






今天学长讲了下图,之前自己也看了看图的,那就回顾一下图的知识
1.图分为有向图和无向图,区别如名有无方向。
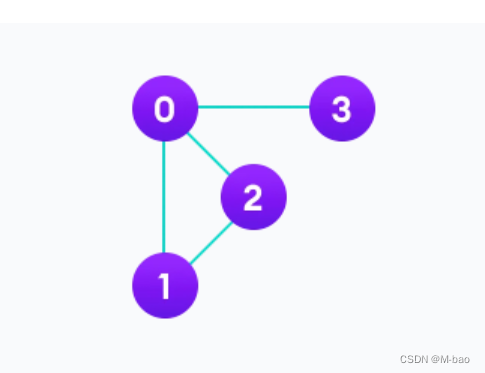 这就是个无向图
这就是个无向图
2.对于图的遍历可以用dfs也可以用bfs
dfs的代码如下
void dfs(Gragh G, int v) { //假设已经创建了一个图的邻接矩阵G ,v是开始访问的顶点
int w;//w是邻接点
cout << G.Vex[v] << endl;
for (w = 0; w < G.vexnum; w++) { //遍历所有顶点
visist[v] = 1; //访问过了标记为真
if (G.Edge[v][w] && !visist[w]) dfs(G, w); //邻接且未被访问过,则递归访问其邻接点bfs
void bfs(Gragh G, int v) {
int u, w;
queue<int>Q;
visist[v] = 1;
cout << G.Vex[v] << endl;
Q.push(v);//顶点v入队
while (Q.empty() == 0) { //如果队列不空
u = Q.front(); //队列的头元素出列赋给u
Q.pop();//队列头元素出队
for (w = 0; w < G.vexnum; w++) {
if (G.Edge[u][w] && !visist[w]) { //u,w邻接且w未被访问过
cout << G.Vex[w] << endl;
visist[w] = 1;
Q.push(w);//领接点加入队列
}
}
}
} 3.还新知道了一个什么邻接表
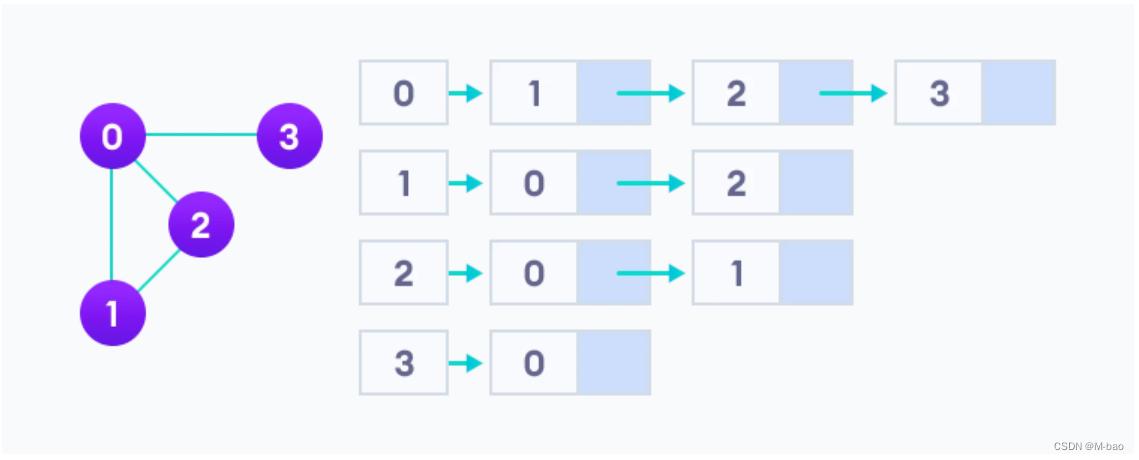
在存储方面,邻接列表从存储空间角度来看是更有效的,因为我们只需要存储边的值。对于一个有数百万个顶点的图来说,这意味着节省了大量的空间。
好像对于邻接表来说一条链先走到底的是bfs而dfs的话就是到后面一个直接跳转到下面的一个。
今天还复习了一下迪杰斯特拉算法,照着啊哈算法敲了一边,大概理清了下思路,明天自己再敲一次巩固下。
#include<bitsdc++.h>
using namespace std;
int main()
{
int e[100][100],i,j,k,n,m,dis[10],book[10],u,v,a,b,c,s=9999;
int min1;
cin>>n>>m;
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
{
if(i==j){e[i][j]=0;}
else e[i][j]=s;
}
for(i=1;i<=m;i++)
{
cin>>a>>b>>c;
e[a][b]=c;
}
for(i=1;i<=n;i++)
{
dis[i]=e[1][i];
}
for(i=1;i<=n;i++)
{
book[i]=0;
}
book[1]=1;
for(i=1;i<=n-1;i++)
{ min1=s;
for(j=1;j<=n;j++)
{
if(book[j]==0&&dis[j]<min1)
{
min1=dis[j];u=j;
}
}
book[u]=1;
for(v=1;v<=n;v++)
{
if(e[u][v]<s)
{
if(dis[v]>dis[u]+e[u][v])
dis[v]=dis[u]+e[u][v];
}
}
}
cout<<dis[n];
getchar();getchar();
return 0;
}















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









