






一、实验介绍
在这一实验中,我们将探索传统上称为前馈网络的神经网络模型,以及两种前馈神经网络:多层感知器和卷积神经网络。多层感知器在结构上扩展了我们在实验3中研究的简单感知器,将多个感知器分组在一个单层,并将多个层叠加在一起。我们稍后将介绍多层感知器,并在“示例:带有多层感知器的姓氏分类”中展示它们在多层分类中的应用。
本实验研究的第二种前馈神经网络,卷积神经网络,在处理数字信号时深受窗口滤波器的启发。通过这种窗口特性,卷积神经网络能够在输入中学习局部化模式,这不仅使其成为计算机视觉的主轴,而且是检测单词和句子等序列数据中的子结构的理想候选。我们在“卷积神经网络”中概述了卷积神经网络,并在“示例:使用CNN对姓氏进行分类”中演示了它们的使用。
在本实验中,多层感知器和卷积神经网络被分组在一起,因为它们都是前馈神经网络,并且与另一类神经网络——递归神经网络(RNNs)形成对比,递归神经网络(RNNs)允许反馈(或循环),这样每次计算都可以从之前的计算中获得信息。在实验6和实验7中,我们将介绍RNNs以及为什么允许网络结构中的循环是有益的。
在我们介绍这些不同的模型时,需要理解事物如何工作的一个有用方法是在计算数据张量时注意它们的大小和形状。每种类型的神经网络层对它所计算的数据张量的大小和形状都有特定的影响,理解这种影响可以极大地有助于对这些模型的深入理解。
二、The Multilayer Perceptron(多层感知器)
多层感知器(MLP)被认为是最基本的神经网络构建模块之一。最简单的MLP是对第3章感知器的扩展。感知器将数据向量作为输入,计算出一个输出值。在MLP中,许多感知器被分组,以便单个层的输出是一个新的向量,而不是单个输出值。在PyTorch中,正如您稍后将看到的,这只需设置线性层中的输出特性的数量即可完成。MLP的另一个方面是,它将多个层与每个层之间的非线性结合在一起。
最简单的MLP,如图所示,由三个表示阶段和两个线性层组成。第一阶段是输入向量。这是给定给模型的向量。在“示例:对餐馆评论的情绪进行分类”中,输入向量是Yelp评论的一个收缩的one-hot表示。给定输入向量,第一个线性层计算一个隐藏向量——表示的第二阶段。隐藏向量之所以这样被调用,是因为它是位于输入和输出之间的层的输出。我们所说的“层的输出”是什么意思?理解这个的一种方法是隐藏向量中的值是组成该层的不同感知器的输出。使用这个隐藏的向量,第二个线性层计算一个输出向量。在像Yelp评论分类这样的二进制任务中,输出向量仍然可以是1。在多类设置中,将在本实验后面的“示例:带有多层感知器的姓氏分类”一节中看到,输出向量是类数量的大小。虽然在这个例子中,我们只展示了一个隐藏的向量,但是有可能有多个中间阶段,每个阶段产生自己的隐藏向量。最终的隐藏向量总是通过线性层和非线性的组合映射到输出向量。
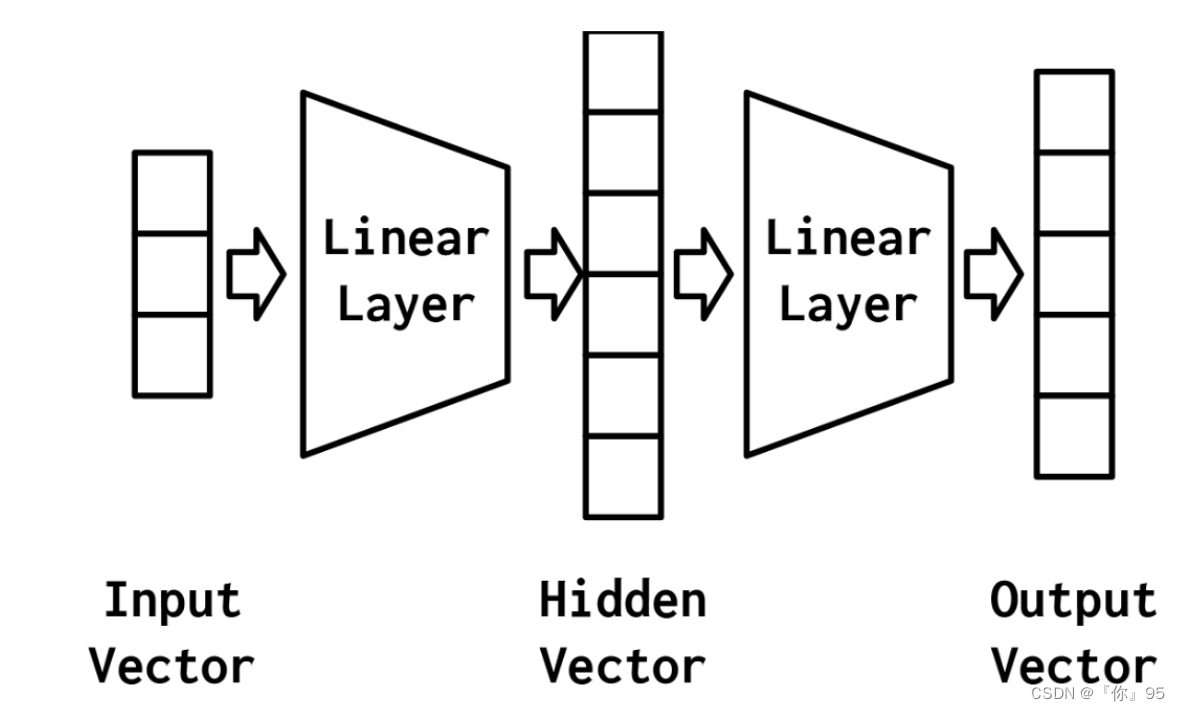
mlp的力量来自于添加第二个线性层和允许模型学习一个线性分割的的中间表示——该属性的能表示一个直线(或更一般的,一个超平面)可以用来区分数据点落在线(或超平面)的哪一边的。学习具有特定属性的中间表示,如分类任务是线性可分的,这是使用神经网络的最深刻后果之一,也是其建模能力的精髓。在下一节中,我们将更深入地研究这意味着什么。
2.1 A Simple Example: XOR
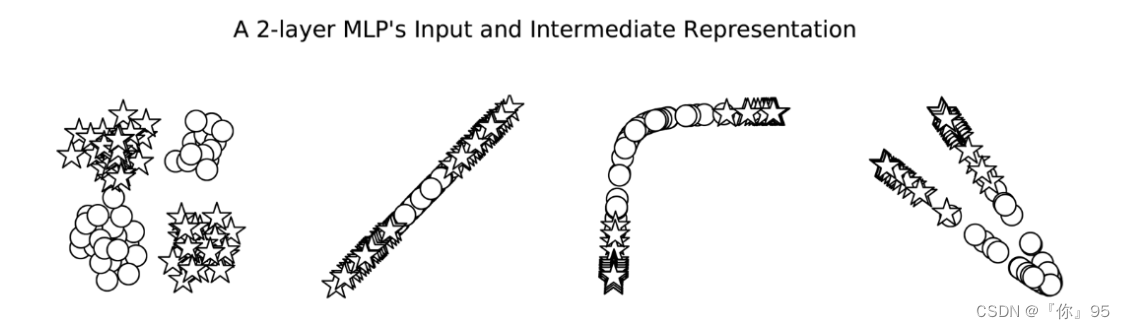
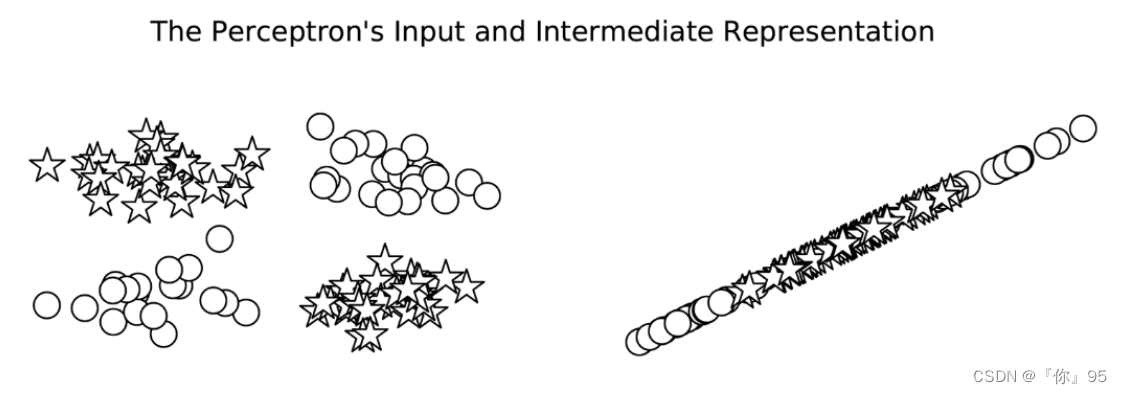
让我们看一下前面描述的XOR示例,看看感知器与MLP之间会发生什么。在这个例子中,我们在一个二元分类任务中训练感知器和MLP:星和圆。每个数据点是一个二维坐标。在不深入研究实现细节的情况下,最终的模型预测如图所示。在这个图中,错误分类的数据点用黑色填充,而正确分类的数据点没有填充。在左边的面板中,从填充的形状可以看出,感知器在学习一个可以将星星和圆分开的决策边界方面有困难。然而,MLP(右面板)学习了一个更精确地对恒星和圆进行分类的决策边界。

在上图中,每个数据点的真正类是该点的形状:星形或圆形。错误的分类用块填充,正确的分类没有填充。这些线是每个模型的决策边界。在边的面板中,感知器学习—个不能正确地将圆与星分开的决策边界。事实上,没有一条线可以。在右动的面板中,MLP学会了从圆中分离星。
虽然在图中显示MLP有两个决策边界,这是它的优点,但它实际上只是一个决策边界!决策边界就是这样出现的,因为中间表示法改变了空间,使一个超平面同时出现在这两个位置上。在图中,我们可以看到MLP计算的中间值。这些点的形状表示类(星形或圆形)。我们所看到的是,神经网络(本例中为MLP)已经学会了“扭曲”数据所处的空间,以便在数据通过最后一层时,用一线来分割它们。
相反,如图所示,感知器没有额外的一层来处理数据的形状,直到数据变成线性可分的。
2.2 Implementing MLPs in PyTorch
在上一节中,我们概述了MLP的核心思想。在本节中,我们将介绍PyTorch中的一个实现。如前所述,MLP除了实验3中简单的感知器之外,还有一个额外的计算层。在我们在例4-1中给出的实现中,我们用PyTorch的两个线性模块实例化了这个想法。线性对象被命名为fc1和fc2,它们遵循一个通用约定,即将线性模块称为“完全连接层”,简称为“fc层”。除了这两个线性层外,还有一个修正的线性单元(ReLU)非线性(在实验3“激活函数”一节中介绍),它在被输入到第二个线性层之前应用于第一个线性层的输出。由于层的顺序性,必须确保层中的输出数量等于下一层的输入数量。使用两个线性层之间的非线性是必要的,因为没有它,两个线性层在数学上等价于一个线性层4,因此不能建模复杂的模式。MLP的实现只实现反向传播的前向传递。这是因为PyTorch根据模型的定义和向前传递的实现,自动计算出如何进行向后传递和梯度更新。
