




目录
1 项目背景与目标
1.1 项目简介
本项目源自学校组织的实习培训,由成都某合作机构提供的机票元搜索大数据项目。该项目是一个基于大数据和人工智能技术的综合性项目,旨在整合航空资源、打破信息壁垒,为用户提供快速、智能的航班查找、拼接和价格对比等服务。
项目由四人合作进行,本人主要负责需求分析与可视化设计与实现,因此本文主要进行基于streamlit的BI数据可视化层的介绍与总结。
1.2 数据来源与规模
数据由机构提供,整体上源自Expedia网站 2022-04-16至 2022-10-05的票价查询数据,整体数据量有30G左右,包含多个维度表以及一张包含了查询数据的事实表。其中本项目中主要使用到的其实是是事实表、国家和地区表,机场频率、跑道数据等数据未使用到。

1.3 可视化模块的作用和定位
根据我对我们整体的大数据项目的理解,所谓的大数据其实就是真的是数据量“很大”,主要是使用到Hadoop、HDFS、Spark、Hive、Airflow这些专门适配大数据处理的工具,其实很多的工作都是框架与工作进行了优化处理的,我们做这个项目的其它成员最主要的工作其实也就是写数据的处理逻辑以及Mysql级别的数据库,而大数据的最终目的其实就是获取信息,获取信息的方式可能是通过数据挖掘来提取特殊信息、甚至人工智能来训练提取特征,但是最常见的方式还是画表——也就是做可视化分析。
数据的最终消费者,往往并不是技术人员,而是业务部门、管理者甚至外部用户。他们更关心的并非底层数据长什么样,而是:
- 哪些城市的票价上涨最明显?
- 某家航司的高价策略是否存在?
- 高峰时段的航班密度是怎样的?
- 哪些航线存在潜在的市场机会?
这就决定了可视化模块是大数据价值转化的桥梁。良好的可视化展示是展示大数据分析价值的重要部分,可视化有以下关键的作用:
- 信息提取与模式识别
- 降低使用门槛,提升数据触达效率
- 支撑多维度分析与动态探索
- 成为沟通工具与项目窗口
2 技术选型与架构设计
2.1 系统架构概览
整体大数据系统的架构如下:
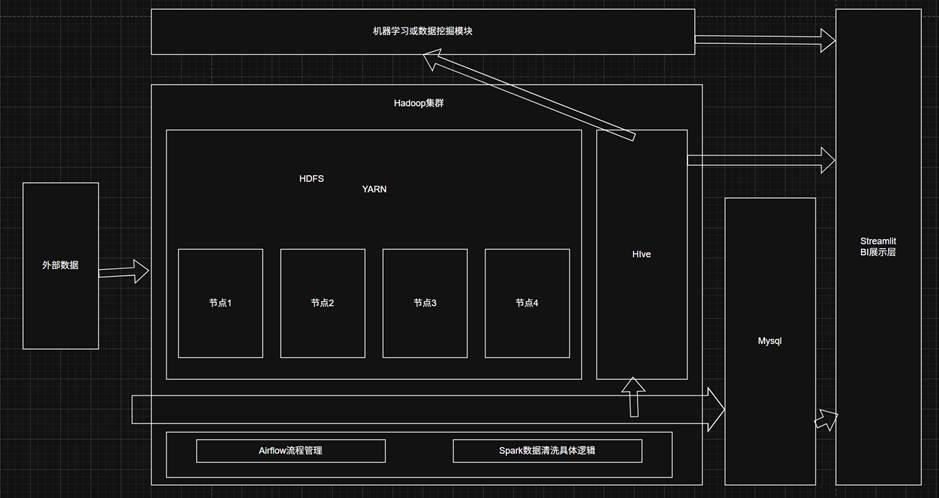
整体的流程是:
Airflow控制管理数据定时读入HDFS->HDFS事实数据通过Hive进行索引->内部Spark基于HDFS和YARN的算力进行数据的处理->计算后的数据存入Mysql->Streamlit优先从mysql使用计算好的数据画表。
需要注意的是,展示层与计算层一般来说是异步的,也就是我们一般直接从Mysql读取,不是事实计算,不关心内部是否在处理数据。一般来说,实际生产中,是一致把数据传入,但是通过Airflow来控制定时给到Spark进行数据的处理,这里所谓的数据处理其实就是计算一些均值、占比等用来画表的数据到Mysql,因为直接读取Hive和实时计算数据都是非常慢的(似乎可以通过ClickHouse解决),所以先把需要的Mysql数据计算好存储又能节约硬盘占用又能提高读取速度。
