







数据集要求: 训练集 和 验证集 (要求分好)
图片放置规则 : 一个总文件夹 放类别名称的子文件夹 其中子文件夹 为存放同一类别图片
举个例子 分类动物 则 总文件夹名称为动物 子文件夹为 猫 狗 猪猪 。。。
其中猫的文件夹里面都是猫
给出代码:
import os
import cv2
import numpy as np
import logging
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
# 设置日志
logging.basicConfig(filename='training_log.txt', level=logging.INFO, format='%(asctime)s - %(message)s')
# 读取图像数据和标签
def load_images_from_folder(folder):
images = []
labels = []
label = 0
for subdir in os.listdir(folder):
subpath = os.path.join(folder, subdir)
if os.path.isdir(subpath):
for filename in os.listdir(subpath):
if filename.endswith(".jpg"):
img_path = os.path.join(subpath, filename)
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
img_normalized = cv2.resize(img, (256, 256)) # 归一化图像大小为256x256
images.append(img_normalized.flatten())
labels.append(label)
label += 1
return images, labels
# 主函数
def main():
# train_folder = "YOUR_TRAIN_DATASET_FOLDER_PATH" # 替换为你的训练集文件夹路径
# test_folder = "YOUR_TEST_DATASET_FOLDER_PATH" # 替换为你的测试集文件夹路径
train_folder = "/Users/chen_dongdong/Desktop/宝钢项目/little_work/train" # 替换为你的训练集文件夹路径
test_folder = "/Users/chen_dongdong/Desktop/宝钢项目/little_work/val" # 替换为你的测试集文件夹路径
logging.info("Loading training data from %s", train_folder)
X_train, y_train = load_images_from_folder(train_folder)
logging.info("Loaded %d training samples", len(X_train))
logging.info("Loading test data from %s", test_folder)
X_test, y_test = load_images_from_folder(test_folder)
logging.info("Loaded %d test samples", len(X_test))
logging.info("Training DecisionTreeClassifier...")
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
logging.info("Training completed.")
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
logging.info("Test Accuracy: %f", accuracy)
cm = confusion_matrix(y_test, y_pred)
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
logging.info("Normalized Confusion Matrix:")
for row in cm_normalized:
logging.info(" - ".join(map(lambda x: "{:.2f}".format(x), row)))
# 打印特征重要性
feature_importances = clf.feature_importances_
top_features = np.argsort(feature_importances)[-10:] # 打印最重要的10个特征
logging.info("Top 10 important features:")
for idx in top_features:
logging.info("Feature %d: %f", idx, feature_importances[idx])
if __name__ == "__main__":
main()
使用DecisionTreeClassifier的feature_importances_属性。这个属性会返回一个数组,其中每个值表示相应特征的重要性。值越大,特征越重要。
我们使用的是图像的灰度值作为特征,所以特征的数量会非常大(例如,对于256x256的图像,有65536个特征)。为了简化输出,我们可以只打印出最重要的特征。
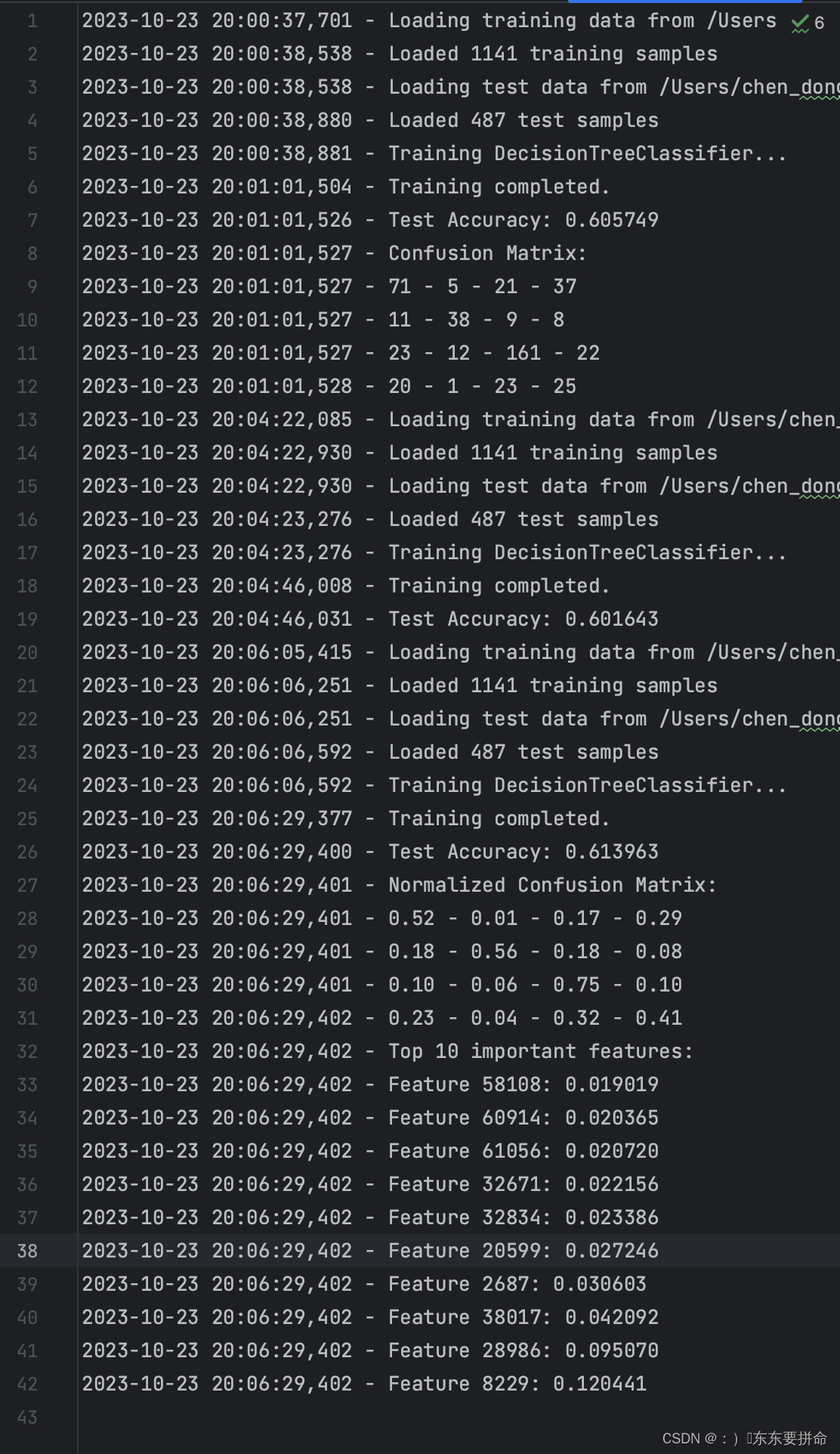
这是我们生成的日志文件
使用sklearn的决策树分类器和opencv来处理图像数据。这个脚本将:
- 从指定的文件夹中读取所有子文件夹中的图像。
- 将图像转换为灰度。
- 将灰度图像转换为一维数组作为特征。
- 使用决策树分类器进行训练。
- 输出模型的准确性。
请确保已经安装了opencv和sklearn库。
pip install opencv-python-headless
pip install scikit-learn
可加镜像
在训练过程中记录关键的信息,例如每次迭代的训练损失、验证损失、准确性等。但由于我们在此使用的是DecisionTreeClassifier,它不像深度学习模型那样进行多次迭代,所以我们只能记录模型的最终准确性和混淆矩阵。
















 2728
2728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











