






各位小伙伴大家好,很高兴又能和你见面,,在这篇博客中我将记录我再暑期学习中出现的debug以及修改debug的过程
首先我们先来看看作业要求

所使用的网络结构: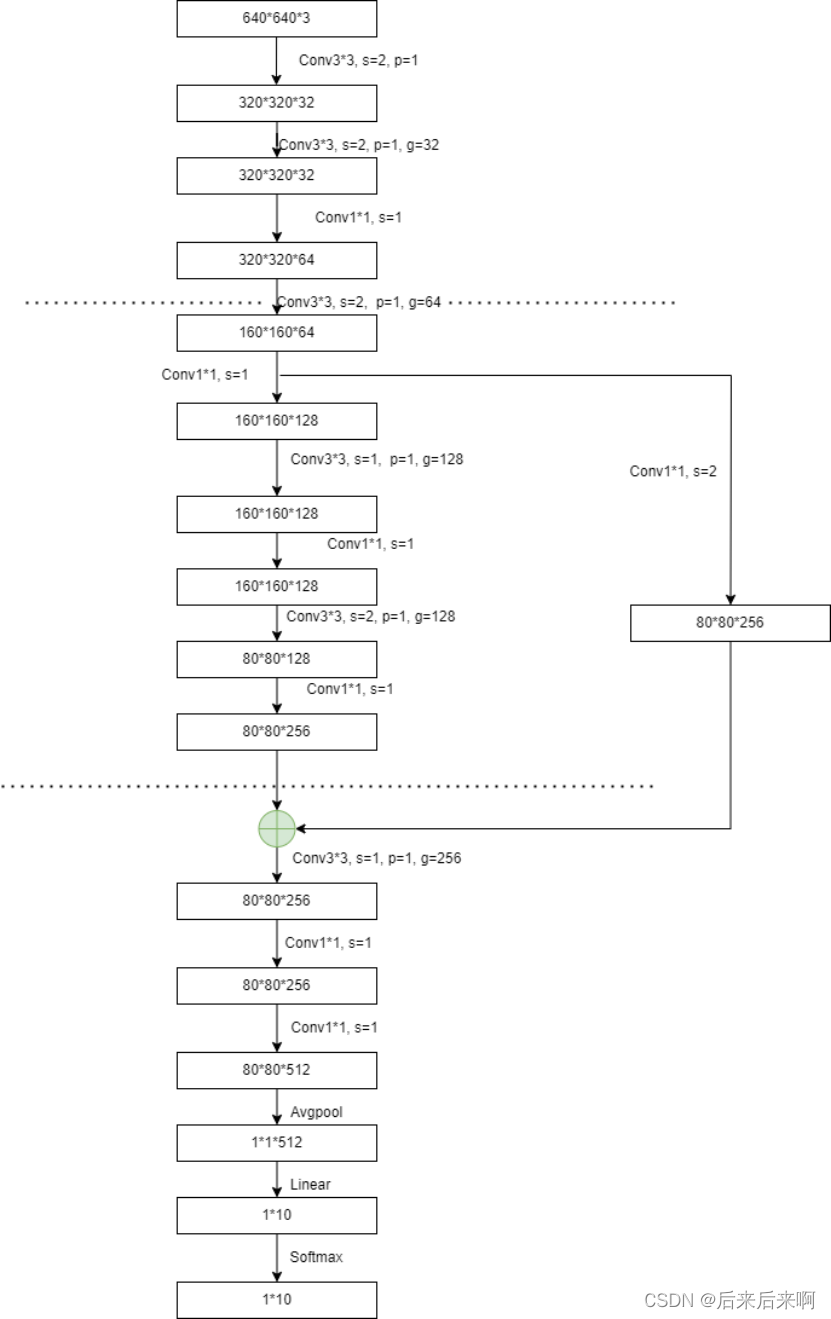
由上网络结构我们易知此网路我们需要用到残差结构,所以我们可以参考resnet的写法来写这个网络结构
resnet代码写法可以参考我之前写的Pytorch学习笔记:RNN的原理及其手写复现_后来后来啊的博客-CSDN博客
在使用pytorch搭建ResNet并基于迁移学习训练(超详细 |附训练代码)_后来后来啊的博客-CSDN博客这篇博客当中,我们定义了一个model函数
所以在此我们也在model.py中定义我们的网络结构
首先我先写了以下代码来实现这个网络结构
import torch
import torch.nn as nn
import torchsummary
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, groups=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, groups=groups)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.relu = nn.ReLU(inplace=True)
if stride != 1 or in_channels != out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0),
nn.BatchNorm2d(out_channels)
)
else:
self.downsample = None
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.relu(out)
out = self.conv2(out)
out = self.relu(out)
out = self.conv3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1)
self.lconv1 = nn.Conv2d(32, 32, kernel_size=3, stride=2, padding=1, groups=32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=1, stride=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, groups=1)
self.conv4 = nn.Conv2d(128, 128, kernel_size=1, stride=1)
self.conv5 = nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1, groups=128)
self.conv6 = nn.Conv2d(256, 256, kernel_size=1, stride=1)
self.conv7 = nn.Conv2d(256, 512, kernel_size=1, stride=1)
self.avgpool = nn.AvgPool2d(kernel_size=20)
self.fc = nn.Linear(2048, 10) # 修改全连接层的输入维度
self.softmax = nn.Softmax(dim=1)
self.relu = nn.ReLU(inplace=True)
self.residual_block = ResidualBlock(128, 128, stride=2, groups=1)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.lconv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.relu(x)
x = self.residual_block(x)
x = self.conv5(x)
x = self.relu(x)
x = self.conv6(x)
x = self.relu(x)
x = self.conv7(x)
x = self.relu(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
x = self.softmax(x)
return x
model = Network()
model = model.cuda()
# Print the model summary to the console
torchsummary.summary(model, (3, 640, 640))
但是我再跑网络的时候发现该结构运行的准确率只有40%左右,于是我我打印出网络结构层级和输出尺寸等信息

发现该网络缺少下采样(batchnorm,dropout)等方法的多使用,且总参数 相比较而言偏少
于是我想在每层卷积后都加个下采样会是什么样
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchsummary
class ResidualBlock(nn.Module):#公式:O=(W-F+2P)/S+1
# 构造方法(构造函数中至少需要传入2个参数:进出的通道数。残差块的一个最主要的作用就是改变信号的通道数)
def __init__(self, in_channels, out_channels, stride=1, groups=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels))
self.conv6 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.ReLU)
self.conv7 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU())
self.conv8 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=2, padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.ReLU())
