







基本查询
基本查询和其它数据库(MySQL等)类似,本文就不再介绍。这里主要说的是Hive数据中一些特别的查询。
RLIKE正则匹配
规则表如下,需要用到的时候查看对应规则即可。
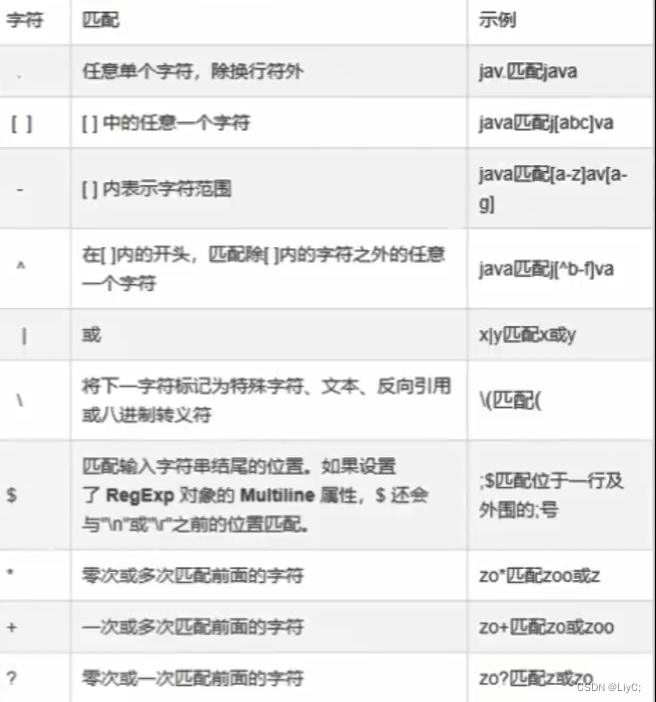
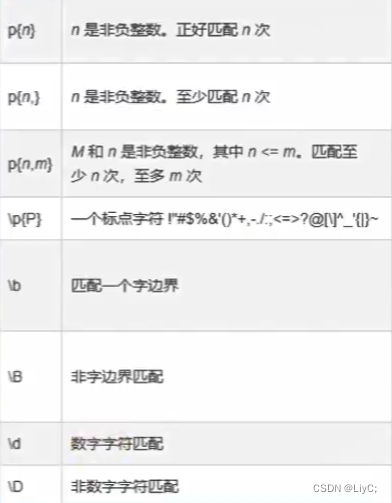
示例:
-- 查询id号中连续出现两次2的学生信息
select * from myhive.scores where s_id RLIKE '.*22.*'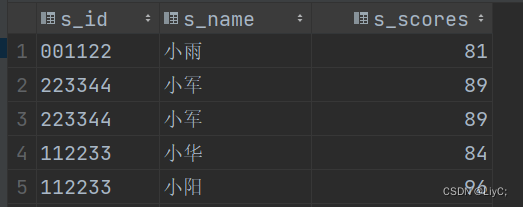
-- 查询id号为X34XXX的学生信息
select * from myhive.scores where s_id RLIKE '.34...'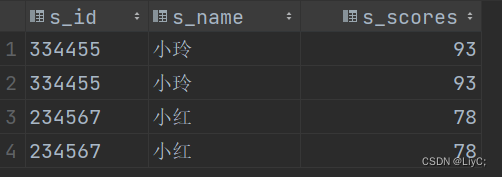
-- 查询学生名字有:美、雷、芳的
select * from myhive.scores where s_name RLIKE '[美雷芳]'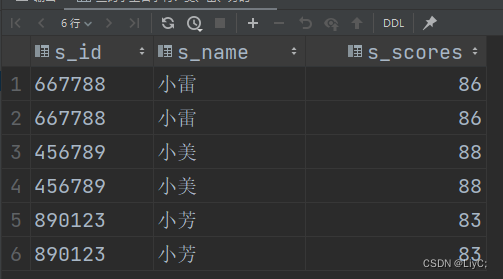
UNION查询
UNION用于将多个SELECT 语的结果组合成单个结果集。每个select 语句返回的列的数量和名称必须相同,否则无法合并,将引发架构错误。

