







目录
🔹 3. 查询增强(Query Reformulation)

🧠 RAG 高效召回方法全景图
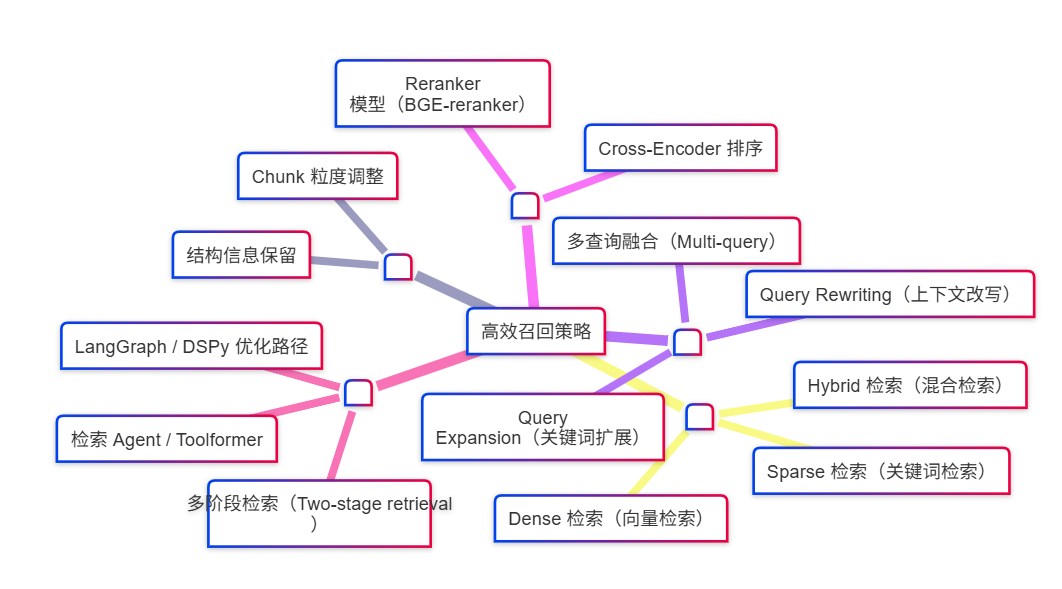
🔹 1. 数据处理优化
✅ Chunk 粒度调整
-
常见设置:
100~500 tokens -
太长 → 检索不准;太短 → 无法传递上下文
-
推荐用 滑动窗口 + 语义分段
✅ 保留结构与元信息
-
如:
标题 + 正文拼接 -
增强查询时的语义匹配能力
🔹 2. 检索方式增强
✅ Dense 向量检索
-
使用语义向量(Embedding)
-
适合“语义相关但字面不同”的问题
-
工具:FAISS, Qdrant, Weaviate
✅ Sparse 检索(关键词检索)
-
基于关键词(TF-IDF/BM25)
-
更适合:法律/技术词汇精准命中
-
工具:Elasticsearch, BM25Retriever
✅ Hybrid 检索(混合方式)✅推荐
-
将 Dense 与 Sparse 同时使用,做 score 融合
-
示例:LangChain 的
MultiRetriever
retriever = MultiRetriever(
retrievers=[dense_retriever, bm25_retriever],
search_type="mmr"
)
🔹 3. 查询增强(Query Reformulation)
✅ Query Expansion
-
将 query 拓展为多个变体(同义、上下位词)
-
示例:
-
用户问:“什么是 RAG?”
-
系统扩展为:“什么是检索增强生成?”、“RAG 的原理是什么?”
-
✅ Query Rewriting(上下文感知)
-
基于上下文重写问题,更利于检索
-
工具:LlamaIndex 的
QueryTransform/ LangChain ReAct Agent
from llama_index.query_engine.transform_query_engine import HyDEQueryTransform
query_engine = HyDEQueryTransform(...)
✅ Multi-Query Retrieval
-
用多个查询同时发起检索(再聚合 Top-k)
-
示例(LangChain):
retriever = MultiQueryRetriever.from_llm(
retriever=base_vector_retriever,
llm=ChatOpenAI(),
)
🔹 4. 重排序(Re-ranking)
✅ Reranker 模型
-
用一个 Cross-Encoder 对 Top-K 检索结果打分
-
模型推荐:
-
BAAI/bge-reranker-base -
nq-distilbert-base-v2
-
-
工具支持:
-
rerank=Truein LlamaIndex -
Haystack ReRanker Pipeline
-
reranker = ReRanker(model="BAAI/bge-reranker-base", top_n=5)
🔹 5. 检索流程优化(系统级)
✅ Two-stage 检索
-
第一阶段:快速粗检索(向量 Top-30)
-
第二阶段:Re-rank or 再召回 Top-5
✅ Tool-based 检索
-
通过 ReAct / Agent 调用不同的检索源
-
示例:网页 + PDF + SQL + API 混合问答
✅ LangGraph + DSPy 任务流程优化
-
通过节点化流程调度检索、问答、验证逻辑
-
避免 LLM 一步出错带来的全局误差
🚀 实战推荐组合(易用 + 高性能)
| 组合策略 | 效果评价 | 工具示例 |
|---|---|---|
| 向量检索 + reranker | 🚀🚀🚀🚀 | FAISS + BGE-reranker |
| Hybrid 检索 + reranker | 🚀🚀🚀🚀🚀 | BM25 + Dense + Re-ranking |
| 多查询 + 向量检索 | 🚀🚀🚀 | LangChain MultiQueryRetriever |
| Query Rewrite + reranker | 🚀🚀🚀🚀 | LlamaIndex + HyDE + bge-reranker |
🧪 Bonus:召回效果评估指标(RAGAS)
-
Precision@k:前 k 条中相关的比例
-
Recall@k:召回所有相关信息的能力
-
Faithfulness / Factuality:最终生成是否忠实于检索内容
用 RAGAS 工具可评估你自己的召回链条效果。

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









