







目录
一、不同YOLOv8版本模型的性能
YOLOv8是一个强大的目标检测和分割模型,支持多种任务,包括分类(cls)、检测(det)、姿态估计(pose)和分割(seg)。以下是这些任务的主要区别:
| 任务 | 描述 | 输出 |
|---|---|---|
| 分类 (cls) | 识别图像中的物体类别 | 类别标签 |
| 检测 (det) | 定位并识别图像中的物体 | 物体的位置和类别 |
| 姿态估计 (pose) | 识别物体的关键点和姿态 | 关键点的位置和姿态信息 |
| 分割 (seg) | 识别图像中每个像素的类别 | 像素级别的类别标签 |
下面简单看一下YOLOv8检测版本和分类版本模型性能:
1、检测版本(det):
主要用于目标检测任务。这些模型不仅需要预测目标的类别,还需要预测目标的位置(边界框)。因此,检测版本的模型通常会有多个输出层,每个层负责不同尺度的目标检测。
(1)模型性能对比
| 检测模型 | 尺寸 (像素) | mAPval 50-95 | 速度 CPU ONNX (ms) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
(2)性能指标说明
-
mAPval 50-95:平均精度均值(mean Average Precision),在交并比(IoU)阈值从50%到95%范围内的变化,是衡量目标检测模型性能的关键指标,数值越高表示模型性能越好。
-
速度 CPU ONNX (ms):模型在CPU上运行时,使用ONNX(Open Neural Network Exchange)格式的推理速度,单位是毫秒(ms)。
-
速度 A100 TensorRT (毫秒):模型在NVIDIA A100 GPU上运行时,使用TensorRT优化后的推理速度,单位是毫秒(ms)。TensorRT是一个深度学习推理引擎,可以优化模型以加快在NVIDIA GPU上的运行速度。
-
params (M):模型的参数总数,以百万(M)为单位。参数数量越多,通常表示模型结构越复杂,计算需求越高。
-
FLOPs (B):模型运行时所需的浮点运算次数(Floating Point Operations Per Second),通常用来衡量模型的计算复杂度。
(3)表格总结:
| 模型 | 特点 | 适用场景 |
|---|---|---|
| YOLOv8n | 参数量和FLOPs少,轻量级,推理速度快,检测准确率相对低 | 资源有限设备(嵌入式、移动端),对实时性要求极高且对准确率要求不苛刻的场景(如简单监控检测物体是否移动) |
| YOLOv8s | 模型规模增大,能学习更复杂特征,准确率提升,速度较YOLOv8n有所下降但仍较高 | 需要速度和准确度较好平衡的应用(如普通安防监控检测人和车辆) |
| YOLOv8m | 模型更大,准确率显著提升(小目标和复杂场景检测能力增强),速度进一步下降,计算资源需求增加 | 对准确度有更高要求且要考虑速度的场景(如工业检测产品微小缺陷) |
| YOLOv8l | 参数较多,准确率较好,能处理复杂检测任务(如重叠目标检测分类),速度慢,需较强计算能力 | 对准确度要求高的应用(如高级安防监控识别目标行为身份) |
| YOLOv8x | 参数量和FLOPs最多,检测准确率最高(复杂场景、小目标检测出色),速度最慢,硬件要求高 | 准确度至关重要的高端应用(如高端医学影像分析、高精度自动驾驶) |
2、分类版本(cls):
主要用于图像分类任务。这些模型通常有一个全局平均池化层和一个全连接层作为输出层,用于预测输入图像所属的类别。
(1)模型性能对比
| 分类模型 | 尺寸 (像素) | 准确率Top1 | 准确率Top5 | 速度CPU ONNX (ms) | 速度A100 TensorRT (ms) | 参数 (M) | FLOPs (B) at 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n - cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s - cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m - cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l - cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x - cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
(2)性能指标说明:
-
版本: 各个版本的YOLOv8模型,从最小的
YOLOv8n-cls到最大的YOLOv8x-cls。 -
top-1准确率 (%): 模型在ImageNet验证集上的top-1准确率,表示模型预测得分最高的类别恰好是正确类别的比例。
-
top-5准确率 (%): 模型在ImageNet验证集上的top-5准确率,表示模型预测得分最高的前五个类别中包含正确类别的比例。
-
CPU ONNX 处理速度 (ms): 在CPU上使用ONNX格式时的处理速度,单位为毫秒每张图片。
-
A100 TensorRT 处理速度 (ms): 在NVIDIA A100 GPU上使用TensorRT加速时的处理速度,单位为毫秒每张图片。
-
参数量 (M): 模型中的参数总数,以百万为单位。
-
FLOPs (B) at 640: 执行一次前向传播所需的浮点运算次数,以十亿次为单位,基于640像素的输入计算。
(3)表格总结:
| 模型 | 特点 | 适用场景 |
|---|---|---|
| YOLOv8n - cls | 最轻量,处理速度最快,准确率相对较低 | 资源有限或对速度要求较高的场景 |
| YOLOv8s - cls | 在保持较高速度的同时准确率有所提升 | 需要在速度和准确度之间取得平衡的应用 |
| YOLOv8m - cls | 准确率显著提升,仍需考虑处理速度 | 对准确度有更高要求,但也要考虑速度的场景 |
| YOLOv8l - cls | 更高的准确率,处理速度较慢 | 对准确度要求较高的应用 |
| YOLOv8x - cls | 提供最高的准确率,速度最慢,需要较强硬件支持 | 准确度至关重要的高端应用 |
二、常见公开数据集
1、常见公开深度学习数据集
本次介绍21个常见的公开深度学习数据集,涵盖了目标检测、图像分割、图像分类、人脸、自动驾驶、姿态估计、目标跟踪等方向。表格中包括了数据集的类型、功能简述。

| 序号 | 数据集名称 | 类型 | 功能 |
|---|---|---|---|
| 1 | ImageNet | 图像分类 | 包含1400多万张标注图像,涵盖1000个类别,用于图像分类任务 |
| 2 | COCO | 目标检测、图像分割 | 包含33万多张图像,覆盖80类物体,用于目标检测、分割和图像标注任务 |
| 3 | MNIST | 图像分类 | 包含70000张手写数字图像,用于手写数字识别任务 |
| 4 | CIFAR-10 / CIFAR-100 | 图像分类 | 包含60000张32x32像素的彩色图像,分为10类或100类 |
| 5 | Pascal VOC | 目标检测、图像分割 | 提供20类对象的标注,用于目标检测和图像分割任务 |
| 6 | LFW (Labeled Faces in the Wild) | 人脸识别 | 包含13000多张人脸图像,用于人脸识别任务 |
| 7 | Cityscapes | 自动驾驶、图像分割 | 包含50个城市街道场景的高质量图像,用于自动驾驶和图像分割任务 |
| 8 | KITTI | 自动驾驶 | 包含德国街道和高速公路场景的多样化图像和激光雷达数据,用于自动驾驶任务 |
| 9 | Open Images | 目标检测、图像分割 | 包含900多万张图像,用于目标检测和分割任务 |
| 10 | Medical Image Datasets | 医疗影像 | 包括多种医疗影像数据,用于疾病诊断和医学影像分析任务 |
| 11 | VQA (Visual Question Answering) | 图像理解 | 包含26万余张图片和相应的问题,用于视觉问答任务 |
| 12 | MS COCO | 目标检测、图像分割 | 包含33万多张图像,覆盖80类物体,用于目标检测和分割任务 |
| 13 | PASCAL 3D+ | 姿态估计 | 包含12类物体的3D姿态注解,用于物体姿态估计任务 |
| 14 | MPII Human Pose | 姿势估计 | 包含4万多张人体图像,标注了关节位置,用于人体姿势估计任务 |
| 15 | YouTube-BB | 目标跟踪 | 包含5000多个视频片段,标注了50多万个边界框,用于目标跟踪任务 |
| 16 | ImageNet VID | 目标跟踪 | 扩展了ImageNet数据集,包含多个视频序列,用于视频目标检测和跟踪任务 |
| 17 | Caltech-101 | 图像分类 | 包含101个类别的图像,用于图像分类任务 |
| 18 | Caltech-256 | 图像分类 | 包含256个类别的图像,用于图像分类任务 |
| 19 | SUN RGB-D | 自动驾驶、图像分割 | 包含10335张RGB-D图像,用于室内场景理解任务 |
| 20 | SIFT Flow | 光流估计 | 包含2800张图像,用于密集对应估计任务 |
| 21 | ETH-80 | 物体识别 | 包含8类物体的图像,用于物体识别任务 |
2、COCO128数据集
COCO128数据集是COCO数据集的一个子集,包含128张高质量的图像,广泛应用于目标检测、图像分割和实例识别等任务,COCO128数据集虽然规模不大,却具备COCO数据集的基本结构和注释格式。
三、环境配置
前提:Anaconda和pycharm已安装,如果不知道怎么安装请看我下面过往文章链接的安装步骤。(Anaconda和pycharm已安装,可直接略过)
1、新建一个pytorch测试环境
(1)创建虚拟环境
-
(base环境下)创建名字为yolov8new,python版本为3.8的虚拟环境
conda create -n yolov8new python=3.8
-
激活pytorch的环境
conda activate yolov8new
(2)官网下载安装pytorch
Previous PyTorch Versions | PyTorch![]() https://pytorch.org/get-started/previous-versions/
https://pytorch.org/get-started/previous-versions/
-
输入nvidia-smi查看自己电脑的CUDA版本(win+r,输入cmd点击“确定”或回车)
-
如下图我的CUDA是11.7版本的,如果没有显示就选择CPU版本的。

