







1.卷积神经网络与传统卷积网络的区别
主要区别在与:在传统的卷积神经网络中,输入的是一维向量,如果想输入一张图片,必须将其拉平,而卷积神经网络则是直接输入一张图片(长x宽x通道数),不需要拉平,而且卷积神经网络多了一个深度(depth)概念
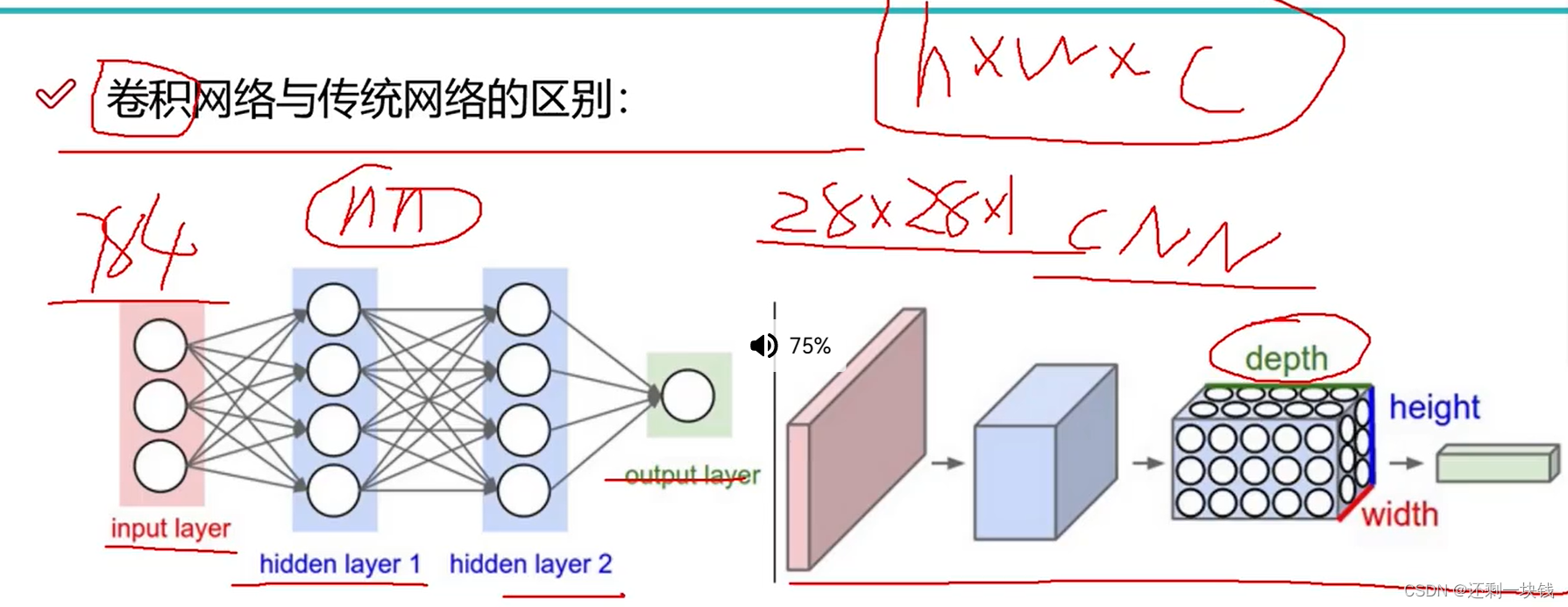
2.卷积神经网络整体架构
1.输入层
就是我们输入的图像大小(长x宽x通道数)
2.卷积层
作用是提取特征
卷积层工作原理
如我们输入一张图片(640x640x3),首先我们会将这张图片按照通道数拆开,得到三张RGB原单色图像,对于每一张单色图像(如R图像)它的每一个像素值都会对应着一个权重参数,这个权重参数会参与到计算。得到一张R单色原图后,我们首先会创建一个滑动小块,滑块的大小就是卷积核大小,滑块每一次移动的距离就是滑动的步长,在小滑块内部的像素会与其对应的权重参数进行内积计算然后相加最后再加一个偏置项得到一个值,这个值就代表了这个小滑块内部的代表值,待小滑块走完整个R单色原图后,我们会得到一个新的R单色图,G,B原单色图也是如此,都会得到新的单色图,最后将RGB新单色图加在一起,然后再加一个偏执项就得到新的图像(拥有RGB的图像,此时产生一个特征图),下一次再卷积时,同步上面的操作,每一次卷积后得到的都是特征图(长x宽x通道数),只不过长宽的大小发生了变化。
如果一张图片经过N次卷积,每一次卷积都会产生一个特征图,则N次卷积后,则产生:长x宽xN,这样的大特征图
一个小滑块,只产生一个值,滑动一次产生一个
一般卷积核都是这样表示:5x5x6: 5x5是大小,6是卷积核个数,也就是产生特征图个数
卷积一次之后,特征图大小计算
我们卷积一次后,图像的大小(长,宽)会发生变化,因为我们使用了滑块
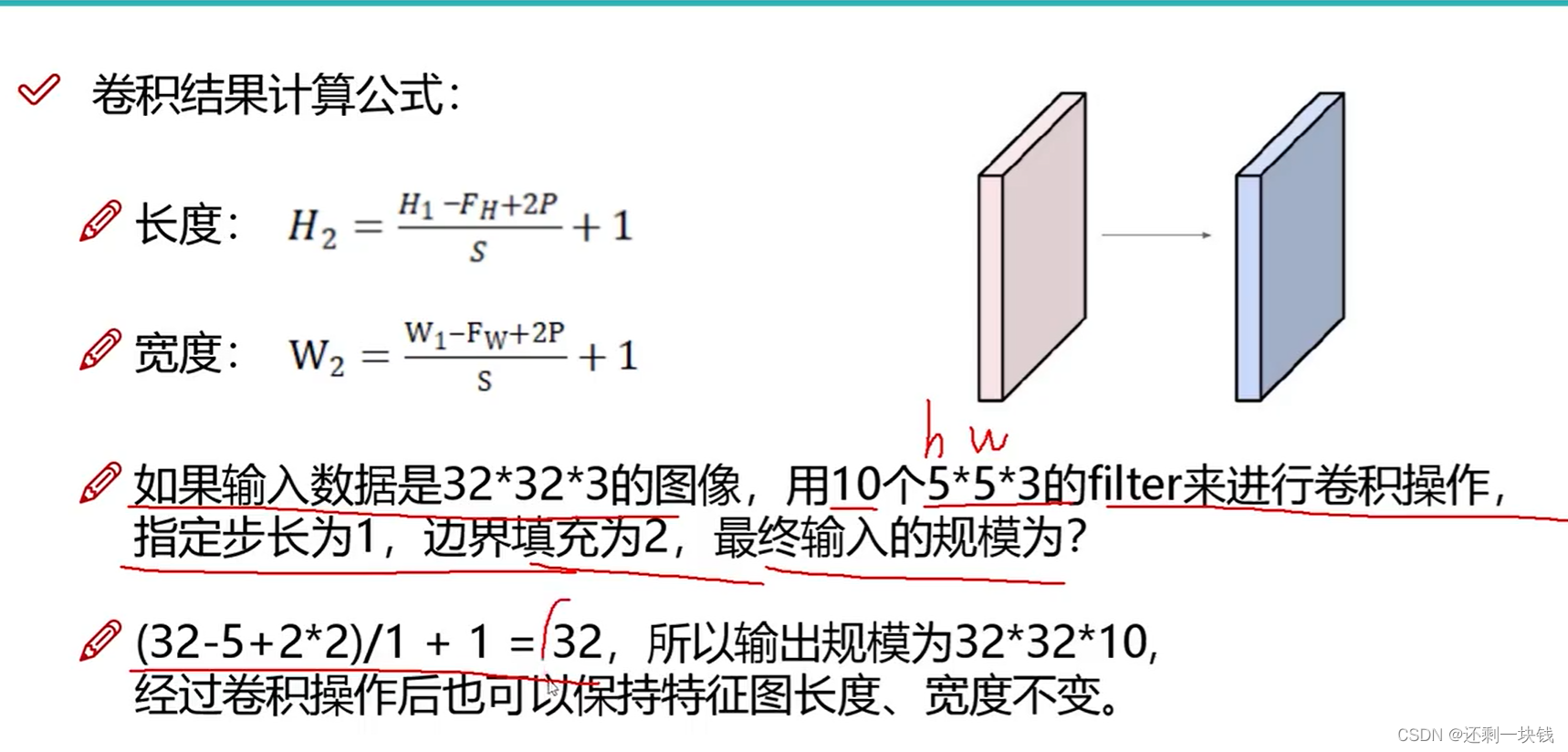
H 1 , W 1 是输入图像的大小, 32 ∗ 32 H1,W1是输入图像的大小,32*32 H1,W1是输入图像的大小,32∗32
F H , F w 是卷积核的长和宽,为 5 ∗ 5 FH,Fw是卷积核的长和宽,为5*5 FH,Fw是卷积核的长和宽,为5∗5
2 p : p 是填充的边界,就是围着图像外面添加几圈 0 2p:p是填充的边界,就是围着图像外面添加几圈0 2p:p是填充的边界,就是围着图像外面添加几圈0
s : 是滑动步长 s:是滑动步长 s:是滑动步长
