







目录
3.Construct Loss and Optimizer(构造损失函数和优化器)
一、Pytorch Fashion
pytorch框架下的深度学习流程主要为以下四步:
1.准备数据集

2.设计模型

3.构造函数和优化器

4.训练周期

二、Linear Regression
1.prepare dataset(准备数据集)
在这个数据集要使用mini-batch的风格,因为只有3个数据,所以都放进去。模型是y=w*x+b。

与前面不同的是,我们构建数据集时,x_data与y_data采用了torch.Tensor ;
注意: X和Y都是矩阵
代码实现:
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])2.Design Model(设计模型)
之前我们都是人工进行求导,但现在我们的重点在于利用张量之间的计算去构造计算图。
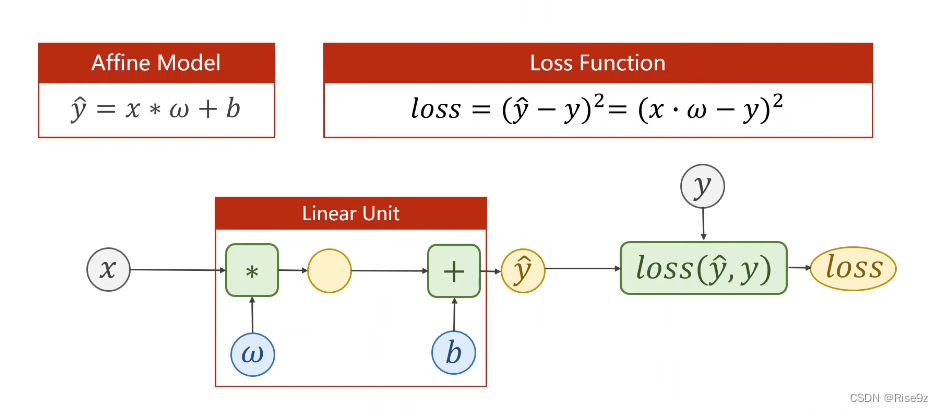
Linear unit(线性单元):把 z = w * x + b 称为线性单元·
在进行构造时,我们需要知道 x 的维度与 y_hat 的维度 来确定 权重 w 的数量
然后将y_hat放入我们的损失函数中 计算损失(Loss)
最后,我们就可以对 Loss 调用 backward ,对整个函数进行反向传播
注意:权重w可以是向量,但是损失loss最后必须是标量,所以我们要对所有loss进行求和。
代码实现:
( 我们的模型类继承于nn.Module )

注意:(1)y_pred = self.linear(x),在对象后面加括号实现一个可调用对象。
(2)在Module类的__call__()就是调用forward()
(3)python里的Functions也是一个类。
import torch.nn
# 将模型定义成一个类
class LinearModel(torch.nn.Module): # 继承nn.Module
def __init__(self): # 构造函数
super(LinearModel, self).__init__() # 调用父类的构造
self.linear = torch.nn.Linear(1, 1) # 构造对象
# torch,nn是pytorch里的一个类,包含两个成员张量:weight和bias
# Linear类也是继承自Module,可以自动进行反向传播
def forward(self, x): # 前馈时的计算
y_pred = self.linear(x) # 对象后面加括号-实现了一个__call__(),可调用的对象
return y_pred
# 创建一个LinearModel实例
model - LinearModel() # 这个model是可调用的3.Construct Loss and Optimizer(构造损失函数和优化器)
损失函数:

torch.nn.MSELoss同样继承于nn.Module类
torch.nn.MSELoss的参数有size_average(是否求均值), reduce(是否求和,降维)
优化器:

代码实现:
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) 4.Training Cycle(训练周期)

代码实现:
for epoch in range(100):
y_pred = model(x_data) # forward:预测
loss = criterion(y_pred, y_data) # forward:loss
print(epoch, loss) # 打印loss时会自动调用__str__()函数,不会产生计算图,这是安全的
optimizer.zero_grad() # 注意.backward()时梯度会被累计,权重清零
loss.backward() # 反向传播:autograd
optimizer.step()训练过程完成了forward,backward和update。
5.Test Model(测试模型)

