









本文主要是根据我自己的学习情况来进行讲解,以一个初学者的角度进行阐释,如果有更深层次的点没有涉及到,还请大家多多包涵。
目录
1.Predictions Across Scales(跨尺度预测)
2.Bounding Box Prediction(边界框预测)
计算机视觉
主流算法
目标检测算法比较流行的算法可以分为两类:
一类是基于Region Proposal(候选区域)的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是two-stage的。需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。
另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个CNN网络直接预测不同目标的类别与位置。
Two-stage(双阶段)
先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。流程概述如下图:
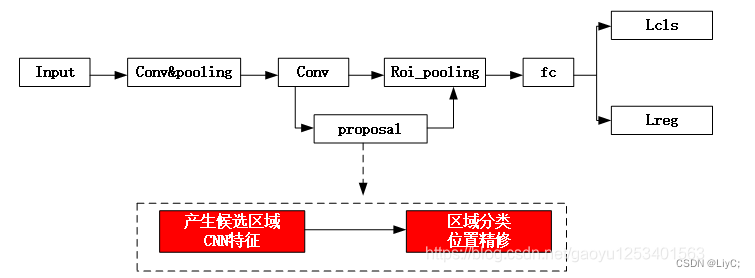
1.首先输入一张图片,接着经过卷积神经网络对图片进行深度特征的提取
2.然后通过RPN(Region Proposal Network)区域生成网络进行候选区域产生的操作
3.对候选区域中的位置进行精确定位和修正
4.使用Roi_pooling层,可以将此层理解为抠图的操作,接着将抠图所得到的候选目标对应到特征图(feature map)上相应的特征区域,然后经过一个全连接层(fc),并得到相应的特征向量
5.最后通过分类和回归这样两个分支,来实现对这个候选目标类别的判定和目标位置的确定(也就是最后矩形框的四个点的坐标,(x,y,w,h):(x,y)为左上角顶点的坐标,w,h是矩形框的长和宽)。
One-stage(单阶段)
直接回归物体的类别概率和位置坐标值(无region proposal),但准确度低,速度相遇two-stage快。流程概述如下图:
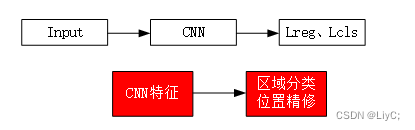
直接通过主干网络给出类别和位置信息,没有使用RPN网路。这样的算法速度更快,但是精度相对Two-stage目标检测网络了略低。
补充
因为刚开始讲YOLO系列,所以涉及到的知识点和要补充的有点多,还请耐心观看。如果已经有一定基础,或者补充的内容都已经提前知道了,可以直接跳过这部分。在后续讲述到的YOLO版本中,有涉及到的一些概念也会放在这个部分进行补充。
CNN(卷积神经网络)
卷积操作
在卷积神经网络中,卷积操作是指将一个可移动的小窗口与图像进行逐元素相乘然后相加的操作。这个小窗口其实是一组固定的权重,它可以被看作是一个特定的滤波器(filter)或卷积核。
这张图中蓝色的框就是指一个数据窗口,红色框为卷积核(滤波器),最后得到的绿色方形就是卷积的结果(数据窗口中的数据与卷积核逐个元素相乘再求和)
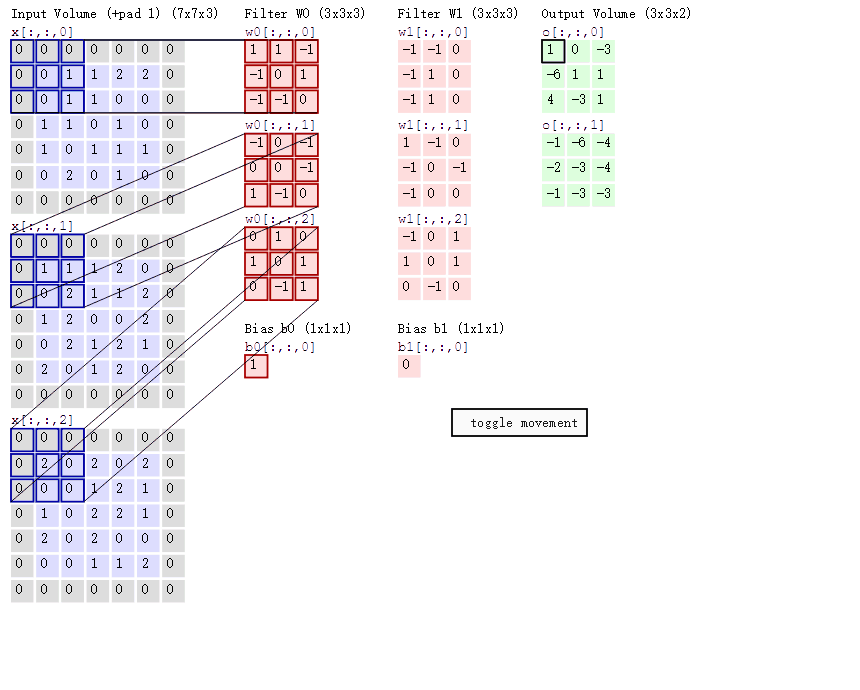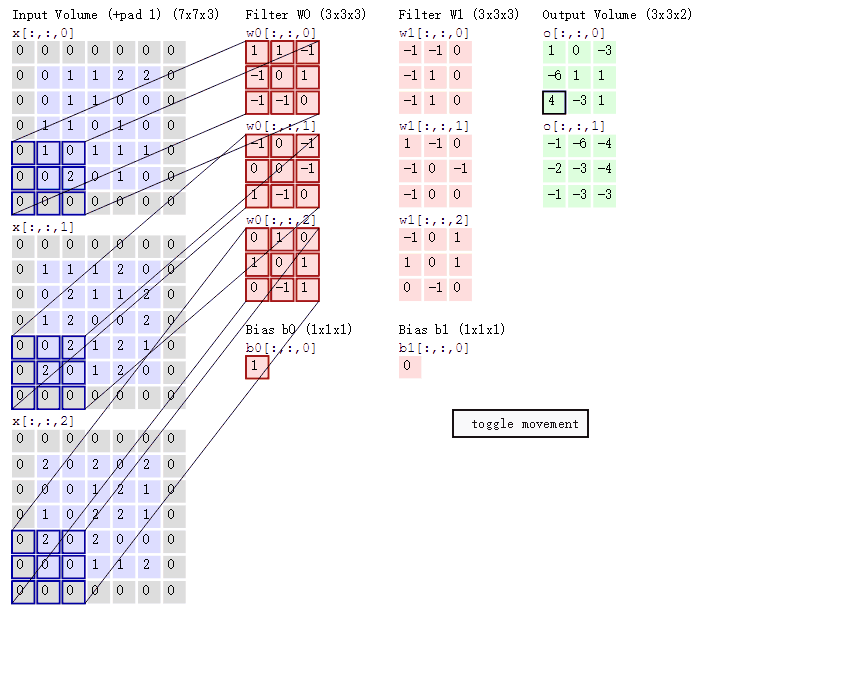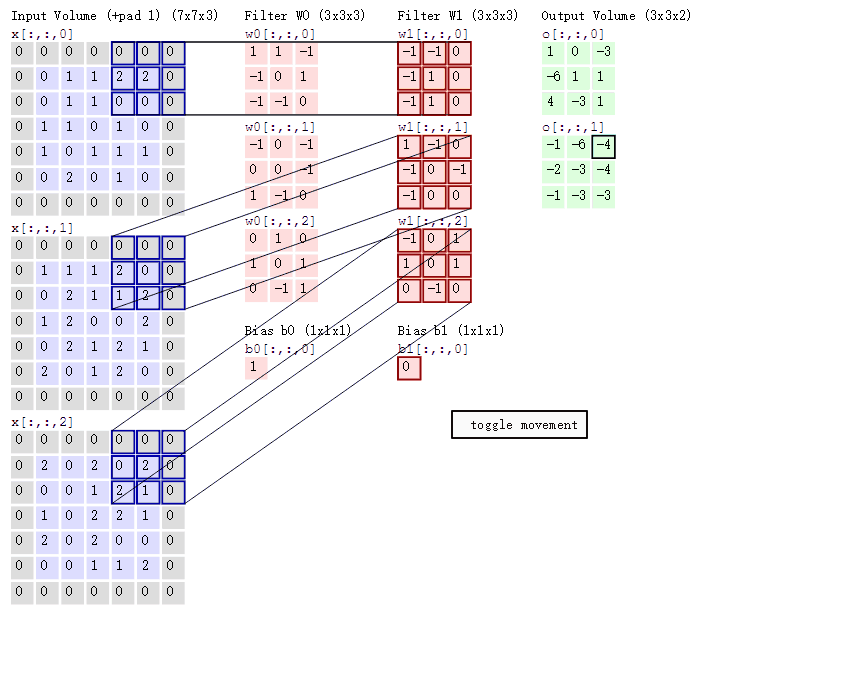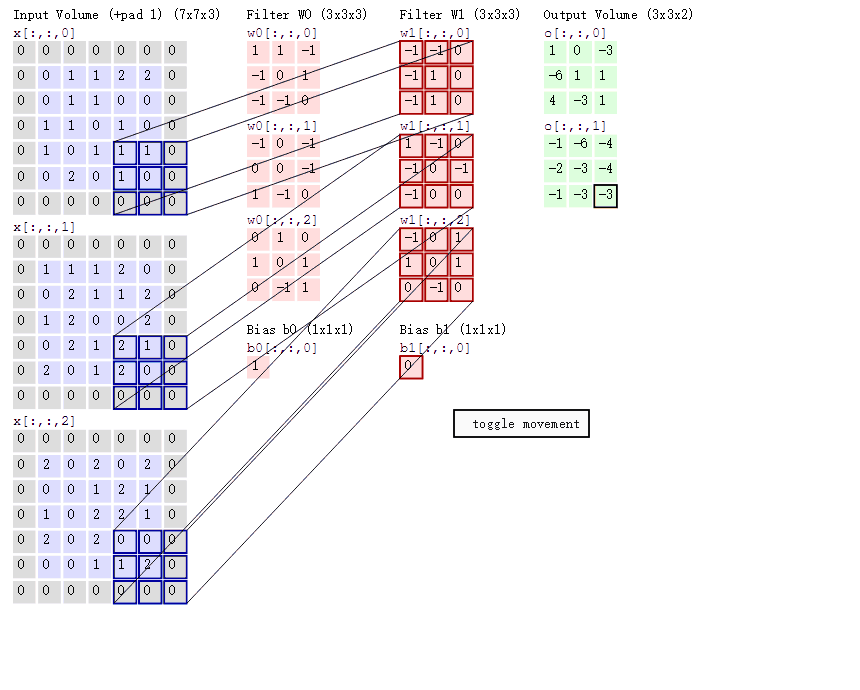
卷积神经网络的构造
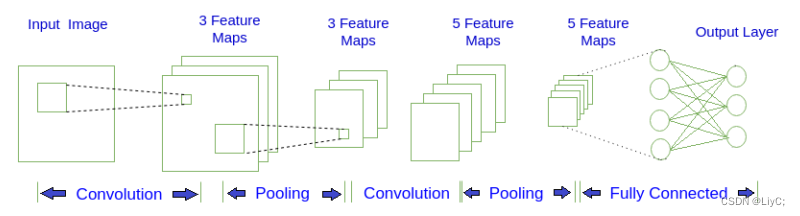
上面是一个简单的 CNN 结构图, 第一层输入图片, 进行卷积(Convolution)操作, 得到第二层深度为 3 的特征图(Feature Map). 对第二层的特征图进行池化(Pooling)操作, 得到第三层深度为 3 的特征图. 重复上述操作得到第五层深度为 5 的特征图, 最后将这 5 个特征图, 也就是 5 个矩阵, 按行展开连接成向量, 传入全连接(Fully Connected)层, 全连接层就是一个 BP 神经网络. 图中的每个特征图都可以看成是排列成矩阵形式的神经元, 与 BP神经网络中的神经元大同小异.
边界框(bounding box)
在检测任务中,我们需要同时预测物体的类别和位置,因此需要引入一些跟位置相关的概念。通常使用边界框(bounding box,bbox)来表示物体的位置,边界框是正好能包含物体的矩形框。
以coco边框坐标编码为例其四个参数定义了它在图像中的位置:
- (x, y):边界框左上角的坐标(通常是相对于图像左上角的像素位置)。
- width:边界框的宽度(以像素为单位)。
- height:边界框的高度(以像素为单位)。