10 个 5 ∗ 5 ∗ 3 介绍: 10 是卷积核个数,也就是特征图个数, 5 ∗ 5 是卷积核的宽和高, 3 是卷积的通道,因为我的原图像有三个通道 10个5*5*3介绍:10是卷积核个数,也就是特征图个数,5*5是卷积核的宽和高,3是卷积的通道,因为我的原图像有三个通道 10个5∗5∗3介绍:10是卷积核个数,也就是特征图个数,5∗5是卷积核的宽和高,3是卷积的通道,因为我的原图像有三个通道
常用参数
**步长:**就是滑块一次移动多大,步长越小对特征提取越细,但速度较慢,图像常用为1
**卷积核尺寸:**就是我们滑块的大小,卷积核尺寸越小,对特征提取越细,速度越慢,一般使用3x3
边缘填充:由于步长选择,有些元素重复加权贡献的,越往里的点贡献多,越往外的点贡献少,是边界点贡献多些,在外面加上一圈0,可以弥补一些边界特征缺失)zero padding 以0为值进行边缘填充
**卷积核个数:**最后要得到多少个特征图,注意的是每个卷积核都是不一样的
**卷积参数共享:**由于每一个像素都会对应一个特定的权重参数,卷积核在扫描图像的过程中,每走一步都会进行计算,而且由于每一像素权重参数不一样,所以会导致计算更大,卷积权重参数共享其实就是用特定的权重参数,来扫描整张图片,每一次滑动,使用的权重参数都一样
**激活函数:**卷积与激活函数是绑定的
激活函数的作用:
提供网络的非线性建模能力。如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机。如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
常见的激活函数有:
- Sigmoid激活函数
- 也称为S型生长曲线,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的阈值函数,将变量映射到0,1之间 。
- Tanh激活函数
- Tanh 激活函数又叫作双曲正切激活函数,在数学中,双曲正切"Tanh"是由基本双曲函数双曲正弦和双曲余弦推导而来
- 优点:比Sigmoid函数收敛速度更快,输出以0为中心。
- 缺点:由于饱和性产生的梯度消失
在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值。
- Relu激活函数
- 该函数明显优于前面两个函数,是现在使用最广泛的函数
- 当输入 x<0 时,输出为 0,当 x> 0 时,输出为 x。该激活函数使网络更快速地收敛。它不会饱和,即它可以对抗梯度消失问题,至少在正区域(x> 0 时)可以这样,因此神经元至少在一半区域中不会把所有零进行反向传播。由于使用了简单的阈值化(thresholding),ReLU 计算效率很高。