-
在pytorch网页安装对应的PyTorch版本,可选择conda方式或者pip方式下载:

-
如下是CUDA11.7,conda方式的pytorch下载安装命令:
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
-
验证是否pytorch安装成功,验证命令如下,显示版本号即表示安装成功:
python import torch
# 查看torch版本
print(torch.__version__)
(3)安装常用库:
-
输入安装所需的各种库命令:
# 安装matplotlib
pip install matplotlib==3.7.3 -i https://pypi.doubanio.com/simple/
# 安装sklearn
pip install scikit-learn==0.24.2 -i https://pypi.doubanio.com/simple/
# 安装pytz
pip install pytz -i https://mirrors.aliyun.com/pypi/simple/
# 安装pandas
pip install pandas==1.1.5 -i https://pypi.doubanio.com/simple/
# 安装opencv
pip install opencv_python==4.4.0.40 -i https://pypi.doubanio.com/simple/
# 安装imageio
pip install imageio -i https://pypi.org/simple/
#安装ultralytics (也是ultralytics的pip下载方式)
pip install ultralytics -i https://pypi.org/simple/
-
进入python验证是否下载成功,验证命令如下:
import numpy as np
import pandas as pd
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
import cv2
import matplotlib
import ultralytics
#最后输入exit()退出
2、pycharm配置pytorch
(1)选择python解释器
-
打开【设置】》【项目】》【Python解释器】》【添加解释器】》【添加本地解释器】。

-
或者点击右下角的解释器进行更改:

