









北邮国院大三电商在读,全文为PPT机翻+自己理解,仅做整体复习浏览知识点熟悉定义用,不做考前突击复习重点用。有任何问题可评论指出,有需要本文pdf/docx/md/Effiesheet格式的同学请私信联系/微信联系。祝您学习愉快。
Performance of rdt3.0
- rdt3.0 is correct, but performance is very bad
Rdt3.0是正确的,但是性能非常差
[以下以1 Gbps link,15ms delay, 8000 bit packet为例]
RTT
RTT = round-trip-time = end-to-end delay * 2
[RTT = 15ms * 2 = 30ms]
[D_trans = L/R = 8000bits / 10^9 bits/sec = 0.008 ms]
utilization 利用率
- fraction of time sender busy sending
发送方忙着发送的时间百分比
- U_sender = (L/R) / (RTT + L/R)
[U_sender = 0.008 / 30+0.008 = 0.00027]
- if RTT=30 msec, 1KB pkt every 30 msec: 33kB/sec throughput over 1 Gbps link
这里的throughput(吞吐量)的计算方法:1KB pkt需要0.03s,即一秒钟可以传输33个1KB的pkt,throughput就是33kB/sec
rdt3.0: stop-and-wait operation

- 明确RTT的范围,从发送数据完毕开始,到发送方接收到ACK为止
Pipelined protocols 流水线协议
- pipelining: sender allows multiple, “in-flight”, yet-to-be-acknowledged packets (packets with no ACK as yet)
流水线:发送方允许多个“正在传输中”但尚未被确认的数据包(目前还没有ACK的数据包)
- range of sequence numbers must be increased
序列号的范围必须增加
- buffering at sender and/or receiver
在发送方和/或接收方进行缓冲
- two generic forms of pipelined protocols: go-Back-N, selective repeat
流水线协议的两种通用形式:go-Back-N,选择性重复
pipelined protocols’ utilization

- RTT的定义相较于rdt3.0的 stop-and-wait 仍然不变,是第一个文件的发送完毕开始,到收到第一个ACK结束
- 所以,这里的U_sender 的分母就是RTT+L/R,与文件数量无关
- 分子与文件数量有关,有几个就是几 L/R
Go-Back-N

- “window” of up to N, consecutive packets with no ACK
“window”最多N个,连续的包没有ACK
- ACK(n): ACKs all packets up to, including sequence # n -“cumulative ACK”
对包括序列# n - "累积ACK "在内的所有数据包进行ACK
【定义略显晦涩,简单解释一下就是假如我收到了ack1,那么就说明receiver接收到了1及1以前的所有pkt】
- may receive duplicate ACKs (see receiver)
可能会收到重复的ACK(具体看下面的图就行)
- 每个pkt都有timer
- timeout(n): retransmit packet n and all higher seq # pkts in window
重传数据包n和所有在window中更高的seq # PKTS.
图解GBN
【以上定义都可以在图中得到解释】

- 先看最左面,N=4,即窗口的大小就是4,一开始是0123
- sender 开始send pkt0,receiver开始rcv pkt0,deliver,然后send ack0证明成功收到了pkt0,sender这边rcv了ack0,接收到了receiver收到pkt0这个信息,然后send了pkt4,并且窗口移动一位,到1234(因为pkt0已经完事了),这个是一个成功的过程
- pkt2到中途loss了,receiver在没接收到pkt2的情况下,接收到了pkt3,receiver意识到了不对,中间丢东西了,然后立马discard(扔掉)了收到的pkt3,并且resend了ack1,不让sender的窗口继续移动(如果send了ack2/3,窗口会移动),pkt4和pkt5同理
- 当pkt2 timeout,sender意识到pkt2丢了,然后立马从pkt2开始重新send(此时窗口为2345,也就是从窗口的第一个开始send),send了pkt2345,然后receiver那边也照常接收,如果有问题就重复上面的过程
- deliver是交付到application layer
selective repeat
- receiver individually acknowledges all correctly received packets
接收方单独确认所有正确接收的数据包
- buffers packets, as needed, for eventual in-order delivery to upper layer
根据需要缓冲数据包,以便最终按顺序交付给上层
- sender only resends packets for which ACK not received (sender timer for each unACKed packet)
发送方只重发未收到ACK的数据包(sender有timer)
- sender window
- N consecutive seq #’s
- N个连续的seq#
- limits seq #s of sent, unACKed packets
- 限制发送的、未打包的数据包的seq次数

- 如果pkt丢了的话,后面的要么也是丢了,要么就会被buffer(缓存)【具体看后面的图】
sender和receiver
sender
- data from above : if next available seq # in window, send pkt
如果下一个可用seq#在窗口,发送PKT
- timeout(n) : resend pkt n, restart timer
重发PKT n,重启定时器
- ACK(n) in [sendbase,sendbase+N-1]:
- mark pkt n as received
- 标记PKT n为收到
- if n smallest unACKed pkt, advance window base to next unACKed seq #
- 如果n是最小的unACKed pkt,提前窗口到下一个unACKed seq#
- 【↑此处存疑,等以后补充】
receiver
- pkt n in [rcvbase, rcvbase+N-1]
- send ACK(n)
- out-of-order: buffer
- in-order: deliver (also deliver buffered, in-order pkts), advance window to next not-yet-received pkt
- pkt n in [rcvbase-N,rcvbase-1]
- ACK(n)
- otherwise : ignore
图解