3.池化层
作用是压缩特征
卷积后我们的特征可能太多了,有些特征是我们不需要的,所以就去掉一些不必要的特征
池化层是不改变特征图的个数的,改变的只是图像的宽高,依此来减少参数特征
没有涉及到任何的矩阵运算
方法
**最大池化:**其实超级简单,拿到一个特征图后,先将其拆分成RGB三个原色图,然后指定一个小方块大小,对RGB三种原色图进行切分,如R原色图大小是64x64,使用4x4大小对于切分,则一共可以切16个小块,然后取每个小块的最大值,最为该小块的最小值,最后将这16个值重新拼接成一个新的R色图,BG原色图也是如此,最后再将RGB新原色图,拼接成一个新的特征图,据此完成一个特征图的最大池化,其他特征图同上,完成全部后,在将他们重新合并
**平均池化:**求每个方块的平均值,其他同上
随机池化:同上
中值池化:同上
组合池化:同上
4.全连接层(fc)
我们经过上面的卷积和池化后,得到的是一个大特征图(长x宽x通道数x特征图个数),是无法进行我们想要的效果的,如分类,
全连接层的作用就是将上面的大特征图变成一条很长很长的特征向量,大小是长x宽x通道数x特征图个数,之后就可以进行我们的分类效果了
全连接层=拉长特征图+分类效果
算一个网络的时候有多少层,我们只看带参数的,只有卷积层和全连接层带参数(激活函数),这俩有多少个,就有多少层
卷积层、池化层、激活函数等的作用是用来提取特征(将原始数据映射到隐藏层特征空间),而全连接层的作用就是分类(将学到的特征表示映射到样本标记空间当中)
在 CNN 结构中,经多个卷积层和池化层后,全连接层中的每个神经元与其前一层的所有神经元进行全连接.全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息.为了提升 CNN 网络性能,全连接层每个神经元的激活函数按你的任务目的选择,分类or回归)。
如在分类中,全连接层的神经元的个数,就是我们想要分类的标签种类
补充知识
**感受野:**其实就是后面一层结构中的某一个像素值,可以感受到前面层中有多少个像素参与计算。越大越好
3.常用网络
Alexnet网络:了解
vgg网络:经典
残差网络:Resnet















 222
222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