self.conv9 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU())
self.downsample = downsample
if stride != 1 or in_channels != out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(256))
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv5(x)
out = self.conv6(out)
out = self.conv7(out)
out = self.conv8(out)
out = self.conv9(out)
out += identity
out = F.relu(out)
return out
class Network(nn.Module):
def __init__(self, num_classes=1000):
super(Network,self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1, bias=True),
nn.BatchNorm2d(32),
nn.ReLU())
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=2, padding=1, groups=32, bias=True),
nn.BatchNorm2d(32),
nn.ReLU())
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=1, stride=1, bias=True),
nn.BatchNorm2d(64),
nn.ReLU())
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2, padding=1, groups=64, bias=True),
nn.BatchNorm2d(64),
nn.ReLU())
self.residual_block = ResidualBlock(64, 128, stride=2)
self.conv10 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1, groups=256),
nn.BatchNorm2d(256),
nn.ReLU())
self.conv11 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=1, stride=1),
nn.BatchNorm2d(256),
nn.ReLU())
self.conv12 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=1, stride=1),
nn.BatchNorm2d(512),
nn.ReLU())
self.Avgpool = nn.AdaptiveAvgPool2d((1,1))#将输入的特征图的大小调整为1x1x512
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(x)
out = self.conv3(x)
out = self.conv4(x)
out = self.residual_block(x)
out = self.conv10(x)
out = self.conv11(x)
out = self.conv12(x)
out = self.Avgpool(x)
out = torch.flatten(x, 1)
out = self.fc(x)
return out
model = Network()
model = model.cuda()
#
# # Print the model summary to the console
torchsummary.summary(model, (3, 640, 640))这是我重新写的一个网络结构,但是出现了相当多的报错,有小伙伴能在不看的情况下把这些报错都改过来吗,有的话评论区扣1,好了回归正题
首先我们遇到的报错是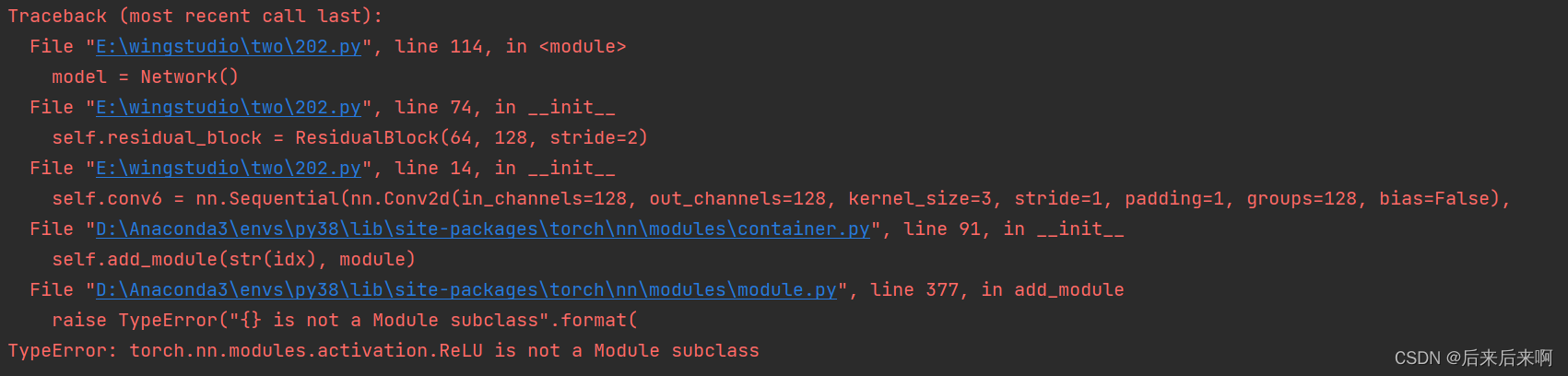
根据报错原因说的是这个错误意味着`torch.nn.modules.activation.ReLU`不是`Module`的子类
我们再来自习看代码发现在16行我们使用的是nn.ReLU,但是正确使用方法应该是nn.ReLU()
更改后是第二个报错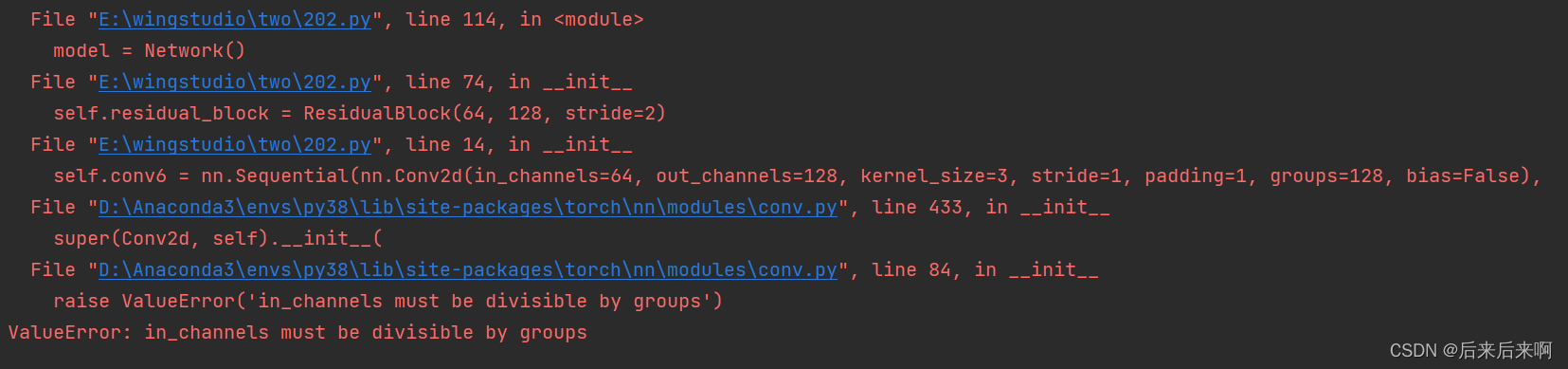
根据报错信息可知是因为输入值不能被groups整除,重新查看网络发现,这是因为我在 定义残差 网络是复制输入那一坨nn.Sequential的时候出现了问题,再看网络时候发现就是输入输出出现了问题
于是改成了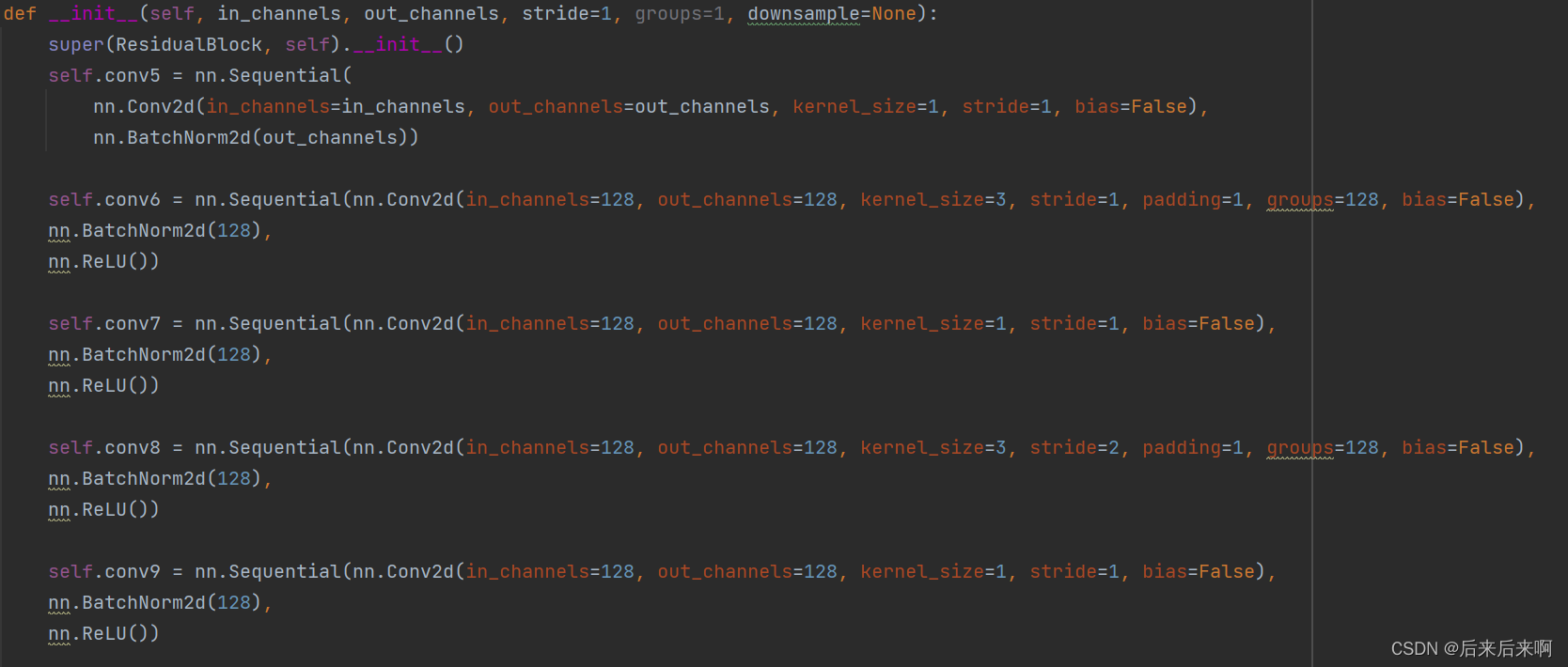
但是接下来又出现了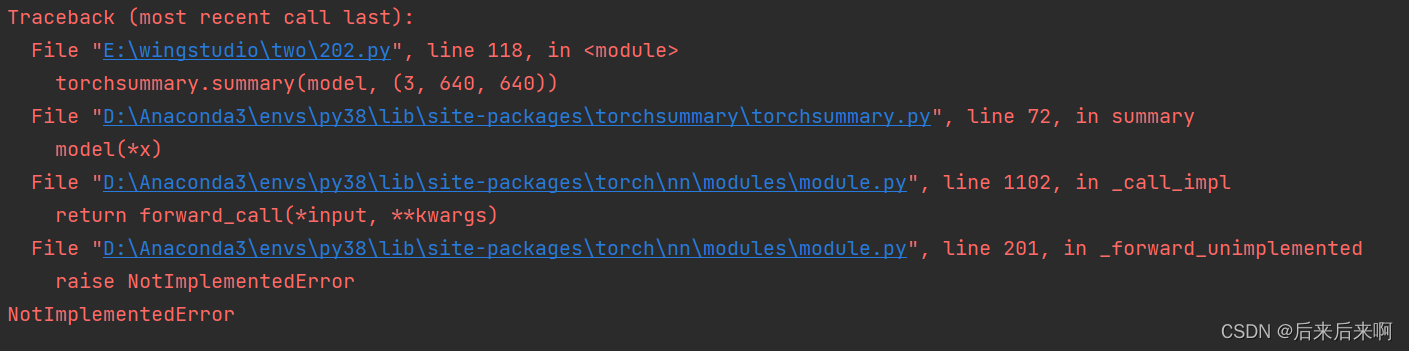
这个报错,思考了我许久,又去看原先定的网络结构,然后 上csdn上 看了这篇博客:NotImplementedError raise NotImplementedError_"s/module.py\", line 201, in _forward_unimplemente_Matthew2333的博客-CSDN博客
该博客说是因为我们forward函数出了错误,再细看网络发现在NetWork中,forward函数中的self没有像正确定义后出现紫色字样,这是因为我们把forward函数定义在了def __init__中,正确 做法应该是俩个def齐平
如下图
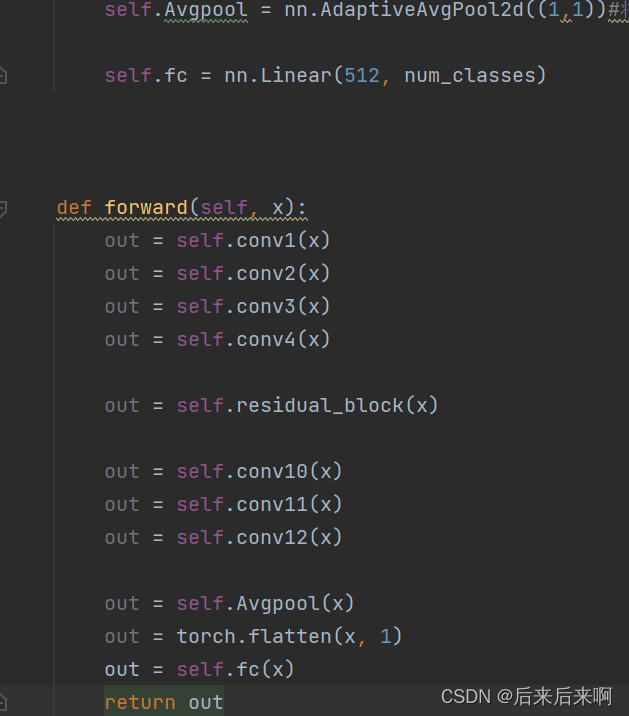
然后出现了最让我头疼的报错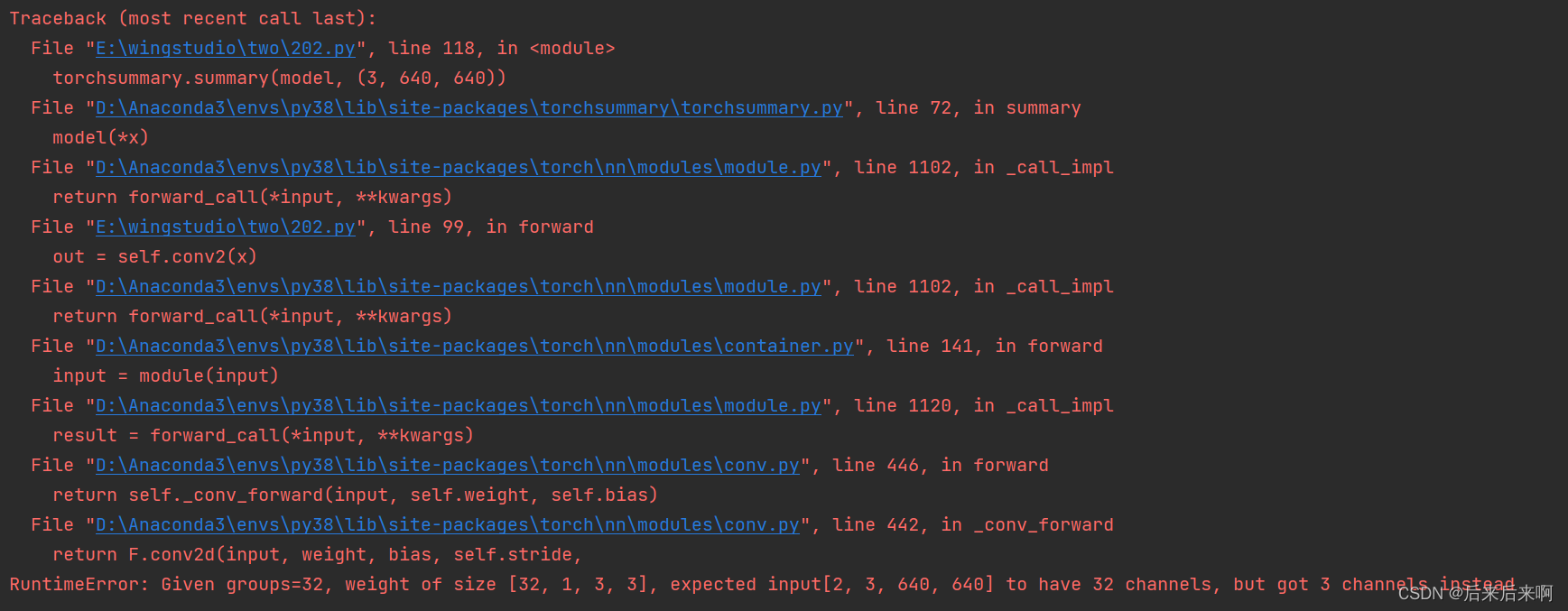
最终在改博客中得到解决:解决Given groups=1,weight [128,64,4,4], so expected inputs [32,32,64,64] to have 64 channels类似错误_萨姆西的博客-CSDN博客