-
添加刚刚创建的python解释器。

(2)新建一个python环境
- 右键项目》【新建】》【Python文件】》输入名称。



四、YOLOv8 (ultralytics)的安装
1、下载YOLOv8 (ultralytics)
GitHub网址:
GitHub - ultralytics/ultralytics: Ultralytics YOLO11 🚀![]() https://github.com/ultralytics/ultralytics进入网址,点击Code,然后点击Download下载zip压缩包 。
https://github.com/ultralytics/ultralytics进入网址,点击Code,然后点击Download下载zip压缩包 。
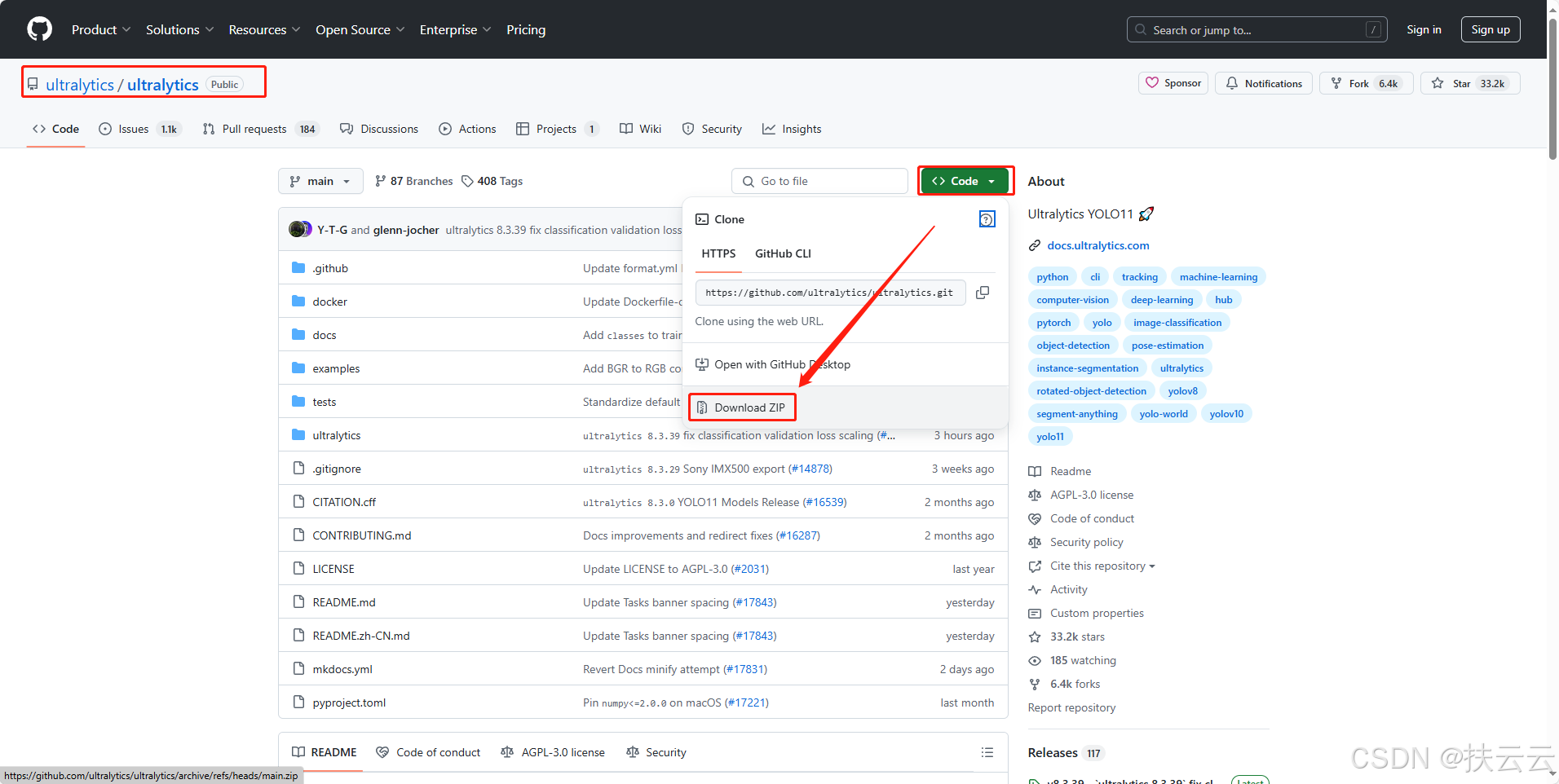
解压,可看见下面文件夹和文件。
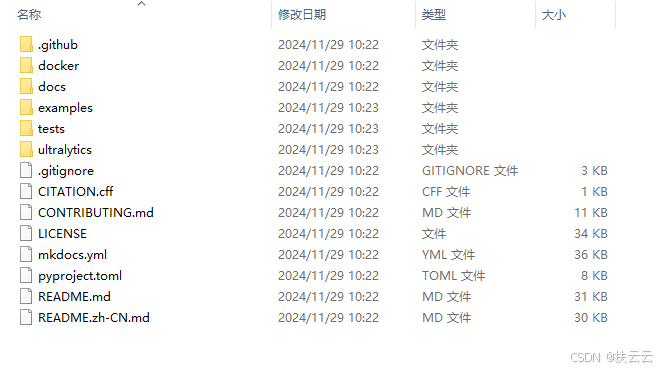
2、YOLOv8内文件夹/文件含义
(1)文件夹含义:
| 文件夹名称 | 含义 |
|---|---|
models | 包含不同版本和配置的YOLOv8模型文件,如yolov8.yaml、yolov8-cls.yaml等,每个文件定义了不同任务(检测、分类、姿态估计等)的模型结构和参数 |
trackers | 存放目标跟踪算法的代码,支持在视频或实时流中跟踪检测到的对象 |
utils | 包含各种实用工具函数,如图像预处理、数据增强、后处理、可视化等 |
data | 包含数据集相关的脚本和文件,如download_weights.sh、get_coco.sh等,用于下载数据集和预训练权重1 |
runs | 训练输出文件夹,包含训练过程中的各种信息,如模型权重、训练日志、评估结果等 |
ultralytics | 包含YOLOv8模型的核心代码,定义了模型架构、训练策略、优化方法等 |
(2)文件含义:
| 文件名称 | 含义 |
|---|---|
README.md | 项目的主文档,包含项目介绍、安装指南、使用说明等8 |
README.zh-CN.md | 项目的中文说明文档,提供中文用户的项目介绍、安装指南、使用说明等 |
LICENSE | 项目的许可证文件,说明项目的开源协议 |
CITATION.cff | 提供引用该项目的相关信息,用于学术引用 |
CONTRIBUTING.md | 贡献指南,说明如何为项目做出贡献 |
mkdocs.yml | MkDocs配置文件,用于生成项目文档网站 |
pyproject.toml | Python项目配置文件,指定项目依赖和构建配置 |
gitignore | Git版本控制系统的忽略文件,指定哪些文件或文件夹不需要被Git跟踪 |
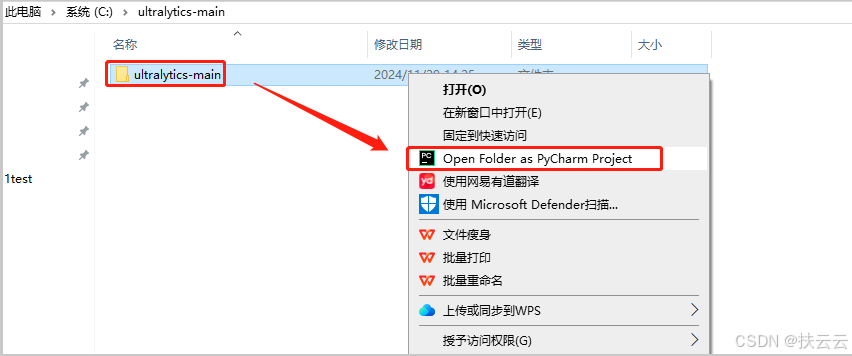
3、使用pycharm打开
-
右键,点击【Open Folder as PyCharm Project】即可打开。
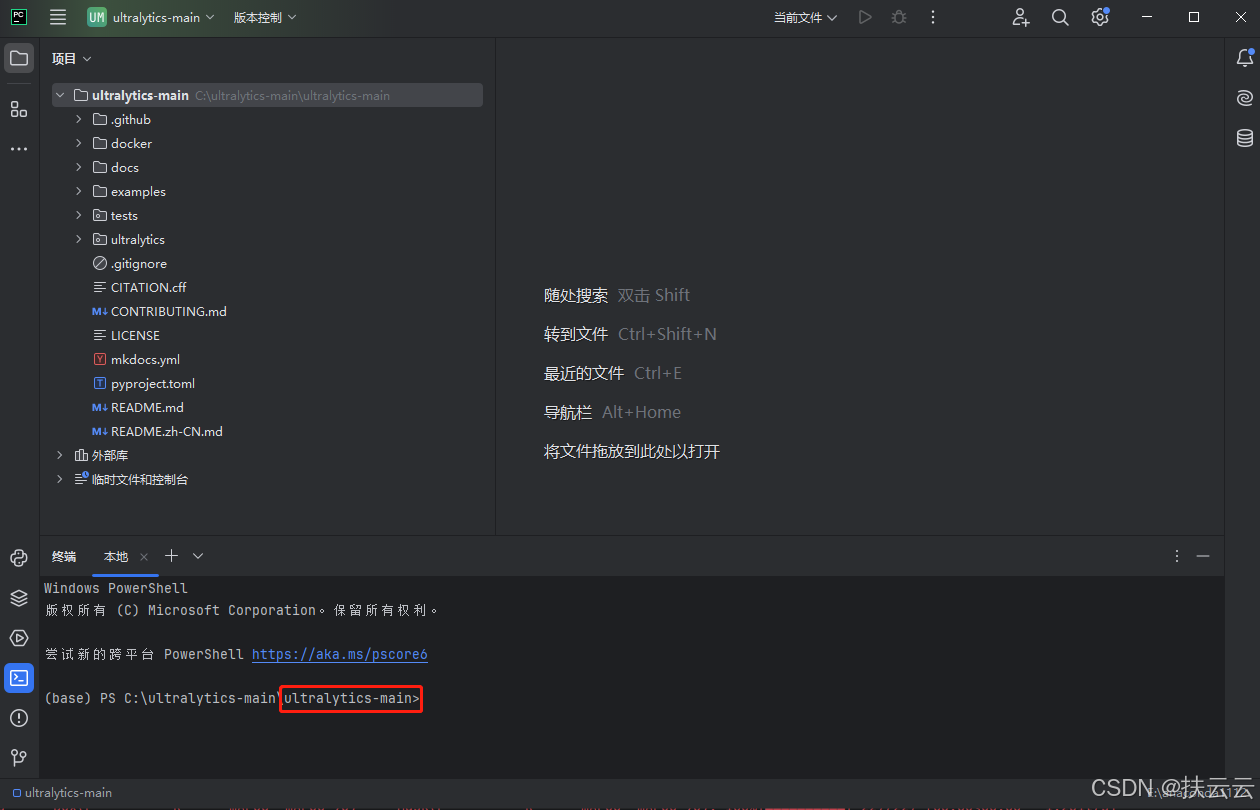
-
再打开终端,出现ultralytics-main即表示安装成功。
五、准备数据集和yaml文件
1、数据集
(1)公开数据集
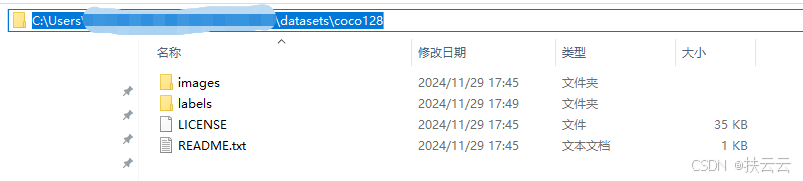
本次训练我们无需另外配置coco128数据集!!!
coco128作为常用的公开数据集,我们在运行训练代码时,系统如果根据yaml指向的路径下没有找到coco128数据集,系统会自动在官网下载coco128数据集.
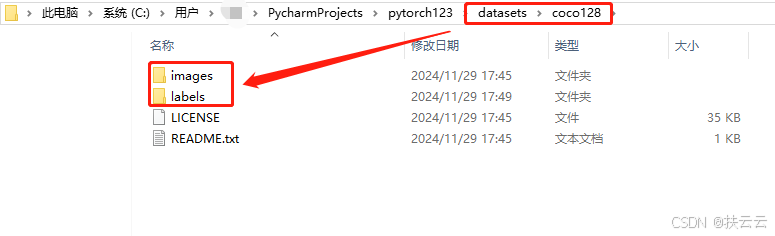
-
如下是运行代码生成的coco128数据集:主要是images图片集和labels标签集要对应好。
-
如下是coco128数据集内文件/文件夹的描述:
| 文件/文件夹 | 描述 |
|---|---|
| images | 包含128张高质量的图像,这些图像是从COCO数据集中选取的,用于目标检测、图像分割和实例识别等任务。 |
| labels | 包含与images文件夹中图像对应的标签信息,这些标签通常是文本文件,描述了图像中目标的类别、位置和其他相关信息。 |
| license | 包含数据集的版权和使用许可信息,通常是一个文本文件,描述了数据集的使用权限和限制。 |
| README.txt | 包含数据集的说明文档,通常是一个文本文件,提供了数据集的基本信息、使用方法、数据格式等详细说明。 |
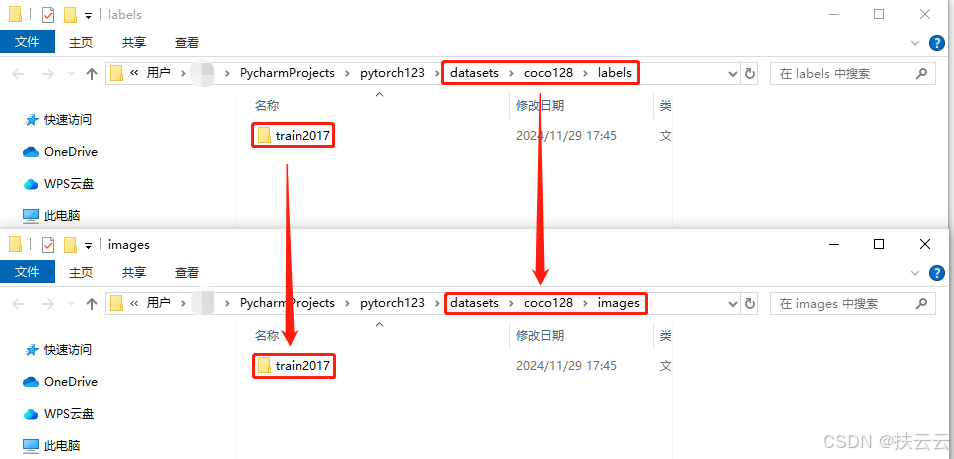
-
如下是coco128的images(jpg)图片集和labels(txt)标签集的对应关系:
-
如下是images(jpg)图片集:
-
如下是labels(txt)标签集,以及标签内容:每一行标签通常代表一个目标实例。

