










哈喽,我是我不是小upper!
之前和大家聊过随机森林和神经网络的相关内容,今天咱们来探讨一下这两者强强联合能产生怎样的协同效应~
首先关于抽象特征提取,举个例子,神经网络就像一位擅长 “抽丝剥茧” 的分析师,通过多层非线性变换,能从原始输入数据(如图像像素、声音波形、文本语义等)中,自动学习出多尺度、多层次的高阶抽象特征。举个例子,在图像分类任务中,它会先捕捉边缘、纹理等基础特征,再层层剥离数据表象,逐步提炼出 “眼睛轮廓”“细胞形态” 等对疾病分类更关键的高层语义特征。这些特征经过非线性变换后,对下游任务(如区分青光眼与白内障)具有更强的判别力,能有效突出数据中的核心模式,同时抑制噪声和冗余信息。
然后,增强模型鲁棒性,随机森林如同一个 “经验丰富的决策委员会”,由多棵决策树通过集成学习组成。每棵树在训练时都会采用袋外样本(out-of-bag)和特征子集随机化策略,这使得它天然具备抗干扰能力:
- 抗噪声性:即使训练数据中存在少量异常样本或标注误差,多棵树的投票机制也能稀释这些干扰,避免单棵树过拟合局部噪声。
- 稳定性:基于信息增益或 Gini 不纯度的特征分割决策,使每棵树的决策逻辑清晰可解释,而集成后的投票 / 平均结果又能平滑单棵树的波动,让整体预测结果更稳定可靠。
最后关于协同效应,其实就是1+1>2 的底层逻辑
这对组合的核心优势在于特征与决策的双向赋能:
- 神经网络→随机森林:神经网络输出的低维抽象特征,如同为随机森林 “清理了战场”—— 这些特征已过滤掉原始数据中的无效信息,并强化了任务相关的关键模式,大幅降低了随机森林在高维稀疏空间中寻找最优分割点的计算复杂度。例如,在医疗影像分析中,神经网络先提取病灶的抽象特征,随机森林再基于这些特征进行快速分类,可提升决策效率。
- 随机森林→神经网络:在混合训练方案中,随机森林的输出(如单棵树的叶节点分布、集成投票概率)可作为额外监督信号反馈给神经网络。这种 “软标签” 能引导神经网络优化输出分布,尤其在样本不平衡或噪声较大的场景中,可进一步稳定训练过程,提升模型泛化能力。
模型结构设计
我们提出的模型采用 “特征提取 - 决策预测” 的两阶段架构,核心思想是结合神经网络(NN)的特征抽象能力与随机森林(RF)的稳健性,兼顾模型性能与可解释性。以下从特征提取、决策预测、联合训练及推理流程四个模块展开详细说明。
一、神经网络特征提取阶段
模型的输入是原始样本 (d 为输入维度)。第一阶段通过神经网络提取高阶抽象特征,具体结构根据数据类型灵活选择:
- 若输入为表格数据(如临床指标、金融特征),采用前馈神经网络(Fully-Connected Network);
- 若输入为图像 / 时序数据(如医学影像、传感器信号),则采用卷积神经网络(CNN)或循环神经网络(RNN)。
以最通用的 L 层前馈网络为例,第 l 层的隐藏表示 由以下公式计算:
其中:
(输入层);
是第 l 层的权重矩阵(
为该层神经元数量);
是偏置向量;
为逐元素非线性激活函数(如 ReLU
、Sigmoid
等),用于引入非线性表达能力。
经过 L 层变换后,最终提取的特征向量记为 ,其维度通常远小于原始输入 d,但包含更具判别力的抽象信息(如医学影像中的病灶边缘、文本中的语义主题)。
二、随机森林决策阶段
第二阶段采用随机森林(Random Forest, RF)作为分类 / 回归器,通过集成多棵决策树提升模型稳健性。RF 包含 T 棵独立训练的决策树 ,每棵树的训练流程如下:
1. 自助采样(Bootstrap)
每棵树的训练数据通过 “有放回抽样” 生成:从原始训练集 中随机抽取 N 个样本(允许重复),构成该树的训练子集
。此操作使每棵树关注不同的数据子集,降低模型过拟合风险。
2. 节点分裂规则
每棵树通过递归分裂构建:在节点 上,从当前节点的 m 个样本中随机选取 k 个特征维度k≪d作为候选分裂特征;对每个候选特征
,在其取值范围内选取若干阈值