根据博主说的是因为我们在输入是打成了x,而不是out,再看看 报错地方正是99行
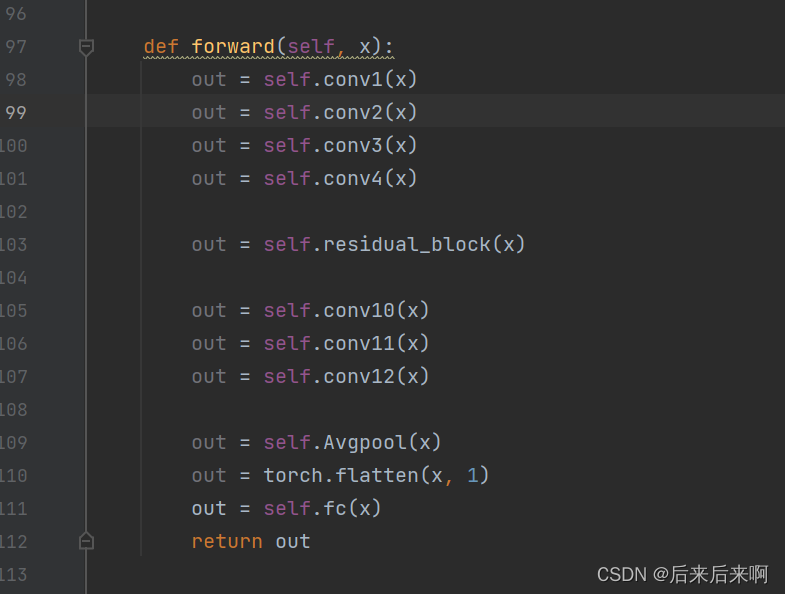
我们修改后面的x为out试试,发现变成了
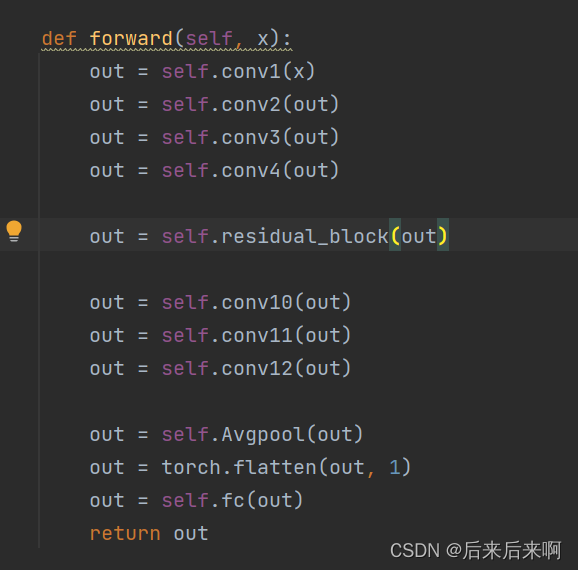
紧接着报错就变成了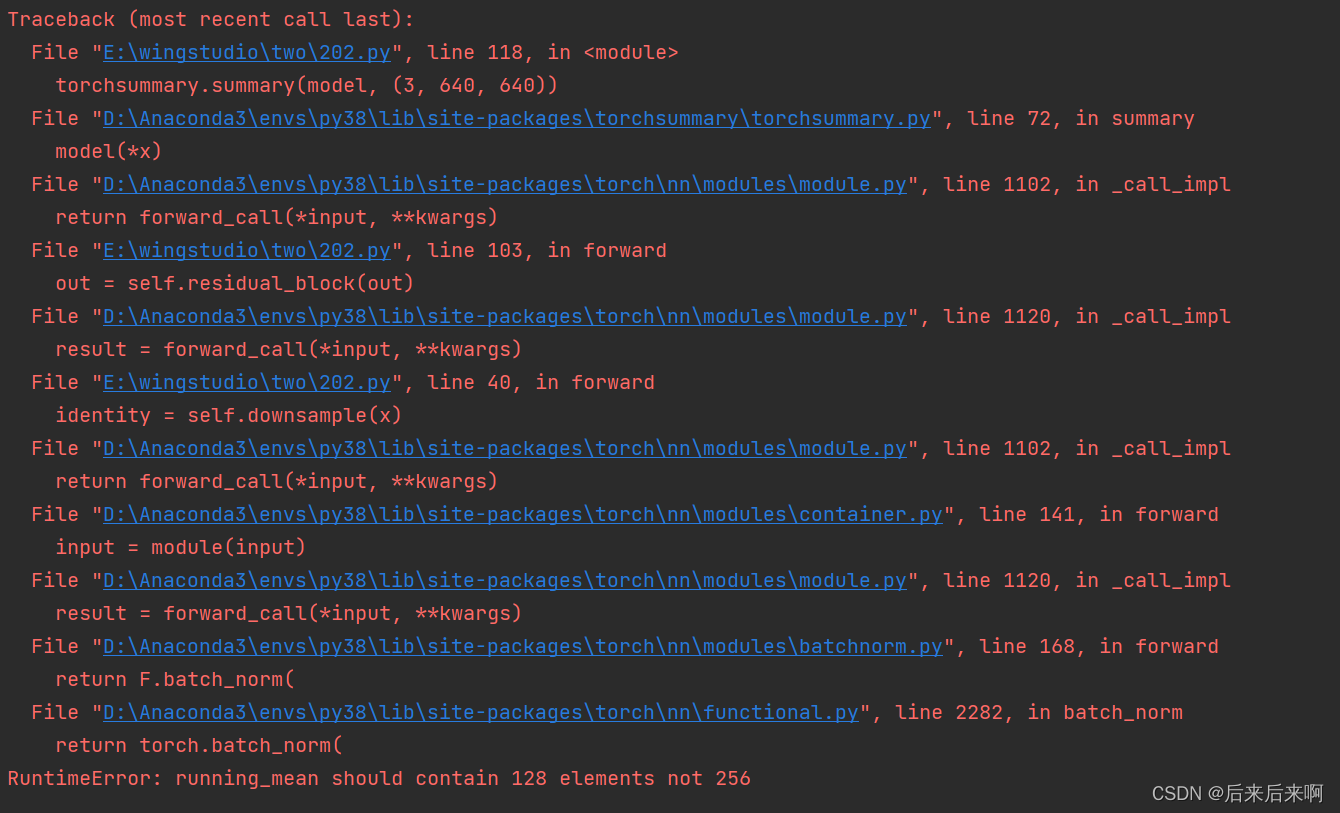
代码说我们在残差网络中我们输入的是128,但是需要的是256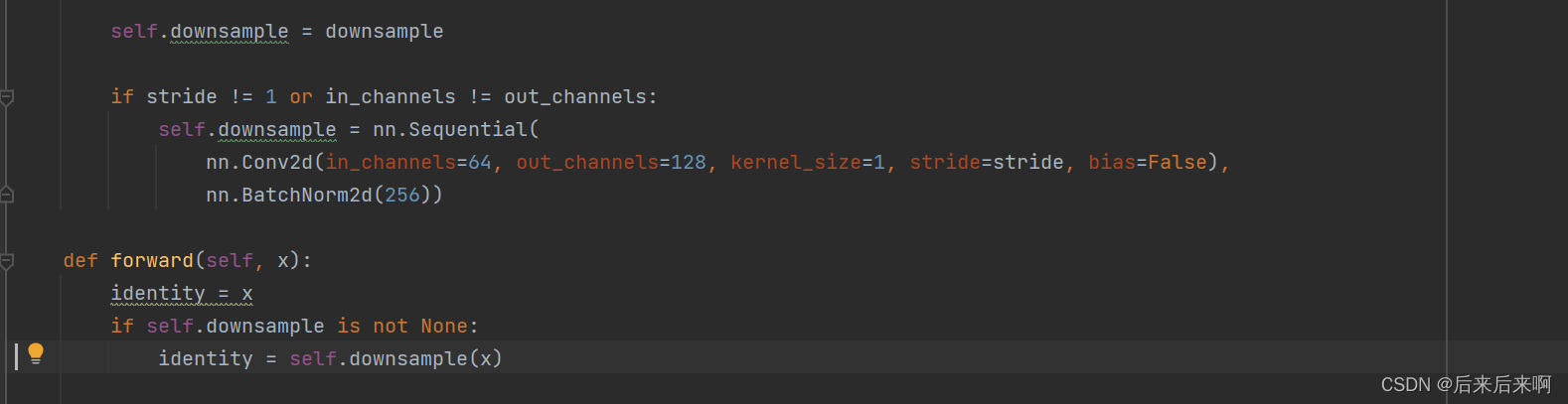
由图可以看到我们在定义downsample的时候,输出写成了128才出现了该错误
于是我们改成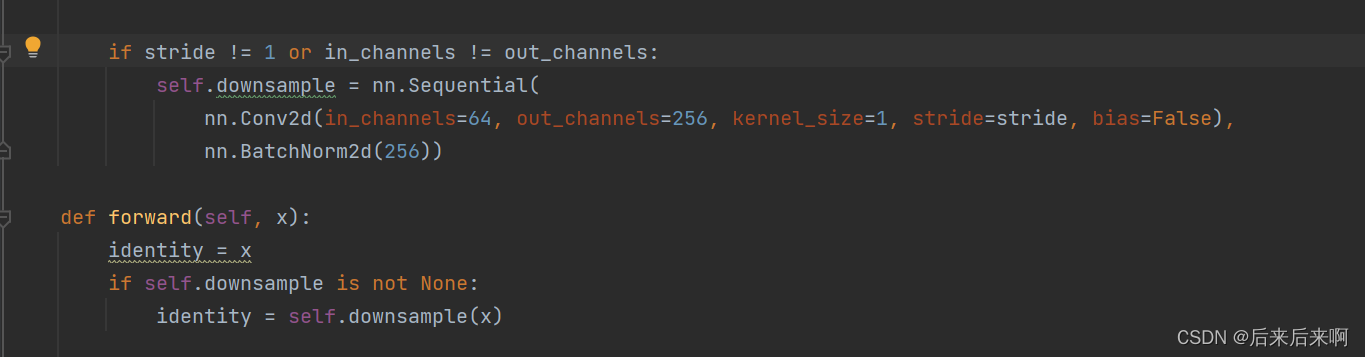
虽然此处解决了,但是还可以使用其他方法,这里给大家提供一种思路

第1,2点可以用在model的out = self.conv9(out)中,例如
out = self.conv9(out.clone().detach())最终打印出网络
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 320, 320] 896
BatchNorm2d-2 [-1, 32, 320, 320] 64
ReLU-3 [-1, 32, 320, 320] 0
Conv2d-4 [-1, 32, 160, 160] 320
BatchNorm2d-5 [-1, 32, 160, 160] 64
ReLU-6 [-1, 32, 160, 160] 0
Conv2d-7 [-1, 64, 160, 160] 2,112
BatchNorm2d-8 [-1, 64, 160, 160] 128
ReLU-9 [-1, 64, 160, 160] 0
Conv2d-10 [-1, 64, 80, 80] 640
BatchNorm2d-11 [-1, 64, 80, 80] 128
ReLU-12 [-1, 64, 80, 80] 0
Conv2d-13 [-1, 256, 40, 40] 16,384
BatchNorm2d-14 [-1, 256, 40, 40] 512
Conv2d-15 [-1, 128, 80, 80] 8,192
BatchNorm2d-16 [-1, 128, 80, 80] 256
Conv2d-17 [-1, 128, 80, 80] 1,152
BatchNorm2d-18 [-1, 128, 80, 80] 256
ReLU-19 [-1, 128, 80, 80] 0
Conv2d-20 [-1, 128, 80, 80] 16,384
BatchNorm2d-21 [-1, 128, 80, 80] 256
ReLU-22 [-1, 128, 80, 80] 0
Conv2d-23 [-1, 128, 40, 40] 1,152
BatchNorm2d-24 [-1, 128, 40, 40] 256
ReLU-25 [-1, 128, 40, 40] 0
Conv2d-26 [-1, 256, 40, 40] 32,768
BatchNorm2d-27 [-1, 256, 40, 40] 512
ReLU-28 [-1, 256, 40, 40] 0
ResidualBlock-29 [-1, 256, 40, 40] 0
Conv2d-30 [-1, 256, 40, 40] 2,560
BatchNorm2d-31 [-1, 256, 40, 40] 512
ReLU-32 [-1, 256, 40, 40] 0
Conv2d-33 [-1, 256, 40, 40] 65,792
BatchNorm2d-34 [-1, 256, 40, 40] 512
ReLU-35 [-1, 256, 40, 40] 0
Conv2d-36 [-1, 512, 40, 40] 131,584
BatchNorm2d-37 [-1, 512, 40, 40] 1,024
ReLU-38 [-1, 512, 40, 40] 0
AdaptiveAvgPool2d-39 [-1, 512, 1, 1] 0
Linear-40 [-1, 1000] 513,000
================================================================
Total params: 797,416
Trainable params: 797,416
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 4.69
Forward/backward pass size (MB): 251.57
Params size (MB): 3.04
Estimated Total Size (MB): 259.30
----------------------------------------------------------------
进程已结束,退出代码0
但是在使用该网络的时候又出现了报错
这个报错让我听没有头绪得,因为他说这个错误通常是由于在计算梯度时,某个变量被就地修改(inplace operation)导致的,于是我上csdn查了一下,然后在博客:报错解决:one of the variables needed for gradient computation has been modified by an inplace operation_y4ung的博客-CSDN博客
中说是因为使用了+=,于是返回 model更改为
最终问题解决 ,代码成功跑起
最后附上model.py和train.py
model.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchsummary
class ResidualBlock(nn.Module):#公式:O=(W-F+2P)/S+1
# 构造方法(构造函数中至少需要传入2个参数:进出的通道数。残差块的一个最主要的作用就是改变信号的通道数)
def __init__(self, in_channels, out_channels, stride=1, groups=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels))