- sender window 的移动方式和之是一样的
- 当pkt2 loss时,pkt345都照常发送,但是在receiver处被buffer,同时和正常情况send了ack345,当sender没接收到ack2而直接接收到了ack3时,他会将ack3 record,ack45也是同样情况
- pkt2 timeout,sender重新send了pkt2,当receiver收到pkt2时,他发现这个是之前没收到的pkt2,会按顺序的把pkt2和之前buffer的ptk345一起按顺序deliver,并且send ack2
- sender收到ack2,发现了receiver正常deliver了pkt2345,于是将window挪到了6789的位置(和正常完成pkt2345的结果是一样的)
dilemma
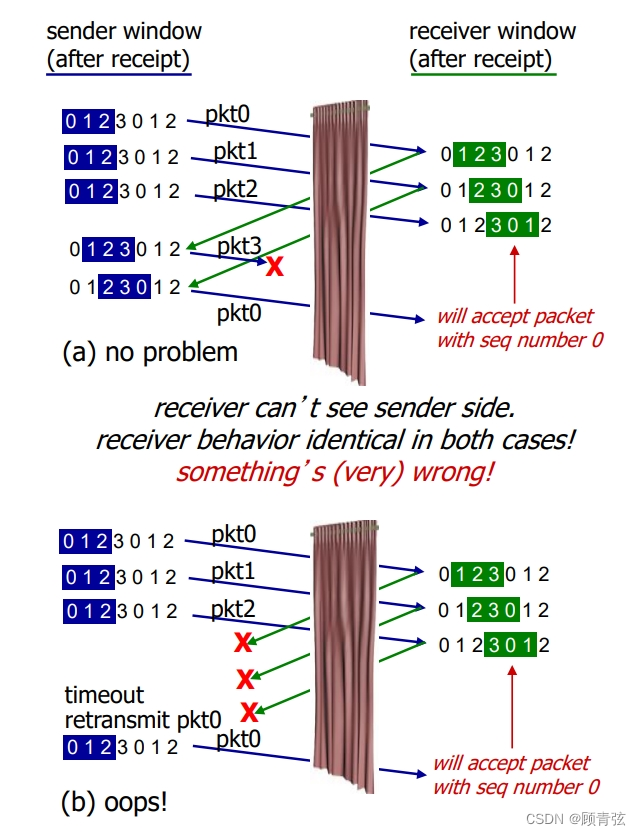
- 很简单,就是告诉你ab两种情况receiver看到的都是一样的,a还好,b会出现数据传输错误,所以在这种情况下window size 要和重复数据的一组的大小相同(图中为4,即同时包括了0123)
TCP seq. numbers,ACKs
TCP header
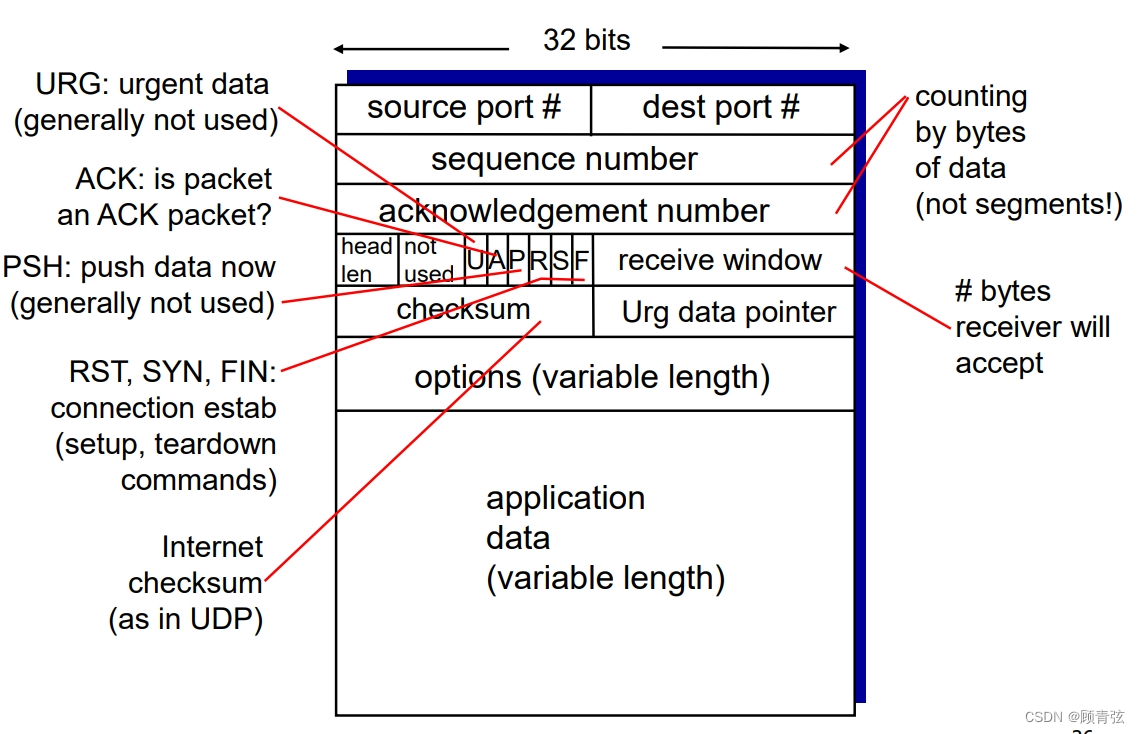
- 主要关注sequence number和acknowledge number
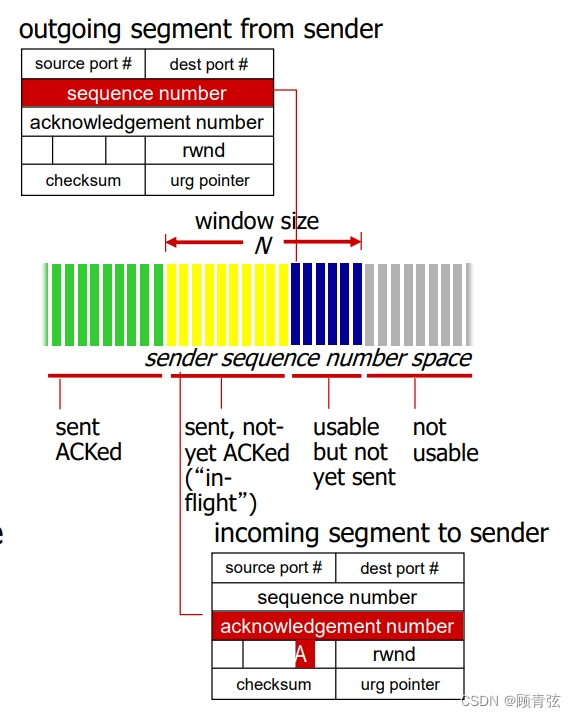
- 说实话,这个图我也没怎么看懂,我觉得不如看下面的定义和图来的实在
sequence number
- byte stream “number” of first byte in segment’s data
段数据中第一个字节的字节流“数”
【会有一个初始值,再加上1,比如一开始的初始值是1000,那么seq num就是1001,也可以理解为,sender告诉receiver“我发送的数据是从序号1001”开始的】
acknowledgement number
- seq # of next byte expected from other side (cumulative ACK)
seq #从另一边期望的下一个字节(累积ACK)
【这边接收到了另一边的数据,并且反馈说我收到了这些数据,所以ACK就应该是上次收到的数据的seq+1,即期望对方下一次的sequence number是多少】
图解

- 我们按照上面的定义来分析
- 第一次是从A到B,seq=42 说明A告诉B:“我这边发送的数据是从42号开始的”,ACK=79,说明A告诉B:“我想要的数据是从79号开始的”
- 第二次是从B到A,ACK=43.说明B告诉A:“我这边收到了42号哈,哥们你下次从43开始给我传”,seq=79,说明A告诉B:“我这边发送的数据是你之前要的从79号开始的哈”
- 第三次是由A到B,seq=43,说明A告诉B:“我想要的数据是从43号开始的”,ACK=80,说明A告诉B:“我收到了79号,我想要80号”
- 不想理解的省流记法:上一个的seq+1=下一个的ACK,上一个的ACK=下一个的seq
TCP RTT,timeout
How to set TCP timeout value?如何设置TCP的超时时间呢?
- 首先就是至少要比RTT长(废话,要不然文件没传完呢,直接timeout了),但是每次的RTT都不同
- 但是这个时间过短或者过长都有缺点
timeout value too short
- early timeout 过早的超时
- unnecessary retransmission 没必要的重传(浪费时间和资源)
timeout value too long
- slow reaction to segment loss 对段丢失反应缓慢
如何估算RTT
- 问题的关键就来到了如何去估算RTT上
- 第一个重要概念:Sample RTT
- SampleRTT: measured time from segment transmission until ACK receipt (ignore retransmissions)
- 从段传输到ACK接收的测量时间(忽略重发)
- 也就是我们之前在rdt3.0 stop-and-wait 和pipelining protocols 那里说的RTT的定义
- SampleRTT will vary, want estimated RTT “smoother”
SampleRTT将有所变化,希望估计的RTT“更平滑”
- average several recent measurements, not just current SampleRTT
对最近的几次测量结果进行平均,而不仅仅是目前的SampleRTT
计算EstimatedRTT
以下公式中a代表希腊字母阿尔法
- EstimatedRTT = (1- a)*EstimatedRTT + a*SampleRTT
- 前一个EstimatedRTT是new,后一个是old,即用前一个去计算后一个
- exponential weighted moving average
- 自回归移动
- influence of past sample decreases exponentially fast
- 过去样本的影响呈指数快速下降
- typical value: a = 0.125
- 典型值: a = 0.125
- EstimatedRTT_new = 0.875 · EstimatedRTT + 0.125 · SampleRTT
Jacobsen/Karel’s Algorithm
以下公式中b代表希腊字母贝塔
-
核心思想就是timeout interval=EstimatedRTT plus “safety margin”
-
large variation in EstimatedRTT -> larger safety margin
-
那么这个safety margin(安全界限)是什么呢
-
DevRTT = (1-b)*DevRTT +b *| SampleRTT-EstimatedRTT |
- | SampleRTT-EstimatedRTT | 为差值的绝对值
- (typically, b = 0.25)
- DevRTT 就是上面的safety margin
-
TimeoutInterval = EstimatedRTT + 4***DevRTT **
- 最终计算出这个timeout value
TCP fast retransmit
- time-out period often relatively long: long delay before resending lost packet
超时时间通常较长,即重发丢失数据包之前的较长时间延迟.
- detect lost segments via duplicate ACKs.
通过重复的ack检测丢失的段。
- sender often sends many segments back-to-back
Sender经常背对背发送许多段
- if segment is lost, there will likely be many duplicate ACKs.
如果段丢失,很可能会有许多重复的ack
【就是说,假如sender收到了好几个重复的ack,就说明他后面那个pkt丢了,就需要重发后面那个,如图所示】
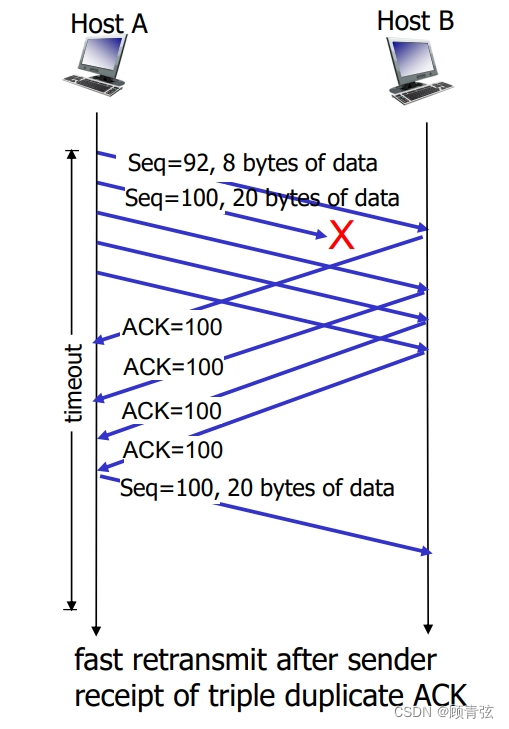
TCP flow control
- 简单来说,就是receiver来控制sender传输的速度
- receiver controls sender, so sender will not overflow receiver buffer by transmitting too much, too fast
接收方控制发送方,因此发送方不会因发送太多、太快而溢出接收方缓冲区
- receiver “advertises” free buffer space by including rwnd value in TCP header of receiver-to-sender segments
接收端通过在接收端到发送端段的TCP报头中包含rwnd值来“发布”空闲缓冲区空间
- rwnd = receive window,即receiver告诉sender我可以接受的数据量
- RcvBuffer size set via socket options (typical default is 4096 bytes)
- 通过套接字选项设置的RcvBuffer大小(典型的默认值是4096字节)
- many operating systems autoadjust RcvBuffer
- 许多操作系统自动调整RcvBuffer
- sender limits amount of unACKed (“in-flight”) data to receiver’s rwnd value
【意思就是sender会根据rwnd来控制unACKed的数据量】
- guarantees receive buffer will not overflow
保证接收缓冲区不会溢出
MSS and MTU
- MSS (mentioned in Nagle algorithm) is a parameter specifying the largest amount of data in a single IP datagram that should be sent by a remote host.
MSS(在Nagle算法中提到)是一个参数,指定远程主机应发送的单个IP数据报中的最大数据量。
- MTU is a parameter specifying the largest amount of data that a communication protocol or system can pass onwards. For example, standards (e.g. Ethernet) can fix the size of an MTU, or systems (such as pointto-point serial links) may set MTU at connect time.
MTU是一个参数,指定通信协议或系统可以向前传输的最大数据量。例如,标准(如以太网)可以固定MTU的大小,或者系统(如点对点串行链路)可以在连接时设置MTU。
- MSS size is set according to MTU:
MSS = MTU – IP header size – TCP header size

