






显示和修改DataFrame列名
print(df.columns) # 显示df的列名
df.columns = ['data_date','最高温度','最低温度','天气','风速等级'] #修改df列名为指定列名
print(df.columns) 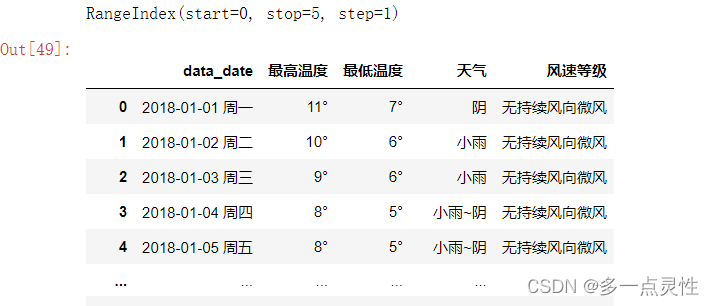
# 删除df中指定列名
data = df.drop(columns=['天气','风速等级'],axis=1,inplace=False)
# axis=1 代表删除的是列,默认为行(0),inplace=False代表不修改df的源数据,True代表修改
拆分列
拆分一列为多列
要将一列数据拆分为两列数据,可以使用pandas的split函数或str.split方法。这将根据指定的分隔符将列中的字符串拆分为多个部分,并创建两个新的列。
data[['data_date','节假日']] = data['date'].str.split(' ',1,expand=True) # 参数“1”表示最多拆分成两列,expend=True用于展示拆分后的结果为两列
print(data)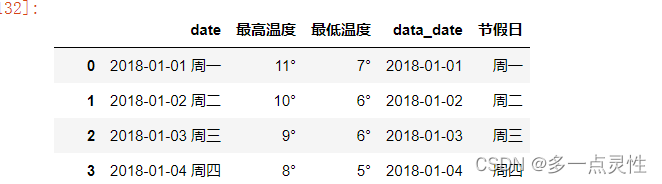
拆分多列为多列
如果有多列需要拆分,可以使用str.split方法配合pandas的apply函数来处理每一列。
apply函数是pandas中的一个重要函数,用于在DataFrame或Series上应用自定义函数或匿名函数。
apply函数的基本语法是:
apply(func, axis=0, args=(), **kwargs)func是要应用的函数,可以是自定义函数或匿名函数。axis指定了函数应用的轴方向,0表示按列应用函数,1表示按行应用函数。args和**kwargs是传递给函数的其他参数。
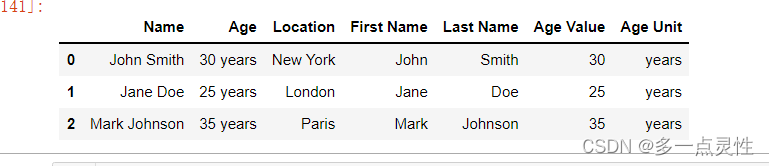
import pandas as pd
# 创建示例DataFrame
data = {'Name': ['John Smith', 'Jane Doe', 'Mark Johnson'],
'Age': ['30 years', '25 years', '35 years'],
'Location': ['New York', 'London', 'Paris']}
df = pd.DataFrame(data)
# 定义拆分函数
def split_column(column):
# 使用str.split()函数拆分列,expand=True表示将拆分结果展开为新的列
# rename()函数用于对拆分后的列进行重命名
return column.str.split(' ', expand=True).rename(columns={0: 'First Name', 1: 'Last Name'})
# 对每一列应用拆分函数,并将拆分结果赋值给新的列
df[['First Name', 'Last Name']] = split_column(df['Name'])
df[['Age Value', 'Age Unit']] = split_column(df['Age'])
# 查看拆分后的DataFrame
print(df)
为同列的每行增加相同字符串
要为每行增加字符,你可以使用 apply 方法来遍历 DataFrame 的每一行,并对每一行进行操作。下面是一个示例代码,演示如何为每行增加字符:
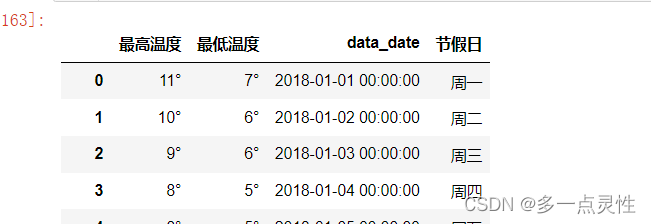
# 为data_date列增加字符串(使用apply函数)
suffix = ' 00:00:00' # 定义要添加的字符
data_new['data_date'] = data_new['data_date'].apply(lambda x: x+suffix) # 使用apply方法为每行增加字符
print(data_new)我们将字符 ' 00:00:00' 添加到 data_date 列的每个元素后面。apply 方法接受一个函数作为参数,我们使用 lambda 函数来将字符添加到每个元素后面。然后,我们将结果赋值回原来的列 data_date。















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