self.conv6 = nn.Sequential(nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.ReLU())
self.conv7 = nn.Sequential(nn.Conv2d(in_channels=128, out_channels=128, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU())
self.conv8 = nn.Sequential(nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=2, padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.ReLU())
self.conv9 = nn.Sequential(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
self.downsample = downsample
if stride != 1 or in_channels != out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(256))
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv5(x)
out = self.conv6(out)
out = self.conv7(out)
out = self.conv8(out)
out = self.conv9(out)
out = out + identity
out = F.relu(out)
return out
class Network(nn.Module):
def __init__(self, num_classes=1000):
super(Network,self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1, bias=True),
nn.BatchNorm2d(32),
nn.ReLU())
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=2, padding=1, groups=32, bias=True),
nn.BatchNorm2d(32),
nn.ReLU())
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=1, stride=1, bias=True),
nn.BatchNorm2d(64),
nn.ReLU())
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2, padding=1, groups=64, bias=True),
nn.BatchNorm2d(64),
nn.ReLU())
self.residual_block = ResidualBlock(64, 128, stride=2)
self.conv10 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1, groups=256),
nn.BatchNorm2d(256),
nn.ReLU())
self.conv11 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=1, stride=1),
nn.BatchNorm2d(256),
nn.ReLU())
self.conv12 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=1, stride=1),
nn.BatchNorm2d(512),
nn.ReLU())
self.Avgpool = nn.AdaptiveAvgPool2d((1,1))#将输入的特征图的大小调整为1x1x512
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.residual_block(out)
out = self.conv10(out)
out = self.conv11(out)
out = self.conv12(out)
out = self.Avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
model = Network()
model = model.cuda()
#
# # Print the model summary to the console
# torchsummary.summary(model, (3, 640, 640))train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from torchvision.models import resnet50, resnet101
from PIL import Image
import os
import model
class LogoDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.image_files = []
self.labels = []
self.label_to_int = {} # 创建一个字典来映射label和整数的关系
self.int_to_label = {} # 创建一个字典来映射整数和label的关系
label_count = 0
for label in os.listdir(root_dir):
label_dir = os.path.join(root_dir, label)
if os.path.isdir(label_dir):
self.label_to_int[label] = label_count
self.int_to_label[label_count] = label
label_count += 1
for image_file in os.listdir(label_dir):
self.image_files.append(os.path.join(label_dir, image_file))
