







前言
论文名称:《Very Deep Convolutional Networks For Large-Scale Image Recognition》
论文地址:https://arxiv.org/abs/1409.1556
VGG是非常经典的卷积神经网络(CNN)架构了,虽然我们现在以及用的很少了,但是其在那个时候也是十分惊艳,并且对后续的卷积神经网络架构带来的深远的影响。VGG由牛津大学视觉几何组(Visual Geometry Group,简称VGG)提出,因此得名。VGG网络以其简洁性和深度而闻名,它在图像识别和分类任务中表现出色,并且在许多计算机视觉竞赛中取得了优异的成绩。
本篇给大家讲述VGG的原理篇,后续会带大家去VGG的实战。
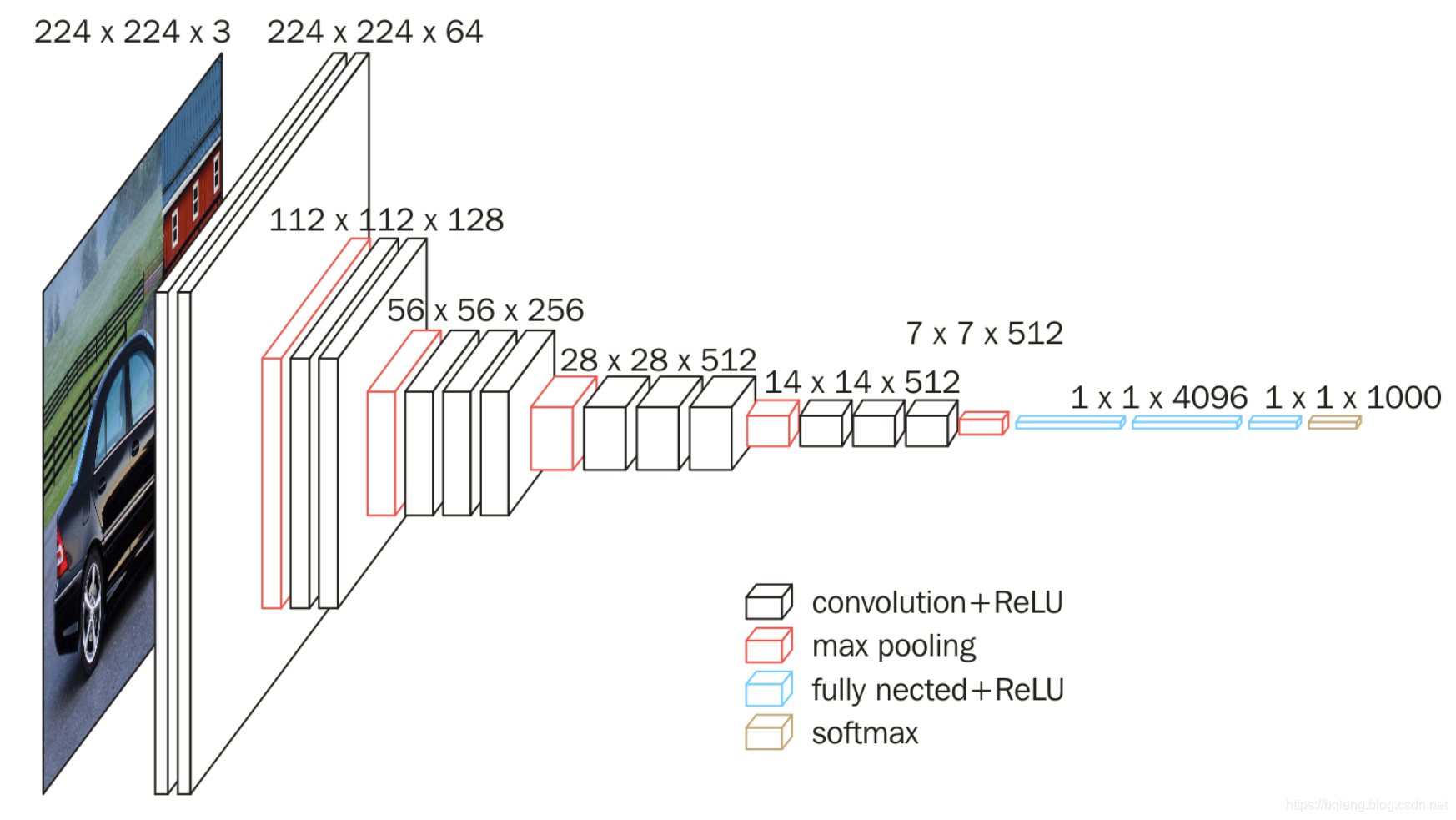
VGG原理概述
在这里我们先补充点背景知识,在VGG出现之前,有的卷积神经网络就是LeNet和AlexNet。
LeNet是卷积神经网络的开创,其定义了卷积三组件:卷积池化全连接,并且是第一个将反向传播用于实际的CNN。然后就是AlexNet。AlexNet首次使用了ReLU激活函数,随机失活等多种策略。
AlexNet在LeNet的基础上加大加深了网络深度,从而取得了更好的效果。那么我们能不能更大更深来获得更好的效果呢?
是的,VGG就出现了。那么来看看VGG都做了些什么。
其实总结我认为就是使用了小卷积。
小卷积
在AlexNet的设计中,作者采用了多种尺寸的卷积核,包括11x11和5x5的大卷积核,以及更多的3x3卷积核。对于stride=4的11x11大卷积核,其设计理念是在网络的初始阶段,由于输入图像的尺寸较大,存在大量的冗余信息。使用大卷积核可以在早期阶段快速捕捉到原始纹理和细节特征的变化。然而,随着网络层数的增加,设计者担心可能会丢失较大局部范围内的特征相关性,因此在后续层中转而使用更多3x3的小卷积核以及一个5x5卷积核来捕捉细节变化。
与AlexNet不同,VGGNet则选择完全采用3x3的卷积核。这一选择背后的原因在于,卷积操作不仅影响计算量,还直接关系到感受野的大小。计算量的大小直接影响到模型是否便于部署到移动设备、是否能够满足实时处理的需求以及训练的难易程度。而感受野的大小则影响到参数的更新、特征图的大小、特征提取的充分性、模型的复杂度以及参数的数量。通过使用3x3的小卷积核,VGGNet能够在保持网络深度的同时,有效地控制计算量和感受野,从而实现更好的性能和效率。
这里又提到两个概念,计算量和感受野。
- 计算量
VGG网络之所以在参数量和计算量上相对减少,主要归功于其设计理念,即使用多个3x3的小卷积核来构建深度网络。与大尺寸卷积核相比,3x3的小卷积核具有更少的参数,这使得网络更加高效。例如,一个3x3卷积核在处理具有64个输入通道的特征图时,只有577(3x3x64)个参数,而一个11x11的卷积核则有7745(11x11x64)个参数。这种参数数量的显著差异意味着使用小卷积核可以大幅减少网络的参数量。
此外,VGG网络通过堆叠多个3x3卷积层而不是增加卷积核的大小来增加网络的深度。这种方法不仅减少了参数数量,还增加了网络的非线性能力,因为每个卷积层后面通常跟着一个ReLU激活函数。与使用大尺寸卷积核的单一层相比,多个小卷积层的堆叠可以提供更好的特征提取能力,同时保持参数和计算量的低效率。
- 感受野
感受野就是神经网络中一个神经元或一个特征图上的位置能够观察到或感受到的输入图像区域的大小。简单来说,感受野定义了神经网络中的某个神经元或特征点在输入空间上所负责的感知范围。什么意思呢?我们以图像举例哈,图中最上层的特征图为2x2,其中每个像素的感受野是多大?就是将其所映射的范围回到最下层的特征图,所能看到的图像的大小。原始图像大小5x5,经过kernel大小为3x3,padding为1,stride为2的卷积后,大小变为3x3,再经过kernel大小为3x3,padding为1,stride为2的卷积后,大小变为2x2,所以最后黄色特征图中每一个特征点在绿色的原始图像上面所能看到的区域大小为7x7。
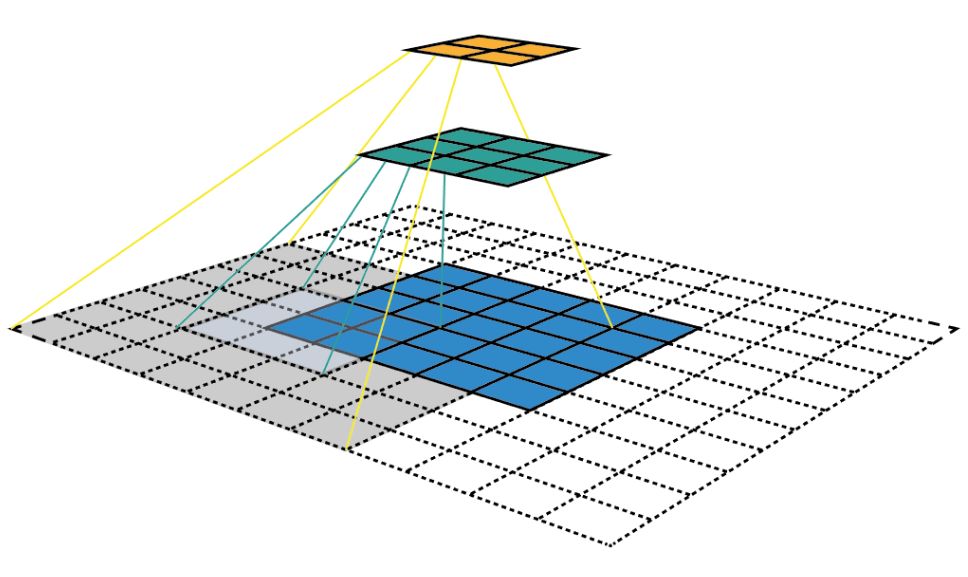