-
以49 0.642859 0.0792187 0.148063 0.148062为例,其中的数字含义如下:
| 数字 | 含义 |
|---|---|
| 49 | 目标的类别ID,这里的49可能代表某个具体的类别,例如“汽车”或者“人”等。 |
| 0.642859 | 目标在图像中的中心点X坐标,这个值是归一化后的结果,范围在0到1之间,表示目标中心点在图像宽度方向上的位置。 |
| 0.0792187 | 目标在图像中的中心点Y坐标,同样是归一化后的结果,表示目标中心点在图像高度方向上的位置。 |
| 0.148063 | 目标在图像中的宽度,也是归一化后的数值,表示目标在图像宽度方向上占据的比例。 |
| 0.148062 | 目标在图像中的高度,同样是归一化后的数值,表示目标在图像高度方向上占据的比例。 |
注意:当所需数据没有公开数据集或公开数据集数据量不足时,需要自己准备数据集!!!
(2)自己准备数据集
-
主要步骤:数据收集-->数据清洗-->数据标注-->数据分割-->数据存储与管理
-
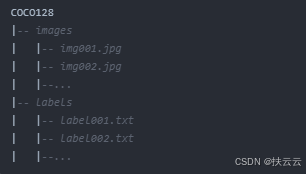
以coco128为例,存放目录如下:
2、yaml配置文件
(1)yolov8含部分yaml文件
本次训练我们可以不用配置yaml文件!!!
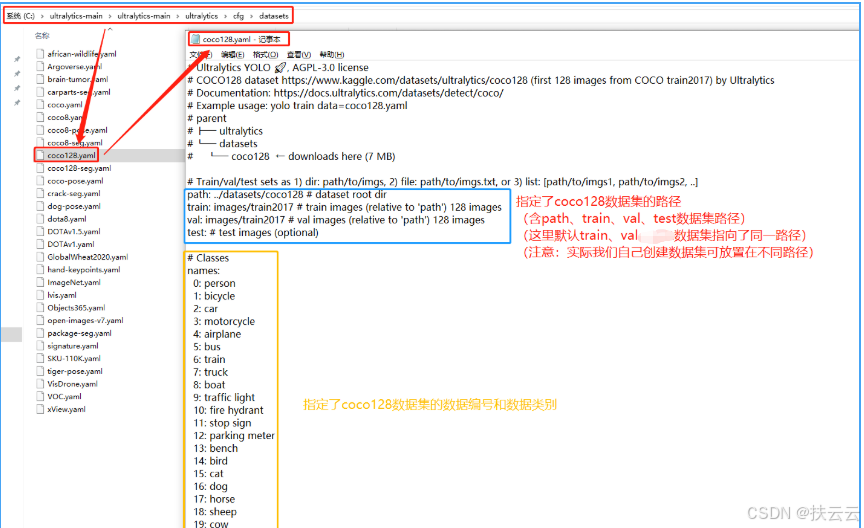
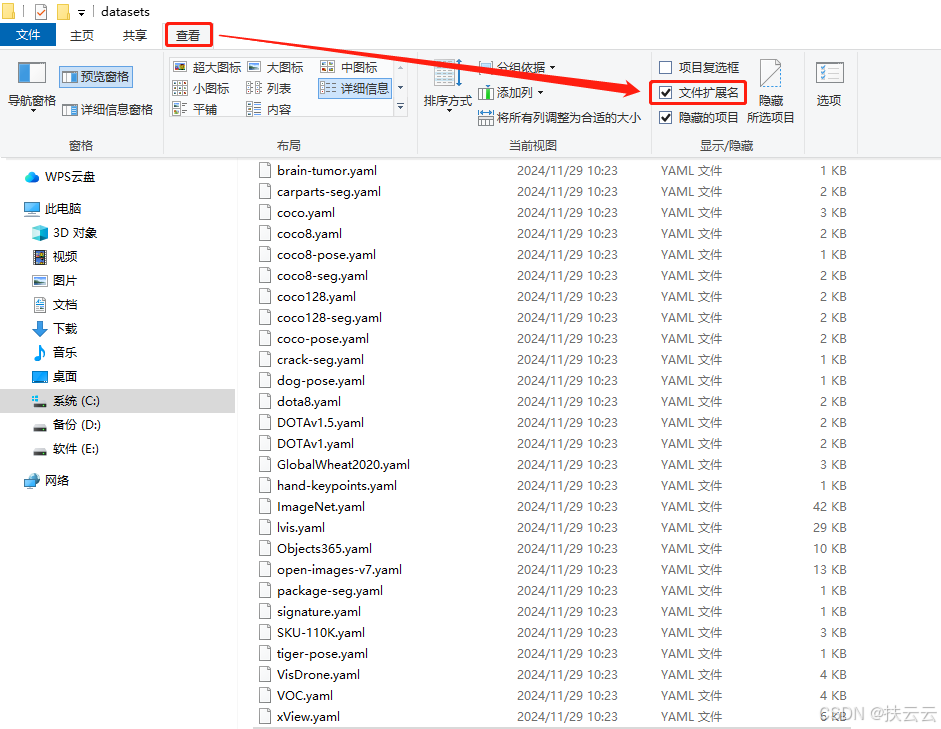
我们下载安装的yolov8 (ultralytics)文件夹本身就含有coco128数据集的yaml配置文件(...\ultralytics\cfg\datasets路径下),也可以根据需求对yaml文件内的路径和类别进行修改。
-
如下是...\ultralytics\cfg\datasets路径下的yaml配置文件和打开的coco128.yaml:
注意:一旦需要训练自己的数据集,就需要自己新建和配置yaml文件!!!
(2)自己新建yaml配置文件
配置格式同coco128.yaml一致,只需更改路径和类别信息,同样需要放在...\ultralytics\cfg\datasets路径下。
我们以coco128.yaml为例,介绍yanl文件的配置过程:
-
分析数据集的路径信息和类别信息:
| 配置项 | 描述 | 示例 |
|---|---|---|
| 数据集根目录 | 数据集的顶级目录路径,包含训练集、验证集和测试集等子目录 | /home/user/dataset |
| 训练集图像路径 | 训练集图像所在的目录路径,位于数据集根目录下 | ${数据集根目录}/train/images |
| 验证集图像路径 | 验证集图像所在的目录路径,位于数据集根目录下 | ${数据集根目录}/val/images |
| 测试集图像路径 | 测试集图像所在的目录路径,位于数据集根目录下 | ${数据集根目录}/test/images |
| 类别编号 | 为每个类别分配的唯一数字标识符,用于在模型训练和识别中区分不同类别 |
1: bicycle 2: car |
| 类别名称 | 数据集中各类别的名称 | person bicycle car |
-
【新建】-->【文本文档】-->命名并打开文本文档
- 编辑配置文件:
path: ../datasets/coco128
train: images/train2017
val: images/train2017
test: #未定义
# Classes
names:
0: person
1: bicycle
2: car
......
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush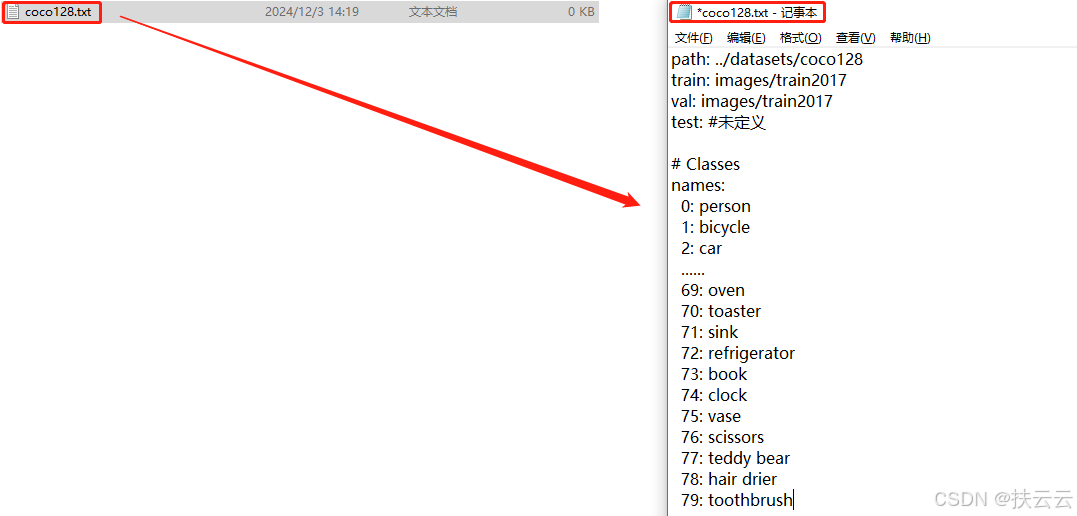
- 点击【文件】-->【保存】

