










哈喽,我是我不是小upper!~
今天和大家聊聊如何结合 CNN(卷积神经网络)与 RNN(循环神经网络)进行时间序列预测。这是深度学习领域里处理时间序列数据的重要方法。
时间序列数据具有两个重要特点:一是数据点在时间维度上呈现局部关联,二是前后数据点存在长期依赖关系。CNN 与 RNN 的结合,恰好能分别处理这两种特性。
CNN 擅长捕捉数据的局部特征。在时间序列预测中,它能分析相邻时间点数据的特征模式,比如提取短周期内数据的变化趋势和波动规律。通过卷积操作,CNN 可以高效地从时间序列中提取出重复出现的局部特征。
RNN 则在处理长期依赖关系上表现出色。它能够记住之前时间步的信息,并将这些信息传递到当前时间步,从而捕捉时间序列在较长时间段内的依赖关系。例如,分析一个月内每日气温变化时,RNN 可以整合多天前的气温信息,更好地预测未来温度。
通过将 CNN 和 RNN 的优势相结合,模型既可以快速提取时间序列的局部特征,又能有效建模其中的长期依赖关系,从而更准确地预测时间序列的未来趋势,在金融市场分析、天气预测、交通流量预估等领域具有广泛应用。
下面我来详细介绍一下~
时间序列预测问题
在时间序列分析领域,预测未来值是一个关键且具有挑战性的任务。给定一个由历史数据点构成的时间序列 ,例如:,
我们的目标是依据这些过去的序列数据,精准预测未来时刻的值,如等。
传统的循环神经网络(RNN),包括长短期记忆网络(LSTM)和门控循环单元(GRU),凭借其独特的结构设计,在学习时间序列的时序依赖关系方面表现出色。RNN 通过隐状态的传递,能够将历史信息保存并传递到后续时间步,从而捕捉数据在时间维度上的前后关联。然而,当面对非常长的序列时,RNN 会遭遇梯度消失的问题。在反向传播过程中,梯度在不断传递的过程中逐渐变小,导致模型难以更新较早期的参数,进而影响对长期依赖关系的建模效果。
卷积神经网络(CNN)则具有不同的优势。CNN 可以并行处理数据,通过卷积核在数据上滑动,高效地捕捉局部模式,例如时间序列中的趋势变化和周期性特征。卷积操作的本质是一种局部加权求和,通过多个不同的卷积核,可以提取出多种不同的局部特征。
因此,将 CNN 与 RNN 相结合,充分发挥二者的优势,可以显著增强模型在时间序列预测任务中的性能。
模型组合流程
完整的模型组合流程如下: 原始序列X首先进入 CNN 模块,经过卷积操作提取局部特征,得到局部特征序列C;接着,C被输入到 RNN 模块中,通过 RNN 的隐状态传递机制,建模序列的长期依赖关系,得到最终的表示;最后,
经过全连接层的线性变换,得到最终的预测值。
卷积特征提取
CNN 在时间序列预测中的核心操作是卷积。对于一维时间序列数据,我们使用一维卷积(1D Conv)。假设输入的时间序列数据维度为,其中N是样本数量,L是序列长度。经过卷积操作后,数据维度变为[N, C, L - K + 1],其中C是输出通道数,K是卷积核大小。卷积操作可以用公式表示为:
其中,是卷积输出结果,
是输入序列第i个样本在位置
的值,
是卷积核的权重。
RNN 时序建模
RNN(以 LSTM 为例)在处理序列数据时,通过细胞状态和门控机制来控制信息的流动。在每个时间步t,LSTM 接收输入和上一个时间步的隐状态
,更新细胞状态
和隐状态
。具体计算公式如下:
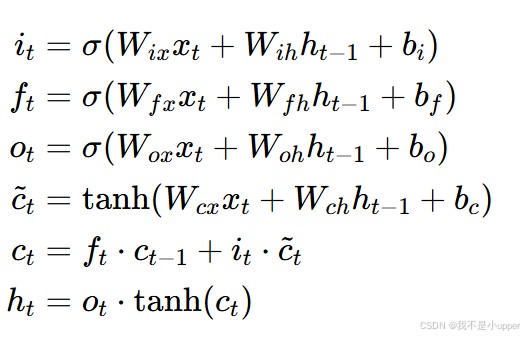
其中,、
、
分别是输入门、遗忘门和输出门,
是候选细胞状态,
是 sigmoid 激活函数,
是双曲正切激活函数。
输出层预测
经过 RNN 得到的最终表示 被输入到全连接层。全连接层通过权重矩阵W和偏置b对
进行线性变换,得到最终的预测值
:
损失函数与优化