,计算分裂质量(即分裂后子节点的不纯度减少量),最终选择分裂质量最高的
对节点进行划分。
分裂质量的计算方式因任务而异:
-
分类任务:采用Gini 不纯度衡量节点混乱度,公式为:
其中
是节点
中类别 k 的样本占比(C 为总类别数)。分裂后的信息增益(不纯度减少量)为:
(n 为当前节点样本数,
为左右子节点样本数)
-
回归任务:采用方差减少量作为分裂指标,公式为:
其中
是节点
3. 叶节点预测与集成输出
每棵树递归分裂直至满足停止条件(如最大深度、最小样本数),最终叶节点的预测规则为:
- 分类:叶节点
输出各类别的概率
(
为类别 k 的样本数,
为叶节点总样本数);
- 回归:叶节点
。
最终,随机森林的集成输出为:
- 分类(多数投票):
(
为第 t 棵树对类别 k 的概率输出);
- 回归(平均):
(
为第 t 棵树的回归预测值)。
三、联合训练与优化策略
模型的训练分为两种模式,可根据任务需求选择:
1. 串联训练(两阶段独立训练)
- 阶段一:训练神经网络:固定随机森林未参与,仅通过监督学习(如分类用交叉熵损失
, 回归用均方误差
)优化神经网络参数
,得到稳定的特征映射
。
- 阶段二:训练随机森林:将神经网络提取的特征
作为输入,用原始标签训练随机森林,优化其分裂规则与叶节点预测。
2. 端到端近似训练
为进一步提升性能,可通过 “可微分决策树” 技术实现神经网络与随机森林的联合优化:将随机森林的硬分裂( 严格属于左 / 右子节点)近似为软分裂(通过激活函数输出属于子节点的概率),使整个模型可通过梯度下降端到端训练。
例如,节点分裂函数可设计为: 其中
是分裂参数,
为温度参数(初始设为较大值使
接近 0.5,训练后期逐步降低
逼近硬划分)。通过这种方式,模型可同时优化神经网络的特征提取能力与随机森林的决策规则,提升整体预测精度。
四、推理流程
给定新样本 ,推理过程分为两步:
- 特征提取:通过训练好的神经网络前向传播,得到抽象特征
;
- 决策预测:将
输入随机森林,每棵树独立输出预测值(分类概率或回归均值),最终通过多数投票(分类)或平均(回归)得到最终结果。
模型优势总结
- 抽象化 + 稳健性:神经网络将原始输入映射为更具判别力的特征(如从像素到 “病灶边界”),随机森林通过多树集成与随机采样降低过拟合风险,提升模型对噪声的鲁棒性;
- 高效训练:两阶段训练简单易行(无需复杂联合优化),端到端近似训练则进一步挖掘模型潜力,适用于高精度需求场景;
- 可解释性:随机森林的决策路径(如 “特征 f3>0.5 → 进入左子节点”)可追溯,结合神经网络的特征可视化(如热力图显示关键输入区域),为模型决策提供透明依据。
完整案例:融合神经网络与随机森林的分类实践
一、虚拟数据集构造与特性
我们构造一个二分类同心圆数据集,用于测试模型对非线性分布数据的处理能力。通过sklearn.datasets.make_circles生成数据,核心参数包括:
n_samples=2000:总样本数noise=0.1:样本噪声水平factor=0.4:内外圆半径比例(值越小,类别间距越大)random_state=42:随机种子确保可复现
数学表达: 数据集分布满足非线性可分条件,两类样本在二维空间中呈同心圆分布,无法用线性决策边界分割。设样本特征为 ,标签为
,理想决策边界为
(r 为临界半径)。
可视化分析:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
# 生成数据
X, y = make_circles(n_samples=2000, noise=0.1, factor=0.4, random_state=42)
# 可视化数据分布
plt.figure(figsize=(6,6))
plt.scatter(X[:,0], X[:,1], c=y, cmap='rainbow', edgecolor='k', s=30)