import torch.nn as nn
import torch.nn.functional as F
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(MultilayerPerceptron, self).__init__()
#线性模块fc1和fc2
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
#前向传递
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the MLP
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate = F.relu(self.fc1(x_in))
output = self.fc2(intermediate)
if apply_softmax:
output = F.softmax(output, dim=1)
return output为了演示,我们使用大小为3的输入维度、大小为4的输出维度和大小为100的隐藏维度。请注意,在print语句的输出中,每个层中的单元数很好地排列在一起,以便为维度3的输入生成维度4的输出。
batch_size = 2 # number of samples input at once
input_dim = 3
hidden_dim = 100
output_dim = 4
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)三、实验目的
本实验的目的是:训练一个MLP,使其能对姓氏所在国籍或地区做出预测。
本实验的流程是:数据集划分及预处理➡构建MLP模型➡训练模型➡测试集预测。
首先对姓氏进行预处理,将其转换为数字向量表示,并进行归一化处理。然后构建一个MLP模型,其输入层接受数字化的姓氏特征,隐藏层通过加权求和和激活函数处理输入,最终输出层给出对应国家或地区的分类结果。在使用训练集对模型进行训练后,通过优化算法不断调整模型参数,使其能够较好地拟合训练数据,最后使用测试集评估训练好的模型性能。
四、实验步骤
4.1数据集Surname Dataset
该数据集收集了来自18个不同国家的10,000个姓氏,这些姓氏来源于互联网。该数据集具有一些有趣的特点,第一个特点是相当不平衡,排名前三的数据占数据的60%以上:27%是英语,21%是俄语,14%是阿拉伯语。第二个特点是,有些拼写变体与原籍国联系非常紧密(比如“O ‘Neill”、“Antonopoulos”、“Nagasawa”或“Zhu”)。
我们从一个简化数据集开始,对其进行预处理。第一个目的是减少数据不平衡——原始数据集中70%以上是俄文,这可能是由于抽样偏差或俄文姓氏的增多。为此,我们对标记为俄语的姓氏数据进行下采样。接下来,我们根据国籍对数据集进行分组,并将数据集分为三个部分:70%的训练集,15%的验证集,最后15%的测试集,以便跨这些部分的类标签分布具有可比性。以下为数据预处理代码:
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
"""
初始化数据集类,处理数据分割并计算类别权重。
Args:
surname_df (pandas.DataFrame): 包含姓氏和国籍信息的数据集。
vectorizer (SurnameVectorizer): 用于文本向量化的实例,基于数据集构建。
"""
self.surname_df = surname_df
self._vectorizer = vectorizer
#数据分割
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# 计算类别权重以平衡数据分布
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
# 类方法:从CSV加载数据并创建新的向量化器
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""Load dataset and make a new vectorizer from scratch
Args:
surname_csv (str): location of the dataset
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split=='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
# 类方法:加载数据集和已保存的向量化器
@classmethod
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
"""Load dataset and the corresponding vectorizer.