UNION 是自动将结果连接后去重再输出结果的,如果加上ALL就是直接输出带结果。
示例(去重)
select * from myhive.scores where s_name='小芳'
union
select * from myhive.scores where s_name='小刚';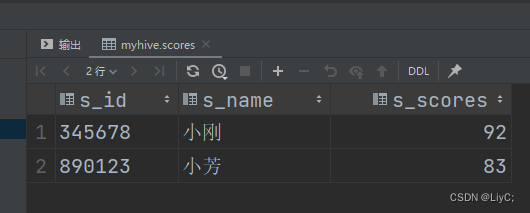
示例(不去重)
select * from myhive.scores where s_name='小芳'
union all
select * from myhive.scores where s_name='小刚';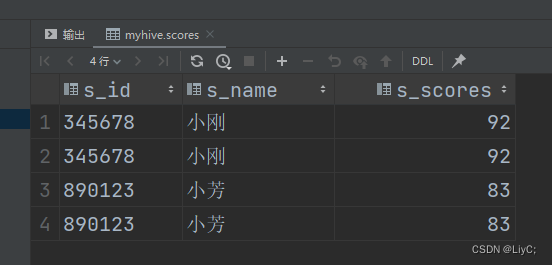
另外UNION也可以用from后,将UNION执行的结果当作一个表来进行查询
select count(*) from (
select * from myhive.scores where s_name='小芳'
union all
select * from myhive.scores where s_name='小刚'
) as u;
数据抽样
基于随机分桶抽样

示例(基于列随机)
-- 基于temperature取模分出8个桶,在这8个桶中随机抽取3个数据出来
select * from weather3 tablesample (bucket 3 out of 8 on temperature);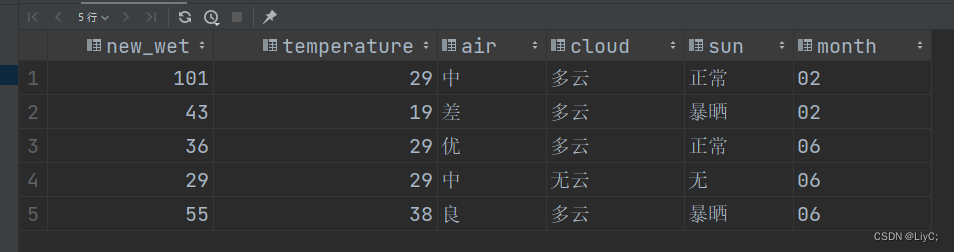
因为是基于列进行哈希运算的分组,每个数据计算出来的值是固定不变的,所以该条SQL无论执行多次结果都是一样的 。因为结构与分桶表相似,所以在对分桶表随机抽样的时候基于列的抽样是有优势的。
示例(基于行随机)
select * from weather3 tablesample (bucket 3 out of 10 on rand());每次运行的结果都不同,这种方式对于非分桶表有优势。
基于数据块抽样

该方法是按照顺序进行抽样,并不是随机抽样 ,所以无论运行多少次结果都是一样的
示例
-- 取四条记录
select * from weather3 tablesample (4 rows);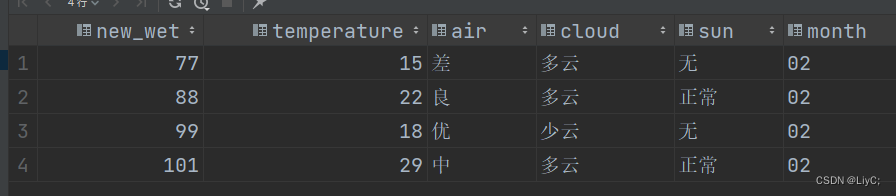
其它的还有下面几个SQL语句,就不展示结果了。
-- 取20%的数据
select * from weather3 tablesample (20 percent);
-- 取1kb的数据
select * from weather3 tablesample (1k);虚拟列

例如
select new_wet,BLOCK__OFFSET__INSIDE__FILE from weather3;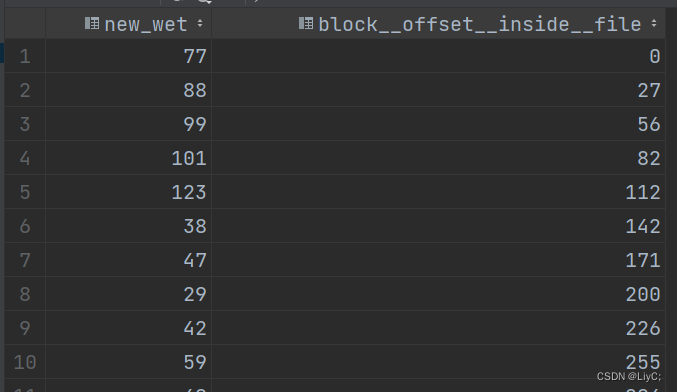















 2432
2432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