plt.title('Dataset: Concentric Circles', fontsize=14)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()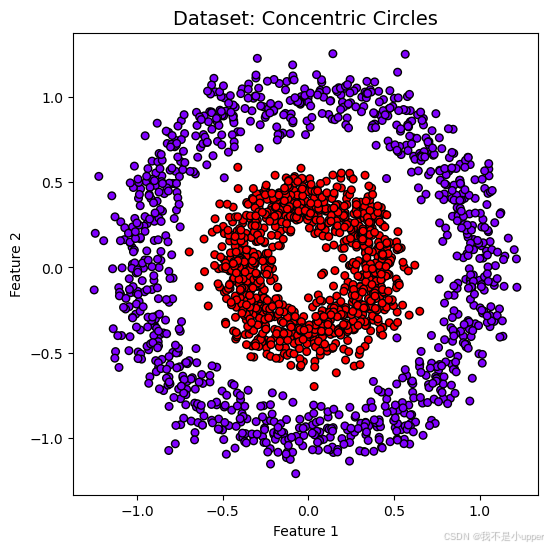
图 1:红蓝样本呈同心圆分布,边界非线性,考验模型特征抽象能力。
二、神经网络模型设计(PyTorch 实现)
我们设计一个多层感知机(MLP),通过多层非线性变换提取高阶特征。模型结构如下:
- 输入层:维度
(原始特征维度)
- 隐藏层:3 层,维度分别为 64、128、64,每层包含:
- 线性变换:
- 批量归一化(BatchNorm):
- 激活函数(ReLU):
- 线性变换:
- 输出层:维度
(二分类对数概率)
前向传播公式: 其中 L 为隐藏层数,
为类别概率分布。
代码实现:
import torch
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, input_dim=2, hidden_dims=[64, 128, 64], output_dim=2):
super(MLP, self).__init__()
layers = []
prev_dim = input_dim
for h in hidden_dims:
layers.append(nn.Linear(prev_dim, h))
layers.append(nn.BatchNorm1d(h))
layers.append(nn.ReLU())
prev_dim = h
layers.append(nn.Linear(prev_dim, output_dim))
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(x)
# 实例化
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_nn = MLP().to(device)三、随机森林模型设计(Scikit-learn 实现)
随机森林通过集成多棵决策树提升鲁棒性,核心机制包括:
- 自助采样(Bootstrap):对训练集随机采样生成多棵树的输入
- 特征随机选择:每棵树分裂时仅考虑部分特征子集
- 投票机制:通过多数投票(分类)或均值(回归)聚合结果
from sklearn.ensemble import RandomForestClassifier
model_rf = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)模型参数:
n_estimators=100:树的数量max_depth=5:单棵树的最大深度(控制复杂度)random_state=42:随机种子
数学本质: 设 T 为树的数量,每棵树 输出类别预测,则随机森林预测为:
其中
为指示函数。
四、模型训练与特征融合框架
-
数据划分: 按 8:2 比例划分为训练集
和测试集
,确保分布一致性。
-
神经网络训练:
- 损失函数:交叉熵损失
- 优化器:Adam 优化器,学习率
- 训练流程:迭代 50 轮,每批次 32 样本,使用 GPU 加速(若可用)。
- 损失函数:交叉熵损失
-
特征融合: 提取神经网络最后隐藏层输出作为抽象特征,与原始特征拼接:
其中
为隐藏层输出,维度为 128(由模型结构决定)。
-
随机森林训练: 将融合特征
输入随机森林,学习样本空间与抽象特征空间的联合分布。
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, TensorDataset
# 划分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# PyTorch 数据加载
train_tensor = TensorDataset(torch.tensor(X_train, dtype=torch.float32), torch.tensor(y_train, dtype=torch.long))
