






一、免费查重网站
学信网作为国内权威的高等教育学生信息服务平台,自2021年起联合万方数据推出毕业论文免费查重服务,为应届毕业生带来重大利好。这项服务的推出,源于过去毕业生在论文查重过程中面临的诸多困境,如网络查重渠道鱼龙混杂、检测报告真假难辨以及论文泄露风险等。学信网的免费查重服务犹如一缕春风,为毕业生提供了正规且安全的文献相似性检测渠道,帮助他们在论文定稿前精准定位重复内容,及时进行修改完善,从而提升论文质量,确保学术诚信。
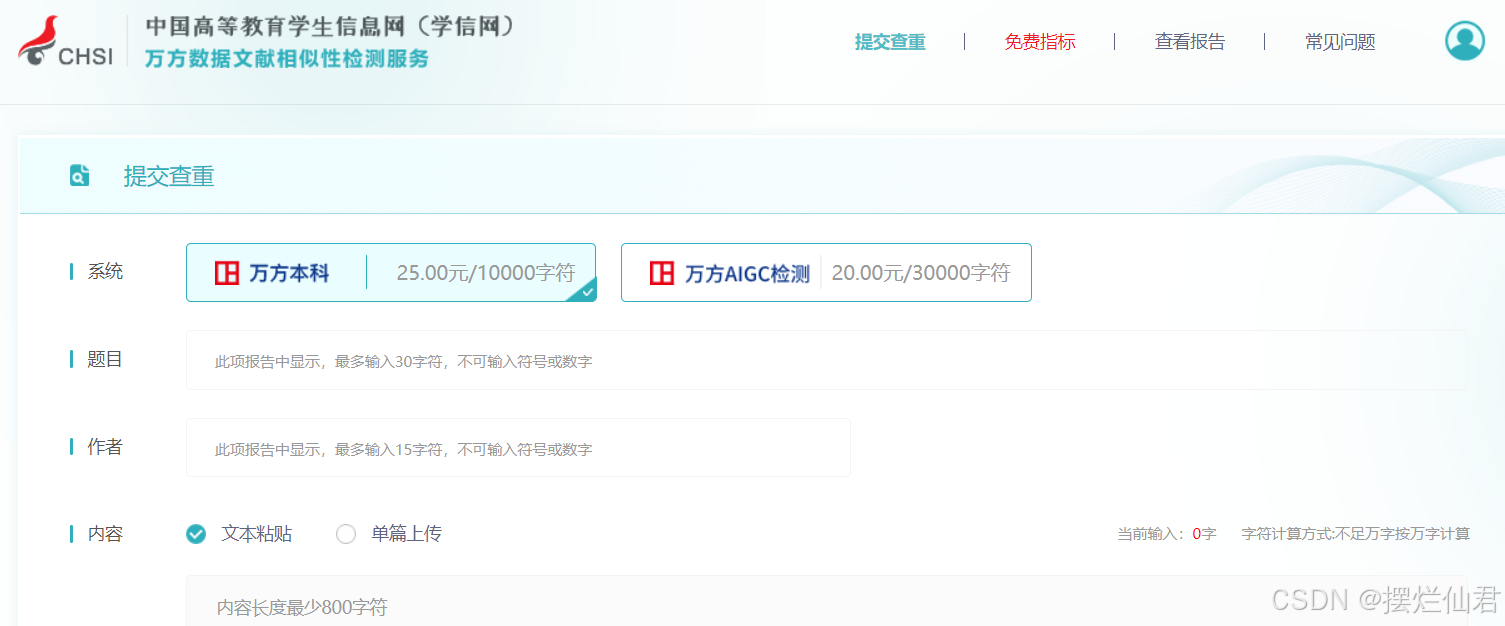
免费查重服务面向本科、硕士和博士三个层次的应届毕业生,每位符合条件的学生可使用学信网账号获得一次免费查重机会。具体操作流程简单便捷,学生只需登录学信网万方数据文献相似性检测系统,按照页面提示选择检测库、上传论文文档并确认提交,系统会在24小时内反馈查重报告。这一过程不仅节省了毕业生的经济支出,还极大地简化了查重流程,让学术诚信的检测变得触手可及。
学信网的查重技术由万方数据提供支持,采用先进的“句子级正交基软聚类倒排”检测算法,能够对海量学术文献数据进行全文比对,为学生提供精准详实的相似性检测结果。查重报告会清晰标注论文中的重复部分,并给出具体重复率数值,帮助学生直观了解论文的原创性状况。尽管不同查重系统的算法和数据库存在差异,但学信网查重结果仍具有重要的参考价值,尤其在毕业论文初稿修改阶段,能够为学生提供有效的质量评估依据。
二、论文降重和AIGC率的原理
论文查重系统主要通过文本比对来检测抄袭行为。它会将论文内容与庞大的数据库进行对比,数据库包含了海量的已发表文献、学术论文、网络资源等。查重系统会先对论文进行预处理,这包括去除一些格式元素,如页眉、页脚、引用格式等,然后将文本分割成不同的单元,这些单元可以是句子、段落或者一定的字数长度。
接下来,会运用特定的算法对这些文本单元进行特征提取。常见的算法有基于字符串匹配的算法,例如简单的文本块比对,即将论文中的文本块与数据库中的文本块逐一比对,看是否存在相同的字符序列。还有一种是基于语义的算法,这种算法更高级,它能够理解文本的含义,检测出不同表述但意思相似的内容。例如,当数据库中的原文是 “全球气候变暖导致冰川融化”,而论文中写的是 “地球变暖使得冰川消融”,语义算法可以通过对词义和语境的分析,判断这两句话在语义上相似,从而判定为抄袭。
除了算法,查重系统还会考虑引用的规范。如果论文中的引用符合学术规范,如正确标注了出处,且引用的内容在合理的范围内,查重系统会对这部分内容进行标注,使其不计入抄袭部分或者按照引用的规则来判定。
三、神奇的小代码来扰乱查重网站
由上所述,查重网站的原理是把文档中的文字提取出来和别人的文章进行对比,如果扰乱提取出来的文字,那么就可以很nice降低查重和AIGC。而我的朋友,这个查重方法是无法提取图片的。下面是一个将 Word 文档中的连续句子文字转换为图片的 Python 代码示例。这个代码会读取 Word 文档中的所有段落,然后将每个段落转换为一张图片。
import os
from docx import Document
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
def text_to_image(text, filename, font_size=16, width=600, height=200):
"""
将转换文字为图片
参数:
text: 要转换的文字