Nagle’s algorithm
- A problem can occur when an application generates data very slowly.
当应用程序生成数据非常缓慢时,就会出现问题。
- Consider, ssh that generates data only when a user types.
例如,ssh只在用户输入时生成数据。
- TCP will send the data as it arrives at the send buffer if there is space left in the send buffer.
如果发送缓冲区中有剩余空间,则TCP将在到达发送缓冲区时发送数据。
- This means (for ssh) one packet sent every time user hits key.
这意味着(对于ssh)用户每次按下键就发送一个数据包。
- Overhead of this is huge (TCP header + IP header + frame header to send one byte).
这样的开销是巨大的(TCP报头+ IP报头+帧报头发送一个字节)。
- Cure is known as “Nagle’s algorithm”.
解决办法被称为“纳格尔算法”。
算法内容
- The sending TCP sends the first piece of data it receives – no matter no small or large
sending TCP发送它接收到的第一块数据——无论大小
- Sending TCP accumulates data in the buffer and waits until one of the following before sending the segment:
发送TCP在缓冲区中积累数据,并在发送段之前等待以下情况之一:
- The receiving TCP sends an acknowledgement
接收TCP发送确认信息
- Data has accumulated to fill a maximum size segment
累积的数据将填充最大大小的段
- Repeat step 2
- Note: Sometimes Nagle’s algorithm should be switched off – e.g. when fast interaction is vital and you want small packet sizes to be sent.
注意:有时Nagle的算法应该关闭——例如,当快速交互是至关重要的,而且你想要发送小尺寸的数据包时。
算法用来解决的问题——silly window syndrome
- Silly Window Syndrome occurs when the TCP system is forced to send very small packets. Named because window size is “silly”.
当TCP系统被迫发送非常小的数据包时,就会发生傻窗综合征。命名是因为窗口大小“愚蠢”。
- This can happen in two separate ways:
-
Sender produces data very slowly.
- Same problem as Nagle’s algorithm.
-
Receiver processes data very slowly.
- Single byte or small number removed from full receive buffer.
- 从全部接收缓冲区中删除的单字节或小数目。
- Sender is informed of opportunity to send small number of bytes and immediately sends filling buffer.
- 发送方被告知有机会发送少量字节,并立即发送填充缓冲区。
- Process repeats.
- 过程反复
- Cure – receiver does not advertise windows that would cause sender to send small amounts of data.
解决办法-接收方不发布会导致发送方发送少量数据的窗口。
【对于这个算法,简单来说就是解决发送大量小的数据包可能造成拥塞的问题。所以先发一个小包,然后把其他的放起来先不发,等收到ack或者缓存区满了才发,有效减少数据包的数量】
TCP connection management
- before exchanging data, sender/receiver “handshake”
在交换数据之前,发送方/接收方“握手”
- agree to establish connection (each knowing the other willing to establish connection)
- 同意建立联系(双方都知道对方愿意建立联系)
- agree on connection parameters
- 同意连接参数
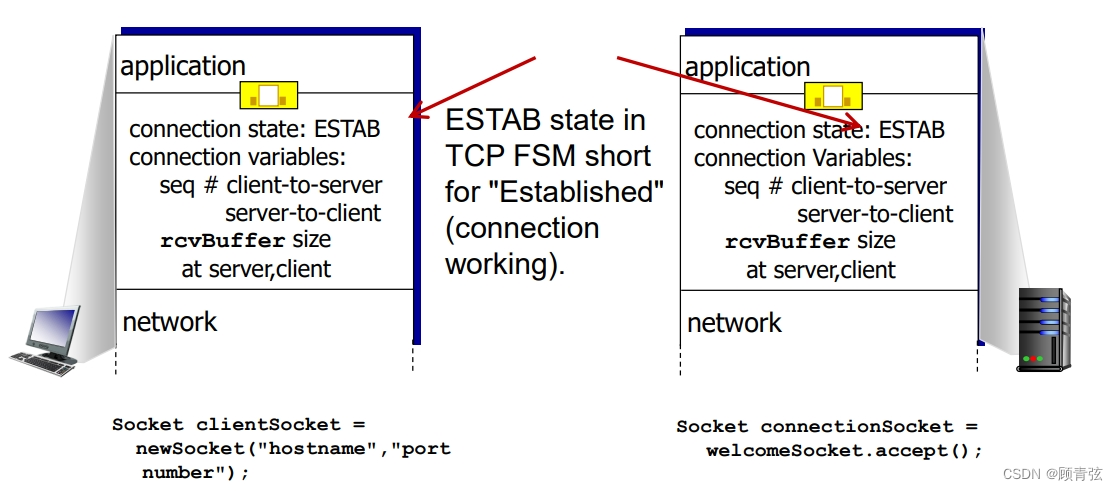
【这个图大概看看就行了,我也不是很明白是啥意思,但是老师讲的时候强调了这个rcvBuffer】
2-way handshake

