么样的,如果说这个时候突然坡度变缓,那么他将走的非常缓慢,不敢向前走。动量法是什么,他记住了你之前走的路径的方向,他现在走的路实际就是上一步我走的方向跟下面本来要走的方向进行向量加和,最终得到真实的下一步方向。
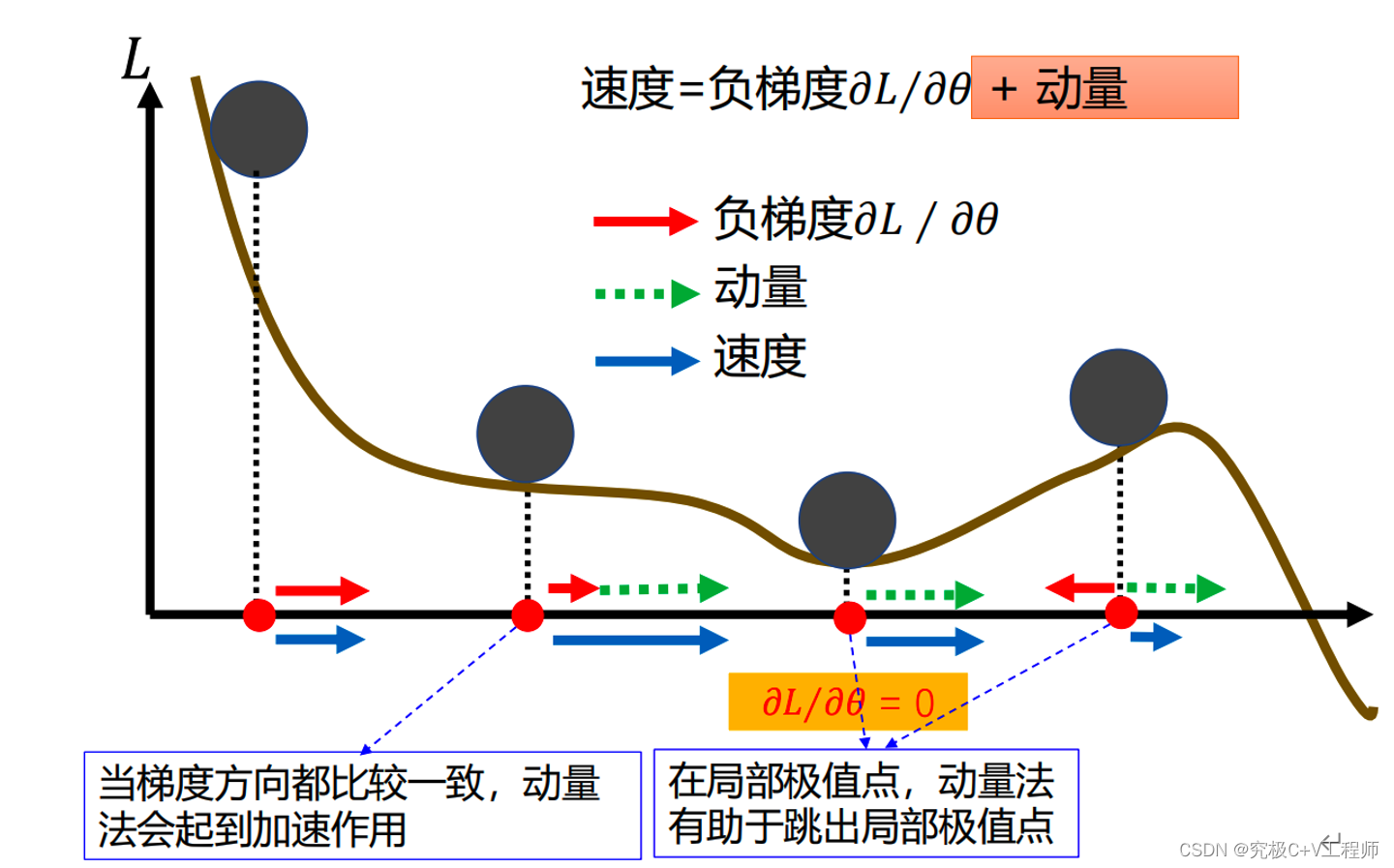
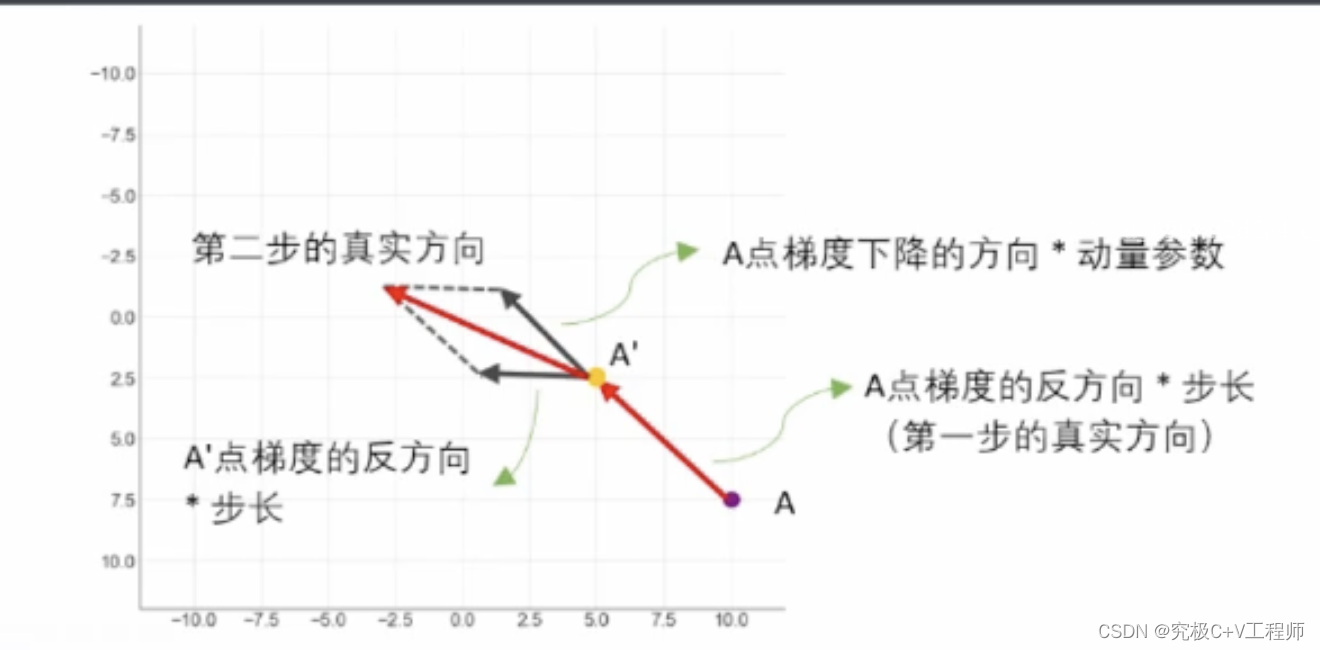
数学理论:
(1)
(2)
从公式也不难理解,公式(1)跟图上所示一致,则不难根据原始梯度下降公式(2)
三、自适应学习率
2.3 AdaGrad
该算法借鉴了L2正则化的思想,每次迭代时,自适应地调整每个参数的学习率.

式子看着有点复杂,这里的指的是梯度的内积开方,
这里就是一个小偏差,可以自己设定,本质上该式子
就是之前学习到所有的梯度的方均根,接下来就不难看出,如果历史数据梯度小,那么
同样的就会变大,如果历史比较大,那么现在你就比较小。
具体机理:
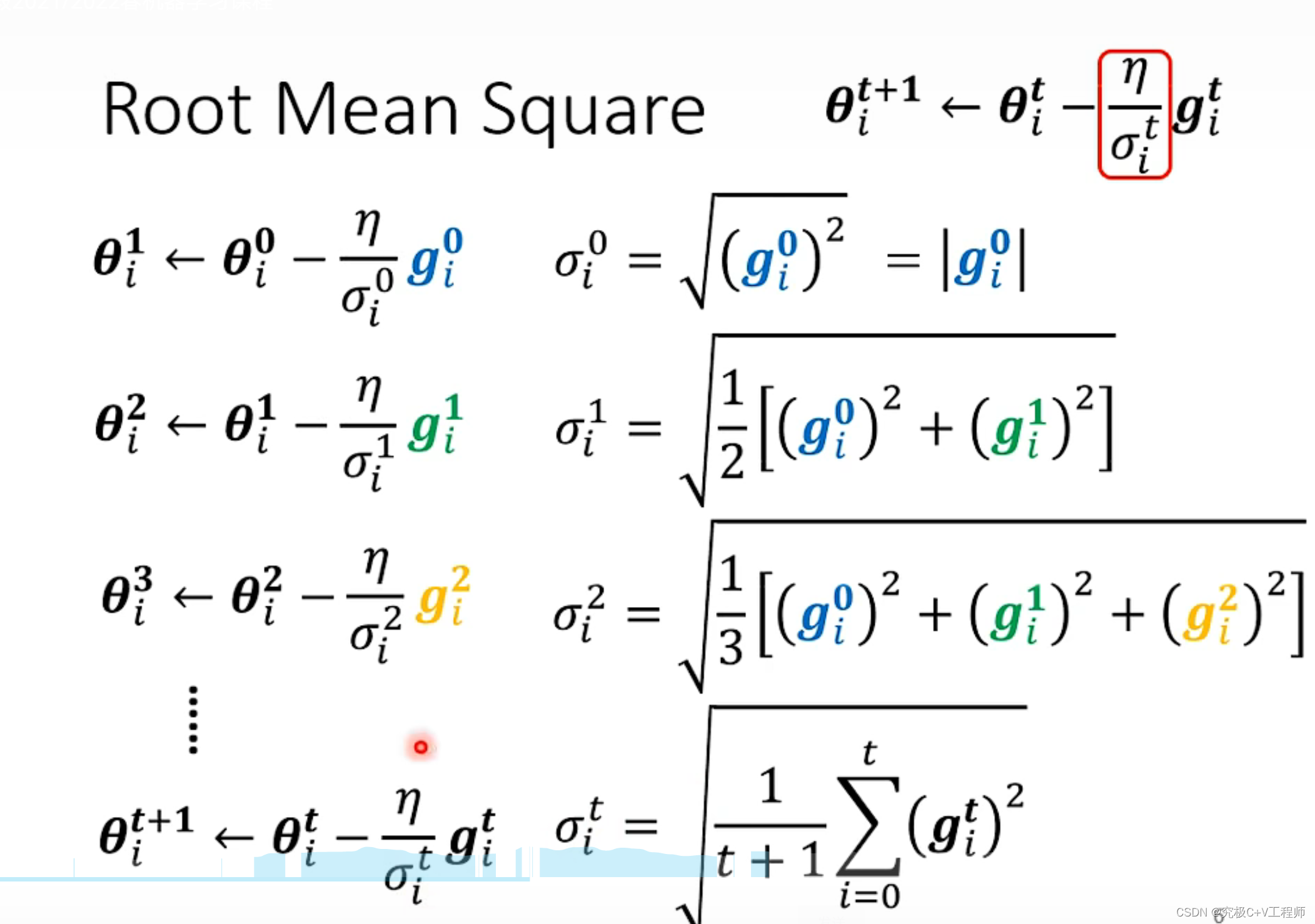
优点:适合稀疏数据
问题:同一个参数的梯度固定差不多,但事实并不一定,但我们希望,同一个参数同一方向
也可以动态调整
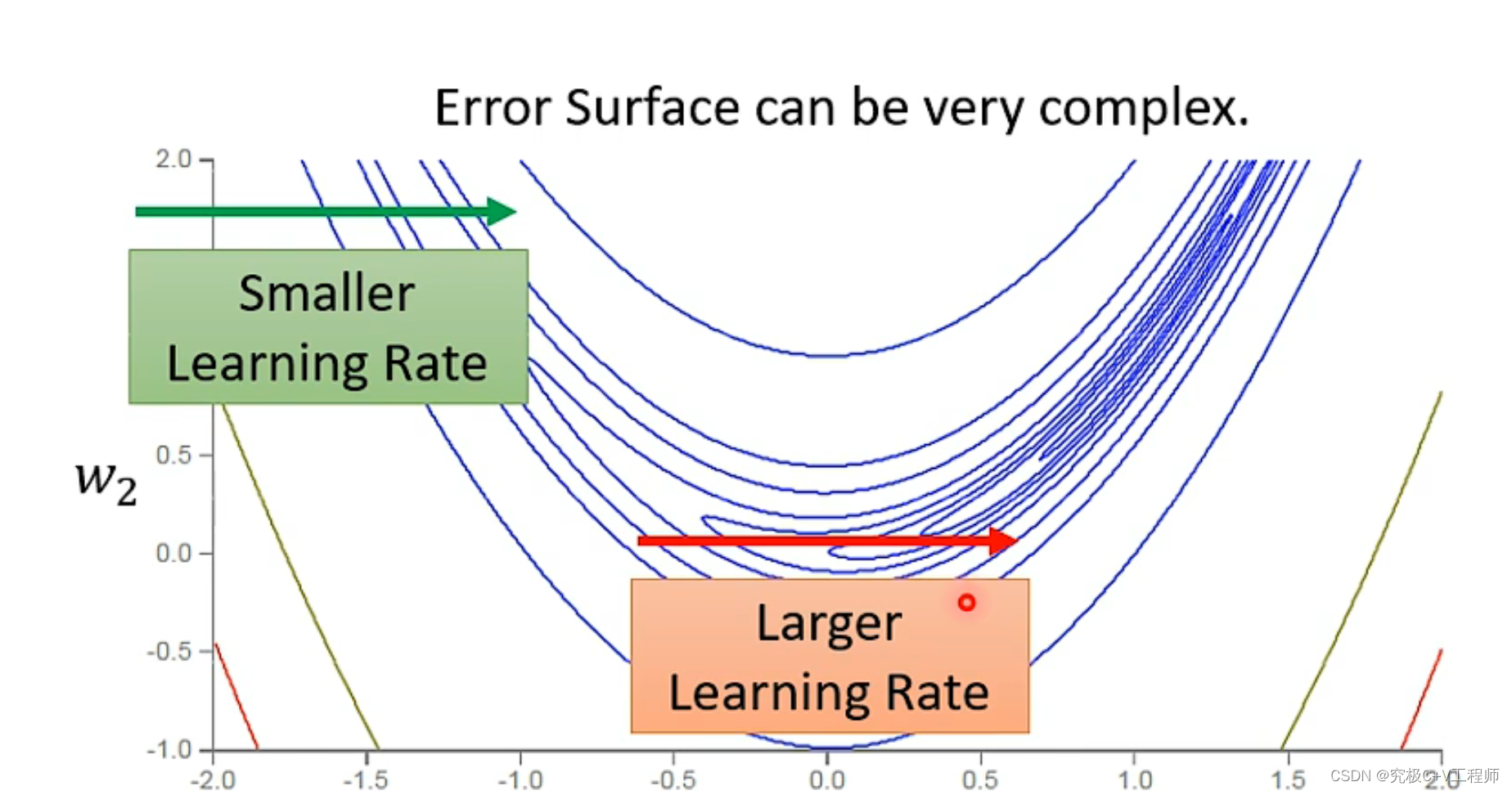