在VGG原论文中,其描述了可以用2个3x3的卷积来代替一个5x5的卷积,可以获得相同的感受野。而3个3x3卷积就可以代替1个7x7的卷积,获得相同的感受野。
于是,在相同感受野的情况下:
堆叠小卷积核相比使用大卷积核具有更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,可使决策函数更加具有辨别能力;此外,3x3比7x7就足以捕获细节特征的变化:3x3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化;3个3x3堆叠近似一个7x7,网络深了两层且多出了两个非线性ReLU函数,网络容量更大,对于不同类别的区分能力更强。
网络架构
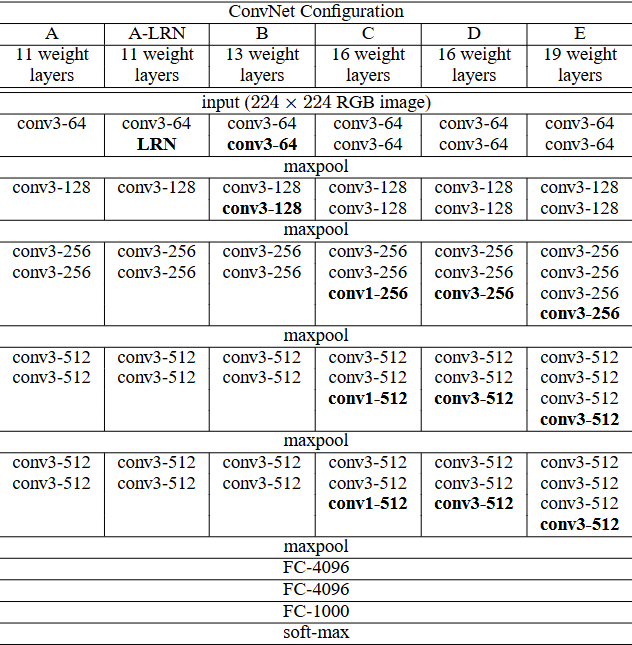
如图便是不同深度的VGG网络了。通过小卷积减少参数量计算量,能够将网络扩展的更加深,带来更多的非线性变换,来更好的提取出图像是语义特征。其中VGG16和VGG19是用的比较多比较常用的了。其实可以明显的看出其特征提取的网络分为5个stage,其中以Maxpool层为界限,每个stage往下通道翻倍,宽高减半。
VGG代码解析
在原理篇的时候我们已经讲了VGG的基本结构,我们就是根据其来构建。(其代码与pytroch官方代码基本一致)
我们设置不同VGG网络深度的配置文件cfgs,通过make_layers函数来构建其特征提取的整个网络。
其实还是很容易理解的。通过配置通道数,加上M代表最大池化层,然后构建整个VGG的特征提取层。
cfgs= {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],# A is vgg11
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],# B is vgg13
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],# D is vgg16
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512,"M"],# E is vgg19
}
def make_layers(cfg, batch_norm= False) -> nn.Sequential:
layers= []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
v = cast(int, v)
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
然后就是构建整个VGG的网络架构了,还记得那个架构图吗?特征提取网络之后就接一个全局池化层,在接三个全连接层,最后输出图像识别的结果。学会这样的写法,基本上所有的网络构建都大差不差的。我们构建完整个网络后就是参数的初始化,然后就是网络的forward函数的构建了。
class VGG(nn.Module):
def __init__(
self, features: nn.Module, num_classes: int = 1000, init_weights: bool = True, dropout: float = 0.5
) -> None:
super().__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, num_classes),
)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
然后我们就可以构建不同深度的VGG网络了。
def vgg11(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["A"], batch_norm=False), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg11']))
return model
