






本地部署deepseek——个人总结
前言
参考视频
个人精简了一下,实际上部署很简单一两分钟就能说完
我的环境
系统win11 显卡4070s
NVIDIA-SMI 566.36 Driver Version: 566.36 CUDA Version: 12.7
关于cuda请自行安装
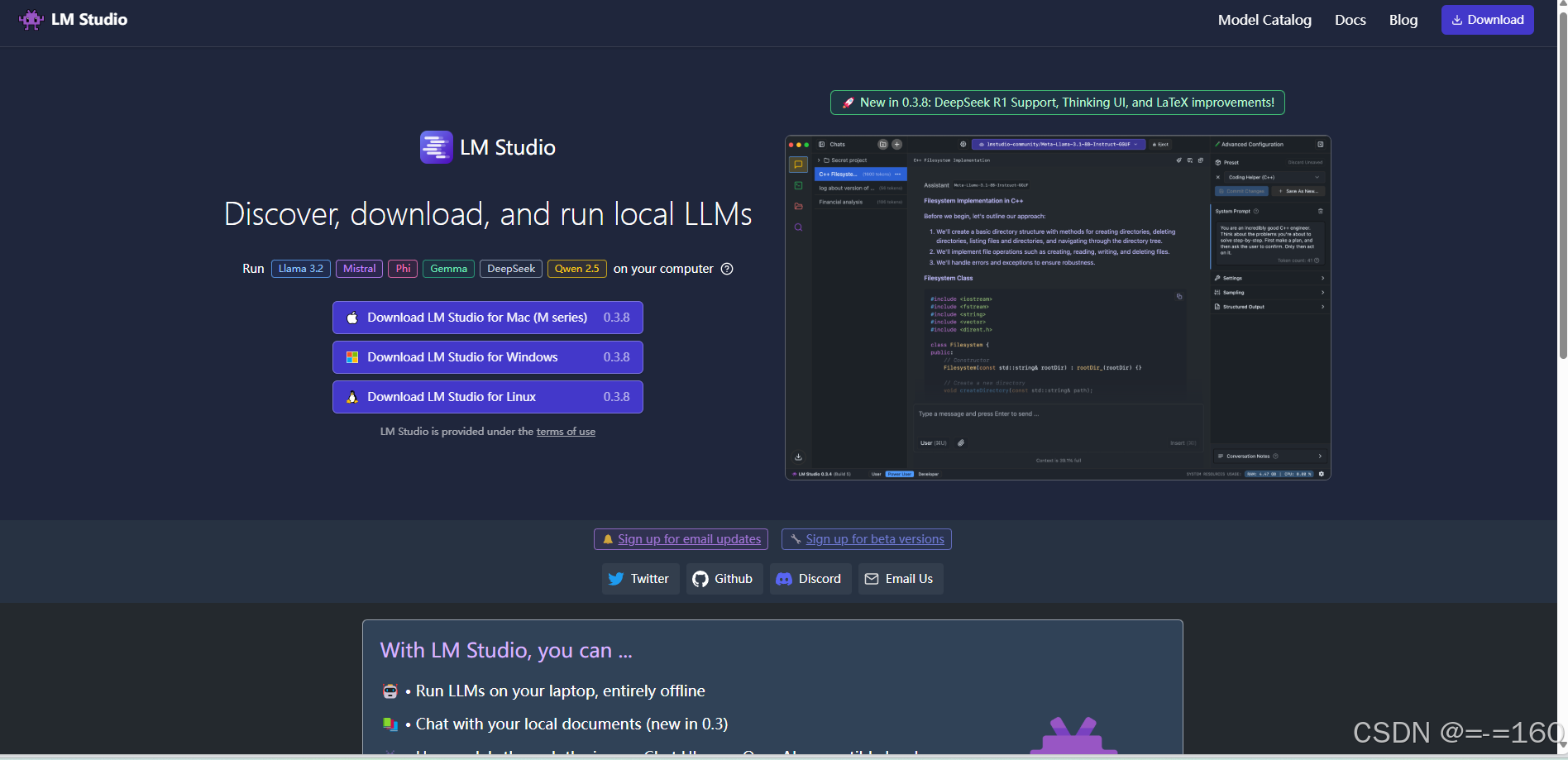
安装 LM Studio
自行安装
下载模型