Used in the case in the vectorizer has been cached for re-use
Args:
surname_csv (str): location of the dataset
vectorizer_filepath (str): location of the saved vectorizer
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(surname_df, vectorizer)
# 静态方法:仅加载向量化器
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
"""a static method for loading the vectorizer from file
Args:
vectorizer_filepath (str): the location of the serialized vectorizer
Returns:
an instance of SurnameVectorizer
"""
with open(vectorizer_filepath) as fp:
return SurnameVectorizer.from_serializable(json.load(fp))
# 保存向量化器到文件
def save_vectorizer(self, vectorizer_filepath):
"""saves the vectorizer to disk using json
Args:
vectorizer_filepath (str): the location to save the vectorizer
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
# 获取向量化器实例
def get_vectorizer(self):
""" returns the vectorizer """
return self._vectorizer
# 设置当前数据集的分割部分
def set_split(self, split="train"):
""" selects the splits in the dataset using a column in the dataframe """
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
# 获取数据集中指定索引的数据项
def __getitem__(self, index):
"""the primary entry point method for PyTorch datasets
Args:
index (int): the index to the data point
Returns:
a dictionary holding the data point's:
features (x_surname)
label (y_nationality)
"""
row = self._target_df.iloc[index]
surname_vector = \
self._vectorizer.vectorize(row.surname)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_vector,
'y_nationality': nationality_index}
def get_num_batches(self, batch_size):
"""Given a batch size, return the number of batches in the dataset
Args:
batch_size (int)
Returns:
number of batches in the dataset
"""
return len(self) // batch_size
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
"""
生成器函数,为给定的数据集创建数据加载器,并确保数据位于目标设备上。
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict4.2处理文本并提取词汇表方法Vocabulary
为了使用字符对姓氏进行分类,我们使用词汇表、向量化器和DataLoader将姓氏字符串转换为向量化的minibatches。这些数据结构与“Example: Classifying Sentiment of Restaurant Reviews”中使用的数据结构相同,它们举例说明了一种多态性,这种多态性将姓氏的字符标记与Yelp评论的单词标记相同对待。数据不是通过将字令牌映射到整数来向量化的,而是通过将字符映射到整数来向量化的。
简要概述一下,词汇表是两个Python字典的协调,这两个字典在令牌(在本例中是字符)和整数之间形成一个双射。也就是说,第一个字典将字符映射到整数索引,第二个字典将整数索引映射到字符。add_token方法用于向词汇表中添加新的令牌,lookup_token方法用于检索索引,lookup_index方法用于检索给定索引的令牌(在推断阶段很有用)。本例中我们使用的是one-hot词汇表,不计算字符出现的频率,只对频繁出现的条目进行限制,这主要是因为数据集很小,而且大多数字符足够频繁。以下为该方法的代码:
class Vocabulary(object):
"""处理文本并提取词汇映射的类"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
初始化词汇表对象。
参数:
token_to_idx (dict, 可选): 初始的令牌到索引映射。
add_unk (bool, 可选): 是否包含未知令牌的标志,默认为True。
unk_token (str, 可选): 表示未知单词的令牌,默认为"<UNK>"。
"""
# 使用提供的字典初始化令牌到索引映射,如果没有则为空
self._token_to_idx = token_to_idx if token_to_idx is not None else {}
# 索引到令牌的反向映射
self._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}
# 未知令牌处理的配置
self._add_unk = add_unk
self._unk_token = unk_token
# 未知令牌的索引,初始化为-1
self.unk_index = -1
# 如果启用未知令牌添加,将其加入词汇表
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
"""将词汇表对象转换为可序列化的字典。"""
return {
'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token
}
@classmethod
def from_serializable(cls, contents):
"""根据序列化的字典重构词汇表对象。"""
return cls(**contents)
def add_token(self, token):
"""向词汇表添加一个令牌并返回其索引。
参数:
token (str): 要添加的令牌。
返回:
index (int): 分配给令牌的索引。
"""
try:
# 如果令牌已存在,则返回其现有索引
index = self._token_to_idx[token]
except KeyError:
# 如果令牌是新的,则分配一个新的索引
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""添加多个令牌到词汇表并返回它们的索引。
参数:
tokens (list): 要添加的令牌列表。
返回:
indices (list): 添加的令牌对应的索引列表。
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""返回令牌的索引,如果未找到,则返回UNK索引。
参数:
token (str): 要查找的令牌。
返回:
index (int): 令牌的索引,或如果令牌不在词汇表中则为UNK索引。
"""
# 如果配置了并且令牌不存在,则返回UNK索引
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
# 如果未启用UNK处理,则对未知令牌报错
return self._token_to_idx[token]
def lookup_index(self, index):
"""根据给定的索引检索对应的令牌。
参数:
index (int): 要查找的索引。
返回:
token (str): 与索引对应的令牌。
异常:
KeyError: 如果索引不存在于词汇表中。
"""
if index not in self._idx_to_token:
raise KeyError(f"索引({index})不在词汇表中")
return self._idx_to_token[index]
def __str__(self):
"""词汇表的字符串表示形式。"""
return f"<词汇表(大小={len(self)})>"
def __len__(self):
"""返回词汇表中的令牌数量。"""
return len(self._token_to_idx)4.3协调词汇表并将其应用的方法SurnameVectorizer
虽然词汇表将单个令牌(字符)转换为整数,但SurnameVectorizer负责应用词汇表并将姓氏转换为向量。实例化和使用中要注意字符串没有在空格上分割。姓氏是字符的序列,每个字符在我们的词汇表中是一个单独的标记。然而,在“卷积神经网络”出现之前,我们将忽略序列信息,通过迭代字符串输入中的每个字符来创建输入的收缩one-hot向量表示。我们为以前未遇到的字符指定一个特殊的令牌,即UNK。由于我们仅从训练数据实例化词汇表,而验证或测试数据中可能有唯一的字符,所以在字符词汇表中仍然使用UNK符号。
虽然我们在这个示例中使用了收缩的one-hot,但是存在另外的可能更优的向量化方法。例如,在“示例:使用CNN对姓氏进行分类”中,将看到一个热门矩阵,其中每个字符都是矩阵中的一个位置,并具有自己的热门向量;在实验5中,将学习嵌入层,返回整数向量的向量化,以及如何使用它们创建密集向量矩阵。以下为SurnameVectorizer类的代码:
class SurnameVectorizer(object):
"""协调词汇表并实现文本向量化的类"""
def __init__(self, surname_vocab, nationality_vocab):
"""
初始化向量化器,需要姓氏词汇表和国籍词汇表。
参数:
surname_vocab (Vocabulary): 姓氏的词汇表实例。
nationality_vocab (Vocabulary): 国籍的词汇表实例。
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""
对提供的姓氏进行向量化处理,采用坍塌的一次热编码方式。
参数:
surname (str): 需要向量化的姓氏字符串。
返回:
one_hot (np.ndarray): 姓氏字符的一次热编码向量。
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""
根据数据集的DataFrame实例化向量化器。
参数:
surname_df (pandas.DataFrame): 包含姓氏和国籍信息的数据集。
返回:
SurnameVectorizer的一个实例,已经根据数据集准备好词汇表。
"""
# 初始化姓氏词汇表,允许出现未知字符标记
surname_vocab = Vocabulary(unk_token="@")
# 初始化国籍词汇表,不包含未知标记,因为假定所有国籍都是已知的
nationality_vocab = Vocabulary(add_unk=False)
# 遍历数据集中的每一条记录
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
# 返回根据数据集构建的向量化器实例
return cls(surname_vocab, nationality_vocab)4.4构建姓氏分类的多层感知器SurnameClassifier
第一个线性层将输入向量映射到中间向量,并对该向量应用非线性。第二线性层将中间向量映射到预测向量。
在最后一步中,可选地应用softmax操作,以确保输出和为1;这就是所谓的“概率”。它是可选的原因与我们使用的损失函数的数学公式有关——交叉熵损失。我们研究了“损失函数”中的交叉熵损失。回想一下,交叉熵损失对于多类分类是最理想的,但是在训练过程中软最大值的计算不仅浪费而且在很多情况下并不稳定。以下为该感知器的代码:
class SurnameClassifier(nn.Module):
"""用于姓氏分类的两层多层感知机(MLP)"""
def __init__(self, input_dim, hidden_dim, output_dim):
"""
初始化方法
参数:
input_dim (int): 输入向量的尺寸
hidden_dim (int): 第一层线性层的输出尺寸
output_dim (int): 第二层线性层的输出尺寸,即分类的类别数
"""
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim) # 第一层全连接层
self.fc2 = nn.Linear(hidden_dim, output_dim) # 第二层全连接层
def forward(self, x_in, apply_softmax=False):
"""
模型的前向传播过程
参数:
x_in (torch.Tensor): 输入数据张量,形状应为 (批量大小, input_dim)
apply_softmax (bool): 是否应用softmax激活函数的标志
如果与交叉熵损失一起使用,应设为False
返回:
torch.Tensor: 输出张量,形状应为 (批量大小, output_dim)
"""
# 第一层全连接后接ReLU激活函数
intermediate_vector = F.relu(self.fc1(x_in))
# 第二层全连接得到预测向量
prediction_vector = self.fc2(intermediate_vector)
# 若要求应用softmax,则对预测向量进行softmax处理
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector4.5训练循环Training Loop
利用训练集训练构建好的MLP模型。下列显示了使用不同的key从batch_dict中获取数据,除了和训练简单感知器过程中外观上的差异,训练循环的功能保持不变。利用训练数据,计算模型输出、损失和梯度。然后使用梯度来更新模型。