通常使用均方误差(MSE)作为损失函数,用于衡量预测值\(\hat{y}\)与真实值y之间的差异。MSE 的计算公式为:
其中,N是样本数量,和
分别是第i个样本的预测值和真实值。
通过反向传播算法计算损失函数对模型参数的梯度,再利用梯度下降法更新模型参数,从而训练整个模型(包括 CNN、RNN 和输出层)。在实际应用中,通常使用 Adam 优化器,它结合了自适应梯度算法(AdaGrad)和均方根传播算法(RMSProp)的优点,能够自动调整学习率,在不同参数上进行自适应的学习率更新。Adam 优化器的更新公式如下:
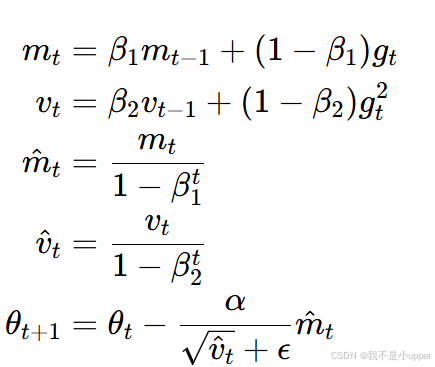
其中,是当前时刻的梯度,
和
分别是梯度的一阶矩和二阶矩的估计,
和
是矩估计的衰减率,
是学习率,
是为了防止分母为零的小常数。
模型优势分析
| 模块 | 优势 |
|---|---|
| CNN | 擅长局部特征提取,能够快速并行计算,通过卷积操作高效捕捉时间序列中的局部模式,如趋势和周期性特征 |
| RNN | 擅长建模序列中长期依赖关系,通过隐状态的传递,保存和利用历史信息 |
| 二者结合 | 充分发挥各自优势,既能捕捉时间序列的局部特征,又能建模全局的长期依赖关系,从而在时间序列预测任务中表现出更强的性能,例如,CNN 能识别季节性 / 周期性特征,而 RNN 建模趋势变化和跨周期影响 |
完整案例
传统 RNN(LSTM/GRU)虽然可以捕捉序列长期依赖,但对短期局部模式(如周期、突变)的敏感度较低;而 1D CNN 能高效提取局部特征,但缺乏跨窗口的记忆能力。接下来,我们通过一个具体案例,进一步理解 CNN 与 RNN 结合进行时间序列预测的过程。
数据集
数据生成
我们首先生成一个包含周期性和随机噪声的时间序列数据:
import numpy as np
np.random.seed(42)
T = 100
t = np.arange(T)
# 周期性 + 随机噪声
data = np.sin(0.1 * t) + 0.5 * np.random.randn(T)这里, 生成了一个周期性的正弦波,频率为
,
添加了均值为0,标准差为 0.5 的高斯噪声。
探索性分析(EDA)
通过傅里叶变换,我们可以分析时间序列的频率成分,找到其主频:
import matplotlib.pyplot as plt
# 简要傅里叶变换
freq = np.fft.fftfreq(T, d=1)
ampl = np.abs(np.fft.fft(data))从傅里叶变换结果可知,正弦波的主频为 0.1,对应完整周期为步;噪声幅度约为0.5,导致曲线局部抖动。这一结果启发我们,后续设计卷积核时,需覆盖至少一个周期内的若干点,以提取完整的周期性模式。
# 图 1: 原始时间序列趋势
plt.figure(figsize=(10,5))
plt.plot(t, data, label='Synthetic Series', color='crimson', linewidth=2)
plt.title('Figure 1: Synthetic Time Series Trend')
plt.xlabel('Time Step')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
plt.show()
完整 PyTorch 实现
参数设置与数据预处理
# 生成数据
TOTAL_LEN = 100
t = np.arange(TOTAL_LEN)
data = np.sin(0.1*t) + 0.5*np.random.randn(TOTAL_LEN)
# 滑动窗口
SEQ_LEN = 10
def create_dataset(series, seq_len):
X, y = [], []