1.5B: bartowski/DeepSeek-R1-Distill-Qwen-1.5B-GGUF · HF Mirror
8B: bartowski/DeepSeek-R1-Distill-Llama-8B-GGUF · HF Mirror
32B: bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF · HF Mirror
没有GPU:1.5B Q8推理 或者 8B Q4推理
4G GPU:8B Q4推理
8G GPU:32B Q4推理 或者 8B Q4推理
16G GPU:32B Q4推理 或者 32B Q8推理
24G GPU: 32B Q8推理 或者 70B Q2推理
这一步会下载得到一个*.gguf文件
![]()
导入模型
启动LM Studio,点击My Model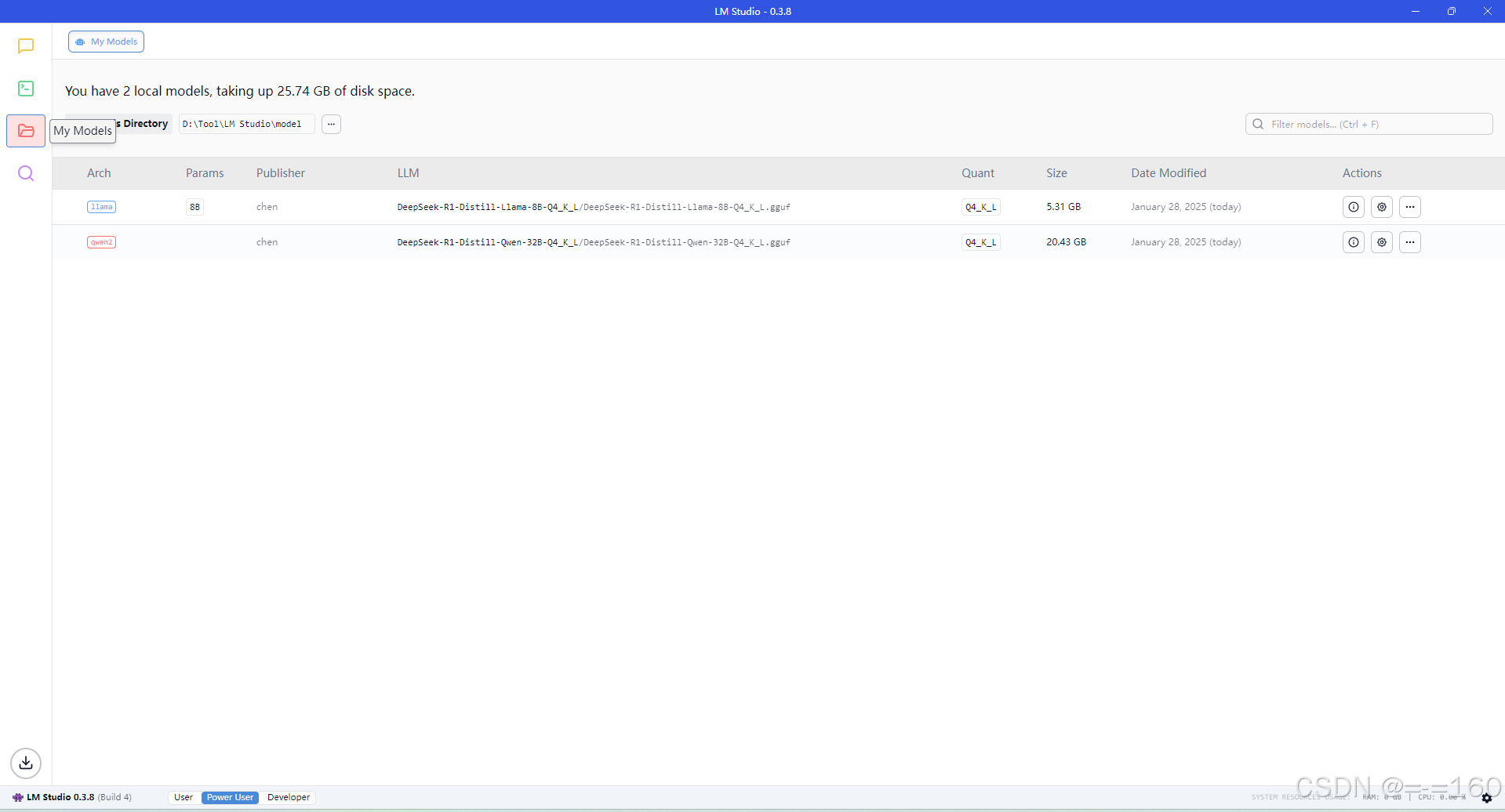
找到模型目录(这里我修改了默认的目录)
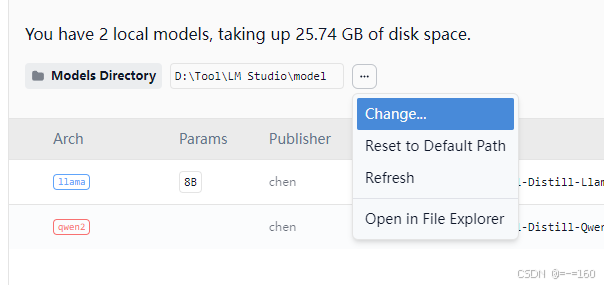
注意这里,先创建一个目录,名字任意