上图例子就是[98, 345, 322, 117]
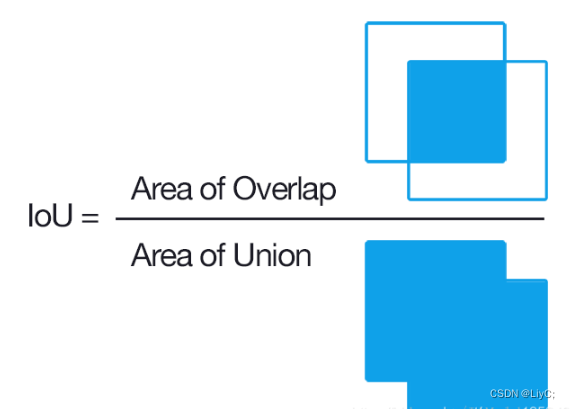
IOU(Intersection over Union)
IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。计算IOU需要两个数据:
- ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围)
- 我们的算法得出的结果范围。
如下图所示。绿色标线是人为标记的正确结果(ground-truth),红色标线是算法预测的结果(predicted)。

IOU的计算如下图
置信度
在YOLO中,置信度是一个介于0和1之间的数值,表示模型对检测到的目标的确信程度。如果置信度接近1,那么模型相信该框中包含了目标对象。如果置信度接近0,模型认为该框中可能没有目标。所以,置信度可以看作是一个概率值,表示目标的存在概率。计算公式如下:
置信度 :pr(object)* IOU(true,pref)
- Pr(Object) 是边界框内存在对象的概率。如果边界框内有对象,则Pr(Object)=1;如果没有对象,则Pr(Object)=0。
- IOU是真实框(ground truth)与预测框(predicted box)的交并比,即预测框和真实框面积的交集与并集的比值。
NMS(非极大值抑制)
这篇文章讲得很易懂,NMS——非极大值抑制_shuzfan-百度飞桨星河社区 (csdn.net),详解在YOLO-V1的预测部分也提到。
FPN(特征金字塔)
我们输入一张图片,我们可以获得多张不同尺度的图像,我们将这些不同尺度的图像的4个顶点连接起来,就可以构造出一个类似真实金字塔的一个图像金字塔。通过这个操作,我们可以为2维图像增加一个尺度维度(或者说是深度),这样我们可以从中获得更多的有用信息。整个过程类似于人眼看一个目标由远及近的过程(近大远小原理)。
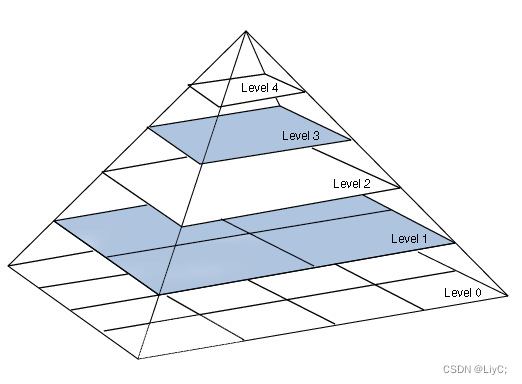