self.labels.append(label)
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
image = Image.open(self.image_files[idx]).convert("RGB")
label = self.labels[idx]
label = self.label_to_int[label] # 使用字典将label转换为整数
if self.transform:
image = self.transform(image)
return image, torch.tensor(label)
data_transform = transforms.Compose([
transforms.Resize((640, 640)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset = LogoDataset("E:/wingstudio/four/logo_data/train", transform=data_transform)
test_dataset = LogoDataset("E:/wingstudio/four/logo_data/test", transform=data_transform)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=4, shuffle=False)
class LogoClassifier(nn.Module):
def __init__(self, num_classes):
super(LogoClassifier, self).__init__()
self.base_model = model.Network()
self.fc = nn.Linear(1000, num_classes)
def forward(self, x):
x = self.base_model(x)
x = self.fc(x)
return x
def train(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
with torch.autograd.set_detect_anomaly(True):
loss.backward()
optimizer.step()
running_loss += loss.item() * images.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
return epoch_loss
def test(model, test_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / len(test_loader.dataset)
accuracy = correct / len(test_loader.dataset)
return epoch_loss, accuracy
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = LogoClassifier(num_classes=5)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(40):
train_loss = train(model, train_loader, criterion, optimizer, device)
test_loss, test_accuracy = test(model, test_loader, criterion, device)
print(
f"Epoch {epoch + 1}/{40}, Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.4f}")
if __name__ == "__main__":
main()
当然在这个网络结构基础上我有个朋友跑出来的正确率稍微更高一点,同样作者厚着脸皮要来了,这里@下原作者:灼清回梦_-CSDN博客
他的model.py
import torch
import torch.nn as nn
import torchsummary
import matplotlib.pyplot as plt
class ResdualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(ResdualBlock, self).__init__()
self.conv0 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=1, stride=1, bias=False)
self.bn0 = nn.BatchNorm2d(128)
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, groups=128, bias=False)
self.bn1 = nn.BatchNorm2d(128)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=1, stride=1, bias=False)
self.bn2 = nn.BatchNorm2d(128)
self.conv3 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=2, padding=1, groups=128, bias=False)
self.bn3 = nn.BatchNorm2d(128)
self.conv4 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=1, stride=1, bias=False)
self.bn4 = nn.BatchNorm2d(256)
self.shortcut = nn.Sequential()
if stride != 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels=256, stride=2, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels))