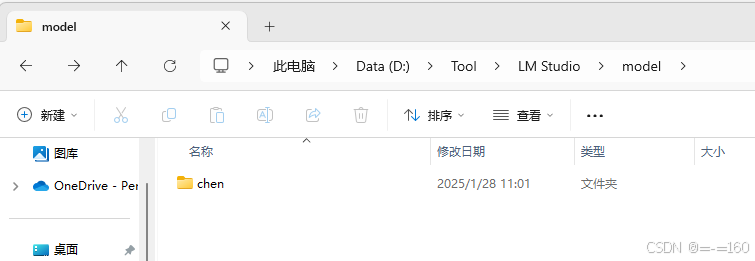
进入,再创建目录,名字为你要放入的模型的名字(去掉后缀)
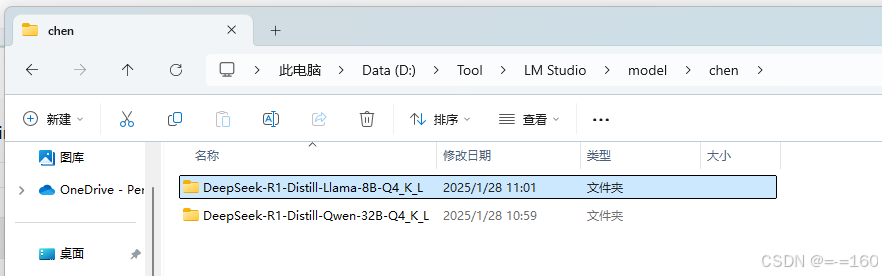
将模型复制进去
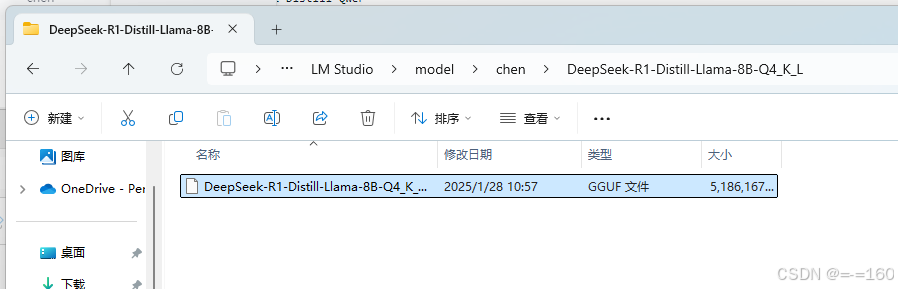
刷新后就能看到模型了
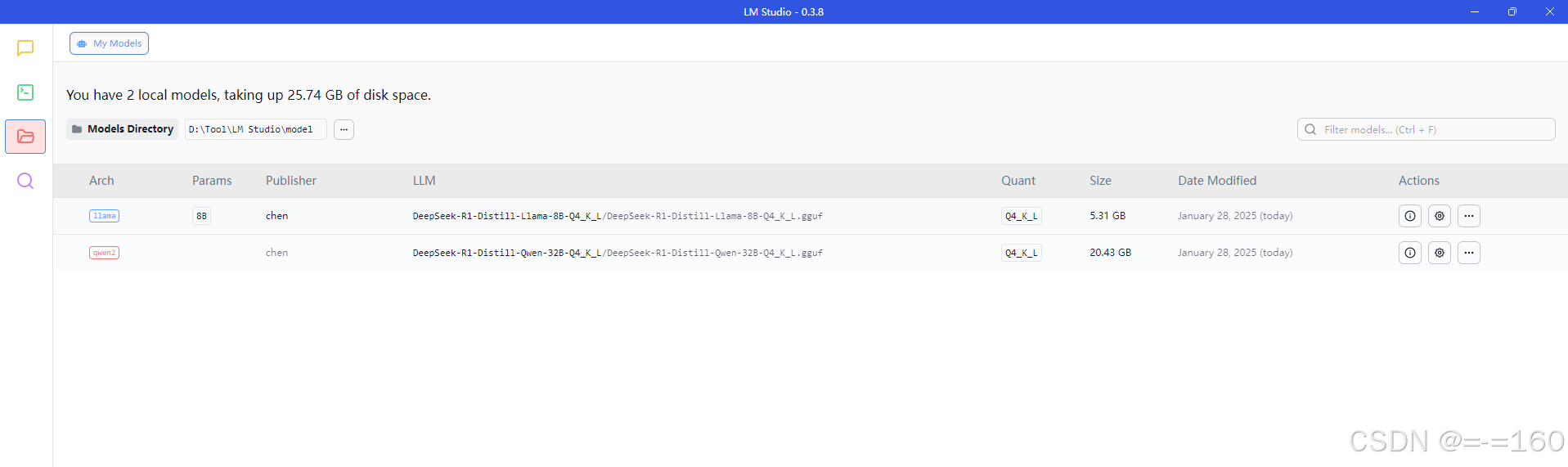
点聊天,加载模型,后面的部分自己按照提示就能完成,不说了