根据图片大小不同,能够显示的细节不同,依次重上往下,我们会在第1层输出简单的目标,第2层输出较复杂的目标,第3层输出复杂的目标,每往下一程可以输出更复杂的目标。
BEC(二元交叉熵函数)
BEC函数定义如下:
BCE(y, y')= -(y*log(y')+(1 -y)*log(1 -y'))
其中,y是真实的标签值(0或1),y是模型预测的概率值(取值范0到1),当y=1时,BCE函数的计算公式为:BCE(1,y')= -log(y'),当y=0时,BCE函数的计算公式为:BCE(0,y')= -log(1-y')
YOLO-V1
模型思想
YOLO 的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框) 的位置及其所属的类别。
具体过程如下:
YOLOv1采用的是“分而治之”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。而RCNN是通过一个RPN来获得目标的感兴趣区域,这种方法精度高,但是需要额外再训练一个RPN网络,这无疑增加了训练的负担。
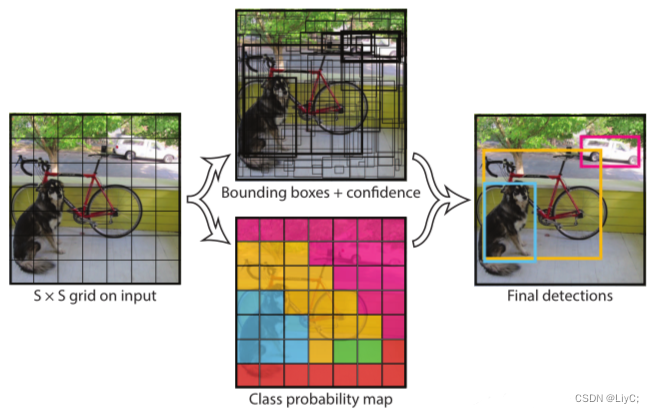
- 将一幅图像分成 7×7个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个object。
- 每个网格要预测 2个bounding box,每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值。这两个框的大小宽高都不确定,可能很大,很宽,也可能很小,很窄。只要这个bounding box的中心点落在这个grid里面就说明这个bounding box是由这个grid所预测的。
- 每个网格还要预测一个类别信息,记为 20 个类。(YOLO-V1使用的训练集有20个类)
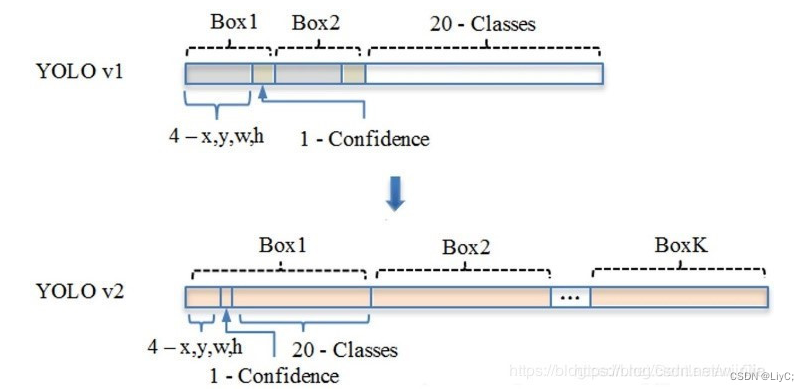
- 总的来说,7×7 个网格,每个网格要预测 2个bounding box ,还要预测 20 个类。网络输出就是一个 7 × 7 × (5×2+20) 的张量。(S x S个网格,每个网格都有B个预测框,每个框又有5个参数,再加上每个网格都有C个预测类)
为什么每个网格固定预测2个bounding box?
在训练的时候会在线地计算每个predictor预测的bounding box和ground truth的IOU,计算出来的IOU大的那个predictor,就会负责预测这个物体,另外一个则不预测。所以对于每个网格来说,不管框 B 的数量是多少,最后只负责预测一个目标。
每个网格预测的2个bounding box是怎么得到的?
YOLO中两个bounding box是人为选定的(2个不同 长宽比)的box,在训练开始时作为超参数输入bounding box的信息,随着训练次数增加,loss降低,bounding box越来越准确。
网络结构
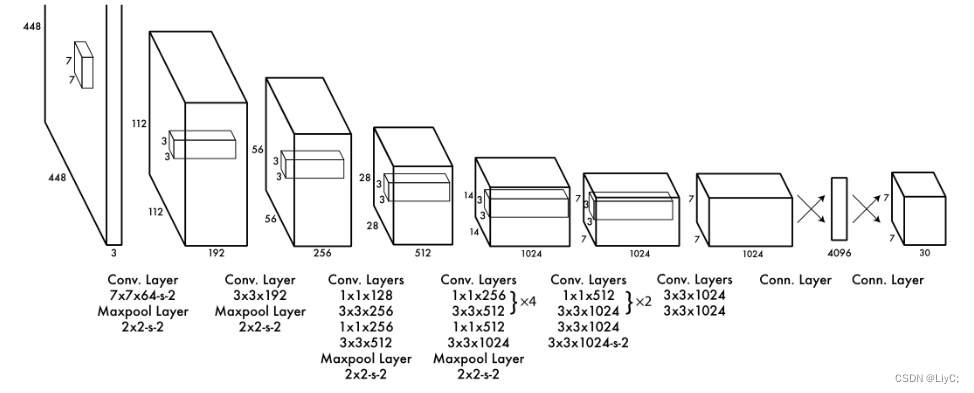
1. YOLO输入图像的尺寸为 448 × 448 ,
2. 经过24个卷积层,用于提取图片的抽象特征。
例如:其中第一个卷积,填充p=3,所以输出(448+2×3-7)/2+2=224.
池化后输出224/2=112
3. 2个全连接的层(FC),用来预测目标的位置和类别概率值。
4. 出的特征图大小为 7 × 7 × 30。
训练与测试
-
第一阶段,预训练分类网络:在ImageNet分类数据集(1000类)上预训练一个分类网络,这个网络是Figure3中的前20个卷积网络+平均池化层+全连接层(此时网络输入是224*224)。
-
第二阶段,训练检测网络:预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。
-
第三阶段,测试图片:输入图片,网络会按照与训练时相同的分割方式将测试图片分割成S x S的形状,因此,划分出来的每个网格预测的class信息和Bounding box预测的confidence信息相乘,就得到了每个Bounding box的Class scores(下面的NMS处理会提到)。

如上图所示,用颜色表示不同的类别,粗细表示置信度就得到了上面的中间图的结果,经过过滤低置信度的框(NMS处理)就得到得了最终的目标检测预测结果。
bounding box序列:
因为一个网格预测两个bounding box,所以最后会有bb1-bb98。对于每个bbox的计算就是这个bounding box的20个类别概率去乘bounding box 的置信度。
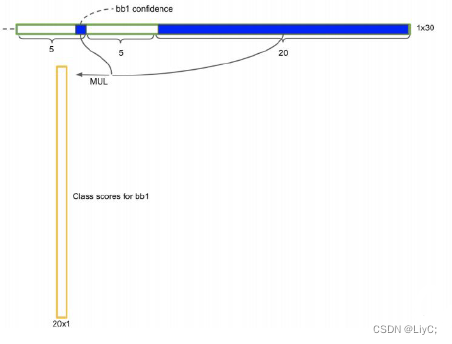
最后会有98个20×1的竖条,每一行代表一个类别。
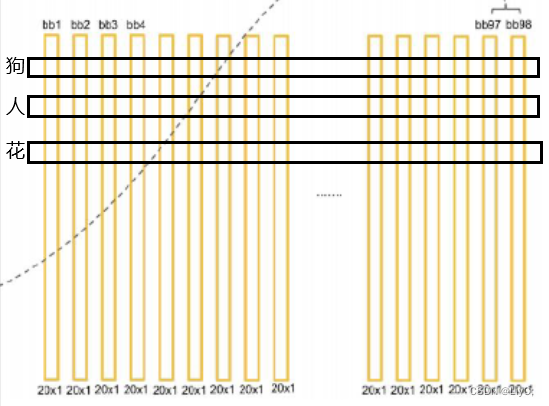
NMS处理过程:
以类别为dog的行为例进行推理