def forward(self, x):
identity = x
out = self.conv0(x)
out = self.bn0(out)
out = self.relu(out)
out = self.conv1(out)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.relu(out)
out = self.conv4(out)
out = self.bn4(out)
out += self.shortcut(identity)
out = self.relu(out)
return out
class Network(nn.Module):
def __init__(self, num_classes=1000):
super(Network,self).__init__()
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
#320*320*32
self.conv6 = nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=3,stride=2,padding=1,groups=32),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
# 320*320*32
self.conv7 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=1, stride=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
#320*320*64
self.conv8 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2,padding=1,groups=64),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
#160*160*64
self.layer1 = self.make_layer(64,256)
self.conv9 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1,groups=256,bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
)
self.conv10 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=1,stride=1,bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
)
self.conv11 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True)
)
#80*80*512
self.avgpool = nn.AdaptiveAvgPool2d((1,1))#1*1*512
self.fc = nn.Linear(512,num_classes)
def make_layer(self, in_channels, out_channels, stride=2):
layer = []
layer.append(ResdualBlock(in_channels,out_channels,stride))
return nn.Sequential(*layer)
def forward(self,x):
out = self.conv5(x)
out = self.conv6(out)
out = self.conv7(out)
out = self.conv8(out)
out = self.layer1(out)
out = self.conv9(out)
out = self.conv10(out)
out = self.conv11(out)
out = self.avgpool(out)
out = torch.flatten(out,1)
out = self.fc(out)
return out
model = Network()
model = model.cuda()
# Print the model summary to the console
torchsummary.summary(model, (3, 640, 640))
他的train.py
import torch
from torchvision import datasets, models, transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import numpy as np
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
image_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
dataset = 'E:\wingstudio/four\logo_data'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'test')
batch_size = 32
num_classes = 5
print(train_directory)
data = {
'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
'test': datasets.ImageFolder(root=valid_directory, transform=image_transforms['test'])
}
train_data_size = len(data['train'])
valid_data_size = len(data['test'])
train_data = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=0)
valid_data = DataLoader(data['test'], batch_size=batch_size, shuffle=True, num_workers=0)