for i in range(len(series)-seq_len):
X.append(series[i:i+seq_len])
y.append(series[i+seq_len])
return np.array(X), np.array(y)
X, y = create_dataset(data, SEQ_LEN)
# 划分训练/测试
TRAIN_RATIO = 0.8
split = int(len(X)*TRAIN_RATIO)
X_train, y_train = X[:split], y[:split]
X_test, y_test = X[split:], y[split:]这里,我们通过滑动窗口的方式,将原始时间序列转换为输入特征X和目标值y,并按照一定比例划分训练集和测试集。
数据集与 DataLoader 详解
import torch
from torch.utils.data import Dataset, DataLoader
class TimeSeriesDataset(Dataset):
def __init__(self, X, y):
# 输入 shape: [N, SEQ_LEN] -> [N, SEQ_LEN, 1]
self.X = torch.tensor(X, dtype=torch.float32).unsqueeze(-1)
self.y = torch.tensor(y, dtype=torch.float32).unsqueeze(-1)
def __len__(self): return self.X.shape[0]
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
# 实例化DataLoader
train_ds = TimeSeriesDataset(X_train, y_train)
test_ds = TimeSeriesDataset(X_test, y_test)
train_loader = DataLoader(train_ds, batch_size=16, shuffle=True)
test_loader = DataLoader(test_ds, batch_size=16)TimeSeriesDataset类继承自Dataset,用于将数据转换为适合 PyTorch 模型输入的格式。DataLoader则负责将数据集划分为批次,batch_size控制每个批次的样本数量,shuffle=True在训练过程中打乱数据顺序,以防止序列相关性对训练产生不良影响。
模型架构与原理解读
import torch.nn as nn
class CNNRNNModel(nn.Module):
def __init__(self):
super().__init__()
# 1D 卷积层:1->16 通道
self.conv = nn.Conv1d(in_channels=1, out_channels=16, kernel_size=3)
self.relu = nn.ReLU()
# LSTM:16 特征 -> 32 隐藏维度
self.lstm = nn.LSTM(input_size=16, hidden_size=32, batch_first=True)
# 全连接:32 -> 1
self.fc = nn.Linear(32, 1)
def forward(self, x):
# x: [B, L, 1] -> [B, C=1, L]
x = x.permute(0,2,1)
# 卷积 + 激活 -> [B,16,L-2]
x = self.relu(self.conv(x))
# 还原维度 -> [B, L-2, 16]
x = x.permute(0,2,1)