# 步骤1. 清零梯度
optimizer.zero_grad()
running_loss = 0.
running_acc = 0.
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
for batch_index, batch_dict in enumerate(batch_generator):
# 步骤2. 计算模型输出
y_pred = classifier(batch_dict['x_surname'])
# 步骤3. 计算损失
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_batch = loss.to("cpu").item()
running_loss += (loss_batch - running_loss) / (batch_index + 1)
# 步骤4. 反向传播计算梯度
loss.backward()
# 步骤5. 使用优化器更新模型参数
optimizer.step() Test loss: 1.7435305690765381; Test Accuracy: 47.875
4.6分类新姓氏
以下代码是给定一个姓氏作为字符串,该函数将首先应用向量化过程,然后获得模型预测。注意,我们包含了apply_softmax标志,所以结果包含概率。模型预测,在多项式的情况下,是类概率的列表。我们使用PyTorch张量最大函数来得到由最高预测概率表示的最优类。
def predict_nationality(name, classifier, vectorizer):
"""
根据姓名预测国籍
Args:
name (str): 需要预测的姓名
classifier (SurnameClassifier): 已经训练好的分类器
vectorizer (SurnameVectorizer): 用于将姓名向量化的向量化器
Returns:
dict: 包含预测的国籍和概率的字典
"""
# 将姓名向量化
vectorized_name = vectorizer.vectorize(name)
# 将向量转换为torch张量,并调整形状为(1, -1)
vectorized_name = torch.tensor(vectorized_name).view(1, -1)
# 使用分类器进行预测,并应用softmax激活函数
result = classifier(vectorized_name, apply_softmax=True)
# 获取最大概率值及其索引
probability_values, indices = result.max(dim=1)
index = indices.item()
# 根据索引获取预测的国籍
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
# 获取预测的概率值
probability_value = probability_values.item()
# 返回包含预测国籍和概率的字典
return {'nationality': predicted_nationality,
'probability': probability_value}
# 接收用户输入的姓氏
new_surname = input("输入要分类的姓氏: ")
# 将分类器转移到CPU上执行
classifier = classifier.to("cpu")
# 使用预测函数进行预测
prediction = predict_nationality(new_surname, classifier, vectorizer)
# 打印预测结果
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))测试结果:
输入要分类的姓氏: McMahan
McMahan -> Irish (p=0.55)
4.7 DROPOUT
单地说,在训练过程中,dropout有一定概率使属于两个相邻层的单元之间的连接减弱。这有什么用呢?我们从斯蒂芬•梅里蒂(Stephen Merity)的一段直观(且幽默)的解释开始:“Dropout,简单地说,是指如果你能在喝醉的时候反复学习如何做一件事,那么你应该能够在清醒的时候做得更好。这一见解产生了许多最先进的结果和一个新兴的领域。”
神经网络——尤其是具有大量分层的深层网络——可以在单元之间创建有趣的相互适应。“Coadaptation”是神经科学中的一个术语,但在这里它只是指一种情况,即两个单元之间的联系变得过于紧密,而牺牲了其他单元之间的联系。这通常会导致模型与数据过拟合。通过概率地丢弃单元之间的连接,我们可以确保没有一个单元总是依赖于另一个单元,从而产生健壮的模型。dropout不会向模型中添加额外的参数,但是需要一个超参数——“drop probability”。drop probability,它是单位之间的连接drop的概率。通常将下降概率设置为0.5。这里给出了一个带dropout的MLP的重新实现。
import torch.nn as nn
import torch.nn.functional as F
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the MLP
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate = F.relu(self.fc1(x_in))
output = self.fc2(F.dropout(intermediate, p=0.5))
if apply_softmax:
output = F.softmax(output, dim=1)
return output4.8 卷积神经网络Convolutional Neural Networks
在本实验的第一部分中,我们深入研究了MLPs、由一系列线性层和非线性函数构建的神经网络。mlp不是利用顺序模式的最佳工具。例如,在姓氏数据集中,姓氏可以有(不同长度的)段,这些段可以显示出相当多关于其起源国家的信息(如“O’Neill”中的“O”、“Antonopoulos”中的“opoulos”、“Nagasawa”中的“sawa”或“Zhu”中的“Zh”)。这些段的长度可以是可变的,挑战是在不显式编码的情况下捕获它们。
在本节中,我们将介绍卷积神经网络(CNN),这是一种非常适合检测空间子结构(并因此创建有意义的空间子结构)的神经网络。CNNs通过使用少量的权重来扫描输入数据张量来实现这一点。通过这种扫描,它们产生表示子结构检测(或不检测)的输出张量。
在本节的其余部分中,我们首先描述CNN的工作方式,以及在设计CNN时应该考虑的问题。我们深入研究CNN超参数,目的是提供直观的行为和这些超参数对输出的影响。最后,我们通过几个简单的例子逐步说明CNNs的机制。在“示例:使用CNN对姓氏进行分类”中,我们将深入研究一个更广泛的示例。
卷积神经网络超参数
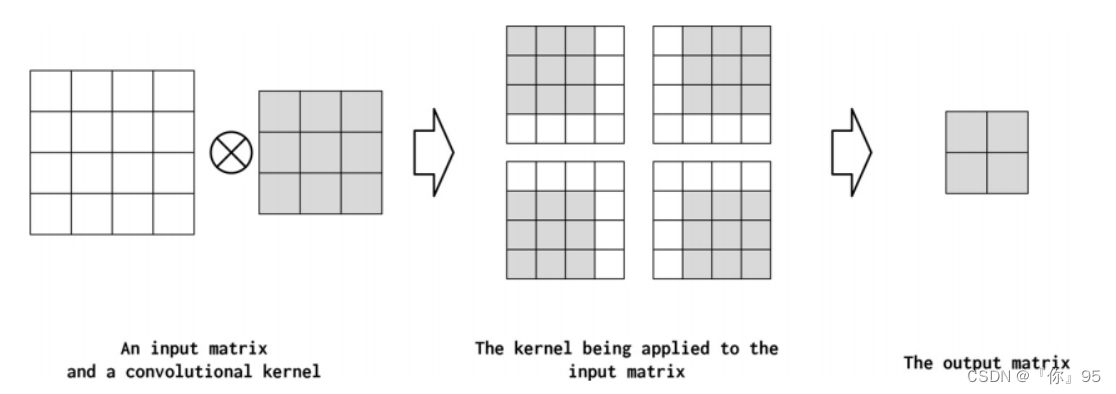
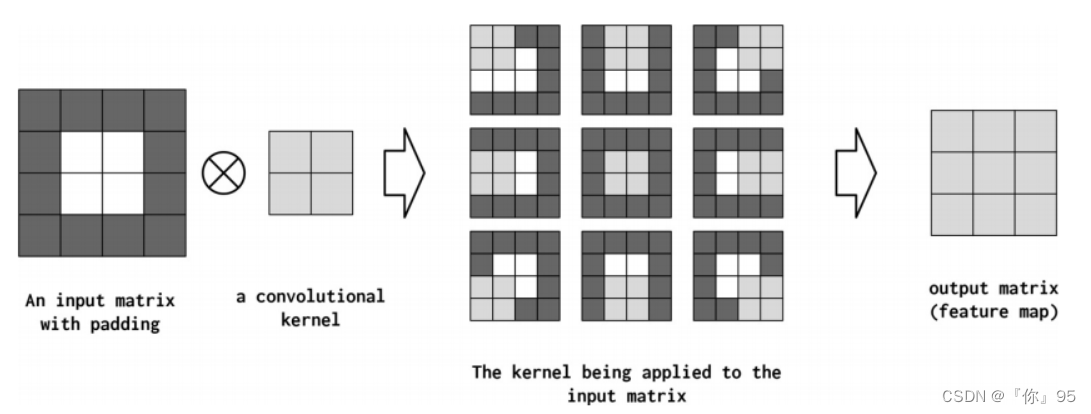
为了理解不同的设计决策对CNN意味着什么,我们在图4-6中展示了一个示例。在本例中,单个“核”应用于输入矩阵。卷积运算(线性算子)的精确数学表达式对于理解这一节并不重要,但是从这个图中可以直观地看出,核是一个小的方阵,它被系统地应用于输入矩阵的不同位置。