print(train_data_size, valid_data_size)
class ResdualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(ResdualBlock, self).__init__()
self.conv0 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=1, stride=1, bias=False)
self.bn0 = nn.BatchNorm2d(128)
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, groups=128, bias=False)
self.bn1 = nn.BatchNorm2d(128)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=1, stride=1, bias=False)
self.bn2 = nn.BatchNorm2d(128)
self.conv3 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=2, padding=1, groups=128, bias=False)
self.bn3 = nn.BatchNorm2d(128)
self.conv4 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=1, stride=1, bias=False)
self.bn4 = nn.BatchNorm2d(256)
self.shortcut = nn.Sequential()
if stride != 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels=256, stride=2, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels))
def forward(self, x):
identity = x
out = self.conv0(x)
out = self.bn0(out)
out = self.relu(out)
out = self.conv1(out)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.relu(out)
out = self.conv4(out)
out = self.bn4(out)
out += self.shortcut(identity)
out = self.relu(out)
return out
###开始拼接上下部分,要求图片大小先裁剪为640*640
class Network(nn.Module):
def __init__(self, num_classes=1000):
super(Network,self).__init__()
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
#320*320*32
self.conv6 = nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=3,stride=2,padding=1,groups=32),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
# 320*320*32
self.conv7 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=1, stride=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
#320*320*64
self.conv8 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2,padding=1,groups=64),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
#160*160*64
self.layer1 = self.make_layer(64,256)
self.conv9 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1,groups=256,bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
)
self.conv10 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=1,stride=1,bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
)
self.conv11 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True)
)
#80*80*512
self.avgpool = nn.AdaptiveAvgPool2d((1,1))#1*1*512
self.fc = nn.Linear(512,num_classes)
def make_layer(self, in_channels, out_channels, stride=2):
layer = []
layer.append(ResdualBlock(in_channels,out_channels,stride))
return nn.Sequential(*layer)
def forward(self,x):
out = self.conv5(x)
out = self.conv6(out)
out = self.conv7(out)
out = self.conv8(out)
out = self.layer1(out)
out = self.conv9(out)
out = self.conv10(out)
out = self.conv11(out)
out = self.avgpool(out)
out = torch.flatten(out,1)