# LSTM计算
out, _ = self.lstm(x)
# 取最后时刻输出
last = out[:, -1, :]
return self.fc(last)
model = CNNRNNModel()在CNNRNNModel中,首先通过一维卷积层self.conv提取局部特征,经过 ReLU 激活函数增加非线性;然后将卷积后的结果输入到 LSTM 层self.lstm中建模长期依赖关系;最后,通过全连接层self.fc得到最终的预测值。
训练流程与验证策略
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
epochs = 100
train_losses, val_losses = [], []
# 可选:划出验证集,或用 early stopping
for epoch in range(1, epochs+1):
# 训练模式
model.train()
total_loss = 0
for xb, yb in train_loader:
optimizer.zero_grad()
preds = model(xb)
loss = criterion(preds, yb)
loss.backward()
optimizer.step()
total_loss += loss.item()
train_losses.append(total_loss/len(train_loader))
# 验证模式
model.eval()
val_loss = 0
with torch.no_grad():
for xb, yb in test_loader:
val_loss += criterion(model(xb), yb).item()
val_losses.append(val_loss/len(test_loader))
if epoch % 10 == 0:
print(f"Epoch {epoch}: Train {train_losses[-1]:.4f} | Val {val_losses[-1]:.4f}")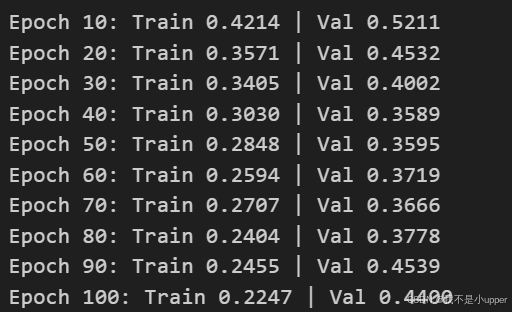
在训练过程中,我们通过model.train()和model.eval()分别设置模型为训练模式和评估模式。在每个训练批次中,首先使用optimizer.zero_grad()清空梯度,然后计算预测值preds和损失loss,通过loss.backward()进行反向传播计算梯度,最后使用optimizer.step()更新模型参数。在验证阶段,使用with torch.no_grad()关闭梯度计算,以节省计算资源。
数据可视化分析
训练 & 验证损失曲线
# 图2
plt.figure(figsize=(10,5))
plt.plot(train_losses, label='Train Loss', linestyle='-', marker='o')
plt.plot(val_losses, label='Val Loss', linestyle='--',marker='x')
plt.title('Figure 2: Loss Curves')
plt.xlabel('Epoch')
plt.ylabel('MSE')
plt.legend()
plt.grid()
plt.show()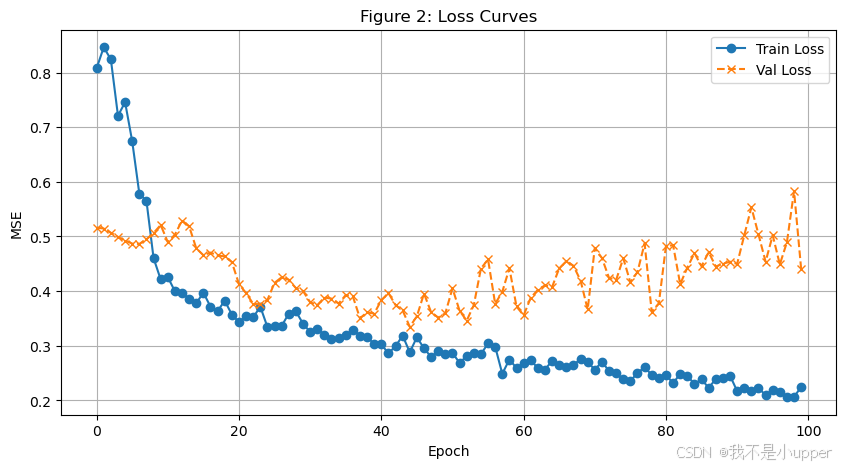
训练损失(Train Loss)呈指数衰减,说明模型在不断学习数据的特征和规律;验证损失(Val Loss)如果出现谷底后上升,提示模型可能出现过拟合现象。理想情况下,二者应趋于平行且收敛。若验证损失在某一epoch后稳定或上升,可以使用提前停止(EarlyStopping)策略,避免模型过拟合。当曲线抖动显著时,可考虑减小学习率或增大batch_size来稳定训练过程。
