







在上一篇文章中我们分享了AUC的公式以及在图中所围的面积,此次我们分享一下AUC和排序损失的一个关系。
我们回顾一下AUC的公式:
我们说AUC就代表的是每两个坐标所围成的梯形求面积然后相加。AUC衡量的是分类器在所有可能的分类阈值上的性能。
它的图像表示为:
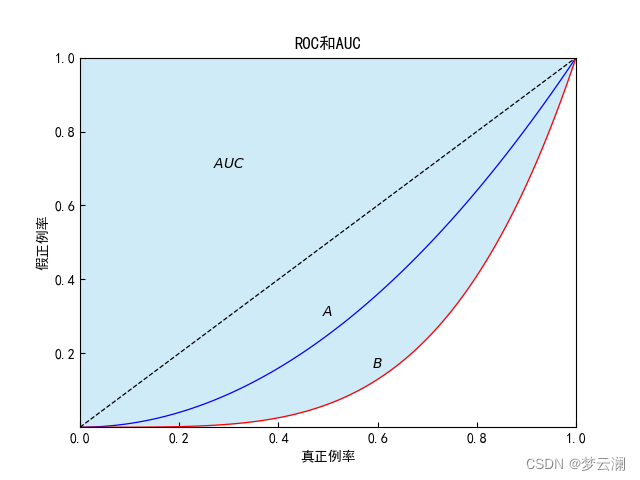
一般认为 ,AUC的值越大,分类器的性能越好。
在介绍排序损失之前,我们需要先介绍一下机器学习的赋值。
举个例子,假如我现在有十张照片,照片内容是数字,我现在需要机器学习识别出数字5的照片,那机器学习是怎样操作的呢?其实是这样的,计算机根据之前数据集训练的规则,然后给这10张照片赋值,如下表所示:

这个赋值都在0到1之间,假如说现在我设置阈值为0.5,那大于0.5的,都识别为数字5,阈值的设定直接影响查全率和查准率,我们也可以看到,大于0.5的值里面。照片数字也不一定是数字5,这就是有识别错误的照片,了解完这个我们就可以介绍一下排序损失了。
排序损失的公式如下:
哇,公式好长,没关系,别慌,咱们一个一个解释里面的字母含义!(公式自己拐弯的,整不回来了)
:正例个数
:负例个数
:正例集合
:负例集合
:相当于一个布尔发生器,当括号内条件满足时输出1,不满足时输出0。
:机器学习的预测规则,相当于数学上的一个函数。
你看,是不是也就那样,不难叭~
如果正例的预测值小于反例(就相当于上述说的赋值),则记一个“罚分”(就是布尔发生器输出1),若相等,则记0.5个“罚分”(后面那个,前面乘了一个0.5,所以记0.5)。
Rank loss衡量的是分类器输出的预测值与实际标签的一致性。在二分类问题中,Rank loss通常指的是正样本的预测值低于负样本预测值的情况。理想情况下,我们希望正样本的预测值高于负样本。
对应ROC曲线上的面积就如下图所示
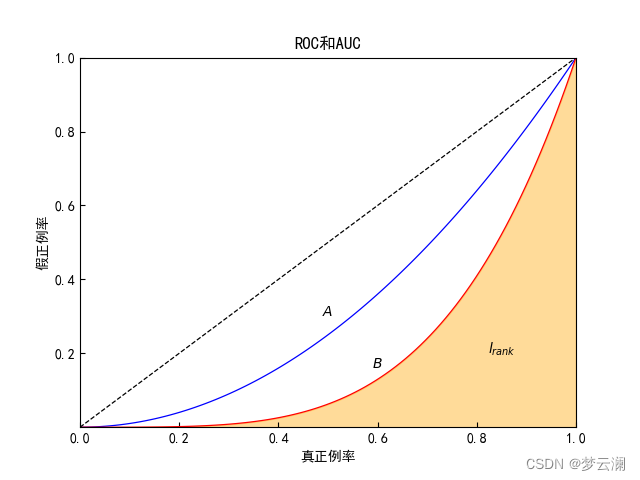
我们观察AUC和Rank loss所围的面积不难发现,它们两个的关系如下:
在图上表示为:
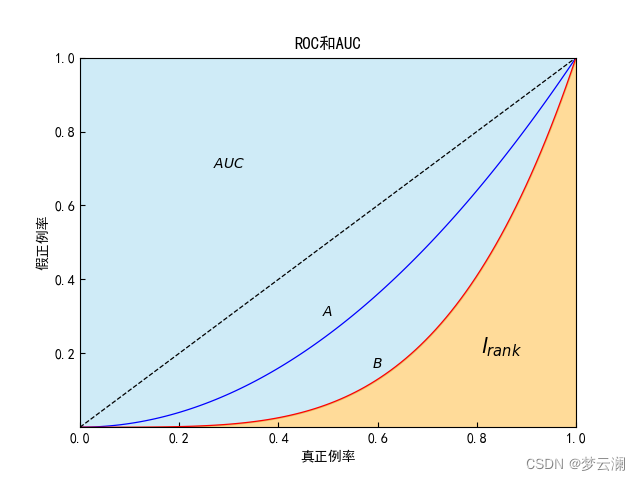
怎么样,不难理解叭~
ok,这篇就到这里啦,欢迎小伙伴们批评指正~(知识来源于西瓜书,图片自制)
















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











