







Hive概述
对数据进行统计分析,SOL是目前最为方便的编程工具,但是MapReduce支持程序开发 (Java、Python等)但不支持SQL开发。
Hive是一款分布式SQL计算的工具,其主要功能是将SQL语句翻译成MapReduce程序运行。
为什么使用Hive
使用HadoopMapReduce直接处理数据所面临的问题。
人员学习成本太高需要掌握java、Python等编程语言,MapReduce实现复杂查询逻辑开发难度太大。
使用Hive处理数据的好处
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
底层执行MapReduce,可以完成分布式海量数据的SQL处理 。
Hive的组件
架构图如下

- 元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。- Hive提供了Metastore 服务进程提供元数据管理功能
- Driver驱动程序
包括语法解析器、计划编译器、优化器、执行器,负责完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
- 用户接口
包括CLI、JDBC/0DBC、WebGUl其中,CL(command line interface)为shell命令行; Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于IDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
MySQL安装
因为hive的运行需要有一个数据库进行元数据存储,所以需要先安装数据库。
下载地址,下载.tar的,解压就可以用了。

mysql安装
a、上传mysql安装包
b、解压mysql安装包
[root@hadoop1 ~]# tar -zxvf /soft/mysql-5.7.36-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
[root@hadoop1 ~]# cd /usr/local
# 重命名为mysql
[root@hadoop1 local]# mv mysql-5.7.36-linux-glibc2.12-x86_64 mysql
c、配置mysql的环境变量
[root@hadoop1 ~]# vi /etc/profile
# mysql的环境变量
export MYSQL_HOME=/usr/local/mysql
export PATH=$MYSQL_HOME/bin:$PATH
d、生效mysql的环境变量
[root@hadoop1 ~]# source /etc/profile
e、测试(报错将在下一个环节处理)
[root@hadoop1 ~]# mysql
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)创建 mysql 属组、用户、安装目录
# 创建新数组 mysql
[root@hadoop1 ~]# groupadd mysql
# 创建用户 mysql ,指定属组为 mysql,禁止其登录
[root@hadoop1 ~]# useradd -r -g mysql mysql -s /sbin/nologin配置mysql
# 创建数据存储目录
[root@hadoop1 ~]# mkdir /usr/local/mysql/data/
# 创建数据日志目录
[root@hadoop1 ~]# mkdir /usr/local/mysql/log/
# 创建临时文件目录
[root@hadoop1 ~]# mkdir /usr/local/mysql/tmp/
# 创建运行文件目录
[root@hadoop1 ~]# mkdir /usr/local/mysql/run/
# 创建启动错误日志
[root@hadoop1 ~]# touch /usr/local/mysql/log/mysqld_safe_error.log
# 创建默认的错误日志目的地
[root@hadoop1 ~]# touch /usr/local/mysql/log/alert.log
# 创建慢查询日志文件
[root@hadoop1 ~]# touch /usr/local/mysql/log/slow.log
# 创建通用查询日志文件的
[root@hadoop1 ~]# touch /usr/local/mysql/log/general.log编辑my.cnf配置文件,将以下内容写入配置文件 /etc/my.cnf
# mysqld_safe脚本启动时读取的配置
[mysqld_safe]
# 存放 MySQL 后台程序 pid 的文件位置
pid-file=/usr/local/mysql/run/mysqld.pid
# 启动错误日志
log-error=/usr/local/mysql/log/mysqld_safe_error.log
# 本地 mysql 客户端程序的配置块
[mysql]
# 本地 mysql 客户端连接的端口
port=3306
# 本地 mysql 客户端命令行提示信息
prompt=\\u@\\d \\r:\\m:\\s>
# 本地 mysql 客户端字符集
default-character-set=utf8mb4
# 开启命令补全
no-auto-rehash
# 所有mysql客户端程序读取的配置块
[client]
# 连接端口
port=3306
# mysql的主机和客户机在同一host上的时候,使用unix domain socket做为通讯协议的载体文件
socket=/usr/local/mysql/run/mysql.sock
# mysql服务端程序mysqld、mysqld_safe和mysqld_multi的配置文件
[mysqld]
# 进程崩溃时生成core file dump文件,便于程序调试和问题排查
core-file
# 该参数指定了安装 MySQL 的安装路径(mysql安装目录),填写全路径可以解决相对路径所造成的问题。
basedir=/usr/local/mysql
# 该参数指定MySQL的数据文件的存放目录,数据库文件即我们常说的 MySQL data 文件。
datadir=/usr/local/mysql/data
# 临时目录
tmpdir=/usr/local/mysql/tmp
# 用于错误消息的区域设置。默认值是en_US。服务器将参数转换为语言名,并将其与lc_messages_dir的值结合,以生成错误消息文件的位置。
lc_messages=zh_CN
# 错误消息所在的目录。服务器使用该值和lc_messages的值来生成错误消息文件的位置。
lc_messages_dir=/usr/local/mysql/share
# 默认的错误日志目的地。如果目标是控制台,则值为stderr。否则,目标是一个文件,log_error值是文件名。
log-error=/usr/local/mysql/log/alert.log
# 慢查询日志文件名。默认值是host_name-slow.log,但可以通过slow_query_log_file选项更改初始值。
slow_query_log_file=/usr/local/mysql/log/slow.log
# 通用查询日志文件的名称。默认值是host_name.log,但初始值可以通过general_log_file选项更改。
general_log_file=/usr/local/mysql/log/general.log
# mysql的主机和客户机在同一host上的时候,使用unix domain socket做为通讯协议的载体文件
socket=/usr/local/mysql/run/mysql.sock
# 服务端字符集
character-set-server=utf8mb4
# 此变量控制写入错误日志的消息中的时间戳的时区,以及写入文件的一般查询日志和慢查询日志消息中的时间戳的时区。
log_timestamps=SYSTEM
# 操作系统中可用于mysqld的文件描述符的数量。
open_files_limit=61535
# 同时允许的最大客户端连接数。
max_connections=1000
# mysql_stmt_send_long_data() C API函数发送的一个包或任何生成/中间字符串的最大大小,或任何参数的最大大小。默认是64MB。
max_allowed_packet=1G
# 如果设置为0,表名将按指定的方式存储,并且比较区分大小写。如果设置为1,表名将以小写形式存储在磁盘上,比较不区分大小写。如果设置为2,则表名按给定值存储,但以小写进行比较。此选项也适用于数据库名称和表别名。
lower_case_table_names=1
# 慢查询日志是否开启。取值为0(或OFF)表示关闭日志,取值为1(或ON)表示打开日志。默认值取决于是否给出——slow_query_log选项。日志输出的目标由log_output系统变量控制;如果该值为NONE,则即使启用了日志,也不会写入任何日志项。
slow_query_log=1
# validate_password插件的加载方法
plugin-load-add=validate_password.so
# validate-password在服务器启动时使用该选项来控制插件的激活
validate-password=FORCE_PLUS_PERMANENT初始化后需记住localhost@root: 后面的内容,就是本机root用户的初始密码,需要记录下来。
# 将安装目录的所有权授予用户、属组 mysql:mysql
[root@hadoop1 ~]# chown -R mysql:mysql /usr/local/mysql
# 初始化数据库
[root@hadoop1 ~]# cd /usr/local/mysql
[root@hadoop1 mysql]# ./bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/
# 再次将安装目录的所有权授予用户、属组 mysql:mysql
[root@hadoop1 mysql]# chown -R mysql:mysql /usr/local/mysql
# 将安装目录的 rwx 授予其所属用户mysql
[root@hadoop1 mysql]# chmod u+wrx -R /usr/local/mysql如果忘记看了,则查看文件/usr/local/mysql/log/alert.log中