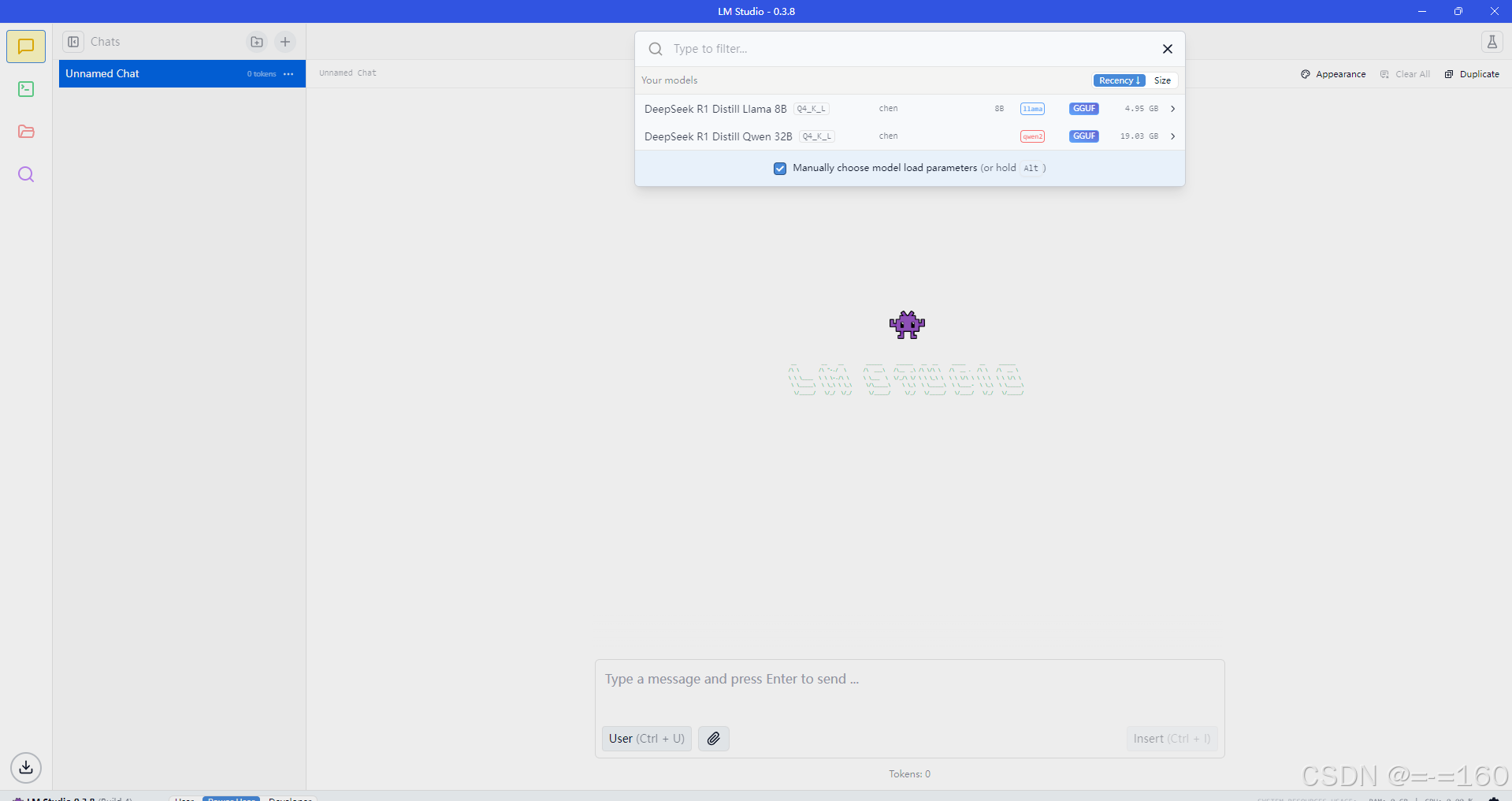
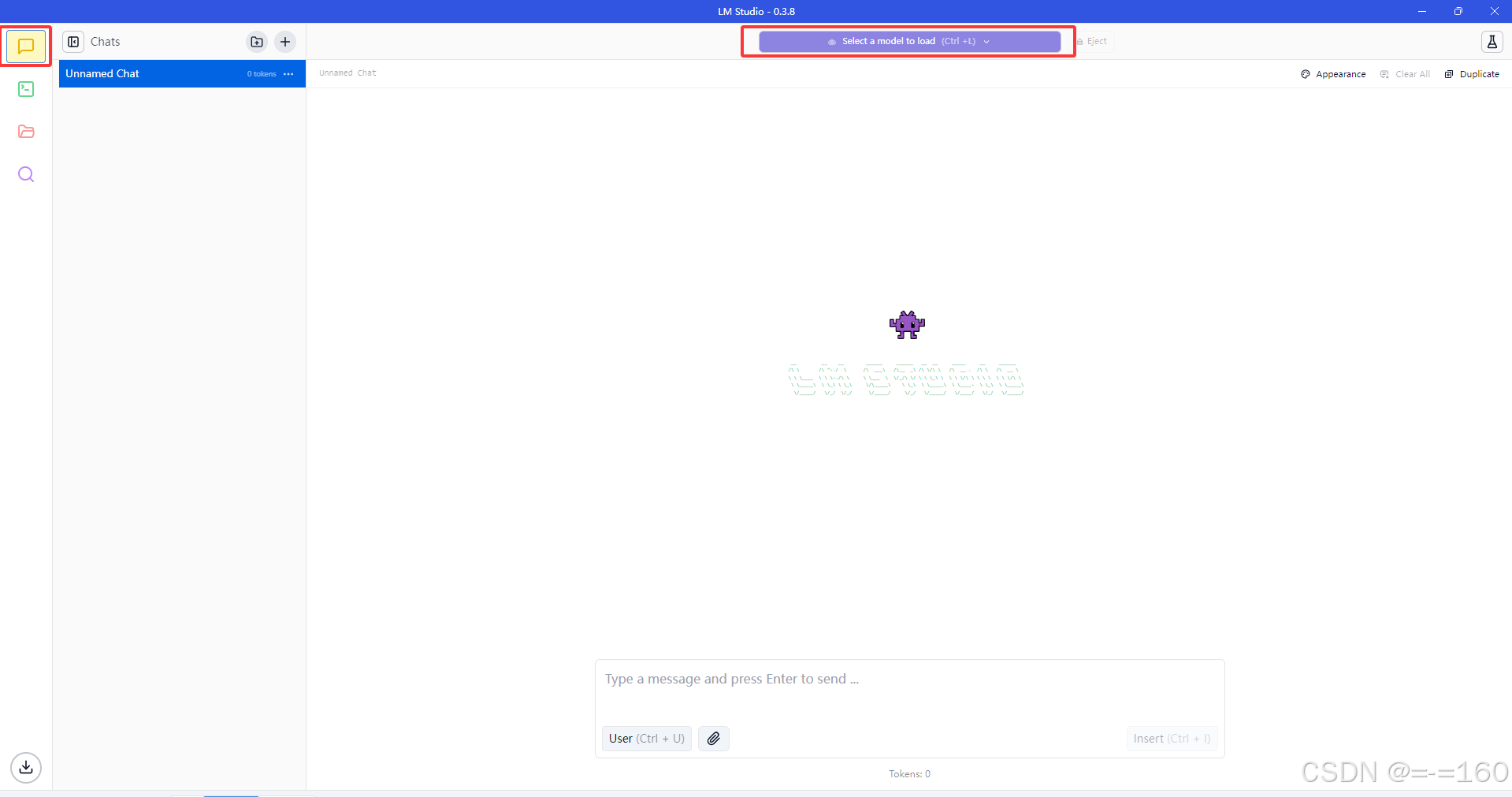
其他
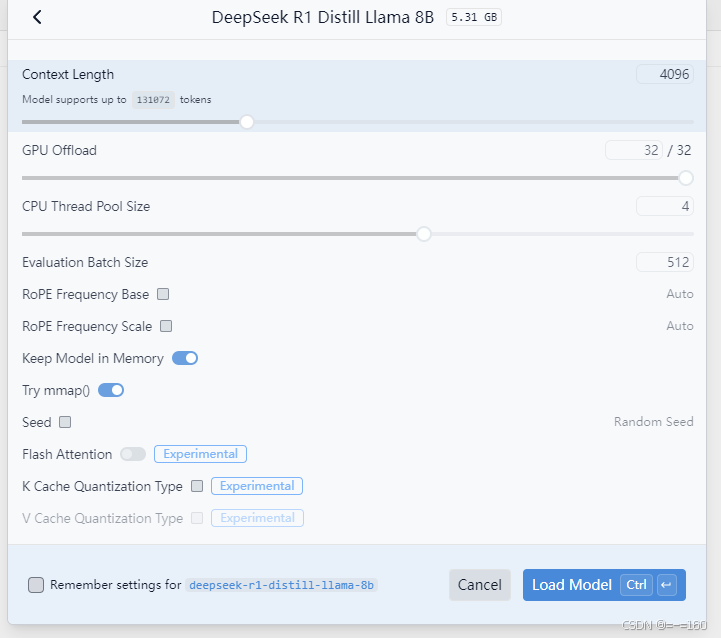
1. 加载模型时的参数设置
如果你内存/显存不够,可以考虑把 Context Length 减小
2. 推理能力据说 32BQ4 比官方的模型差10%
参考资料
b站up NathMath
DeepSeek R1 推理模型 完全本地部署 保姆级教程 断网运行 无惧隐私威胁 大语言模型推理时调参 CPU GPU 混合推理 32B 轻松本地部署哔哩哔哩bilibili
DeepSeek R1 推理模型 一键包【答疑2】完全本地部署 保姆级教程 断网运行 无惧隐私威胁 深度求索 32B 模型3050显卡实测跑通!哔哩哔哩bilibili

















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