1.先拿出置信度最大的那个框,剩下的每一个都与它做比较,如果两者的IoU大于某个阈值,则认为这俩框重复识别了同一个物体,就将其概率的重置成0(删掉这个框)。
2.最大的那个框和其他的框全部比完一次之后,再从剩下的框找最大的,继续和其他的比。
3.重复2步骤直到全部比完,最后得到一个稀疏矩阵,因为里面有很多地方都被重置成0,拿出来不是0的地方拿出来概率和类别,就得到最后的目标检测结果了。
损失函数
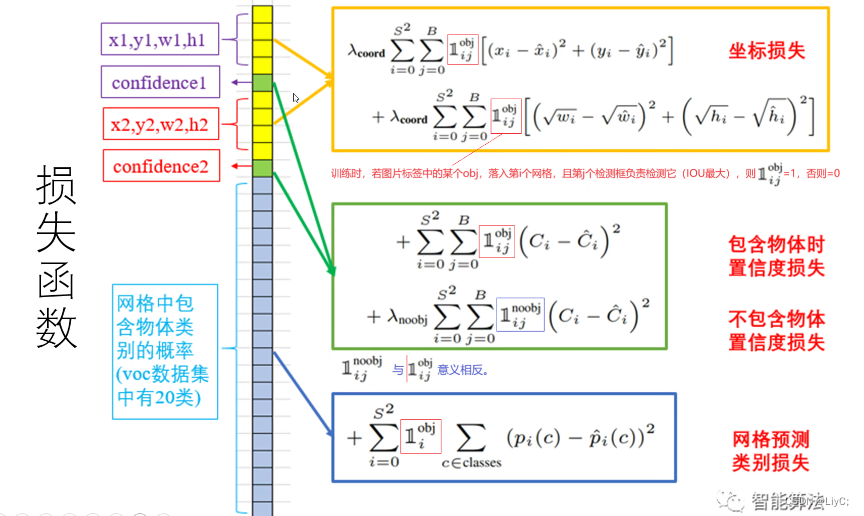
1. 第一行公式表示负责检测物体的bounding box中心点定位误差,要和ground truth尽可能拟合。
第二行表示负责检测物体的bounding box的宽高定位误差,加根号是为了使得对小框的误差更敏感。(大框(大目标)差的这一点也许没啥事儿,而小框(小目标)差的这一点可能就会导致bounding box的方框和目标差了很远。)
 :训练时,若图片标签中的某个obj(例如obj=自行车),落入第i个网络,且第j个检测框负责检测它(IOU最大),则该值=1,否则=0。这样的好处是计算某个obj的坐标损失的时候不需要每个格子都需计算。只计算中心点落入的网格。
:训练时,若图片标签中的某个obj(例如obj=自行车),落入第i个网络,且第j个检测框负责检测它(IOU最大),则该值=1,否则=0。这样的好处是计算某个obj的坐标损失的时候不需要每个格子都需计算。只计算中心点落入的网格。
2.第三行是负责检测物体的bounding box的置信度误差,标签值实际上就是bounding box和ground truth的IOU。预测的置信度应该是越跟IOU越接近越好。
第四行是不负责检测物体的bounding box的置信度误差,就是所有被抛弃的bounding box。让他们预测出来的置信度最好都是0,标签值就是0。
3.第五行是负责检测物体的grid的分类误差
YOLO-V2
模型思想
为了解决YOLOv1在召回率()和定位精度方面的不足,一个网格只预测一个类,对相互靠近的物体(小目标)检测效果不是很好的问题。作者 Joseph Redmon 和 Ali Farhadi 在 YOLOv1 的基础上,进行了大量改进,提出了 YOLOv2 和 YOLO9000。
改进的地方
1.加入Anchor Box机制
什么是Anchor Box?
Faster R-CNN提出anchor box,在RPN中,每个网格处设定了k个具有不同尺寸、不同宽高比的anchor box,在训练阶段,RPN网络会为每一个anchor box学习若干偏移量:中心点的偏移量和宽高的偏移量。这些偏移量可以将预先设定好的anchor box尺寸调整至所检测的目标的真实框的尺寸。
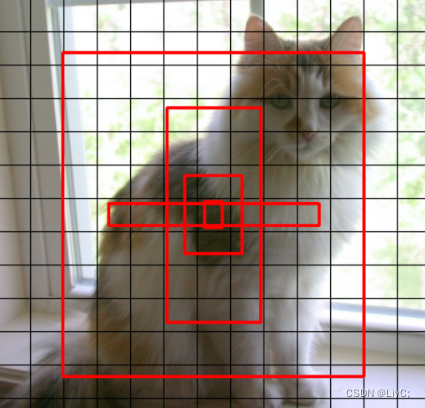
以这张图为例,只标出了最中间网格的先验框,一共有五个且大小不同。 在实际训练过程中,每个网格都会有这五个先验框。
为什么引用Anchor Box?
在YOLOv1中,作者设计了端对端的网路,直接对边界框的位置(x, y, w, h)进行预测。这样做虽然简单,但是由于没有类似R-CNN系列的推荐区域,所以网络在前期训练时非常困难,很难收敛。于是,自YOLOv2开始,引入了 Faster R-CNN 中的 Anchors box 机制,希望通过提前筛选得到的具有代表性先验框Anchors,使得网络在训练时更容易收敛。
如何引用与改进?
在 Faster R-CNN 算法中,是通过预测 bounding box 与 ground truth 的位置偏移值,间接得到bounding box的位置。其公式如下:
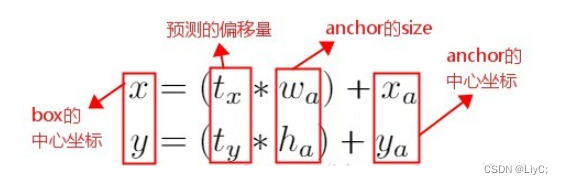
这个公式是无约束的,预测的边界框很容易向任何方向偏移。因此,每个位置预测的边界框可以落在图片任何位置,这会导致模型的不稳定性。
YOLOv2 在此方法上进行了一点改变:预测边界框中心点相对于该网格左上角坐标的相对偏移量,同时为了将bounding box的中心点约束在当前网格中,使用 sigmoid 函数将
归一化处理,将值约束在0-1,这使得模型训练更稳定。
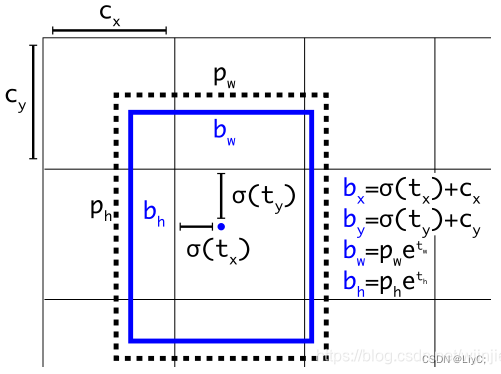
下图为 Anchor box 与 bounding box 转换示意图,其中蓝色的是要预测的bounding box,黑色虚线框是Anchor box。直接理解 anchor box 是先验框,bounding box是预测框就可以了。bounding box 用于预测物体的位置信息,是基于anchor box 偏移得到
2. 使用全卷积网络结构
为什么使用全卷积结构?
Convolutional With Anchor Boxes(带有Anchor Boxes的卷积)。
在YOLOv1中,一个显著的弊病就是网络在最后阶段使用了全连接层。具体来说,YOLOv1先将[B, C, H, W]格式的特征图拉平成[B, N]格式的向量,然后交给全连接层去处理。这一操作通常会破坏特征图的空间结构。为了解决这一问题,作者便将其改成了全卷积结构,并且添加了Faster R-CNN工作所提出的anchor box机制。
做出哪些改进?
- 首先将YOLOv1网络的FC层和最后一个Pooling层去掉,使得最后的卷积层的输出可以有更高的分辨率特征。
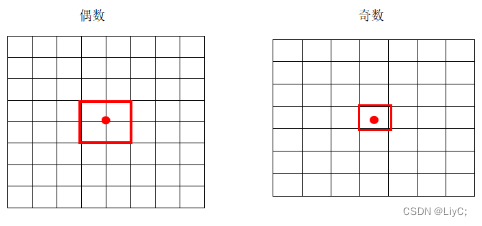
- 然后缩减网络,用416×416大小的输入代替原来的448×448,使得网络输出的特征图有奇数大小的宽和高,进而使得每个特征图在划分单元格的时候只有一个中心单元格(Center Cell)。YOLOv2通过5个Pooling层进行下采样,得到的输出是13×13的像素特征。
- 借鉴Faster R-CNN,YOLOv2通过引入Anchor Boxes,预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。
- 采用Faster R-CNN中的方式,每个Cell预测5个Anchor Box。
YOLOv1每个网格处预测2个边界框,每个边界框都有自己的置信度,但他们却都共享一组类别置信度,这导致了一个网格只能预测一个类。
YOLOv2改为每一个先验框都预测一个边界框置信度和一组类别置信度,即每个边界框都是独立的。因此,改进后的YOLOv1的输出张量大小就从原先的7×7×(5×2+20)变成了现在的13×13×k×(5+20),其中k=每个网格最多可以检测K个Anchor Box(yolov2中k=5)。如下图。
3.k-means聚类选择Anchors
问题
Anchor Boxes的尺寸是手工指定了长宽比和尺寸,相当于一个超参数,这违背了YOLO对于目标检测模型的初衷,因为如果指定了Anchor的大小就没办法适应各种各样的物体了。
解决办法
YOLOv2 使用 K-means 聚类方法得到 Anchor Box 的大小,选择具有代表性的尺寸的Anchor Box进行一开始的初始化。
什么是K-means
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
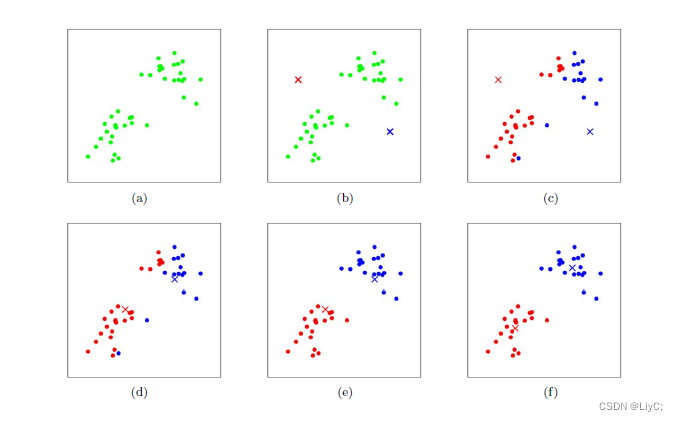
- 上图a表达了初始的数据集,假设k=2。
- 在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心
- 然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别,如图c所示
- 经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如图d所示
- 图e和图f重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图f
计算过程
由上面分析已知,设置先验Anchor Boxes的主要目的是为了使得预测框与真值的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标
box:其他框, centroid:聚类中心框