启动mysql服务
# 启动mysql服务
service mysqld start
# 停止mysql服务
service mysqld stop
# 重启mysql服务
service mysqld restart
# 查看mysql服务是否启动
service mysqld status登录mysql
# 登录Mysql
# mysql -h[ip地址] -u[用户名] -p
mysql -uroot -p
# 密码是前面记录的初始密码设置密码
-- 设置密码验证安全级别
set global validate_password_policy=LOW;
-- 设置密码验证最小长度
set global validate_password_length=6;
-- 设置密码为123456(根据自己的想法设置)
alter user root@localhost identified by '123456';Hive的部署
因为hive本身是一个单机的工具,所以只要在一台机器上部署就行了。
1.配置hadoop,让hive代理hadoop,打开hadoop/etc/hadoop/core-site.xml。配置完成后通过scp命令分发给另外两台机器。
#在<configuration></configuration>中加上以下代码
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>2.下载并解压Hive
下载连接,apache-hive-3.1.3-bin.tar.gz
下载完成后上传到Linux服务器中,并用tar -zxvf命令解压
tar -zxvf apache-hive-3.1.3-bin.tar.gz
#改名为hive
mv apache-hive-3.1.3-bin hive3.下载mysql驱动包放入hive/lib目录下
下载地址,下载完成后解压,只上传mysql-connector-j-8.3.0.jar即可。

4.在Hive的conf目录内,将hive-env.sh.template文件复制并重命名为hive-env.sh文件,填入以下环境变量内容
#复制
cp hive-env.sh.template hive-env.sh
#加入以下内容
export HADOOP_HOME=/data/root/env/environment/hadoop
export HIVE_CONF_DIR=/data/root/env/environment/hive/conf
export HIVE_AUX_JARS_PATH=/data/root/env/environment/hive/lib5.在Hive的conf目录内,将hive-default.xml.template文件复制并重命名为hive-site.xml文件,然后在<configuration></configuration>中增加连接数据库的配置
cp hive-default.xml.template hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
#javax.jdo.option.ConnectionURL:元数据连接的数据库地址
#javax.jdo.option.ConnectionDriverName:元数据所用数据库的驱动
#javax.jdo.option.ConnectionUserName:元数据登录用户
#javax.jdo.option.ConnectionPassword:元数据登录密码6.进入mysql,创建hive数据库 ,授予权限给用户root
CREATE DATABASE hive;
grant all on *.* to 'root'@'%';7.初始化Hive,在hive/bin目录下执行以下命令
./schematool -initSchema -dbType mysql
报错
解决办法:进入hive-site.xml文件中的第3215行,删除第97列的符号“”

