







第三章、概率密度函数的估计
贝叶斯决策
:
利用类条件概率 和先验概率 来设计分类器; 最核心的思想是利用后验概率;
贝叶斯决策的基础 是 概率密度函数的估计,即 先验概率 和 类条件概率 的估计。
第二章,在先验概率和类条件概率确定的情况下,我们通过贝叶斯公式来进行决策。
而第三章我们要解决的问题是估计先验概率和类条件概率
具体做法是:
利用训练样本估计先验概率和条件密度函数,并把这些估计的结果当作实际的先验概率和条件密度函数,然后再设计分类器。
目录
一、概率密度估计的方法
1.参数估计
已知概率密度函数的形式,但其中部分或者全部参数未知,概率密度函数的估计问题就是用样本来估计这些参数,主要是方法有两大类:最大似然估计 和 贝叶斯估计 ,两者在很多实际情况下结果接近,但从概念上它们的处理方法是不同的。
2.非参数估计
就是概率密度函数的形式也未知,或者概率密度函数不符合目前研究的任何分布模型,因此不能仅仅估计几个参数,而是用样本把概率密度函数数值化的估计出来。
3.参数估计中的基本概念
统计量:每一种训练样本都包含着总体的某种信息,一个训练样本集包含总体的全部信息,针对不同的参数估计要求构造某种函数以便从样本集中抽取有关信息,这种函数称为统计量。
参数空间:所有未知参数 的可能取值的集合称为参数空
间,记为 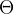 。
。
点估计、估计量和估计值:估计总体分布的一个或几个具体参数叫点估计。针对某未知参数 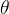 构造一个统计量作为 的估计,称
构造一个统计量作为 的估计,称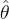 为 的估计量; 的值叫做 的估计值。
为 的估计量; 的值叫做 的估计值。
区间估计:除点估计外,还有另一类估计,他要求用区间  作为
可能取值范围的一种估计。 这个区间称为
置信区间,这类估计问题称为
区间估计。
作为
可能取值范围的一种估计。 这个区间称为
置信区间,这类估计问题称为
区间估计。
二、最大似然估计与贝叶斯估计根本的区别 (
本章要求估计总体分布的具体参数,属于点估计问题。
我将介绍两种主要的点估计方法——最大似然估计 和 贝叶斯估计
二、最大似然估计与贝叶斯估计根本的区别 ( )
)
(1)最大似然估计 是 把待估计的参数当作未知但固定的量,要做的 是 根据观测数据估计这个量的取值;
(2)贝叶斯估计 是 把待估计的参数本身也看作是随机变量,要做的 是 根据观测数据对参数的分布进行估计, 除了观测数据外,还可以考虑参数的先验分布。
三、最大似然估计的基本原理
已知某一类样本集包含
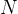 个样本
个样本
 ,带估计的未知参数为
,由于假设样本是独立抽取的,那么
,带估计的未知参数为
,由于假设样本是独立抽取的,那么
看做是参数
的函数,称联合概率密度
 为样本集
为样本集
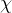 的似然函数,通常我们把这个函数用
的似然函数,通常我们把这个函数用
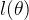 来表示。
来表示。
为了便于分析,由于对数函数的单调性,还可以定义对数似然函数:
参数向量
的最大似然估计,就是使
 达到最大值的那个参数估计向量
达到最大值的那个参数估计向量
“最有可能出现的”样本似然函数最大的样本
四、最大似然估计的求解(求均值、方差)
1. 求解方法:
根据已知的样本集 ,使似然函数取极大值  时得到的参数,
时得到的参数,
就是我们要找的估计量



2.计算例题
(1)


(2)

(3)

(4)


五、贝叶斯估计的基本原理(思路)、雅可比函数
1.基本原理(思路)
贝叶斯估计就是根据一个样本集,找出估计量
,估计
所属总体分布的某个真实参数
,使带来的贝叶斯风险最小。
具体来说,
就是利用先验概率 、类条件概率
和贝叶斯公式先求
的后验概率密度函数
,然后, 用
,即求 在后验概率密度
下的期望值或平均值作为
的估计。

2.雅可比函数
六、贝叶斯学习的基本原理、基本思路
1.基本原理
把先验概率记作 ,表示在没有样本情况下的概率密度估计。随着样本数的增加,得到一系列对概率密度函数参数的估计称作
,表示在没有样本情况下的概率密度估计。随着样本数的增加,得到一系列对概率密度函数参数的估计称作
递推的贝叶斯估计
。如果随着样本数的增加,后验概率序列逐渐尖锐,逐步趋向于以 的真实值为中心的一个尖峰,当样本无穷多时收敛于在参数真实值上的脉冲函数,则这一过程称作
贝叶斯学习
。
















 5965
5965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