到聚类中心的距离越小越好,但IOU值是越大越好,所以使用 1 - IOU;这样就保证距离越小,IOU值越大。
如下图,聚类出5个先验框。 其中紫色和灰色也是分别表示两个不同的数据集,可以看出其基本形状是类似的。
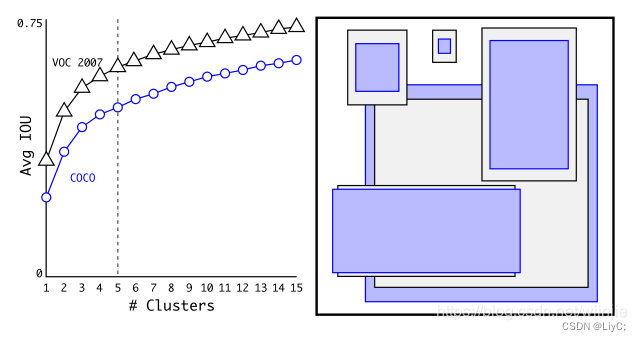
4.添加BN层
Batch Normalization 简称 BN ,意思是批量标准化。BN 对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。基于此,YOLOv2 对所有卷积层上添加BN,这样网络就不需要每层都去学数据的分布,收敛会变得更快。计算过程如下:
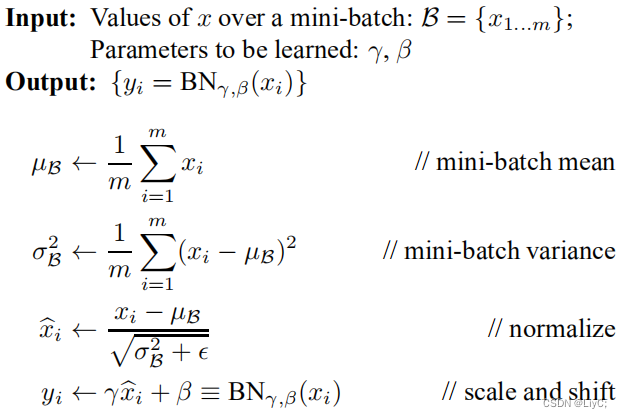
- 对输入值先求平均值,然后求标准差,然后进行归一化(前三行)
- 把归一化得到的值乘以
再加上
5.高分辨率主干网络
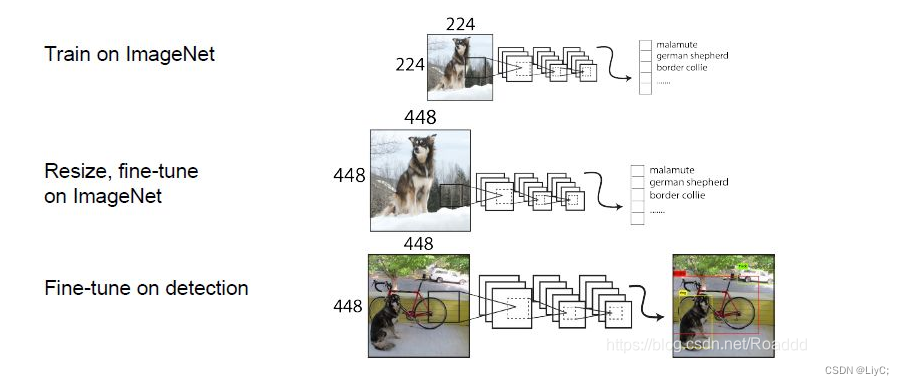
在YOLOv1中,将YOLOv1的Backbone网络放到ImageNet数据集中,使用224×224的图像去做预训练,然后再将训练好的权重作为目标检测任务的Backbone部分的初始化权重。
由于使用224×224的图像做预训练,却用448×448的图像做检测,作者认为图像尺寸的前后差异会造成一些负面影响,原因和改变如下:
- Backbone从较小的224×224的图像所学到的信息远不如448x448的图像丰富,这可能使得Backbone无法学习到更充分的信息。
- 因此,在完成了224x224的图像的预训练后,作者接着又将Backbone网络在448x448的图像上做进一步的“微调”(训练10个epoch)。
- 完成了这两步的预训练后,再将预训练权重用作Backbone网络的初始化权重。
6.Fine-Grained Features
为什么要细粒度特征?
细粒度特征可理解为不同层之间的特征融合。修改后的YOLOv2在13 × 13特征图上进行检测。虽然这对于大型对象来说已经足够了,但是对于较小的对象来说,更细粒度的特性可能会使得检测效果更好。
如何使用?
YOLOv2为网络简单地添加一个直通层( passthrough layer),获取前层26×26分辨率特征,将前层26×26×512的特征图转换为13×13×2048的特征图,并与原最后层特征图进行拼接。
具体操作
- YOLO v2提取Darknet-19最后一个maxpooling层的输入(第13层卷积的输出),得到26×26×512的特征图
- 经过1×1×64的卷积以降低特征图的维度,得到26×26×64的特征图,然后经过pass through层(抽取原特征图每个2x2的局部区域组成新的channel,即原特征图大小降低4倍,channel增加4倍)的处理变成13x13x256的特征图
- 再与13×13×1024大小的特征图连接,变成13×13×1280的特征图,最后在这些特征图上做预测。
特征采样的过程如下图:
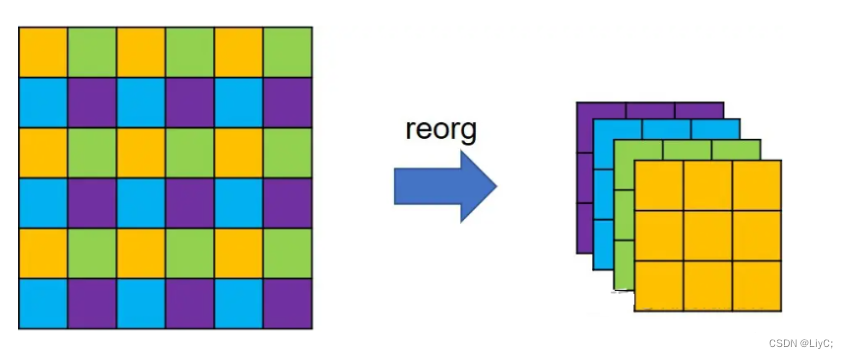
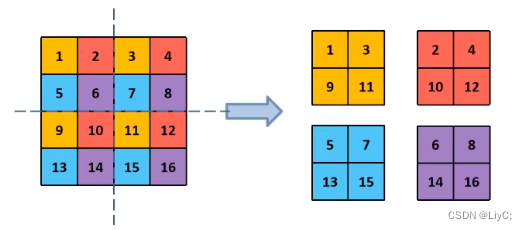
从上图可以看出来,并不是简单的“两刀切4块”,而是在每个2×2的小区域上都选择相同的角块。
整体过程如下图:
基于Darknet-19分类器修改的检测网络结构
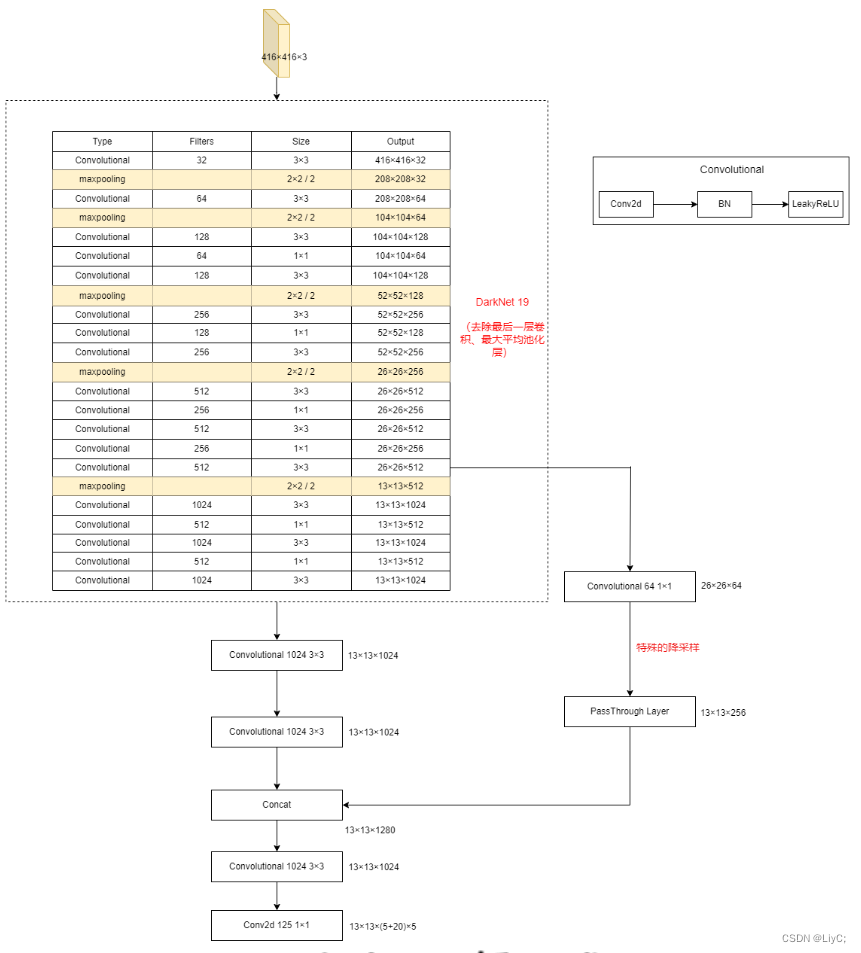
网络结构
Darknet-19
一个新的分类模型作为YOLOv2的基础框架,有19个卷积层和5个maxpooling层。(v1的GooLeNet是4个卷积层和2个全连接层)其整体结构如下:
Darknet-19分类器网络结构
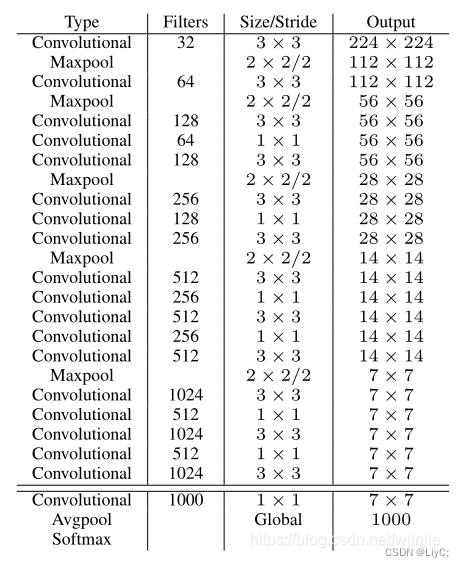
- 与VGG相似,使用了很多3×3卷积核;并且每一次池化后,下一层的卷积核的通道数 = 池化输出的通道 × 2。
- 在每一层卷积后,都增加了批量标准化(Batch Normalization)进行预处理。
- 采用了降维的思想,把1×1的卷积置于3×3之间,用来压缩特征。
- 在网络最后的输出增加了一个global average pooling层。
- 整体上采用了19个卷积层,5个池化层。
训练与测试
涉及到的两个网络结构图片,参考前两个图片(Darknet-19分类器网络结构、基于Darknet-19分类器修改的检测网络结构)。YOLOv2的训练主要包括三个阶段:
- 第一阶段,先在ImageNet分类数据集(1000类)上预训练Darknet-19,此时模型输入为224×224,共训练160个epochs。
- 训练参数:使用初始学习率为0.1随机梯度下降法、4的多项式率衰减法、0.0005的权值衰减法和0.9的动量衰减法
- 第二阶段,将网络的输入调整为448×448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,让模型适应变化的尺度。
- 第三阶段,修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络。
- 移除最后一个卷积层、global avgpooling层和softmax
- 增加3个3x3x1024的卷积层
- 增加passthrough层
- 增加一个1×1个卷积层作为网络输出层。输出的channel数为num_ anchors×(5+num_ calsses),即5×(5+20)
损失函数