- 将txt后缀更改为yaml
注意:如果看不见后缀,就打开【查看】,勾选【文件扩展名】。
六、训练和验证
1、训练和验证---示意代码
(1)公开数据集直接运行
coco128是公开数据集,可直接运行训练示意代码,当系统在yaml文件指向的本地路径如果找不到coco128数据集,会自动链接官网进行下载coco128数据集。
注意:如果是训练自己的数据集,需要先准备数据集和yaml配置文件!!!
from ultralytics import YOLO
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML构建并转移权重
if __name__ == '__main__':
results = model.train(data='coco128.yaml', epochs=10, device='0')
metrics = model.val()(2)代码的具体含义

注意:如果是CPU环境,device='cpu'。
2、训练和验证---过程
(1)下载权重和公开数据集
训练过程会下载yolov8n.pt权重文件和coco128数据集(公开数据集)

(2)训练过程-参数说明
| 参数 | 描述 | 默认值 | 训练参数设置 |
|---|---|---|---|
| model | 模型文件路径(例如yolov8n.pt等) | None | 按任务选合适的预训练模型文件 |
| data | 数据文件路径(如coco128.yaml) | None | 挑匹配数据集的配置文件 |
| batch | 一批次的图像数量 | 16 | 硬件资源多就增大,避免内存不足 |
| epochs | 训练完整遍历数据集的次数 | 100 | 数据集小或模型简单可减少;反之增加,避免过拟合 |
| imgsz | 输入图像大小 | 640 | 参考硬件性能和模型要求调整 |
| optimizer | 优化器类型(如SGD、Adam) | 'auto' | 依模型和数据集特性选 |
| pretrained | 是否用预训练模型 | True | 新任务一般默认 |
| device | 运行设备(如cuda或cpu) | None | 依据硬件资源选择 |
| workers | 加载数据的线程数 | 8 | 按系统资源调整 |
| save | 是否保存训练成果 | True | 一般默认即可 |
| val | 训练中是否验证 | True | 一般默认 |
| resume | 是否从断点恢复训练 | False | 中断后继续设为True |
| fraction | 训练用数据集比例 | 1.0 | 用部分数据训练时调整 |
| cache | 是否缓存数据(有不同方式) | False | 硬件和数据集合适就用 |
| amp | 是否自动混合精度训练 | True | 硬件支持就选 |
| lr0 | 初始学习率 | 0.01 | 依模型和数据集调整 |
| lrf | 最终学习率 | 0.01 | 按训练策略调整 |
| momentum | 优化器相关动量参数 | 0.937 | 按优化器类型调整 |
| weight_decay | 优化器权重衰减 | 0.0005 | 一般默认 |
| warmup_epochs | 热身周期数 | 3.0 | 依模型特性调整 |
| warmup_momentum | 热身初始动量 | 0.8 | 按训练策略调整 |
| warmup_bias_lr | 热身初始偏置学习率 | 0.1 | 按训练策略调整 |
| box | 目标检测盒子损失增益 | 7.5 | 依模型和数据调整 |
| cls | 目标检测类别损失增益 | 0.5 | 按分类任务难度调整 |
| dfl | 目标检测DFL损失增益 | 1.5 | 按具体应用调整 |
| pose | 姿态检测损失增益(姿态任务) | 12.0 | 仅姿态任务用 |
| kobj | 姿态检测关键点损失增益(姿态任务) | 2.0 | 仅姿态任务用 |
| label_smoothing | 分类任务标签平滑比例 | 0.0 | 按训练策略调整 |
| nbs | 参考批量大小 | 64 | 依硬件资源调整 |
| dropout | 分类任务正则化(dropout) | 0.0 | 分类任务中过拟合时调整 |
| overlap_mask | 分割训练掩码是否重叠 | True | 仅分割任务用 |
| mask_ratio | 分割训练掩码下采样比例 | 4 | 仅分割任务用 |
| time | 训练时长(小时),优先于epochs | None | 按实际训练时长需求设 |
| patience | 早停等待周期(无明显改进) | 50 | 看模型训练情况调整 |
| cos_lr | 是否用余弦学习率调度器 | False | 按训练策略决定 |
| close_mosaic | 何时关闭马赛克增强 | 10 | 按训练需求调整 |
| single_cls | 多类数据是否当单类训练 | False | 特殊场景调整 |
| rect | 特殊的矩形训练模式 | False | 特殊场景使用 |
| deterministic | 是否结果确定 | True | 想结果一致就设为True |
| seed | 随机种子(重现结果用) | 0 | 要重现结果就确定值 |
| verbose | 是否详细输出 | False | 开发调试设为True |
| exist_ok | 能否覆盖已有实验 | False | 重复实验时设为True |
| name | 实验名 | None | 自定义方便区分实验 |
| project | 项目名 | None | 按需求自定义 |
| save_period | 多久保存一次训练成果,<1不保存 | -1 | 按需设置 |
| plots | 训练/验证时是否保存图表 | False | 需可视化时设为True |
(3)验证过程-参数说明
| 参数 | 描述 | 默认值 | 验证参数设置 |
|---|---|---|---|
| data | 数据文件的路径,例如coco128.yaml | None | 检查文件是否存在,路径是否正确 |
| imgsz | 输入图像的大小,以整数表示 | 640 | 确保值符合模型输入要求,避免过大或过小影响性能 |
| batch | 每批图像的数量(AutoBatch为 -1) | 16 | 根据硬件资源调整,避免内存溢出或利用率过低 |