【就是简单的一应一答的过程】
2-ways handshake不适用的情况
- variable delays
可变延迟
- retransmitted messages (e.g. req_conn(x)) due to message loss
由于消息丢失而重传的消息(例如req_conn(x))
- message reordering
消息重新排序
- cannot “see” other side
不能“看到”另一边
两个图例

【这种情况就是在acc_conn(x)还没回来的时候就timeout了,于是client retransmit了一个,但是到了server的时候,connection已经结束了,所以只是建立了一个client-server的单项连接,即client连接到了server,但server不知道有client】

【这种情况就是在上一个的基础上send了一些数据,然后又retransmit了这些数据。从client看,就是两次建立连接和两次发送数据,但是在server看来,是两次独立的连接和两次独立的数据】
【举个例子,A给B转了100块钱,但一开始没转成功,又转了一次,理论上就转了100块,但在B看来,A转了两次100块,收到了200块。】
3-way handshake
分为 SYN —— SYN-ACK —— ACK
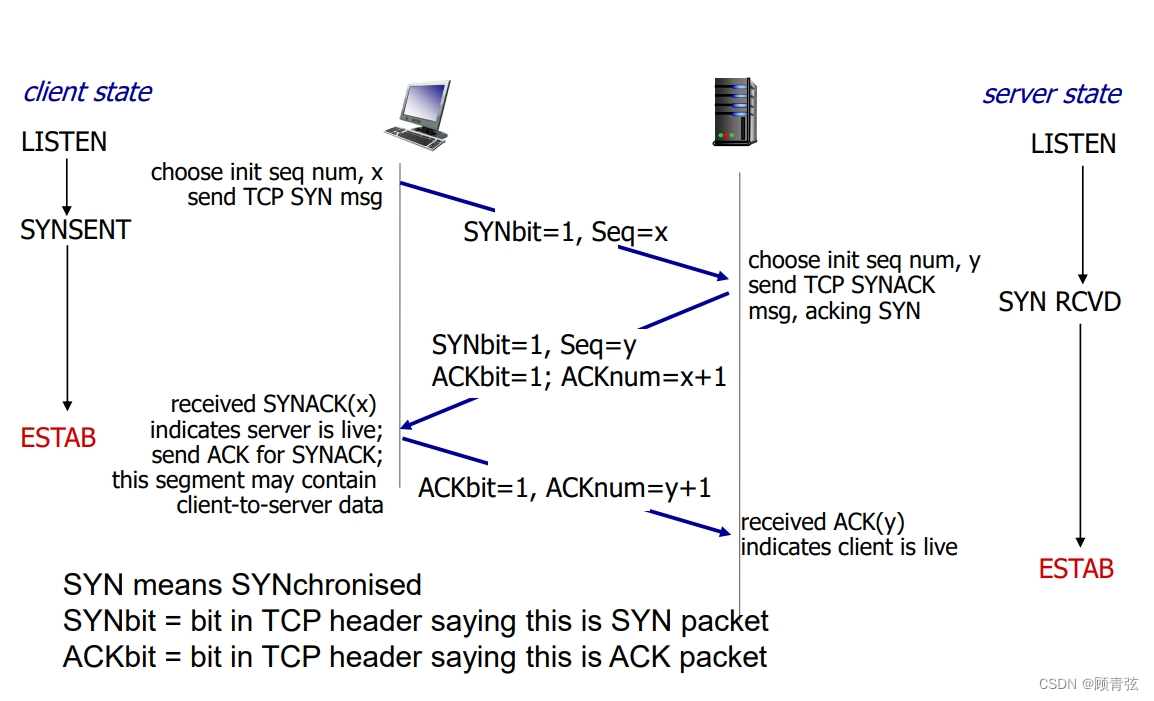
- 第一次握手(SYN):SYNbit=1,告诉server想要建立新连接,seq=x,说明send了一个序号为x的数据来建立连接
- 第二次握手(SYN-ACK):SYNbit=1,ACKbit=1,告诉client server收到了数据,seq=y,说明server返回了一个序号为y的数据,ACKnum=x+1,说明接下来需要client发送序号为x+1的数据(和前面的ACK,seq意义相同)
- 第三次握手(ACK):ACKbit=1,告诉server我收到了你的数据,ACKnum=y+1,告诉server希望下次收到的是y+1开始的数据
在finite state machine中的图解

【不知道有什么用,只是说了TCP的三次握手在finite state machine中】
TCP:closing a connection
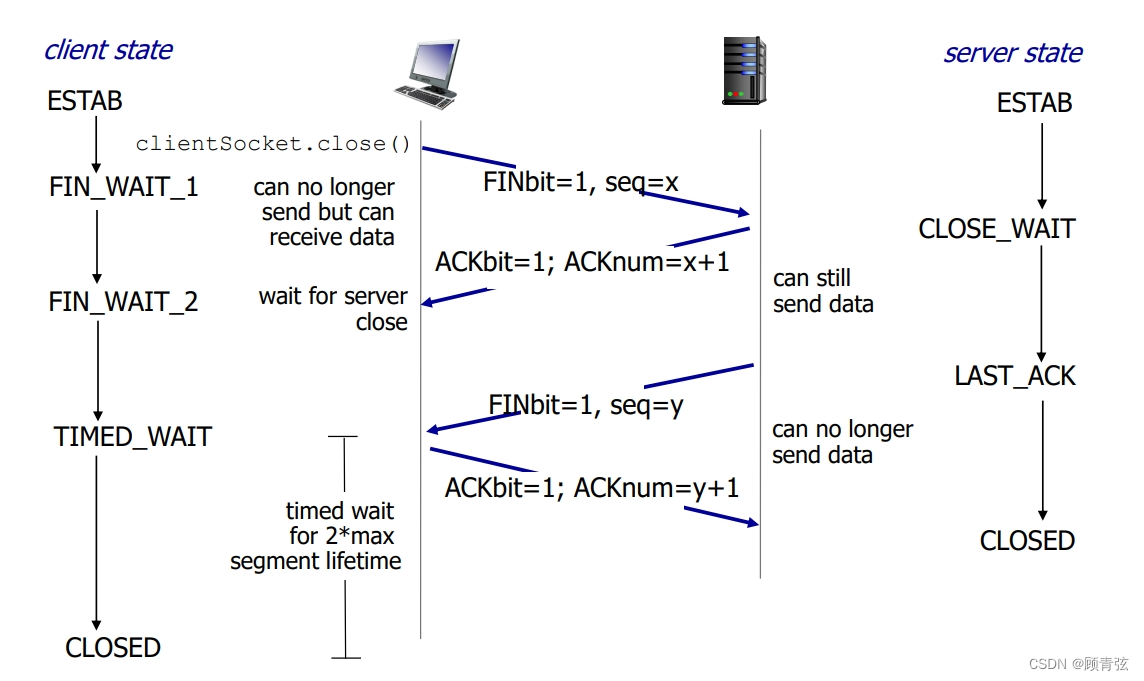
【和建立连接的过程大同小异,中间的两个server → client的可以合在一起,叫做FIN-ACK,如果分开的话,在这两段之间client仍然可以向server传输数据】
Principles of congestion control
- 什么是congestion(拥塞)?
- informally: “too many sources sending too much data too fast for network to handle”
非正式的说法:“太多的源发送太多的数据,速度太快,网络无法处理”
- how does this look?
- lost packets (buffer overflow at routers)
- long delays (queueing in router buffers)
causes and costs of congestion
- Too much traffic enters router – buffer fills up, this increases delay (and hence reduces throughput).
太多的流量进入路由器——缓冲区被填满,这会增加延迟(从而降低吞吐量)。
- Much too much traffic enters router – buffer overfills and causes loss. Packet needs to be retransmitted.
太多的流量进入路由器——缓冲区溢出,造成损失。报文需要重传。
- If packet is lost after several “hops” then many resources are wasted. (e.g. Packet travels from A to B to C to D then lost at D – it has taken up space at A, B and C unnecessarily).
如果数据包在几“跳”后丢失,那么许多资源将被浪费。(例如,数据包从A到B到C再到D,然后在D处丢失——它不必要地占用了A、B和C处的空间)。
- Useful concept: goodput – this is the rate at which data reaches the application layer. Different from throughput because of:
有用的概念:goodput——这是数据到达应用层的速率。不同于吞吐量的原因是:
- loss
- retransmission
- corrupted packets
additive increase & multiplicative decrease
- approach:sender increases transmission rate (window size), probing for usable bandwidth, until loss occurs
方法:发送方增加传输速率(窗口大小),探测可用带宽,直到发生丢失
- Set cwnd – congestion window to initial value
- additive increase: increase cwnd by 1 MSS every RTT until loss detected
加性增加:每RTT增加1 MSS,直到检测到丢失
- multiplicative decrease: cut cwnd in half after loss
乘减:发现丢失后后将cwnd减半
如图所示
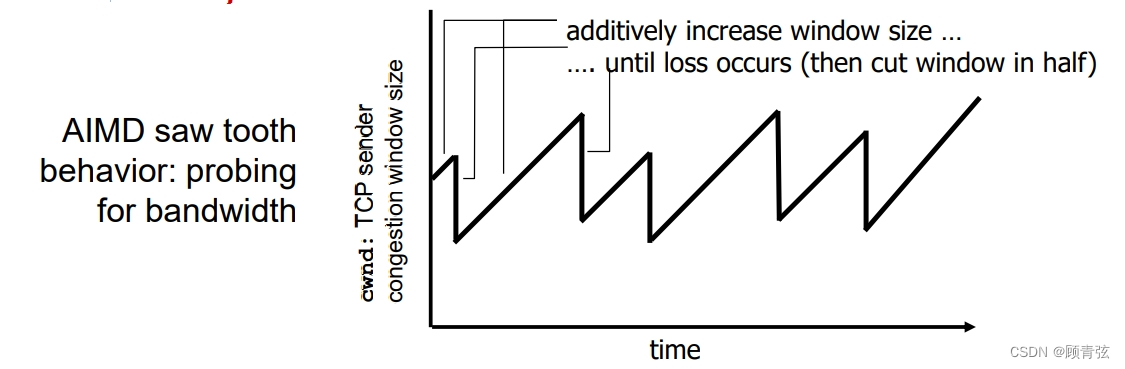
【按照每RTT一个MSS的速度增加,当检测到丢失时立马减掉一半,再从头增加】
details