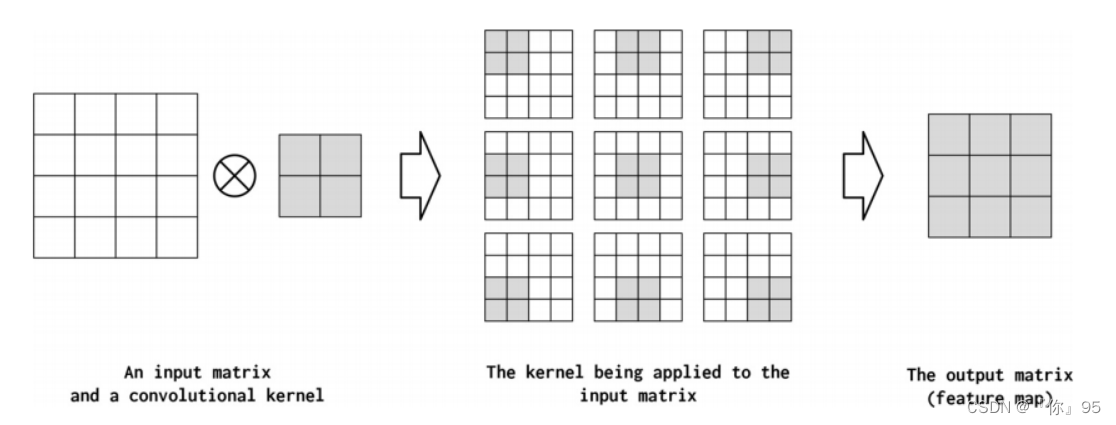
输入矩阵与单个产生输出矩阵的卷积核(也称为特征映射)在输入矩阵的每个位置应用内核。在每个应用程序中,内核乘以输入矩阵的值及其自身的值,然后将这些乘法相加kernel具有以下超参数配置:kernel_size=2,stride=1,padding=0,以及dilation=1。这些超参数解释如下:
虽然经典卷积是通过指定核的具体值来设计的,但是CNN是通过指定控制CNN行为的超参数来设计的,然后使用梯度下降来为给定数据集找到最佳参数。两个主要的超参数控制卷积的形状(称为kernel_size)和卷积将在输入数据张量(称为stride)中相乘的位置。还有一些额外的超参数控制输入数据张量被0填充了多少(称为padding),以及当应用到输入数据张量(称为dilation)时,乘法应该相隔多远。在下面的小节中,我们将更详细地介绍这些超参数。
通道CHANNELS
通道(channel)是指沿输入中的每个点的特征维度。例如,在图像中,对应于RGB组件的图像中的每个像素有三个通道。在使用卷积时,文本数据也可以采用类似的概念。从概念上讲,如果文本文档中的“像素”是单词,那么通道的数量就是词汇表的大小。如果我们更细粒度地考虑字符的卷积,通道的数量就是字符集的大小(在本例中刚好是词汇表)。在PyTorch卷积实现中,输入通道的数量是in_channels参数。卷积操作可以在输出(out_channels)中产生多个通道。您可以将其视为卷积运算符将输入特征维“映射”到输出特征维。
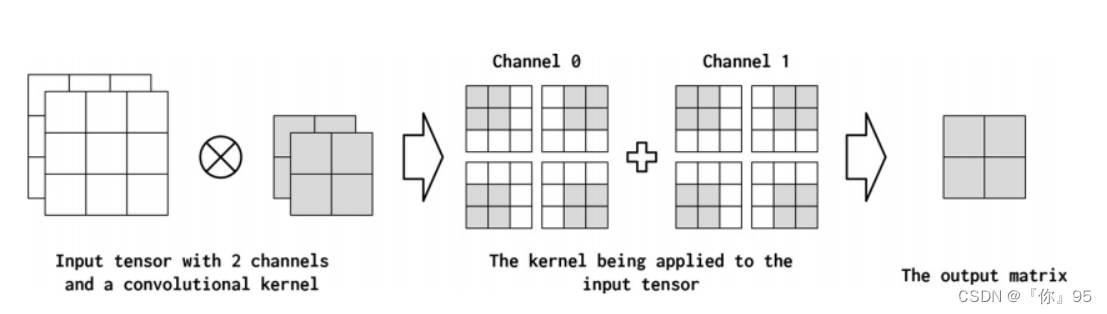
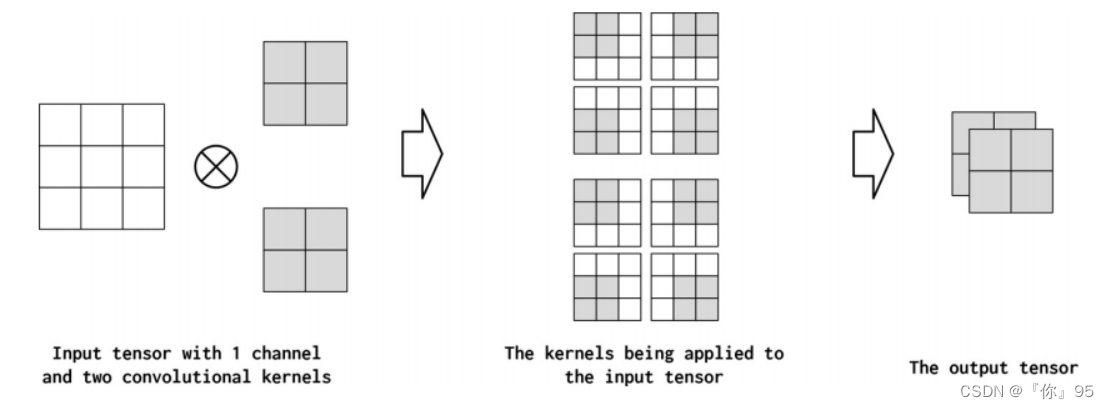
很难立即知道有多少输出通道适合当前的问题。为了简化这个困难,我们假设边界是1,1,024——我们可以有一个只有一个通道的卷积层,也可以有一个只有1,024个通道的卷积层。现在我们有了边界,接下来要考虑的是有多少个输入通道。一种常见的设计模式是,从一个卷积层到下一个卷积层,通道数量的缩减不超过2倍。这不是一个硬性的规则,但是它应该让您了解适当数量的out_channels是什么样子的。
卷积核大小KERNEL SIZE
核矩阵的宽度称为核大小(PyTorch中的kernel_size)。在图4-6中,核大小为2,而在图4-9中,我们显示了一个大小为3的内核。卷积将输入中的空间(或时间)本地信息组合在一起,每个卷积的本地信息量由内核大小控制。然而,通过增加核的大小,也会减少输出的大小(Dumoulin和Visin, 2016)。这就是为什么当核大小为3时,输出矩阵是图4-9中的2x2,而当核大小为2时,输出矩阵是图4-6中的3x3。
此外,可以将NLP应用程序中核大小的行为看作类似于通过查看单词组捕获语言模式的n-gram的行为。使用较小的核大小,可以捕获较小的频繁模式,而较大的核大小会导致较大的模式,这可能更有意义,但是发生的频率更低。较小的核大小会导致输出中的细粒度特性,而较大的核大小会导致粗粒度特性。
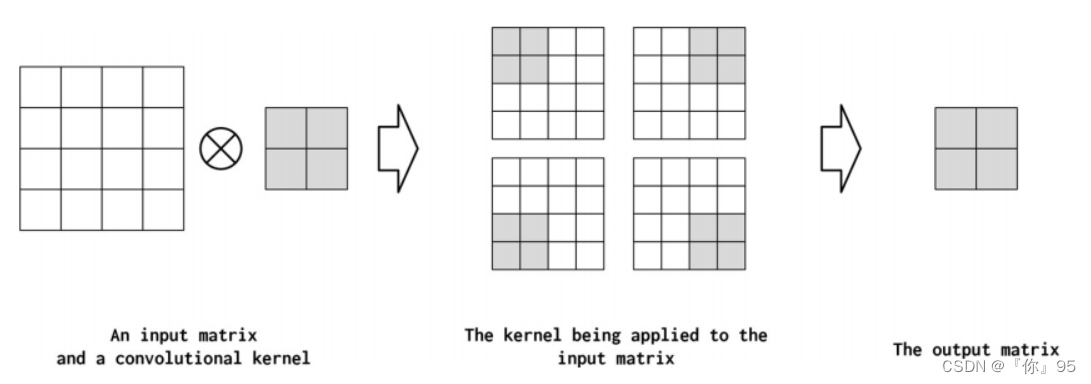
步长STRIDE
Stride控制卷积之间的步长。如果步长与核相同,则内核计算不会重叠。另一方面,如果跨度为1,则内核重叠最大。输出张量可以通过增加步幅的方式被有意的压缩来总结信息。
填充PADDING
即使stride和kernel_size允许控制每个计算出的特征值有多大范围,它们也有一个有害的、有时是无意的副作用,那就是缩小特征映射的总大小(卷积的输出)。为了抵消这一点,输入数据张量被人为地增加了长度(如果是一维、二维或三维)、高度(如果是二维或三维)和深度(如果是三维),方法是在每个维度上附加和前置0。这意味着CNN将执行更多的卷积,但是输出形状可以控制,而不会影响所需的核大小、步幅或扩展。
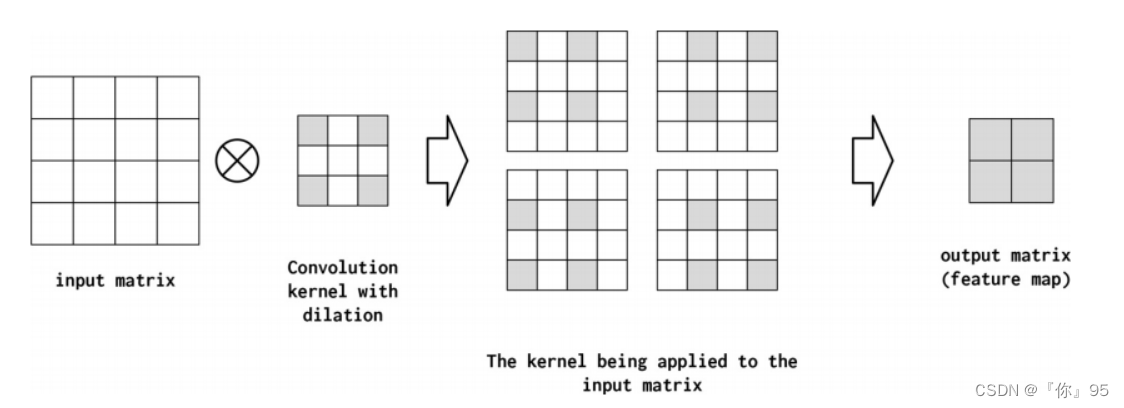
扩张率DILATION
膨胀控制卷积核如何应用于输入矩阵。在图4-12中,我们显示,将膨胀从1(默认值)增加到2意味着当应用于输入矩阵时,核的元素彼此之间是两个空格。另一种考虑这个问题的方法是在核中跨跃——在核中的元素或核的应用之间存在一个step size,即存在“holes”。这对于在不增加参数数量的情况下总结输入空间的更大区域是有用的。当卷积层被叠加时,扩张卷积被证明是非常有用的。连续扩张的卷积指数级地增大了“接受域”的大小;即网络在做出预测之前所看到的输入空间的大小。
4.9 在PyTorch中实现CNN
在本节中,我们将通过端到端示例来利用上一节中介绍的概念。一般来说,神经网络设计的目标是找到一个能够完成任务的超参数组态。我们再次考虑在“示例:带有多层感知器的姓氏分类”中引入的现在很熟悉的姓氏分类任务,但是我们将使用CNNs而不是MLP。我们仍然需要应用最后一个线性层,它将学会从一系列卷积层创建的特征向量创建预测向量。这意味着目标是确定卷积层的配置,从而得到所需的特征向量。所有CNN应用程序都是这样的:首先有一组卷积层,它们提取一个feature map,然后将其作为上游处理的输入。在分类中,上游处理几乎总是应用线性(或fc)层。
本课程中的实现遍历设计决策,以构建一个特征向量。我们首先构造一个人工数据张量,以反映实际数据的形状。数据张量的大小是三维的——这是向量化文本数据的最小批大小。如果你对一个字符序列中的每个字符使用onehot向量,那么onehot向量序列就是一个矩阵,而onehot矩阵的小批量就是一个三维张量。使用卷积的术语,每个onehot(通常是词汇表的大小)的大小是”input channels”的数量,字符序列的长度是“width”。
构造特征向量的第一步是将PyTorch的Conv1d类的一个实例应用到三维数据张量。通过检查输出的大小,你可以知道张量减少了多少。
人工数据和使用 Conv1d 类
from torch.nn import Conv1d
batch_size = 2
one_hot_size = 10
sequence_width = 7
data = torch.randn(batch_size, one_hot_size, sequence_width)
conv1 = Conv1d(in_channels=one_hot_size, out_channels=16,
kernel_size=3)
intermediate1 = conv1(data)
print(data.size())
print(intermediate1.size())torch.Size([2, 10, 7]) torch.Size([2, 16, 5])
进一步减小输出张量的主要方法有三种。第一种方法是创建额外的卷积并按顺序应用它们。最终,对应的sequence_width (dim=2)维度的大小将为1。我们在例4-15中展示了应用两个额外卷积的结果。一般来说,对输出张量的约简应用卷积的过程是迭代的,需要一些猜测工作。我们的示例是这样构造的:经过三次卷积之后,最终的输出在最终维度上的大小为1。
对数据进行卷积的迭代应用
conv2 = nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3)
conv3 = nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3)
intermediate2 = conv2(intermediate1)
intermediate3 = conv3(intermediate2)