可以看到这个损失函数是相当复杂的,我们一步一步分解来看。
首先这里的W和H代表的是特征图网格的高宽,都为13,而A指的是Anchor个数,YOLOv2中是5,各个λ值是各个loss部分的权重系数。
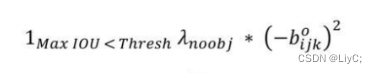
第一行公式,是计算background的置信度误差,这里需要计算各个预测框和所有的ground truth之间的IOU值,并且取最大值记作MaxIOU,如果MaxIOU小于一定的阈值(YOLOv2取了0.6即),那么这个预测框就标记为background,需要计算
。有物体的话,那么
,如果没有物体
。需要将没有物体部分(no object)的部分考虑进来,避免最后模型不能分辨前景和背景。(个人理解为该公式就是寻找纯背景网格)
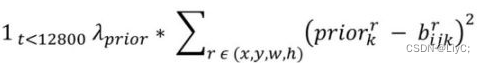
第二个公式,是坐标误差计算,计算Anchor boxes和预测框的坐标误差,这里只在前12800个迭代中计算,用于促进网络学习到anchor的形状。
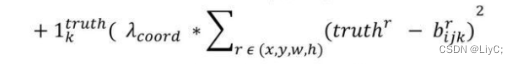
第三个公式,计算坐标损失,对于某个特定的ground truth,首先要计算其中心点落在哪个cell上,然后计算这个cell的5个先验框和grond truth的IOU值,计算IOU值的时候不考虑坐标只考虑形状,所以先将Anchor boxes和ground truth的中心都偏移到同一位置,然后计算出对应的IOU值,IOU值最大的先验框和ground truth匹配,对应的预测框用来预测这个ground truth。
![]()
第四个公式,计算置信度损失,在计算obj置信度时, 增加了一项权重系数,也被称为rescore参数,当其为1时,损失是预测框和ground truth的真实IOU值。而对于没有和ground truth匹配的先验框,除去那些MaxIOU低于阈值的,其它就全部忽略。

第五个公式,计算分类损失和YOLOv1一致。
YOLO-V3
模型思想
作者 Redmon 又在 YOLOv2 的基础上做了一些改进。特征提取部分采用darknet-53网络结构代替原来的darknet-19,利用特征金字塔网络结构实现了多尺度检测,分类方法使用逻辑回归代替了softmax,在兼顾实时性的同时保证了目标检测的准确性。从YOLOv1到YOLOv3,每一代性能的提升都与backbone(骨干网络)的改进密切相关。在YOLOv3中,作者不仅提供了darknet-53,还提供了轻量级的tiny-darknet。如果你想检测精度与速度兼具,可以选择darknet-53作为backbone;如果你希望达到更快的检测速度,精度方面可以妥协,那么tiny-darknet是你很好的选择。
改进的地方
1.Predictions Across Scales(跨尺度预测)
因为翻译不同,跨尺度预测也可以叫多尺度预测,YOLOv3借鉴了FPN(在文章前面的补充部分有解释)的方法,采用多尺度的特征图对不同大小的物体进行检测,以提升小物体的预测能力。
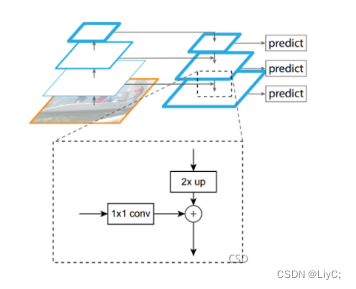
YOLOv3设计了3种不同尺度的网络输出,分别是13X13 (416/32),26X26(416/16) 以及52X52(416/8)(三个不同卷积层提取的特征) ,目的是预测不同尺度的目标。
例如下图,向YOLOv3输入416X416的图像,则会得到13X13、26X26、52X52这3个尺度的特征图。

YOLOv3 选择了三种不同形状的Anchors(一个网格预测三个Anchor box),同时每种Anchors对应到不同尺度的特征图具有不同的尺度,一共9种不同大小的Anchors。使用k-means聚类法来确定边界框预设。任意地选择了9个聚类和3个尺度,然后在各个尺度上均匀地划分得到9个聚类(anchor boxes),并将这些anchor boxes划分到3个尺度特征图上,网格数更多的特征图使用更小的先验框。如下图。