- sender limits transaction: LastByteSent - LastByteAcked ≤ cwnd
【(黄色+绿色)- 绿色,就是黄色的部分要小于cwnd】
- cwnd is dynamic, function of perceived network congestion
CWND是动态的,感知网络拥塞的功能
- TCP sending rate:
- roughly: send cwnd bytes, wait RTT for ACKS, then send more bytes
- rate ≈ cwnd / RTT (bytes/sec)
slow start
- when connection begins, increase rate exponentially until first loss event:
- initially cwnd = 1 MSS
- double cwnd every RTT
- done by incrementing cwnd for every ACK received
- 通过增加接收到的每个ACK的cwnd来完成
- summary: initial rate is slow but ramps up exponentially fast
总结:初始速率是缓慢的,但上升指数级快速

【一开始传一个,然后传两个,然后传四个……这样来增加速度】
TCP flavours TCP的种类
- There are lots of implementations of TCP.
TCP有很多实现。
- The protocol specifies certain things but leaves others free.
协议规定了某些内容,但保留了其他内容。
- For example TCP protocols can choose how they want to react to duplicate ACKs or what their initial window sizes are.
例如,TCP协议可以选择如何对重复的ack做出反应,或者选择它们的初始窗口大小。
- TCP protocols are sometimes named after places with casinos (gambling): Reno, Tahoe, New Reno
TCP协议有时以赌场(赌博)的地方命名:Reno, Tahoe, New Reno
TCP: detecting, reacting to loss
TCP RENO 是怎么处理的
- loss indicated by timeout:
- cwnd set to 1 MSS;
- window then grows exponentially (as in slow start) to threshold, then grows linearly
- 窗口然后指数增长(如慢启动)到阈值,然后线性增长
-
loss indicated by 3 duplicate ACKs:
- dup ACKs indicate network capable of delivering some segments
- dup ack表示网络能够传输某些段
- cwnd is cut in half window then grows linearly
- cwnd被切掉一半,然后线性增长
TCP Tahoe 是怎么处理的
- TCP Tahoe always sets cwnd to 1 (timeout or 3 duplicate acks)
TCP Tahoe总是将cwnd设置为1(超时或3个重复的ack)
两个一起对比看
- Q: when should the exponential increase switch to linear?
什么时候指数增长应该转变成线性增长?
- A: when cwnd gets to 1/2 of its value before timeout.
当CWND在超时前达到其值的1/2时。

【到达ssthresh时转为线性增长】
- Implementation: 实现方法
- variable ssthresh 用变量ssthresh
- on loss event, ssthresh is set to 1/2 of cwnd just before loss event
- 丢失事件时,阈值设置为丢失事件前CWND的1/2
TCP throughput
假定是TCP RENO
- W: window size (measured in bytes) where loss occurs
- avg. window size (# in-flight bytes) is ¾ W
- avg. throughput is 3/4 W per RTT
- avg TCP thruput = 3/4 W/RTT (bytes/sec)

TCP Fairness
- fairness goal: if K TCP sessions share same bottleneck link of bandwidth R, each should have average rate of R/K
公平目标:如果K个TCP会话共享同一个带宽为R的瓶颈链路,则每个会话的平均速率为R/K
Fairness and UDP
▪ multimedia apps often do not use TCP
多媒体应用程序通常不使用TCP
- do not want rate throttled by congestion control
不希望速率被拥塞控制控制
▪ instead use UDP: send audio/video at constant rate, tolerate packet loss
使用UDP:以恒定的速率发送音频/视频,容忍包丢失.
Fairness, parallel TCP connections
- application can open multiple parallel connections between two hosts
应用程序可以在两台主机之间打开多个并行连接
- web browsers do this
- e.g., link of rate R with 9 existing connections:
- 例如,速率为R的连接有9个现有连接:
- new app asks for 1 TCP, gets rate R/10
- 新应用程序请求1个TCP,得到速率R/10【1/(9+1)】
- new app asks for 11 TCPs, gets just over R/2
- 新的应用程序要求11个tcp,得到刚刚超过R/2【11/(9+11)】
开始Network Layer部分
Two key network-layer functions
- network-layer functions:
- forwarding: move packets from router’s input to appropriate router output
- 转发:将数据包从路由器的输入移动到适当的路由器输出
- routing: determine route taken by packets from source to destination
- 路由:确定数据包从源到目的所经过的路由
以旅行作为类比
- forwarding: process of getting through one road junction.
转发:通过一个路口的过程
- routing: process of planning trip from source to destination
路由:从源到目的地计划行程的过程
Network layer
- transport segment from sending to receiving host
从发送主机到接收主机的传输段
- on sending side encapsulates segments into datagrams
发送端将段封装到数据报中
- on receiving side, delivers segments to transport layer
接收端将段传送到传输层
- network layer protocols in every host, router
每个主机,路由器都有网络层协议
- router examines header fields in all IP datagrams passing through it
路由器检查所有经过它的IP数据报的报头字段
IPv4 address notation
- There are three common notations to show an IPv4 address:
- binary notation 二进制记数法
- dotted-decimal notation (most commonly used) 点分十进制记数法(最常用)
- hexadecimal notation 十六进制表示法

【简单的二进制转换】
data plane
- local, per-router function
本地的,pre-router功能
- determines how datagram arriving on router input port is forwarded to router output port
确定到达路由器输入端口的数据报如何转发到路由器输出端口
- forwarding function
- 【就是决定datagram怎么在路由器里从input传递到相应的output,主要用于路由器里的forwarding】
Control plane
- network-wide logic
- determines how datagram is routed among routers along end-end path from source host to destination host
确定数据报如何在路由器之间沿着从源主机到目标主机的端-端路径路由
- two control-plane approaches:
- traditional routing algorithms: implemented in routers
- 传统的路由算法:在路由器中实现
- software-defined networking (SDN): implemented in (remote) servers
- 软件定义网络(SDN):在(远程)服务器中实现
Per-router control plane
- Individual routing algorithm components in each and every router interact in the control plane
每个路由器中的各个路由算法组件在控制平面中相互作用

