







摘要
线性回归(Linear Regression)是机器学习中最基础的算法,也是理解复杂模型的敲门砖。本文从数学原理、公式推导、Python代码实现到实战优化,手把手带你掌握线性回归的核心要点。
目录
一、什么是线性回归?
线性回归是一种用于建立自变量(特征)与因变量(标签)之间线性关系的监督学习算法。其核心思想是找到一条直线(或超平面),使得预测值与真实值的误差最小化。
应用场景:房价预测、销售额分析、用户行为建模等。
二、数学原理与公式推导
1. 假设函数(Hypothesis Function)
线性回归的预测模型为:
![]()
其中:
-
θ0 是偏置项(截距)
-
θ1,θ2,…,θn 是特征权重
向量化表示:
![]()
(X 为包含偏置项1的特征矩阵,θ 为权重向量)
2. 损失函数(Loss Function)
使用均方误差(MSE)衡量预测值与真实值的差距:
![]()
目标是通过优化 θ 最小化 J(θ)。
3. 参数优化:梯度下降法
梯度下降通过迭代更新参数 θθ,逐步逼近最优解:
![]()
求导后得到更新公式:
![]()
其中 α 为学习率(Learning Rate)。
三、Python代码实战
1. 数据集准备
使用Scikit-learn内置的波士顿房价数据集:
from sklearn.datasets import load_boston
boston = load_boston()
X = boston.data # 特征矩阵(13个特征)
y = boston.target # 房价标签2. 数据预处理
标准化处理(提高模型收敛速度):
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)划分训练集与测试集:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2)3. 模型训练
使用Scikit-learn的LinearRegression:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)4. 模型评估
计算均方误差(MSE)和R²分数:
from sklearn.metrics import mean_squared_error, r2_score
y_pred = model.predict(X_test)
print("MSE:", mean_squared_error(y_test, y_pred))
print("R² Score:", r2_score(y_test, y_pred))5. 可视化结果
绘制真实值与预测值对比图:
import matplotlib.pyplot as plt
plt.scatter(y_test, y_pred)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red') # 绘制对角线
plt.xlabel("True Price")
plt.ylabel("Predicted Price")
plt.title("Boston Housing Price Prediction")
plt.show()四、线性回归的进阶话题
1. 过拟合与正则化
-
岭回归(Ridge Regression):L2正则化
![]()
-
Lasso回归(Lasso Regression):L1正则化
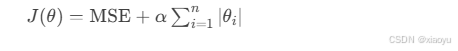
代码实现:
from sklearn.linear_model import Ridge, Lasso
ridge_model = Ridge(alpha=0.5)
ridge_model.fit(X_train, y_train)2. 多项式回归
通过引入特征的高次项拟合非线性关系:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
model.fit(X_poly, y)五、常见问题与解决方案
特征相关性高:使用PCA降维或正则化。
数据存在异常值:采用鲁棒回归(如RANSAC)。
学习率选择:通过网格搜索(GridSearchCV)调参。
六、总结
线性回归虽简单,但包含了机器学习的核心思想:模型假设、损失函数、优化方法。理解它能为后续学习逻辑回归、神经网络打下坚实基础。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