out = self.fc(out)
return out
resnet_net = Network()
Network.cuda(resnet_net)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.SGD(resnet_net.parameters(),lr=0.01)
def train_and_valid(model, loss_function, optimizer, epochs=50):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
history = []
best_acc = 0.0
best_epoch = 0
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(tqdm(train_data)):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()
for j, (inputs, labels) in enumerate(tqdm(valid_data)):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_function(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss/train_data_size
avg_train_acc = train_acc/train_data_size
avg_valid_loss = valid_loss/valid_data_size
avg_valid_acc = valid_acc/valid_data_size
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if best_acc < avg_valid_acc:
best_acc = avg_valid_acc
best_epoch = epoch + 1
epoch_end = time.time()
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch+1, avg_valid_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start
))
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
torch.save(model,dataset + '_model_' + str(epoch + 1) + '.pt')
return model, history
num_epochs = 40
trained_model, history = train_and_valid(resnet_net, loss_func, optimizer, num_epochs)
torch.save(history,dataset+'_history.pt')
history = np.array(history)
plt.plot(history[:, 0:2])
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 2)
plt.show()
plt.plot(history[:, 2:4])
plt.legend(['Tr Accuracy', 'Val Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.show()
# 六、使用模型进行预测
# 加载训练好的模型
model = torch.load(dataset+'_model_'+str(num_epochs)+'.pt')
model.eval()
# 定义预测函数
def predict_image(image_path):
image = image_transforms['test'](Image.open(image_path))
image_tensor = image.unsqueeze_(0)
input = image_tensor.to("cuda:0")
output = model(input)
index = output.data.cpu().numpy().argmax()
return index
# 预测新的图像是个啥
from PIL import Image
image_path = r'E:\wingstudio\four\logo_data\test\burger king\ankamall_image_106.jpg'
print("这张图片标签索引是:",predict_image(image_path))
def predict(model, image_path):
# 加载图像并进行预处理
image = Image.open(image_path)
image_tensor = image_transforms['test'](image).float()
image_tensor = image_tensor.unsqueeze_(0)
input = input = image_tensor
# 将输入传递给模型并获取输出
output = model(input.cuda())
# 获取预测结果并转换为类别标签
_, predicted = torch.max(output.data, 1)
class_index = predicted.cpu().numpy()[0]
return data['train'].classes[class_index]
# 预测again
image_path = r'E:\wingstudio\four\logo_data\test\burger king\ankamall_image_106.jpg'
print("这张图片是:", predict(trained_model, image_path))以上就是全部内容了,我还会继续向更加优秀的博主和up主学习,看到这个应该也是真爱粉了,大家一起共勉吧















 2693
2693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