【上面是control plane,下面是data plane,二者共同组成router】
Logically centralized control plane
- A distinct (typically remote) controller interacts with local control agents (CAs)
不同的(通常是远程的)控制器与本地控制代理(ca)交互。

Network layer service models

【第一行是最常用的网络架构,“best effort”的意思是虽然Internet不能保证任何事,但是会尽全力】
Router architecture overview

【数据从input ports进,output ports出,中间的high-speed switching fabric(高速交换网络)可以分配出口(比如下面的ports的数据从上面的ports出去)】
Input port function
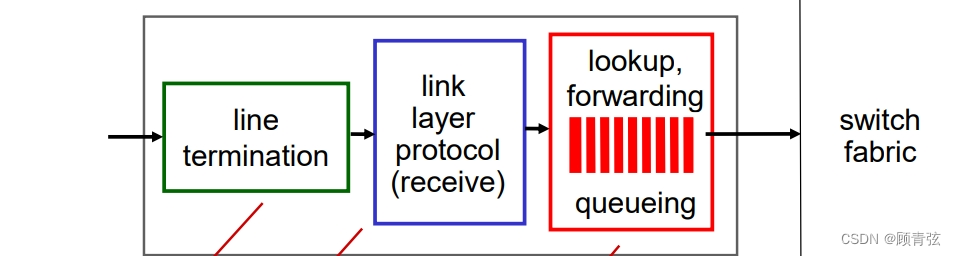
- line termination:physical layer —— bit-level reception
线路终止:物理层——位级接收
【简单来说就是接收信号的】
- link layer protocol(receive):data link layer —— e.g., Ethernet
链路层协议(接收):数据链路层,如以太网
- lookup, forwarding: decentralized switching 分散切换
- using header field values, lookup output port using forwarding table in input port memory (“match plus action”)
- 使用报头字段值,使用输入端口内存中的转发表查找输出端口(“匹配+动作”)
- goal: complete input port processing at ‘line speed’
- 目标:以“线速度”完成输入端口处理
- queuing: if datagrams arrive faster than forwarding rate into switch fabric
- 排队:如果数据报到达交换机的速度比转发速度快
- destination-based forwarding: forward based only on destination IP address (traditional)
- 基于目的的转发:只基于目的IP地址转发(传统)
- generalized forwarding: forward based on any set of header field values
- 广义转发:基于任何一组报头字段值进行转发
Longest prefix matching
最长前缀匹配
- when looking for forwarding table entry for given destination address, use longest address prefix that matches destination address.
- 查找指定目的地址的转发表表项时,使用与目的地址匹配的最长地址前缀。
举例:
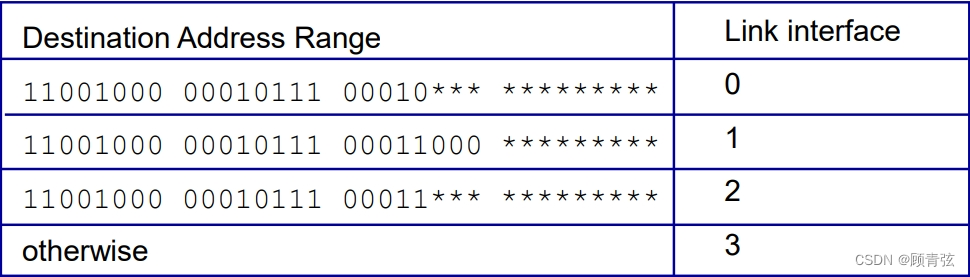
【如果有重叠(比如图里的第二行和第三行),则取最长的一个(第二行)】
- longest prefix matching: often performed using ternary content addressable memories (TCAMs) specialised very high speed memory
- 最长前缀匹配:通常使用三元内容可寻址存储器(TCAMs)专用高速存储器执行
- content addressable: present address to TCAM: retrieve address in one clock cycle, regardless of table size
- 内容可寻址:到TCAM的当前地址:在一个时钟周期内检索地址,无论表的大小
- Cisco Catalyst: can up ~1M routing table entries in TCAM
- 交换机:可以在TCAM中增加~1M的路由表项
switching fabrics
交换网络
-
transfer packet from input buffer to appropriate output buffer
-
将数据包从输入缓冲区传输到适当的输出缓冲区
-
switching rate: rate at which packets can be transfer from inputs to outputs
-
交换速率:数据包从输入端传输到输出端的速率
- often measured as multiple of input/output line rate
- 通常用输入/输出线速率的倍数来衡量
- N inputs: switching rate N times line rate desirable
- N输入:开关速率N倍线路速率可取
-
three types of switching fabrics
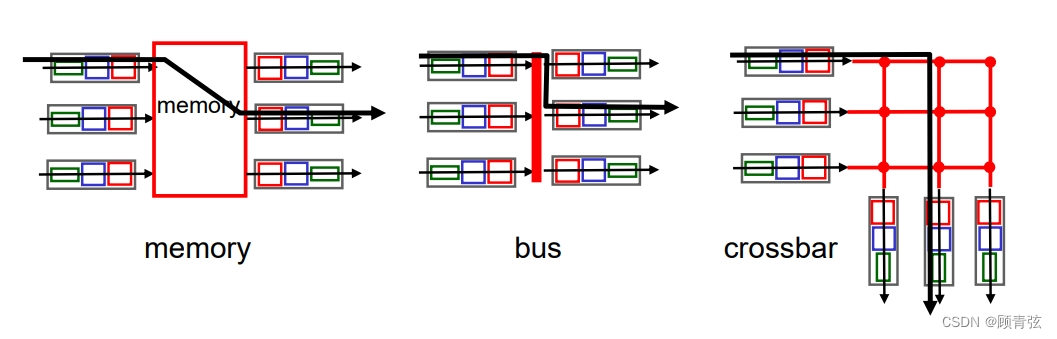
Switching via memory
first generation routers:
- traditional computers with switching under direct control of CPU
- 由中央处理器直接控制开关的传统计算机
- packet copied to system’s memory
- 包拷贝到系统内存
- speed limited by memory bandwidth (2 bus crossings per datagram)
- 受内存带宽限制的速度(每个数据报有2个总线交叉)
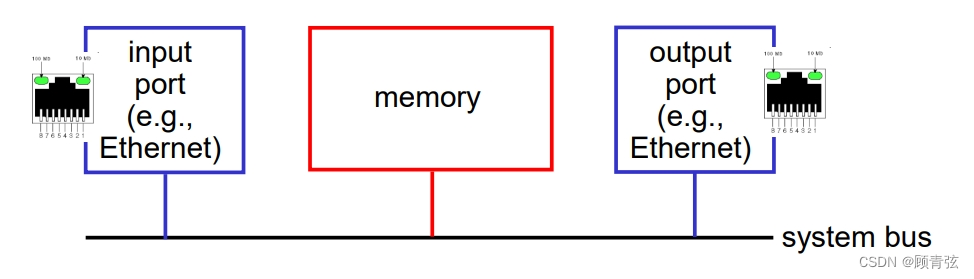
【每个packet从input port经过system bus到memory,再从memory经过system bus到output port】
Switching via a bus
- datagram from input port memory to output port memory via a shared bus
- 通过共享总线从输入端口内存到输出端口内存的数据报
- bus contention: switching speed limited by bus bandwidth
- 总线竞争:切换速度受总线带宽限制
- 32 Gbps bus, Cisco 5600: sufficient speed for access and enterprise routers
- 32 Gbps总线,Cisco 5600:足够的速度用于访问和企业路由器