到100次迭代时,w和b没有到达最理想值,说明训练还没收敛。进行1000次迭代,效果更好。
代码实现:
#输出w和b
print('w = ', model.linear.weight.item()) #打印时选item,不然w是一个矩阵
print('b = ', model.linear.bias.item())
# 测试模型test model
x_test = torch.Tensor([[4.0]]) #输入1*1矩阵
y_test = model(x_test) #输出1*1矩阵
print('y_pred = ', y_test.data)
总结
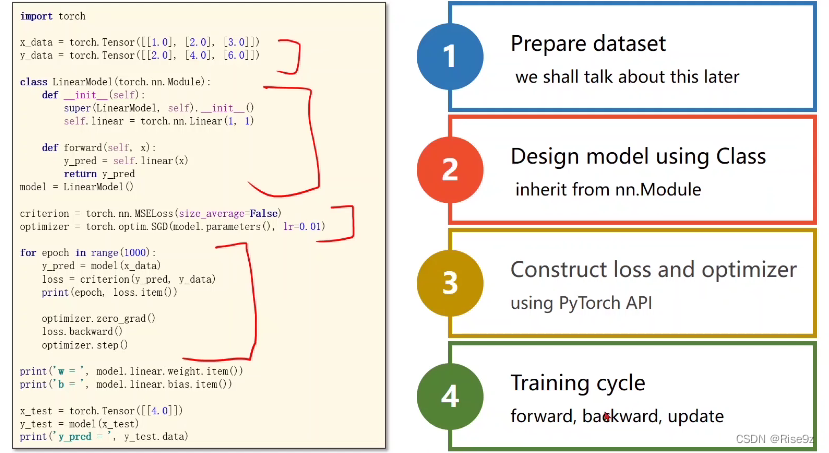
完整的代码:
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
# 将模型定义成一个类
class LinearModel(torch.nn.Module): # 继承nn.Module
def __init__(self): # 构造函数
super(LinearModel, self).__init__() # 调用父类的构造
self.linear = torch.nn.Linear(1, 1) # 构造对象
# torch,nn是pytorch里的一个类,包含两个成员张量:weight和bias
# Linear类也是继承自Module,可以自动进行反向传播
def forward(self, x): # 前馈时的计算
y_pred = self.linear(x) # 对象后面加括号-实现了一个__call__(),可调用的对象
return y_pred
# 创建一个LinearModel实例
model = LinearModel() # 这个model是可调用的
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
y_pred = model(x_data) # forward:预测
loss = criterion(y_pred, y_data) # forward:loss
print(epoch, loss) # 打印loss时会自动调用__str__()函数,不会产生计算图,这是安全的
optimizer.zero_grad() # 注意.backward()时梯度会被累计,权重清零
loss.backward() # 反向传播:autograd
optimizer.step()
# 输出w和b
print('w = ', model.linear.weight.item()) # 打印时选item,不然w是一个矩阵
print('b = ', model.linear.bias.item())
# 测试模型test model
x_test = torch.Tensor([[4.0]]) # 输入1*1矩阵
y_test = model(x_test) # 输出1*1矩阵
print('y_pred = ', y_test.data)
训练100次得到的结果:
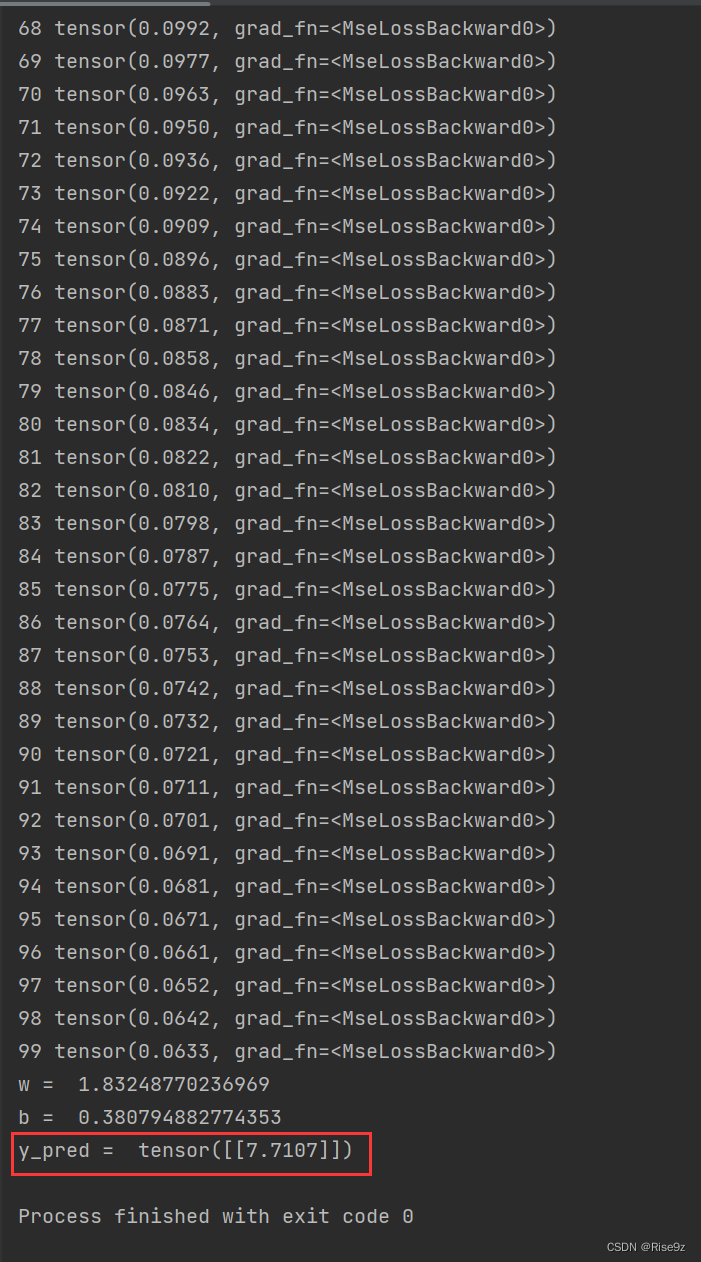
训练1000次得到的结果:

可见,训练1000次的效果更接近于我们所要获得的数据。
















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