预测 vs 真实对比
# 图3
true_vals, pred_vals = [], []
model.eval()
with torch.no_grad():
for xb, yb in test_loader:
pred = model(xb).squeeze().cpu().numpy()
true = yb.squeeze().cpu().numpy()
pred_vals.extend(pred); true_vals.extend(true)
plt.figure(figsize=(10,5))
plt.plot(true_vals, label='True', alpha=0.7)
plt.plot(pred_vals, label='Pred', alpha=0.7)
plt.title('Figure 3: Predictions vs True')
plt.xlabel('Sample Index'); plt.ylabel('Value')
plt.legend(); plt.grid()
plt.show()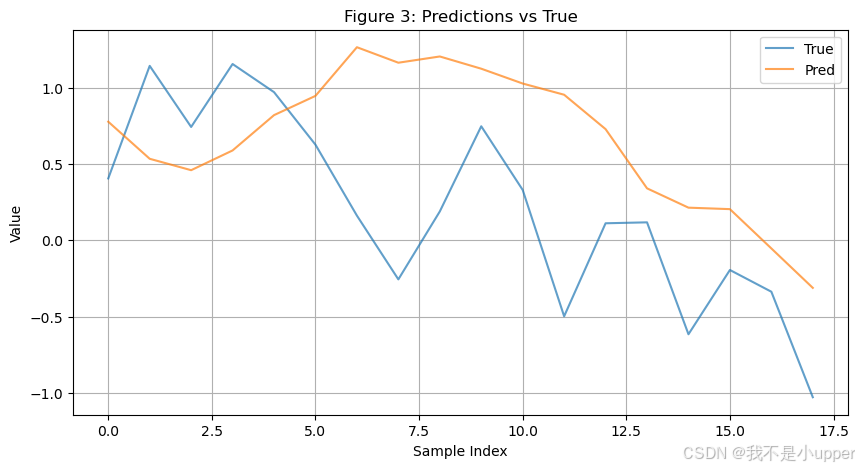
通过对比预测值和真实值曲线,最理想的情况是两条曲线高度重叠。如果预测曲线落后真实曲线一个时间步,需要检查标签对齐或模型的记忆窗口长度是否设置合理。此外,若模型对波峰、波谷等突变情况的预测误差较大,可考虑在卷积层前后加入残差连接,增强模型对局部特征的捕捉能力。
误差直方图
# 图4
errors = np.array(pred_vals) - np.array(true_vals)
plt.figure(figsize=(8,4))
plt.hist(errors, bins=20, edgecolor='black')
plt.title('Figure 4: Error Distribution')
plt.xlabel('Error'); plt.ylabel('Frequency')
plt.grid()
plt.show()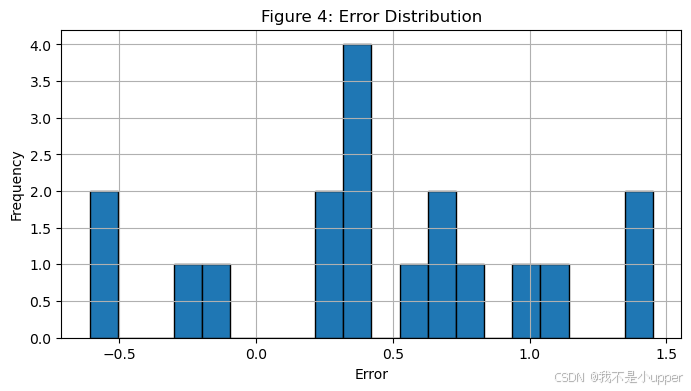
观察误差分布直方图,如果分布近似对称,且尖峰和谷值较小,说明误差接近高斯分布;若分布存在偏态或长尾现象,需要分析异常值点,并可考虑使用 Huber Loss 替代 MSE Loss,以降低异常值对损失函数的影响。此外,还可以通过计算偏度(skewness)和峰度(kurtosis)等指标,量化误差分布的特性。
参数网格设计
为了进一步优化模型性能,可以对以下参数进行网格搜索:
-
学习率 (lr): [1e-4, 3e-4, 1e-3, 3e-3];
-
Batch Size: [8, 16, 32, 64];
-
隐藏层维度 (hidden_size): [16, 32, 64, 128];
-
卷积核大小 (kernel_size): [3, 5, 7, 9];
-
卷积通道数 (out_channels): [16, 32, 64];
总结
以上内容,全面展示了 CNN+RNN 时间序列预测的设计思路、实现细节与调优方法。
大家可基于本模板:
-
引入 Transformer、TCN、图神经网络等;
-
拓展多变量时间序列、多步预测;
-
集成自动化调参框架;
-
在生产环境使用 TorchScript、ONNX 加速推理。


















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