train_loader = DataLoader(train_tensor, batch_size=32, shuffle=True)
# NN 训练流程
optimizer = torch.optim.Adam(model_nn.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
model_nn.train()
for epoch in range(50):
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
preds = model_nn(batch_x)
loss = criterion(preds, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 提取特征
model_nn.eval()
with torch.no_grad():
feat_train = model_nn.net[:-1](torch.tensor(X_train, dtype=torch.float32).to(device)).cpu().numpy()
feat_test = model_nn.net[:-1](torch.tensor(X_test, dtype=torch.float32).to(device)).cpu().numpy()
# 拼接特征
X_train_fused = np.concatenate([X_train, feat_train], axis=1)
X_test_fused = np.concatenate([X_test, feat_test], axis=1)
# RF 训练
model_rf.fit(X_train_fused, y_train)
# 预测
with torch.no_grad():
logits = model_nn(torch.tensor(X_test, dtype=torch.float32).to(device))
proba_nn = torch.softmax(logits, dim=1)[:, 1].cpu().numpy()
proba_rf = model_rf.predict_proba(X_test_fused)[:,1]fig, axes = plt.subplots(2, 2, figsize=(12,12))
xx, yy = np.meshgrid(np.linspace(-1.5,1.5,300), np.linspace(-1.5,1.5,300))
grid = np.c_[xx.ravel(), yy.ravel()]
def plot_contour(ax, model_fn, title):
Z = model_fn(grid)
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, levels=20, cmap='plasma', alpha=0.6)
ax.scatter(X_test[:,0], X_test[:,1], c=y_test, cmap='rainbow', edgecolor='k', s=20)
ax.set_title(title, fontsize=14)
# (1)
axes[0,0].scatter(X_test[:,0], X_test[:,1], c=y_test, cmap='rainbow', edgecolor='k', s=30)
axes[0,0].set_title('Original Data')