filename: 保存图片的文件名
font_size: 字体大小
width: 图片宽度
height: 图片高度
"""
# 创建一个白色背景的图片
image = Image.new('RGB', (width, height), color='white')
draw = ImageDraw.Draw(image)
# 设置字体(确保使用中文字体)
try:
font = ImageFont.truetype('simhei.ttf', font_size) # 使用黑体字体
except:
font = ImageFont.load_default()
# 计算文本位置居中
text_width = font.getlength(text)
position = ((width - text_width) / 2, (height - font_size) / 2)
# 绘制文字
draw.text(position, text, font=font, fill='black')
# 保存图片
image.save(filename)
def word_text_to_images(doc_path, output_folder):
"""
将 Word 文档中的所有段落转换为图片
参数:
doc_path: Word 文档路径
output_folder: 保存图片的文件夹
"""
# 创建输出文件夹(如果不存在)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 加载 Word 文档
doc = Document(doc_path)
image_count = 1
for i, paragraph in enumerate(doc.paragraphs):
# 如果段落不为空,则转换为图片
if paragraph.text.strip():
image_name = f"image_{image_count}.png"
image_path = os.path.join(output_folder, image_name)
# 调整图片大小以适应文本长度
text_length = len(paragraph.text)
width = min(800, max(400, text_length * 8)) # 根据文本长度计算宽度
# 转换为图片
text_to_image(paragraph.text, image_path, font_size=16, width=width, height=40)
print(f"已转换段落 {i+1} 为图片:{image_path}")
image_count += 1
if __name__ == "__main__":
# 设置 Word 文档路径和输出文件夹
doc_path = "your_document.docx" # 替换为你的 Word 文档路径
output_folder = "output_images" # 输出图片的文件夹
# 执行转换
word_text_to_images(doc_path, output_folder)
print(f"\n转换完成!图片已保存到 {output_folder} 文件夹")


















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