初始化完成可以到mysql中查看hive数据库,发现数据库已经有了74个表

进入/etc/profile文件,添加hive变量

添加完成后使用source /etc/profile生效环境变量
8.启动hvie
在hive目录下创建一个logs文件夹用来保持日志,创建temp文件夹
mkdir logs
mkdir temp替换/hive/conf/hive-site.xml文件夹中的${system:java.io.tmpdir},用temp的绝对路径替换。
两个都要改。

启动元数据管理服务(如果metastore启动报错JAVA拒绝连接是因为没有打开Mysql服务)
#二选一即可
#后台执行方法
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
#前台执行方法
hive --service metastore
通过jps可以查看到Runjar就是metastore进程
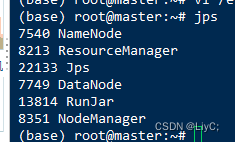
启动hive(启动之前确保hdfs和yarn已经开启,不然会报错)
hive报错

解决办法:退出安全模式
hdfs dfsadmin -safemode leave
查询数据库,如果查询成功说明安装完成

Hive的操作
1.简单的SQL语句,创建、插入、查询
#创建表
CREATE TABLE test(id INT,name STRING);
#插入数据
INSERT INTO test VALUES(1, 'SAM'),(2, 'DIVE'),(3, 'TOM');
#查询内容
SELECT * FROM test;
#带计算的查询
SELECT COUNT(*) FROM test;当我们在执行插入语句或者SQL语句中含有计算的时候,发现该语句执行了一分钟左右才完成,这是因为Hive其实执行的是MapReduce分布式计算。
![]()
当我们创建完表后,它会存入到我们hdfs文件系统中(默认放在/user/hive/warehouse中),可以用命令查看
hdfs dfs -ls /user/hive/warehouse
hdfs dfs -cat /user/hive/warehouse/test/*

HiveServer2服务
HiveServer2是Hive内置的一人ThriftServer服务,提供Thrift端口供其它客户端链接使用hive
#二选一即可
#后台执行方法
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
#前台执行方法
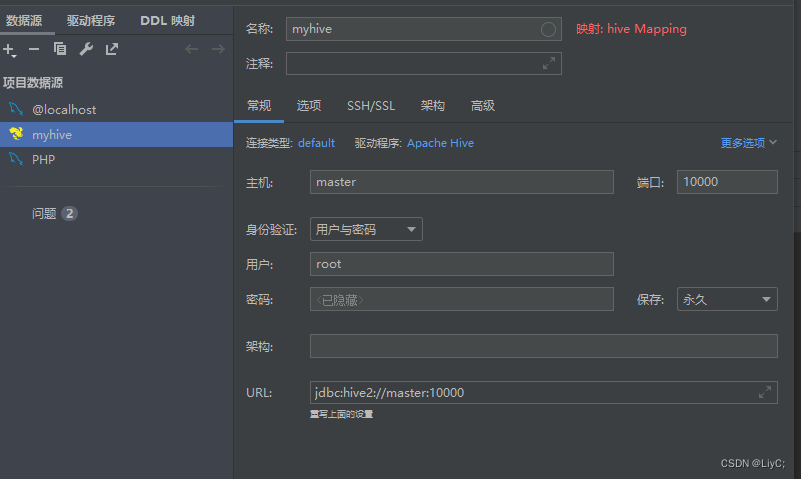
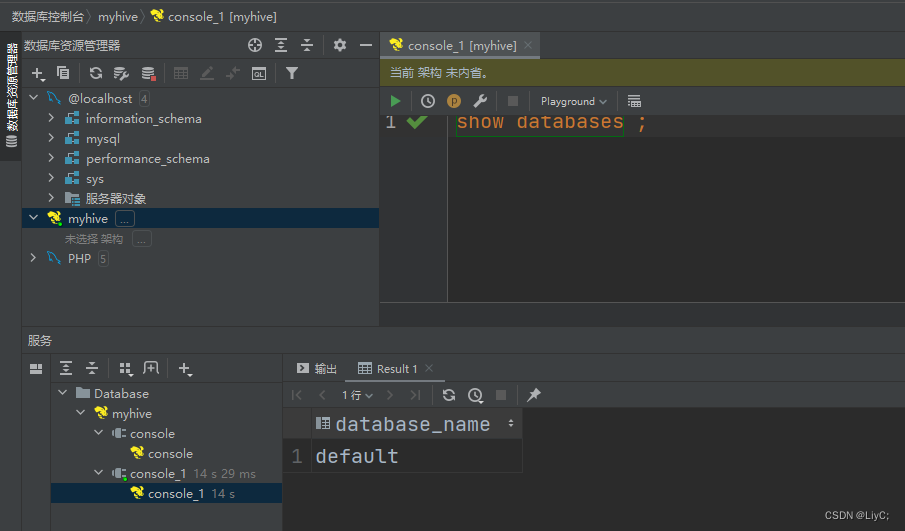
hive --service hiveserver2使用DataGrip连接hive,并查询数据库















 8514
8514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