print(intermediate2.size())
print(intermediate3.size())
y_output = intermediate3.squeeze()
print(y_output.size())torch.Size([2, 32, 3]) torch.Size([2, 64, 1])
torch.Size([2, 64])
在每次卷积中,通道维数的大小都会增加,因为通道维数是每个数据点的特征向量。张量实际上是一个特征向量的最后一步是去掉讨厌的尺寸=1维。您可以使用squeeze()方法来实现这一点。该方法将删除size=1的所有维度并返回结果。然后,得到的特征向量可以与其他神经网络组件(如线性层)一起使用来计算预测向量。
另外还有两种方法可以将张量简化为每个数据点的一个特征向量:将剩余的值压平为特征向量,并在额外维度上求平均值。这两种方法如示例4-16所示。使用第一种方法,只需使用PyTorch的view()方法将所有向量平展成单个向量。第二种方法使用一些数学运算来总结向量中的信息。最常见的操作是算术平均值,但沿feature map维数求和和使用最大值也是常见的。每种方法都有其优点和缺点。扁平化保留了所有的信息,但会导致比预期(或计算上可行)更大的特征向量。平均变得与额外维度的大小无关,但可能会丢失信息。
用于将数据降维为特征向量的另外两种方法
# Method 2 of reducing to feature vectors
print(intermediate1.view(batch_size, -1).size())
# Method 3 of reducing to feature vectors
print(torch.mean(intermediate1, dim=2).size())
# print(torch.max(intermediate1, dim=2).size())
# print(torch.sum(intermediate1, dim=2).size())torch.Size([2, 80]) torch.Size([2, 16])
这种设计一系列卷积的方法是基于经验的:从数据的预期大小开始,处理一系列卷积,最终得到适合您的特征向量。虽然这种方法在实践中效果很好,但在给定卷积的超参数和输入张量的情况下,还有另一种计算张量输出大小的方法,即使用从卷积运算本身推导出的数学公式。
4.10 The SurnameDataset
虽然姓氏数据集之前在“示例:带有多层感知器的姓氏分类”中进行了描述,但建议参考“姓氏数据集”来了解它的描述。尽管我们使用了来自“示例:带有多层感知器的姓氏分类”中的相同数据集,但在实现上有一个不同之处:数据集由onehot向量矩阵组成,而不是一个收缩的onehot向量。为此,我们实现了一个数据集类,它跟踪最长的姓氏,并将其作为矩阵中包含的行数提供给矢量化器。列的数量是onehot向量的大小(词汇表的大小)。示例4-17显示了对SurnameDataset.__getitem__的更改;我们显示对SurnameVectorizer的更改。在下一小节向量化。
我们使用数据集中最长的姓氏来控制onehot矩阵的大小有两个原因。首先,将每一小批姓氏矩阵组合成一个三维张量,要求它们的大小相同。其次,使用数据集中最长的姓氏意味着可以以相同的方式处理每个小批处理。
class SurnameDataset(Dataset):
# ... existing implementation from Section 4.2
def __getitem__(self, index):
row = self._target_df.iloc[index]
surname_matrix = \
self._vectorizer.vectorize(row.surname, self._max_seq_length)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_matrix,
'y_nationality': nationality_index}4.11 Vocabulary, Vectorizer, and DataLoader
在本例中,尽管词汇表和DataLoader的实现方式与“示例:带有多层感知器的姓氏分类”中的示例相同,但Vectorizer的vectorize()方法已经更改,以适应CNN模型的需要。具体来说,正如我们在示例4-18中的代码中所示,该函数将字符串中的每个字符映射到一个整数,然后使用该整数构造一个由onehot向量组成的矩阵。重要的是,矩阵中的每一列都是不同的onehot向量。主要原因是,我们将使用的Conv1d层要求数据张量在第0维上具有批处理,在第1维上具有通道,在第2维上具有特性。
除了更改为使用onehot矩阵之外,我们还修改了矢量化器,以便计算姓氏的最大长度并将其保存为max_surname_length
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def vectorize(self, surname):
"""
Args:
surname (str): the surname
Returns:
one_hot_matrix (np.ndarray): a matrix of one-hot vectors
"""
one_hot_matrix_size = (len(self.character_vocab), self.max_surname_length)
one_hot_matrix = np.zeros(one_hot_matrix_size, dtype=np.float32)
for position_index, character in enumerate(surname):
character_index = self.character_vocab.lookup_token(character)
one_hot_matrix[character_index][position_index] = 1
return one_hot_matrix
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
character_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
max_surname_length = 0
for index, row in surname_df.iterrows():
max_surname_length = max(max_surname_length, len(row.surname))
for letter in row.surname:
character_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(character_vocab, nationality_vocab, max_surname_length)4.12 使用卷积神经网络重新实现姓氏分类器
我们在本例中使用的模型是使用我们在“卷积神经网络”中介绍的方法构建的。实际上,我们在该部分中创建的用于测试卷积层的“人工”数据与姓氏数据集中使用本例中的矢量化器的数据张量的大小完全匹配。正如在上述示例中所看到的,它与我们在“卷积神经网络”中引入的Conv1d序列既有相似之处,也有需要解释的新添加内容。具体来说,该模型类似于“卷积神经网络”,它使用一系列一维卷积来增量地计算更多的特征,从而得到一个单特征向量。