| conf | 用于检测的对象置信度阈值 | 0.001 | 根据实际检测效果和数据特点进行调整和验证 |
| iou | NMS(非极大抑制)用的交并比(IoU)阈值 | 0.6 | 通过测试集验证是否能有效过滤重叠框 |
| max_det | 每张图像的最大检测数量 | 300 | 依据检测任务需求和图像内容确定合适的值 |
| half | 使用半精度(FP16) | True | 验证硬件是否支持半精度计算,以及对精度的影响 |
| device | 运行所用的设备,例如cuda device = 0/1/2/3或device = cpu | None | 检查设备是否可用,驱动是否安装正确 |
| dnn | 使用OpenCV DNN进行ONNX推理 | False | 确认OpenCV版本是否支持DNN相关功能 |
| plots | 在训练期间显示图表 | False | 检查显示设备或相关绘图库是否能正常工作 |
| rect | 矩形验证,每批图像为了最小填充整齐排列 | False | 通过可视化或数据检查验证排列效果 |
| split | 用于验证的数据集分割,例如 'val'、'test'或 'train' | val | 确认分割后的数据集符合预期,数据分布合理 |
| save_json | 将结果保存至JSON文件 | False | 验证文件保存的权限、路径是否可操作 |
| save_hybrid | 保存混合版本的标签(标签 + 额外预测) | False | 检查相关数据结构是否支持混合保存 |
-
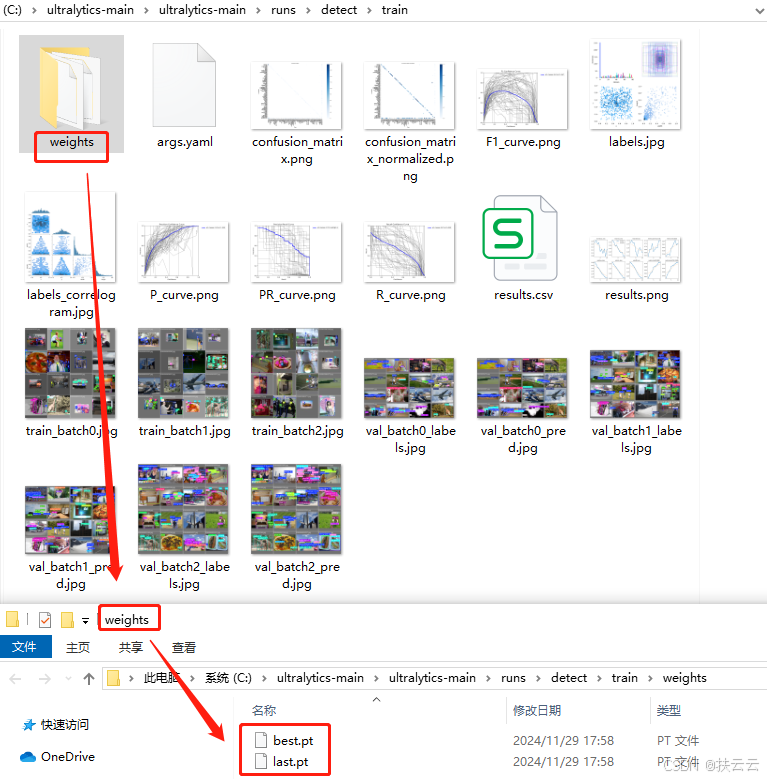
最终在.../runs/detect目录下生成两个文件夹:train(训练结果)和train2(验证结果)。
3、训练和验证---结果
(1)训练结果
【1】训练结果展示
【2】训练文件/文件夹说明
| 文件名称 | 说明 | 如何判断模型好坏 |
|---|---|---|
| best.pt | 损失值最小的模型文件 | 损失值小,模型可能较好, 但还要看在新数据上的表现。 |
| last.pt | 训练到最后的模型文件 | 最后损失稳定,评估指标不错, (如精确度、召回率等) 模型较好;否则可能有问题。 |
| args.yaml | 模型训练的配置参数 | 合理的参数是模型训练好的前提, 不合理可能导致模型不好。 |
| confusion_matrix.png | 混淆矩阵,展示分类模型性能,每行代表预测类别,每列代表实际类别,对角线数值表示正确预测数量,颜色深浅反映数量多少 | 对角线数值越大,模型分类越准; 非对角线数值小,混淆少,模型越好。 |
| confusion_matrix_ normalized.png | 标准化混淆矩阵,显示每个类别的预测正确比例,有助于比较不同类别预测准确性(类别样本数量不平衡时) | 比例越高(即越接近1), 模型对各分类预测越准,模型越好。 |
| F1_curve.png | F1 - 置信度曲线,显示F1得分随置信度阈值的变化,F1得分是精确度和召回率的调和平均值,曲线峰值表示最佳平衡点 | 峰值越高,模型在不同置信度下精确度 和召回率平衡得越好。 |
| labels.jpg | 标签分布图和边界框分布图,柱状图显示不同类别实例分布数量,散点图展示目标检测任务中边界框空间分布情况 | 标签分布均匀、边界框分布正常, 有助于模型学习,模型可能更好。 |
| labels_correlogram.jpg | 标签相关图,提供不同类别标签之间关系以及在图像中位置的相关性,助于理解识别时的关联或混淆 | 能正确反映类别关系, 模型对类别理解好,性能可能好。 |
| P_curve.png | 精确度 - 置信度曲线,展示模型预测精确度随置信度阈值的变化,精确度是正确正例与预测为正例总数的比值 | 曲线整体高且平稳, 模型在不同阈值下精确度好。 |
| PR_curve.png | 精确度 - 召回曲线,展示模型精确度与召回率之间的关系,理想情况应保持两者良好平衡 | 曲线越靠近右上角, 模型综合性能越好。 |
| R_curve.png | 召回 - 置信度曲线,显示模型召回率随置信度阈值的变化,召回率是正确预测正例与实际正例总数的比值 | 曲线整体高, 模型找出正例的能力强。 |
| results.png | 训练结果图表,展示模型训练过程中的性能变化,如损失函数变化和评估指标变化 | 损失下降且稳定, 评估指标上升且稳定在高位, 模型训练效果好。 |
| results.csv | 训练结果数据,包含模型训练过程中的性能变化数据,如精确度、召回率和mAP等评估指标 | 指标数值越高, 模型在对应任务性能越好。 |
results.csv表格内几个关键的指标:
| 指标名称 | 定义 | 作用 |
|---|---|---|
| metrics/precision(B) | Precision(精确率):在所有被预测为正例的样本中,真正为正例的比例。在目标检测中,表示预测出的目标中真正是目标的比例。 | 衡量模型预测的准确性,即模型预测出的结果中有多少是正确的。 |
| metrics/recall(B) | Recall(召回率):在所有真实为正例的样本中,被预测为正例的比例。在目标检测中,表示实际存在的目标中被模型检测出来的比例。 | 衡量模型对正例的检测能力,即模型能够检测出多少实际存在的目标。 |
| metrics/mAP50(B) | mAP50(平均精度均值,IoU阈值为50%):在不同物体类别上,模型预测结果与真实结果的交并比(IoU)大于50%时的平均精度。 | 衡量模型在不同类别上的检测精度,是目标检测中常用的评估指标之一。 |
| metrics/mAP50 - 95(B) | mAP50 - 95(平均精度均值,IoU阈值从50%到95%):在不同物体类别上,模型预测结果与真实结果的交并比(IoU)在50%到95%之间的平均精度。 | 与mAP50相比,更全面地衡量模型在不同IoU阈值下的性能,能够更准确地反映模型的检测能力。 |
【3】示例分析
下面两个训练结果哪个训练模型的效果较好?
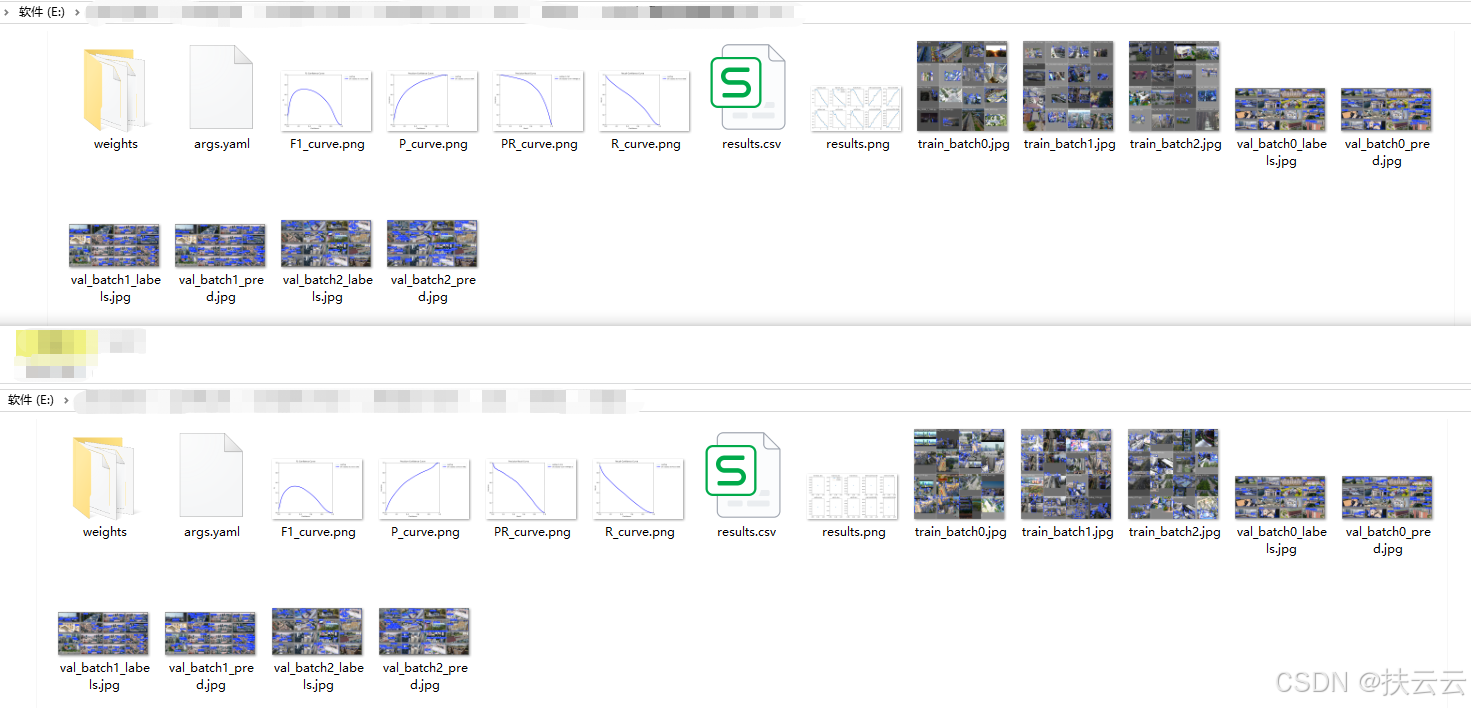
第一个训练模型的效果较好,从以下几点分析:
-
F1_curve.png峰值高
-
P_curve.png曲线整体高且平稳
-
PR_curve.png曲线越靠近右上角
-
R_curve.png曲线整体高
-
......
(2)验证结果
【1】验证结果展示