2.2 RMSProp(该方法没有论文)

就是在上面方法基础上增加一个学习率,通过调整学习率,来确定她是看重还是轻视之前的历史梯度。
2.3 Adam(自适应学习率(RMSprop)+梯度方向优化(动量法))
本质上就是个缝合怪,集成了上面俩的优点。你可以自行看论文,目前最常用的,在这里不用细说。
四、超参数设置方法
4.1 网格搜索(GridSearchCV)
网格搜索即网格搜索和交叉验证。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,他要求遍历所有可能参数的组合,在面对大数据集和多参数的情况下,非常耗时。
Grid Search:一种调参手段,本质上就是穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。但耗费算力巨大,所以网格搜索适用于三四个(或者更少)的超参数(当超参数的数量增长时,网格搜索的计算复杂度会呈现指数增长,这时候则使用随机搜索),用户列出一个较小的超参数值域,这些超参数至于的笛卡尔积(排列组合)为一组组超参数。网格搜索算法使用每组超参数训练模型并挑选验证集误差最小的超参数组合。
4.2 随机搜索(RandomizedSearchCV)
基本跟上面网格搜索差不多,不同点在于RandomizedSearchCV随机在超参数空间中搜索几十几百个点,探寻其中比较小的值。(随机搜索从指定分布中抽取固定数量的参数设置)
4.3 蒙特卡洛树搜索(可以研究,美赛可以用)
4.4 对抗搜索(可以研究,美赛可以用)
4.5 贝叶斯优化
(牛!基本直接无脑用)贼难理解,哥们建议直接用。
五、高数据量问题
4.1小批量梯度下降(mini-batch)
本质上是批量梯度下降与随机梯度下降结合版,随机采样m(batch_size)个样本来近似损失在一个数据集上进行多次 epoch。
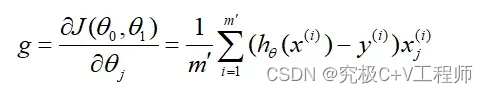
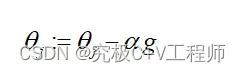
公式就是上面这俩,在这个过程中为了防止,一直在震荡,收敛很慢(非凸函数)的情况,一般可以采用自适应性学习率的方式来进行迭代优化(相关概念可查看文末链接)。
普遍性规律:batch_size在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快,但是要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。当Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化,也可能会超出内存容量。
文末:给大家推荐一个大佬的GitHub写的很棒!
https://enzo-miman.github.io/#/
参考链接:
深度学习之 8 深度模型优化与正则化_梯度方向优化和自适应学习率_水w的博客-CSDN博客
正则化项L1,L2以及weight decay在SGD,Adam中的理解 (mengtingxu1203.github.io)
2021 - 类神经网络训练不起来怎么办(一) 局部最小值 (local minima) 与鞍点 (saddle point)_哔哩哔哩_bilibili
Adam:https://arxivorg/pdf/1412.6980.pdf【技术干货】超参数优化专题:贝叶斯优化|BayesOpt|HyperOpt|Optuna|自动化调参|高斯过程|TPE|机器学习_哔哩哔哩_bilibili人工智能导论:08搜索求解算法:蒙特卡洛树搜索|AI入门必学课程_哔哩哔哩_bilibili















 1904
1904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