【以32 Gbps bus为例,但是假如输入的速率是10*10 Gbps,那么这个bus就会变成bottle neck,将速率控制在32Gbps】
Switching via interconnection network
- overcome bus bandwidth limitations
- 克服总线带宽限制
- banyan networks, crossbar, other interconnection nets initially developed to connect processors in multiprocessor
榕树网络,交叉棒,其他互连网最初开发用于连接多处理器中的处理器
- advanced design: fragmenting datagram into fixed length cells, switch cells through the fabric.
先进的设计:将数据报分割成固定长度的单元,通过fabric进行交换单元。
- Cisco 12000: switches 60 Gbps through the interconnection network
Cisco 12000:通过互连网络交换60gbps
Input port queuing
- fabric slower than input ports combined → queueing may occur at input queues
Fabric比输入端口的组合速度慢→在输入队列中可能发生排队
- queueing delay and loss due to input buffer overflow!
- 由于输入缓冲区溢出导致排队延迟和丢失
- Head-of-the-Line (HOL) blocking: queued datagram at front of queue prevents others in queue from moving forward.
- head -of- line (HOL)阻塞:在队列前面排队的数据报阻止队列中的其他数据报向前移动

【下面的绿色就被delay了,只有等两个红色都结束了才能开始】
Output port
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xscHf22v-1668946744869)(bd8e3fcd1b5d4334aedaac93110d05df.jpg)]
- buffering required when datagrams arrive from fabric faster than the transmission rate
当从fabric到达的数据报比传输速率快时,需要缓冲
- Datagram (packets) can be lost due to congestion, lack of buffers
- 数据报(包)可能由于拥塞、缓冲区缺乏而丢失
- scheduling discipline chooses among queued datagrams for transmission
调度规程在队列中的数据报中进行选择以进行传输
- Priority scheduling – who gets best performance, network neutrality
- 优先调度——谁能获得最好的性能,网络中立性
Output port queneing

- buffering when arrival rate via switch exceeds output line speed
- 当通过开关的到达速率超过输出线速度时进行缓冲
- queueing (delay) and loss due to output port buffer overflow!
- 由于输出端口缓冲区溢出,排队(延迟)和丢失!
How much buffering?
- RFC 3439 rule of thumb: average buffering equal to “typical” RTT (say 250 msec) times link capacity C
- RFC 3439经验法则:平均缓冲等于“典型的”RTT(比如250 msec)乘以链路容量C
- e.g., C = 10 Gpbs link: 2.5 Gbit buffer
- recent recommendation: with N flows, buffering equal to (RTT*C) / (N^1/2)
Scheduling mechanisms
调度机制
- scheduling: choose next packet to send on link.
- 调度:选择链路上发送的下一个报文。
- FIFO scheduling – first in first out 先进先出调度
- Like an orderly queue of people, no pushing in.
- 就像一排有序的队伍,没有人插队。
- If queue is full last packets are dropped.
- 如果队列已满,最后的数据包将被丢弃。
- Priority scheduling 优先调度
- Some packets are more important
- Example: You need live video packets now, email could wait.
- Round robin scheduling 循环调度法
- If your queue is from several inputs ports treat them fairly
- 如果您的队列来自多个输入端口,则公平对待它们
- Pick a packet from input port 1, then 2, then 3, then 4
- 从输入端口1中选取一个数据包,然后是端口2,端口3,端口4
- Port which is sending lots of traffic doesn’t block others.
- 发送大量流量的端口不会阻塞其他端口。
- Weighted Fair Queue (like this but give some queues a little more priority – give a little more traffic to port 1)
- 加权公平队列(就像这样,但给一些队列更多的优先级——给端口1更多的流量)【谁速度快谁权重大】
IP datagram format

【左下角这个东西的意思是你每次传送都要40bytes的overhread,所以传送小数据效率会很低】
IP fragmentation, reassembly
IP的分片与重组
- network links have MTU (max.transfer size) -largest possible link-level frame
- 网络链路有MTU (max。传输大小)—最大可能的链路级帧
- 【说人话就是你最大的能传到下一层的数据量,你拆分的时候要按照最大的size=MTU去拆分】
- different link types, different MTUs
- large IP datagram divided (“fragmented”) within net
- 大型IP数据报在网络内被分割(“碎片化”)
- one datagram becomes several datagrams
- 一个数据报可以变成多个数据报
- “reassembled” only at final destination
- “重组”只在最终目的地
- IP header bits used to identify, order related fragments
- IP头位用于识别、排序相关片段
举例:

- length <= MTU
- fragflag:如果这个切片后面还有切片,那么就为1,否则为0
- offset:较长的分组的分片 , 中间的某个分片 , 在原来的 IP 分组中的相对位置 ; 单位是 8字节 ; 也就是说除了最后一个分片 , 每个分片的长度是 8字节的整数倍 ;
- 1480 bytes是因为有20bytes的IP头部
- MTU里也有20bytes的头部,所以需要1480+3*20 的总length
IP addressing
- IP address: 32-bit identifier for host, router interface
- IP地址:主机、路由器接口的32位标识符
- interface: connection between host/router and physical link
- 接口:主机/路由器与物理链路之间的连接
- routers typically have multiple interfaces
- 路由器通常有多个接口
- host typically has one or two interfaces (e.g., wired Ethernet, wireless 802.11)
- 主机通常有一个或两个接口(例如,有线以太网、无线802.11)。
- IP addresses associated with each interface
- IP地址与各接口关联
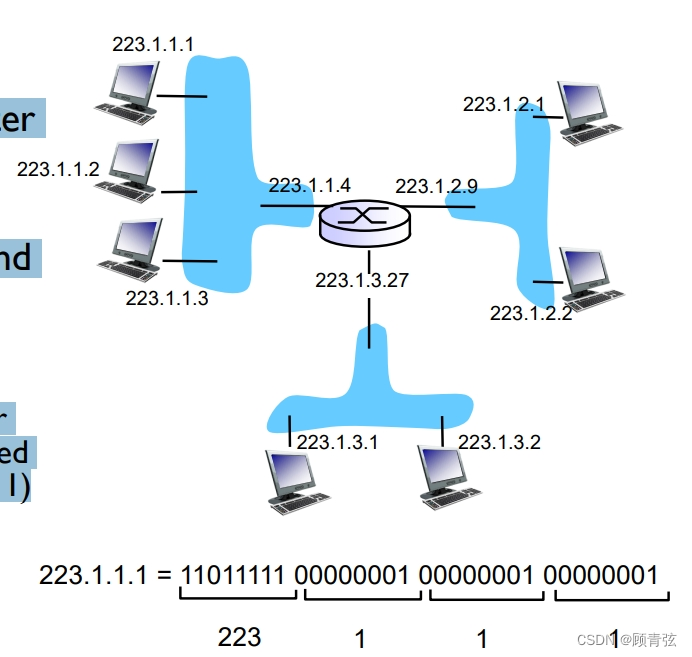
Classful IP addressing
有类的IP寻址
- In classful addressing, the IP address space is divided into five classes: A, B, C, D, E.
- 在分类寻址中,IP地址空间被分为五类:A、B、C、D、E。
- Starting number, n (first byte), shows whether Class A, B or C
- 起始数n(第一个字节)显示是A、B还是C类
- Class A: n<128 (up to 16m hosts)
- Class B: 128 <= n < 192 (up to 65K hosts)
- Class C: 192 <= n <224 (up to 254 hosts)
- 根据Class ABC的判定来判定那些是Netid,那些是Hostid