【2】验证文件/文件夹说明
| 文件/曲线名称 | 含义 | 如何判断模型好坏 |
|---|---|---|
| confusion_matrix.png | 以矩阵形式展示模型预测与实际类别的对比情况,行代表实际类别,列代表预测类别,对角线为正确预测数 | 对角线数值越大,非对角线数值越小,表明模型分类越准确,模型性能越好 |
| confusion_matrix _normalized.png | 每个元素表示预测标签与真实标签之间的比例 | 比例越高(即越接近1),表明模型对各分类预测越准确,模型性能越好 |
| F1_curve.png | F1分数(精确率和召回率的调和平均值)与置信度之间的关系曲线 | 峰值越高,模型在不同置信度下精确度 和召回率平衡得越好。 |
| P_curve.png | 精确率和置信度之间的关系曲线 | 曲线整体高且平稳, 模型在不同阈值下精确度好。 |
| PR_curve.png | 精确率 - 召回率之间的关系曲线 | 曲线越靠近右上角, 模型综合性能越好。 |
| R_curve.png | 召回率和置信度之间的关系曲线 | 曲线整体高, 模型找出正例的能力强。 |
| val_batch0_labels.jpg | 验证集第0批次的实际标签图像 | 与对应预测结果对比,匹配度高则模型性能好 |
| val_batch0_pred.jpg | 验证集第0批次的模型预测结果图像 | 与val_batch0_labels.jpg对比,若预测的目标类别和位置与实际标签一致,则模型性能较好 |
| val_batch1_labels.jpg | 验证集第1批次的实际标签图像 | 与对应预测结果对比,匹配度高则模型性能好 |
| val_batch1_pred.jpg | 验证集第1批次的模型预测结果图像 | 与对应批次的标签图像对比,若预测结果准确(检测到的目标类别和位置与实际标签一致),则模型性能较好 |
| val_batch2_labels.jpg | 验证集第2批次的实际标签图像 | 与对应预测结果对比,匹配度高则模型性能好 |
| val_batch2_pred.jpg | 验证集第2批次的模型预测结果图像 | 与对应批次的标签图像对比,若预测结果准确(检测到的目标类别和位置与实际标签一致),则模型性能较好 |
【3】示例分析
下面两个验证结果哪个验证模型的效果较好?
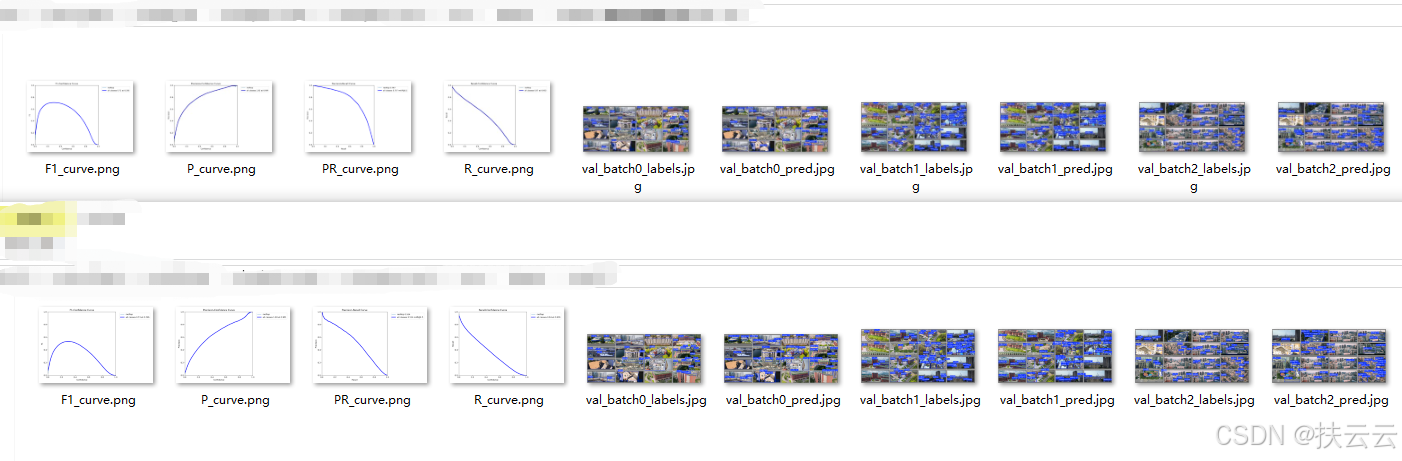
第一个训练模型的效果较好,从以下几点分析:
-
F1_curve.png峰值高
-
P_curve.png曲线整体高且平稳
-
PR_curve.png曲线越靠近右上角
-
R_curve.png曲线整体高
-
......
七、预测
1、预测准备
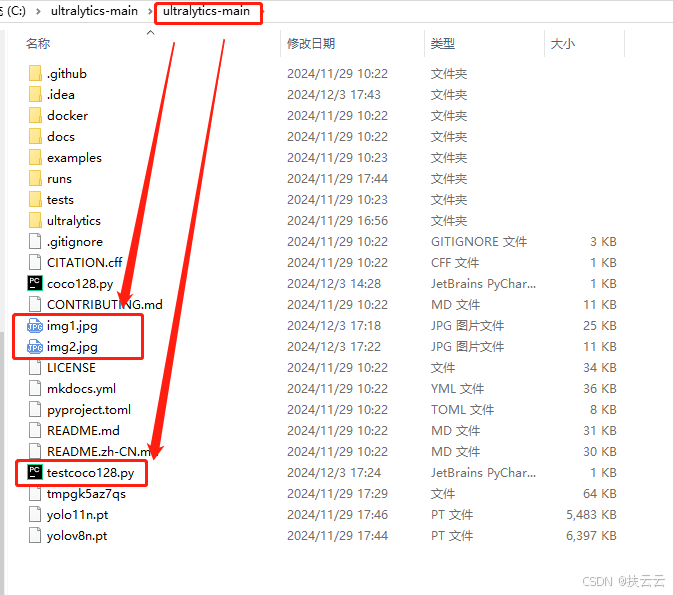
(1)下载预测图片
先在网上找两张图片(要求含有coco128数据集类别),并下载图片img1和img2放在.../ultralytics-main/ultralytics-main目录下,下面是我在网上找的两张图片:
img1:

img2:

(2)新建一个py环境
在.../ultralytics-main/ultralytics-main目录下新建一个python环境提供给预测代码使用。
2、预测示例代码
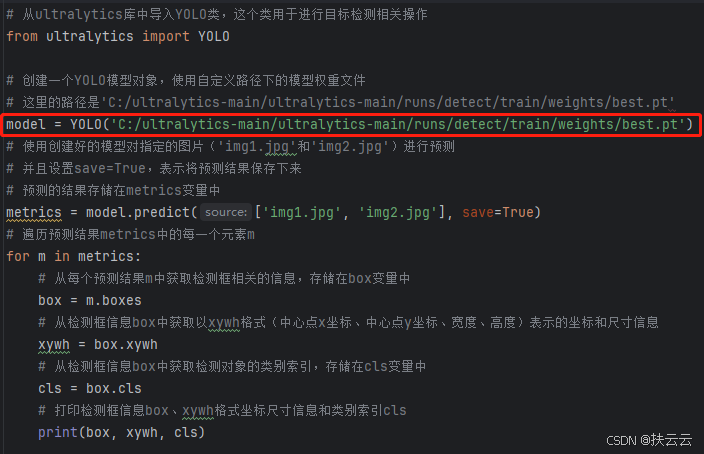
(1)图片预测代码
# 图片预测
from ultralytics import YOLO
model = YOLO('C:/ultralytics-main/ultralytics-main/runs/detect/train/weights/best.pt')
metrics = model.predict(['img1.jpg', 'img2.jpg'], save=True)
for m in metrics:
box = m.boxes
xywh = box.xywh
cls = box.cls
print(box, xywh, cls)上述代码已将模型路径更改为训练得到的best.pt文件路径。

(2)代码的具体含义
3、预测结果
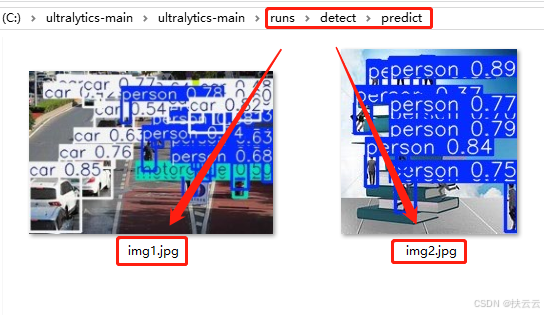
(1)预测结果展示
在.../runs/detect/predit目录下生成2张预测后图片,含类别和置信度。(置信度是模型对其单次预测结果的确信程度,通常表现为概率值。模型对其预测的置信度高并不总能保证预测的准确性,因为模型可能会过度自信地做出错误的预测,特别是在面对分布偏移或未见过的数据时。)
(2)预测参数说明
| 名称 | 描述 | 默认值 |
|---|---|---|
| source | 图像或视频的源目录 | 'ultralytics/assets' |
| conf | 检测对象的置信度阈值 | 0.25 |
| iou | 用于NMS的交并比(IoU)阈值 | 0.7 |
| imgsz | 图像大小,可以是标量或(h, w)列表,例如(640, 480) | 640 |
| half | 使用半精度(FP16) | False |
| device | 运行设备,例如 cuda device = 0/1/2/3 或 device = cpu | None |
| show | 如果可能,显示结果 | False |
| save | 保存带有结果的图像 | False |
| save_txt | 将结果保存为.txt文件 | False |
| save_conf | 保存带有置信度分数的结果 | False |
| save_crop | 保存带有结果的裁剪图像 | False |
| show_labels | 隐藏标签 | True |
| show_conf | 隐藏置信度分数 | True |
| max_det | 每张图像的最大检测数量 | 300 |
| vid_stride | 视频帧速率跳跃 | False |
| stream_buffer | 缓冲所有流媒体帧(True)或返回最新帧(False) | False |
| line_width | 边框线宽度。如果为None,则按图像大小缩放。 | None |
| visualize | 可视化模型特征 | False |
| augment | 应用图像增强到预测源 | False |
| agnostic_nms | 类别不敏感的NMS | False |
| retina_masks | 使用高分辨率分割掩码 | False |
| classes | 按类别过滤结果,例如 classes = 0,或 classes = [0, 2, 3] | None |
| boxes | 在分割预测中显示框 | True |
(3)预测输出参数说明
| 输出参数 | 说明 |
|---|---|
| cls | 张量,存储检测对象的类别索引,索引值对应预定义类别列表,如tensor([0., 5., 0., 0., 0.], device = 'cuda:0')中,0和5分别表示对象所属类别索引 |
| conf | 张量,存储检测对象的置信度分数,分数越高表明模型对检测结果越有信心 |
| data | 张量,包含检测对象的边界框信息(如[x, y, width, height, confidence, class],其中[x, y]可能为中心点坐标,width和height为框的宽高,confidence为置信度,class为类别相关信息) |
| xywh | 边界框坐标与尺寸表示,格式为[中心点x坐标, 中心点y坐标, 宽度, 高度],便于计算框中心与大小,常用于交并比计算等 |
| xywhn | 归一化的边界框坐标与尺寸(相对于图像尺寸),取值范围0 - 1,便于处理不同尺寸图像 |
| xyxy | 边界框坐标表示,格式为[左上角x坐标, 左上角y坐标, 右下角x坐标, 右下角y坐标],直观表示框的对角顶点坐标,常用于可视化等操作 |
| xyxyn | 归一化的xyxy格式边界框坐标,使坐标表示与图像尺寸无关,便于不同大小图像的统一处理 |
| is_track | 布尔值,表示是否使用跟踪算法跟踪检测对象,在视频对象跟踪场景中起重要作用 |
| orig_shape | 原始图像的形状(如[高度, 宽度, 通道数]),用于还原图像或按原始尺寸进行比例计算等操作 |
| shape | 处理后的张量形状,反映图像经预处理(如缩放、裁剪等)后的形状,有助于理解数据在模型中的处理情况 |
(4)扩展:视频预测示例代码
考虑到有部分人想使用视频预测,这里补充视频预测示例代码以供学习和参考。
# 视频预测
from ultralytics import YOLO
model = YOLO('C:/ultralytics-main/ultralytics-main/runs/detect/train/weights/best.pt')
video_path = "sp.mp4"
metrics = model.predict(source=video_path, save=True)
for m in metrics:
box = m.boxes
xywh = box.xywh
cls = box.cls
print(box, xywh, cls)总结:实现数据集的训练,需要pt模型文件,数据集【images文件夹(jpg)、label文件夹(txt)】,还有yaml配置文件(一般需要自己配置,指定数据集路径和类型)。
参考资料:



















 1949
1949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