不同尺度特征图的计算如下图,先上流程图,该图是基于讲解的,voc数据集有20个类别,如果是基于coco的数据集就会有80种类别,最后的维度应该为3x(80+5)=255。
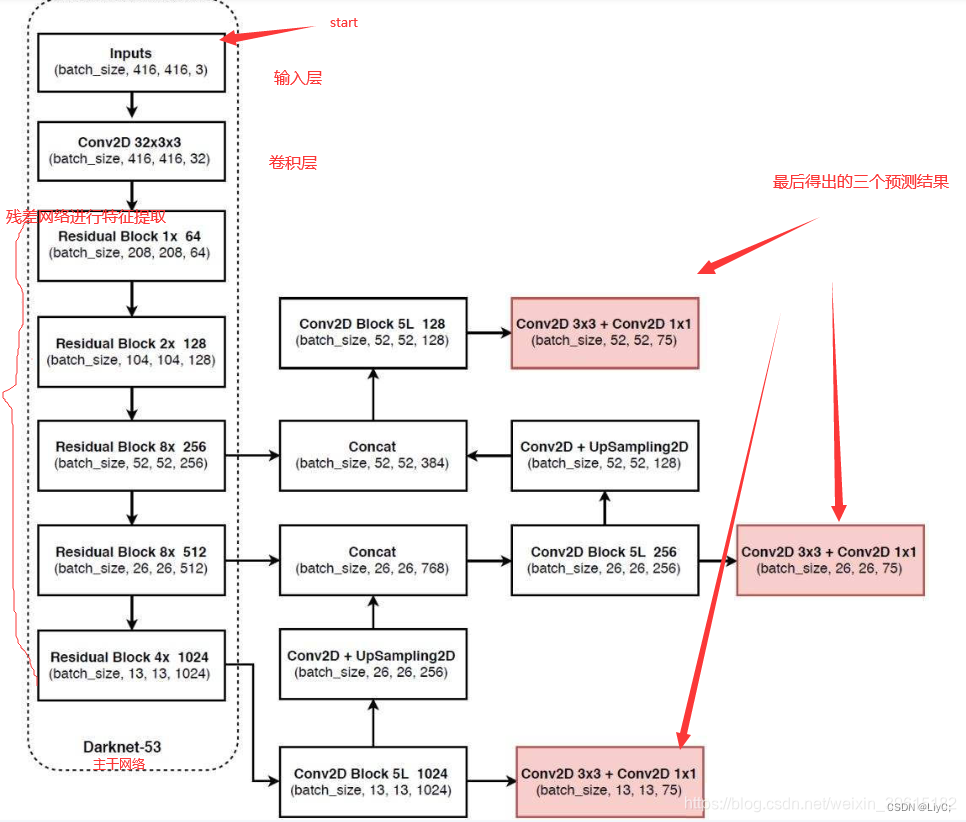
(1)第一种尺度:[13, 13, 75]
对原图下采样32x得到(13 x 13)特征图,添加几个卷积层,最后输出一个 N × N × [3 ∗ (4 + 1 + 20)] 的张量表示预测。
(2)第二种尺度: [26, 26, 75]
对原图下采样16x得到 (26 x 26)特征图,对第一种尺度得到的(13 x 13)特征图进行上采样,得到(26 x 26)特征图。两种计算得到的(26 x 26)特征图通过连接合并在一起。添加几个卷积层,最后输出一个 N × N × [3 ∗ (4 + 1 + 20)] 的张量表示预测。这个张量的大小是尺度一输出张量大小的两倍。
(3)第三种尺度:[52, 52, 75]
对原图下采样8x得到 (52 x 52)特征图,对第二种尺度得到的(26 x 26)特征图进行上采样,得到(52 x 52)特征图。两种方式得到的(52 x 52)的特征图通过连接合并在一起。添加几个卷积层,最后输出一个 N × N × [3 ∗ (4 + 1 + 20)] 的张量表示预测。这个张量的大小是尺度二输出的两倍
合并(加入残差啊思想)的目的?
在每一种维度输出之前还有一个分支就是和下一路进行concat拼接(上一层进行上采样后拼接)。这样加入残差思想,保留各种维度特征(底层像素+高层语义)。三个尺度就可以预测各种不同大小的物体了。
2.Bounding Box Prediction(边界框预测)
与YOLOv2相同之处
使用dimension clusters来找到先验anchor boxes,然后通过anchor boxes来预测边界框。
YOLOv3的改进
在YOLOv3 中,利用逻辑回归来预测每个边界框的客观性分数( object score ),也就是YOLOv1 论文中说的confidence :
● 正样本: 如果当前预测的包围框比之前其他的任何包围框更好的与ground truth对象重合,那它的置信度就是 1。
● 忽略样本: 如果当前预测的包围框不是最好的,但它和 ground truth对象重合了一定的阈值(这里是0.5)以上,神经网络会忽略这个预测。
● 负样本: 若bounding box 没有与任一ground truth对象对应,那它的置信度就是 0
为什么YOLOv3要将正样本confidence score设置为1?
置信度意味着该预测框是或者不是一个真实物体,是一个二分类,所以标签是1、0更加合理。并且在学习小物体时,有很大程度会影响IOU。如果像YOLOv1使用bounding box与ground truth对象的IOU作为confidence,那么confidence score始终很小,无法有效学习,导致检测的Recall不高。
为什么存在忽略样本?
由于YOLOV3采用了多尺度的特征图进行检测,而不同尺度的特征图之间会有重合检测的部分。例如检测一个物体时,在训练时它被分配到的检测框是第一个特征图的第三个bounding box与ground truth的IOU为0.98,此时恰好第二个特征图的第一个bounding box与该ground truth的IOU为0.95,也检测到了该ground truth对象,如果此时给其confidence score强行打0,网络学习的效果会不理想。
3.单标签分类改进为多标签分类
在YOLOv2中,算法认定一个目标只从属于一个类别,根据网络输出类别的得分最大值,将其归为某一类。然而在一些复杂的场景中,单一目标可能从属于多个类别。
比如在一个交通场景中,某目标的种类既属于汽车也属于卡车,如果用softmax进行分类,softmax会假设这个目标只属于一个类别,这个目标只会被认定为汽车或卡车,这种分类方法就称为单标签分类。如果网络输出认定这个目标既是汽车也是卡车,这就被称为多标签分类。
改进方法
1.YOLOv3 使用的是logistic 分类器对每个类别都进行二分类,而不是之前使用的softmax。
2.在YOLOv3 的训练中,便使用了Binary Cross Entropy ( BCE, 二元交叉熵) 来进行类别预测。
网络结构
相比于 YOLOv2 的 骨干网络,YOLOv3 进行了较大的网络结构改进。借助残差网络的思想,YOLOv3 将原来的 darknet-19 改进为darknet-53。论文中给出的整体结构如下:
darknet-53
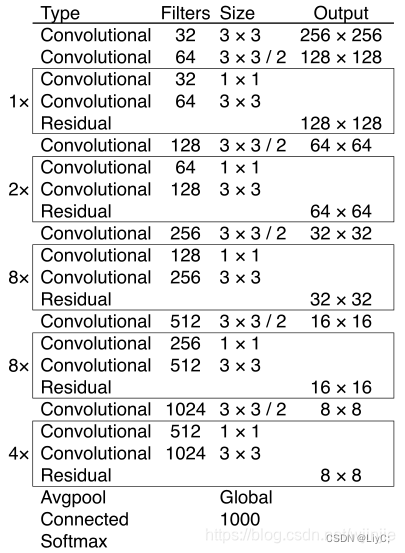
Darknet-53主要由1×1和3×3的卷积层组成(图中画框的部分),每个卷积层之后包含一个批量归一化层和一个Leaky ReLU 加入这两个部分的目的是为了防止过拟合。(YOLOv2中有提到),卷积层、批量归一化层以及Leaky ReLU共同组成Darknet-53中的基本卷积单元DBL。因为在Darknet-53中共包含53个这样的DBL(52个卷积层+1个全连接层),所以称其为Darknet-53。
Yolo_v3使用了darknet-53的前面的52层(没有全连接层),yolo_v3这个网络是一个全卷积网络。
与yolov2对比
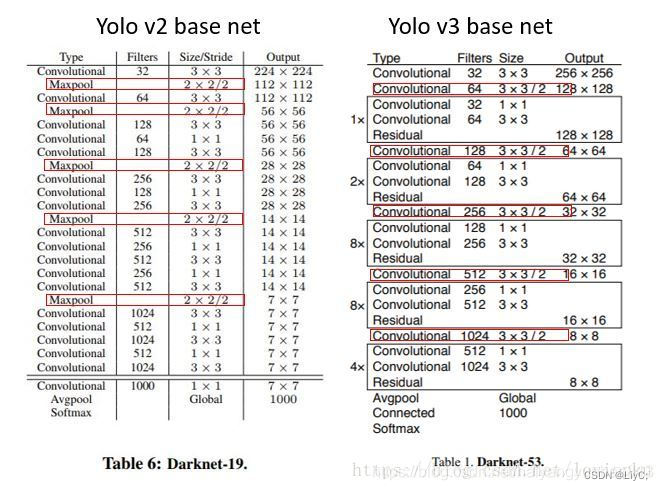
- 为了降低池化带来的梯度负面效果,没有采用最大池化层,转而采用步长为2的卷积层进行下采样。
- 引入了残差网络(Residual)的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
- 将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。
借助两张图片,帮助大家再进一步详细了解YOLOv3的整体网格结构(这两张图说的都是YOLOv3的整体结构,只是表达方式不同,能看明白其中一个就好)
图一
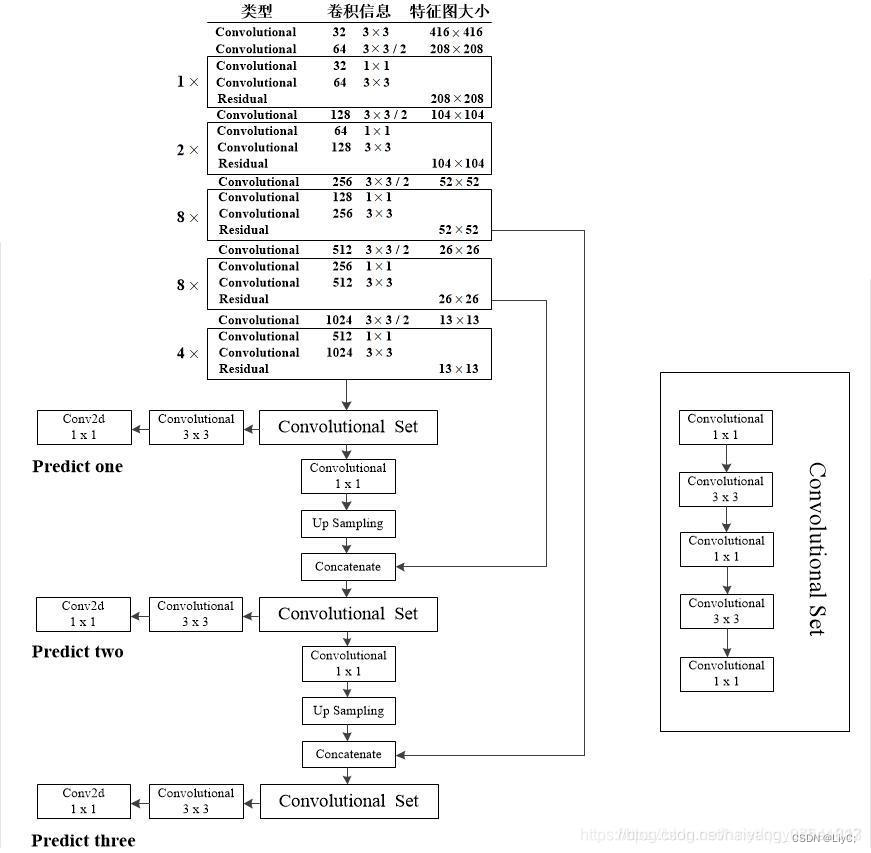
图二