# (2) NN
plot_contour(axes[0,1], lambda d: torch.softmax(model_nn(torch.tensor(d, dtype=torch.float32).to(device)),1)[:,1].cpu().detach().numpy(), 'NN Boundary')
# (3) RF
plot_contour(axes[1,0], lambda d: model_rf.predict_proba(np.concatenate([d, model_nn.net[:-1](torch.tensor(d, dtype=torch.float32).to(device)).cpu().detach().numpy() ],axis=1))[:,1], 'RF on Fused Features')
# (4) 预测对比曲线
axes[1,1].plot(sorted(proba_nn), label='NN Probabilities')
axes[1,1].plot(sorted(proba_rf), label='RF Probabilities')
axes[1,1].set_title('Prediction Probabilities Comparison')
axes[1,1].legend()
fig.suptitle('Model Visualization and Comparison', fontsize=16)
plt.tight_layout()
plt.show()五、结果可视化与分析
-
决策边界对比:
- 神经网络:通过多层非线性变换,学习复杂曲面边界,贴合同心圆分布(图 2)。
- 随机森林(融合特征):基于高阶特征生成更平滑的决策边界,对噪声鲁棒性更强(图 3)。
-
预测概率对比: 将测试集样本按预测概率排序,神经网络在低概率区间(不确定样本)波动更大,而随机森林概率分布更集中,反映其集成特性带来的稳定性(图 4)。
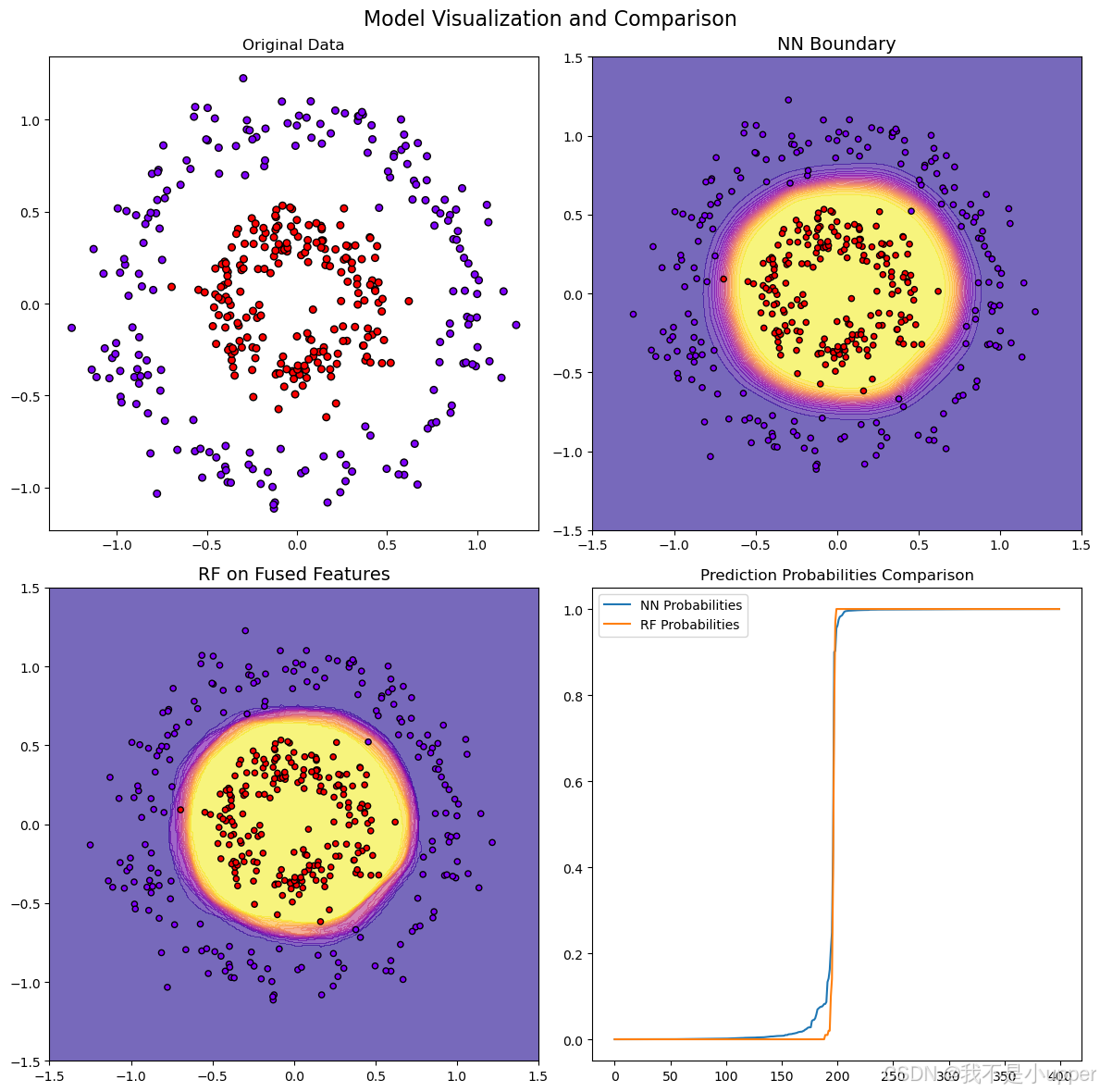
图 2-4:从左到右、从上到下依次为原始数据、神经网络边界、随机森林边界、概率曲线对比。
六、算法优化要点与调参逻辑
-
神经网络优化:
- 结构调优:增加隐藏层宽度(如从 128→256)可提升表达能力,但需配合正则化防止过拟合。
- 正则化:在隐藏层后添加 Dropout 层(如
nn.Dropout(0.2)),或使用权重衰减(L2 正则化)。 - 学习率调度:采用余弦退火学习率(CosineAnnealingLR),动态调整学习率加速收敛。
-
随机森林优化:
- 树的数量:
n_estimators需足够大(如≥200)以降低方差,但过高会增加计算成本。 - 特征选择:
max_features='sqrt'(默认)适用于低维数据,高维场景可尝试max_features=0.3。 - 剪枝参数:通过
min_samples_split=10限制叶子节点最小样本数,避免过拟合。
- 树的数量:
-
集成策略扩展:
- 特征融合优化:对抽象特征进行 PCA 降维(如从 128→32),减少随机森林输入维度。
- 概率加权融合:结合神经网络与随机森林的预测概率(如
0.6*p_nn + 0.4*p_rf),提升泛化能力。
总结
本案例通过神经网络提取非线性特征与随机森林集成决策的结合,两者的结合既保留了神经网络的特征学习优势,又继承了随机森林的可解释性与稳健性,堪称 “抽象思维” 与 “经验决策” 的完美互补。关键在于:
- 神经网络通过多层变换捕获数据内在复杂结构
- 随机森林利用集成机制增强鲁棒性,避免过拟合
- 特征融合实现 “原始特征的物理意义” 与 “抽象特征的高阶关联” 的联合建模
在复杂场景下,此框架可扩展至图像分类、生物医学信号分析等复杂非线性场景,通过调参和架构优化进一步提升性能。



















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