def vgg11_BN(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["A"], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg11_BN']))
return model
def vgg13(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["B"], batch_norm=False), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg13']))
return model
def vgg13_BN(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["B"], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg13_BN']))
return model
def vgg16(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["D"], batch_norm=False), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg16']))
return model
def vgg16_BN(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["D"], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg16_BN']))
return model
def vgg19(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["E"], batch_norm=False), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg19']))
return model
def vgg19_BN(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["E"], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg19_BN']))
return model
完整代码如下:
from typing import cast
import torch
import torch.nn as nn
from torch.nn.functional import batch_norm
from torch.utils import model_zoo
__all__ = ["vgg11","vgg11_BN","vgg13","vgg13_BN","vgg16","vgg16_BN","vgg19","vgg19_BN"]
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-8a719046.pth',
'vgg11_BN': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-19584684.pth',
'vgg13_BN': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg16_BN': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg19_BN': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}
cfgs= {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}
def make_layers(cfg, batch_norm= False) -> nn.Sequential:
layers= []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
v = cast(int, v)
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
class VGG(nn.Module):
def __init__(
self, features: nn.Module, num_classes: int = 1000, init_weights: bool = True, dropout: float = 0.5
) -> None:
super().__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, num_classes),
)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def vgg11(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["A"], batch_norm=False), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg11']))
return model
def vgg11_BN(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["A"], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg11_BN']))
return model
def vgg13(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["B"], batch_norm=False), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg13']))
return model
def vgg13_BN(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["B"], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg13_BN']))
return model
def vgg16(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["D"], batch_norm=False), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg16']))
return model
def vgg16_BN(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["D"], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg16_BN']))
return model
def vgg19(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["E"], batch_norm=False), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg19']))
return model
def vgg19_BN(pretrained=True,**kwargs):
model = VGG(make_layers(cfgs["E"], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg19_BN']))
return model
if __name__ == '__main__':
model = vgg16()
print(model)
img = torch.randn(1, 3, 224, 224)
output = model(img)
print(output.size())

















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