- DBL: 一个卷积层、一个批量归一化层和一个Leaky ReLU组成的基本卷积单元。
- res unit: 输入通过两个DBL后,再与原输入进行add;这是一种常规的残差单元。残差单元的目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
- resn: 其中的n表示n个res unit;所以 resn = Zero Padding + DBL + n × res unit 。
- concat: 将darknet-53的中间层和后面的某一层的上采样进行张量拼接,达到多尺度特征融合的目的。这与残差层的add操作是不一样的,拼接会扩充张量的维度,而add直接相加不会导致张量维度的改变。
- Y1、Y2、Y3: 分别表示YOLOv3三种尺度的输出。
训练与测试
训练
训练过程就是基于训练集让程序自动去描框、计算损失、调整参数,经过一定步数的训练后得到一个较好的模型(参数集)。
预测
yolov3处理图片过程如下
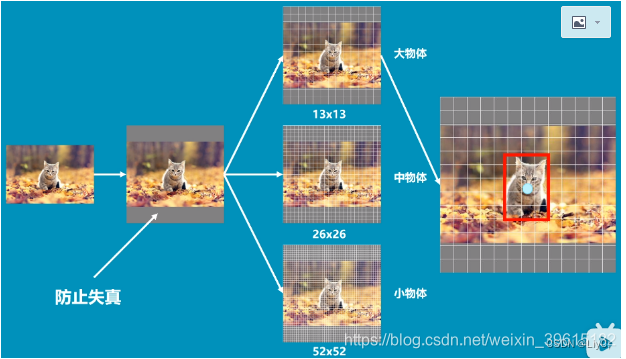
首先一张图片传进yolo,yolo会将其转化为416×416大小的网格,增加灰度条用于防止失真,之后图片会分成三个网格图片(13×13,26×26,52×52)
具体过程
第一步:特征图输出
yolov3提取多特征层进行目标检测,三个特征图分别从主干特征提取网络darknet53的不同位置输出(经过卷积、上采样、拼接等操作)
第二步:预测结果的解码
yolov3的预测原理是分别将整幅图分为13x13、26x26、52x52的网格(一共13×13×3+26×26×3+52×52×3=10647个预测框),每个网络点负责一个区域的检测。解码过程就是计算得出最后显示的边界框的坐标bx,by,以及宽高bw,bh,这样就得出了边界框的位置,计算过程如图。
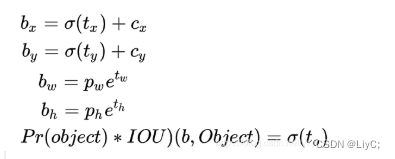
结合下图为例 ,蓝色的是要预测的bounding box,黑色虚线框是Anchor box。预测框即是先验框的微调结果,其结果是更加的贴近真实框
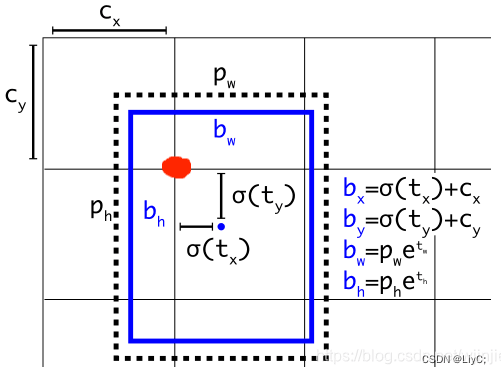
以中心点(蓝点)落在的网格的左上角坐标(红点)进行偏移,所以红点的坐标是(cx,cy)。因为使用 sigmoid 函数,所以便宜范围只能在0-1个网格之间(中心点只能在这个网格内偏移)。bw和bh是根据anchor box的pw和ph来变化的(缩放)。
那么如何去描述他们的损失呢?
1.按照上面同样的方式先用GroundTruth(真实框)和anchorbox(先验框,锚框)借助上面四个公式反向计算出偏移和缩放比,记为dx,dy,dh,dw,这个即标签label(标准)。
2.正向计算输出的BoundingBox(预测框)是tx,ty,th,tw四个值
我们的目标是通过网络不断学习得到的(tx,ty,tw,th)这四个值,然后用这四个值去微调(平移,缩放)anchorbox(先验框,锚框)得到BoundingBox(预测框),使得BoundingBox不断接近GroundTruth(真实框),也就是(tx,ty,tw,th)不断的接近(dx,dy,dh,dw)
第三步:对预测出的边界框得分排序与非极大抑制筛选
使用非极大抑制将最大概率的框筛选出来
整个过程可以理解为:输出三个特征图,共10647个预测框,选择与目标框最接近的预测框进行显示。因为三个特征图的网格尺寸由大到小,能提取到的细节也更多,所以YOLOv3对于小目标检测能力又有所提高。
损失函数
YOLOv3的损失函数如下图
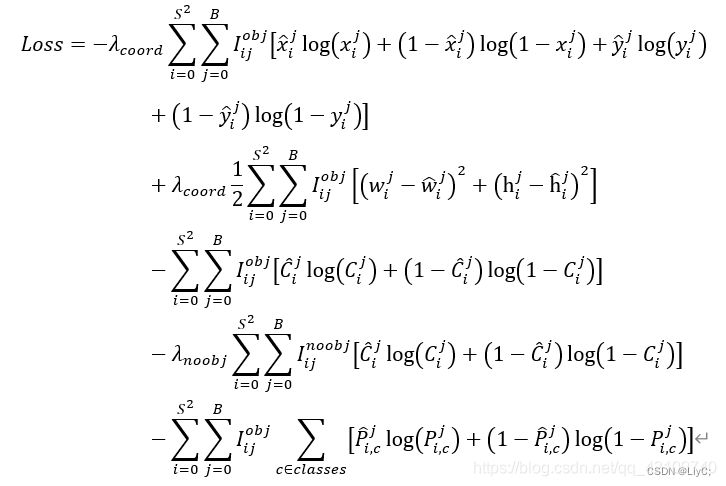
依然是五行公式,我们一行一行来看
第一行公式:计算矩形框中心点误差 ,这是一个交叉熵计算。


第二行公式:预测框宽高误差。
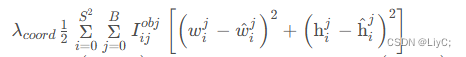

第三四行公式: 预测框置信度损失
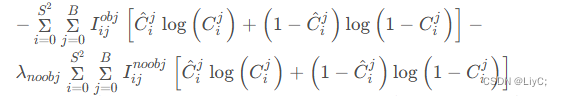

第五行公式:
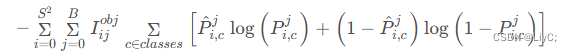
![]()

















 7039
7039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