Addresses for private networks

- These addresses are “special” and not used on the general Internet. You use them to set up test networks or networks of machines not accessible from outside.
- 这些地址是“特殊的”,不会在一般的互联网上使用。您可以使用它们来设置测试网络或无法从外部访问的机器网络。
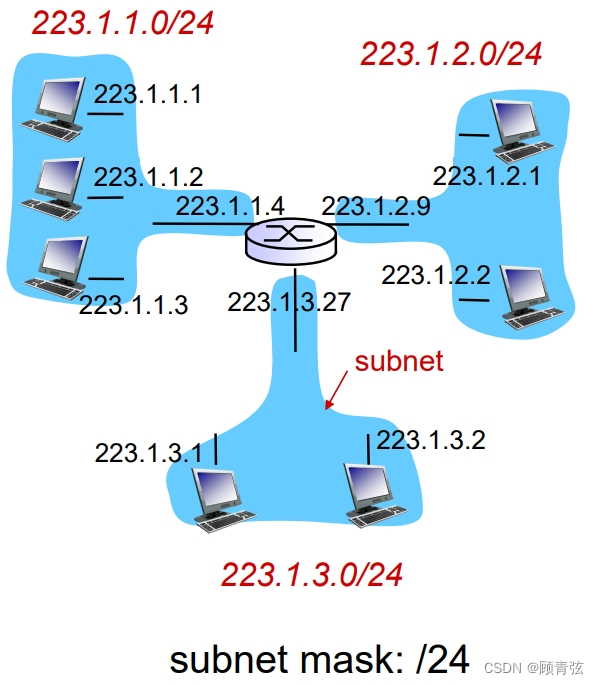
Subnets
- Subnet——device interfaces with same subnet part of IP address
子网——具有IP地址相同子网部分的设备接口
-
can physically reach each other without intervening router
-
可以在没有路由器介入的情况下物理上互相联系
-
在IP地址中:
- subnet part - high order bits
- 子网部分-高阶位
- host part - low order bits
- 主机部分-低阶位
- E.g. 223.1.1.1中,223.1.1是subnet part,1为host part
-
to determine the subnets, detach each interface from its host or router, creating islands of isolated networks
-
要确定子网,请将每个接口与它的主机或路由器分离,创建孤立的网络孤岛
-
each isolated network is called a subnet
-
每个独立的网络称为子网
-
subnet mask (or slash notation) number of bits taken to identify network
-
子网掩码(或斜杠符号)用于识别网络的位数
- /8 size of old class A
- /16 size of class B
- /24 size of class C
Network mask and subnetwork mask
网络掩码和子网掩码
- Subnetting increases length of netid and decreases length of hostid.
- 子网划分增加了netid的长度,减少了hostid的长度。

- To divide a network to s number of subnetworks, each of equal numbers of hosts, the subnetid for each subnetwork can be calculated as
- 要将一个网络划分为s个子网,每个子网的主机数量相等,每个子网的subnetid可以计算为
-
n_sub = n + log2(s)
-
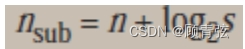
-
n - length of netid, n_sub - length of each subnetid, s – number of subnets
-
举例:classB的分割成四个子网,那么n_sub = 16 + log2(4) = 18,那么每一个子网的子网掩码就是18
Three-Level Addressing: Subnetting
三级处理:子网划分
- The idea of splitting a block to smaller blocks is referred to as subnetting.
将一个块分割成更小的块的想法被称为子网。
- In subnetting, a network is divided into several smaller subnetworks (subnets) with each subnetwork having its own subnetwork address.
在子网划分中,一个网络被划分为几个更小的子网(子网),每个子网都有自己的子网地址。
Why subnetting?
- an organization that was granted a large block of IP addresses (a long time ago this would be class A, class B etc)
- 一个被授予大量IP地址的组织(很久以前这是A类,B类等)
- wants to divide this into smaller blocks of addresses that are individual networks.
- 想把它分成更小的地址块,它们是单独的网络。
- Or perhaps organization wants to sell some of its IP addresses off.
- 或者组织想要出售一些IP地址。.
A subnetting example
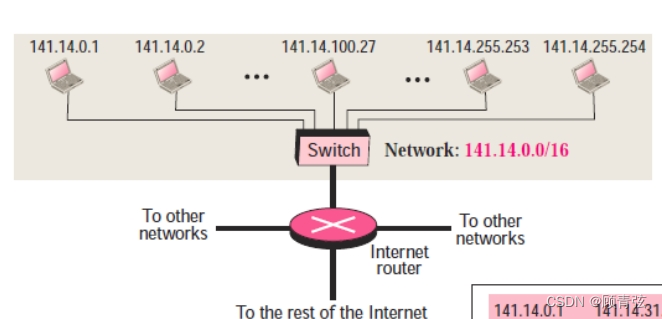
将上图划分成四个子网
- 由图可知,这个网络是ClassB(第一个数字为141,以及最后是/16)
- 分为四个子网,所以n_sub=16+log2(4)=18
- 子网的IP地址的第三组八位二进制数分别为00000000,01000000,10000000,11000000【十八位的最后两位在这里是前两位】
- 所以子网的IP地址前三个数字就可以确定了,如图
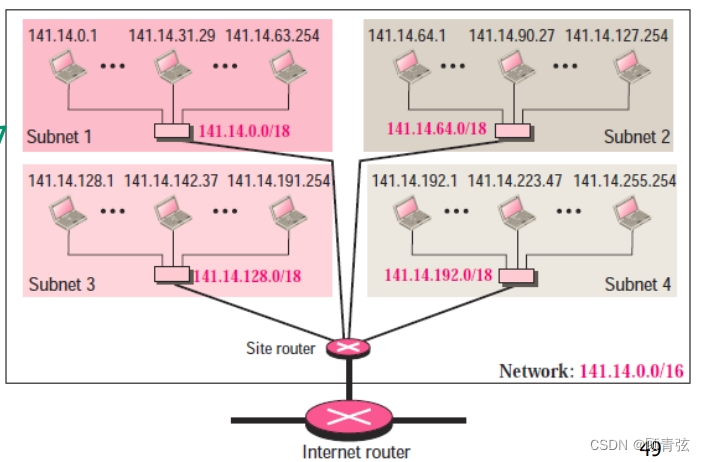
- a private site router is used to divide the network into four subnetworks.
- 私网路由器用于将网络划分为四个子网。
- after subnetting, each subnetwork can now have almost 2^14 hosts.
- 子网划分后,每个子网可以有2^14个主机。
- /16 and /18 show the length of the netid and subnetids.
Classless addressing
- In classless addressing, variable-length blocks are assigned that belong to no class.
- 在无类寻址中,不属于任何类的可变长度块被分配。
- In this architecture, the entire address space (232 addresses) is divided into blocks of different sizes.
- 在这种体系结构中,整个地址空间(232个地址)被划分为不同大小的块。
- The slash notation is formally referred to as classless interdomain routing or CIDR (Classless InterDomainRouting) notation.
- 斜杠表示法正式称为无类域间路由表示法或CIDR(无类域间路由表示法)。

-
用的仍是之前的八个一组的方法来表示,但是判定net和host的依据是斜杠后的数字
-
Network address is the address with all the host bits set to zero – address like any other but represents the network.
-
网络地址是所有主机位都设为零的地址——地址和其他地址一样,但代表网络。
-
E.g.10000001.01000010.00011000.00000000
-
Network address: 129.66.24.0/22
-
The network address is also the first usable IP address in the block
-
网络地址也是块中第一个可用的IP地址
-
Broadcast address (sends to everyone) is the address with all the host bits set to one.
-
广播地址(发送给所有人)是所有主机位都设置为1的地址。
-
E.g. 10000001.01000010.00011011.11111111
-
Broadcast address: 129.66.27.255/22
Splitting IP address by slash notation(方法及注意事项)
- For a /n address, the first n bits are the network address and the last 32-n bits are for the host.
- If the host parts are all 1s then this is the broadcast address – sent to all hosts on the network.
- Host has m = 32-n bits (e.g. /20 has m=12)
- Room for 2^m – 1 hosts (e.g. /20 has 4095)【减去了broadcast address,如果要avoid internet address的话就是2^m - 2】
- Example:
- 140.120.84.24/20
- Network address is 140.120.80.0/20
- Broadcast address is 140.120.95.255/20
- (95 is 01011111 255 is 11111111)
- /31 only has 1 host address
▪ /30 is smallest subnet we can have – 3 hosts
▪ /30 commonly used to connect just two routers
(which must be on same subnet).
VLSM (variable length subnet mask)
可变长子网掩码技术
【就是每个路由器的host数量不相等】
解决办法:

DHCP: Dynamic Host Configuration Protocol
动态主机配置协议
- goal: allow host to dynamically obtain its IP address from network server when it joins network
- 目标:允许主机在加入网络时从网络服务器动态获取自己的IP地址
- can renew its lease on address in use
- 在使用的地址上可以续租
- allows reuse of addresses (only hold address while connected/“on”)
- 允许重复使用地址(仅在连接时保持地址/ " on ")
- support for mobile users who want to join network (more shortly)
- 对想要加入网络的移动用户的支持(更简短)















 3841
3841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