然而,本例中的新内容是使用sequence和ELU PyTorch模块。序列模块是封装线性操作序列的方便包装器。在这种情况下,我们使用它来封装Conv1d序列的应用程序。ELU是类似于实验3中介绍的ReLU的非线性函数,但是它不是将值裁剪到0以下,而是对它们求幂。ELU已经被证明是卷积层之间使用的一种很有前途的非线性(Clevert et al., 2015)。
在本例中,我们将每个卷积的通道数与num_channels超参数绑定。我们可以选择不同数量的通道分别进行卷积运算。这样做需要优化更多的超参数。我们发现256足够大,可以使模型达到合理的性能
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
"""
Args:
initial_num_channels (int): size of the incoming feature vector
num_classes (int): size of the output prediction vector
num_channels (int): constant channel size to use throughout network
"""
super(SurnameClassifier, self).__init__()
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
"""The forward pass of the classifier
Args:
x_surname (torch.Tensor): an input data tensor.
x_surname.shape should be (batch, initial_num_channels,
max_surname_length)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, num_classes)
"""
features = self.convnet(x_surname).squeeze(dim=2)
prediction_vector = self.fc(features)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector4.13 训练程序
训练程序包括以下似曾相识的的操作序列:实例化数据集,实例化模型,实例化损失函数,实例化优化器,遍历数据集的训练分区和更新模型参数,遍历数据集的验证分区和测量性能,然后重复数据集迭代一定次数。此时,这是本书到目前为止的第三个训练例程实现,应该将这个操作序列内部化。对于这个例子,我们将不再详细描述具体的训练例程,因为它与“示例:带有多层感知器的姓氏分类”中的例程完全相同。
args = Namespace(
# Data and Path information
surname_csv="surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/cnn",
# Model hyper parameters
hidden_dim=100,
num_channels=256,
# Training hyper parameters
seed=1337,
learning_rate=0.001,
batch_size=128,
num_epochs=100,
early_stopping_criteria=5,
dropout_p=0.1,
# Runtime omitted for space ...
)Test loss: 1.769006888071696; Test Accuracy: 53.776041666666664
对新姓氏进行分类或检索顶部预测
在本例中,predict_nationality()函数的一部分发生了更改,我们没有使用视图方法重塑新创建的数据张量以添加批处理维度,而是使用PyTorch的unsqueeze()函数在批处理应该在的位置添加大小为1的维度。相同的更改反映在predict_topk_nationality()函数中。
def predict_nationality(surname, classifier, vectorizer):
"""Predict the nationality from a new surname
Args:
surname (str): the surname to classifier
classifier (SurnameClassifer): an instance of the classifier
vectorizer (SurnameVectorizer): the corresponding vectorizer
Returns:
a dictionary with the most likely nationality and its probability
"""
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}Enter a surname to classify: McMahan McMahan -> Irish (p=0.97)
批处理标准化
批处理标准化是设计网络时经常使用的一种工具。BatchNorm对CNN的输出进行转换,方法是将激活量缩放为零均值和单位方差。它用于Z-transform的平均值和方差值每批更新一次,这样任何单个批中的波动都不会太大地移动或影响它。BatchNorm允许模型对参数的初始化不那么敏感,并且简化了学习速率的调整(Ioffe and Szegedy, 2015)。在PyTorch中,批处理规范是在nn模块中定义的。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MYModel(nn.Module):
def __init__(self):
super(MYModel, self).__init__()
self.conv1 = nn.Conv1d(in_channels=1, out_channels=10, kernel_size=5, stride=1)
self.conv1_bn = nn.BatchNorm1d(num_features=10) # BatchNorm1d after Conv1d
# Other layers initialization if needed
def forward(self, x):
x = F.relu(self.conv1(x)) # Applying Conv1d followed by ReLU
x = self.conv1_bn(x) # Applying BatchNorm1d
# Further operations on x if needed
return x
# Example usage:
# Create an instance of the model
model = MYModel()
# Assuming x is your input tensor of shape (batch_size, channels, length)
x = torch.randn(32, 1, 100) # Example input
output = model(x)
print(output.shape) # Example output shapetorch.Size([32, 10, 96])















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