2.2 可视化框架选择
一般来说,大数据的BI展示主要有完整前后端、工具快速前端两种选择,而搭建一个完整的前后端并不符合我们的小型项目,所以我首要选择现有的工具进行快速搭建。
项目初期我们打算是使用Superset进行快速的搭建,但是在原型搭建时遇到一些问题:
- 远程Hive数据库的连接出现问题,貌似是鉴权的问题
- .最主要的问题是,Superset的最新版本无法实现页面内的交互,也就是一些颗粒度、时间的选择只能使用左侧的过滤器,而页面仪表盘的图表只能是静态表格。这导致我们寻求新的方案-Streamlit。
- 还有一个问题就是其只能通过MapBox来绘制地图,而mapbox需要海外银行卡来注册。
“Streamlit 是一个专为机器学习工程师和数据科学家设计的Python 框架,用于快速构建数据应用和交互式仪表板。核心理念是让数据应用开发像写 Python 脚本一样简单。无需前端知识,就能把数据分析、机器学习模型的结果、甚至是复杂的交互式图表,直接通过简单的 Python 代码呈现在网页上。“
虽然比起Superset来说Streamlit需要更多的编码,使用上较复杂,但是这也带来了更加灵活的选择,我们可以自定义页面、导航、选择,内部还可以集成HTML、Markdown等内容展示方式,而且由于可以自行编码,远程连接数据库、机器学习服务器等也更加方便。
2.3 前端架构
整体前端采用分层架构,主要包含展示层和数据层,展示层主要进行图表绘制和页面展示的真“前端”,而数据层用于从数据库取出数据进行初步的格式转化再提供给展示层使用。
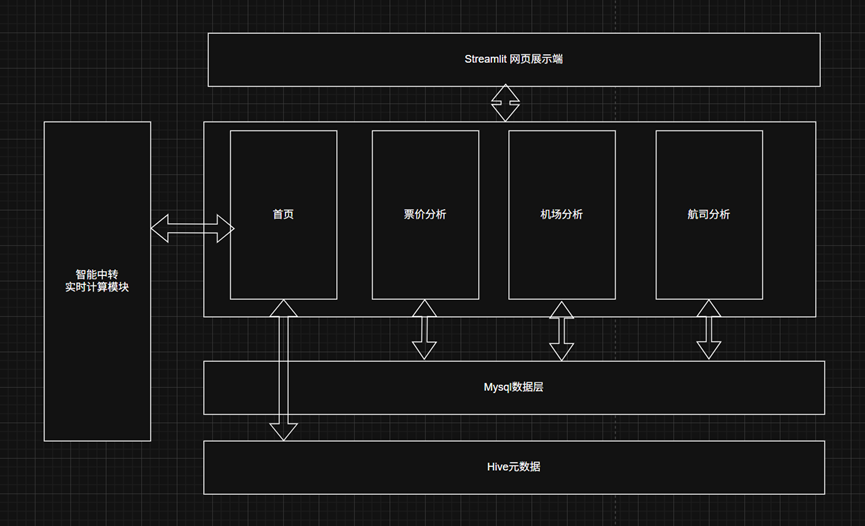
3 功能模块设计
本机票元搜索平台的功能设计围绕用户的核心需求,提供了航班方案查询和多维度可视化分析两大核心模块,通过直观的交互和丰富的图表,辅助用户进行数据洞察和决策。
主要设计的四个页面分别是:
- 首页:主要是展示机票元数据,也就是类似购票软件的机票查询。
- 票价分析:针对航班的票价进行深入的图表分析。
- 城市机场分析:主要以城市(机场)为中心维度进行分析。
- 航司分析:注重对航司相关内容的具体可视化。
3.1 首页 Home
3.1.1 设计目标
提供一个简洁、高效的航班搜索入口,满足用户快速获取特定航班信息的需求。用户能够通过首页查看某个时间段内某个航段的机票信息,提供详细的航班尤其是中转信息的展示,同时通过地图绘制飞行图。
3.1.2 核心功能
- 航班搜索:用户可输入出发城市(支持模糊搜索/下拉选择)、到达城市、出发日期区间、舱位、预算等信息。
- 结果展示:以“航班卡片”形式展示关键信息,包括城市路径、机场路径、起飞/到达时间、价格、是否中转、航司、舱位、总时长等 。
- 高级筛选与排序:支持按票价、起飞时间升降序排序 ,以及按舱位(经济舱、商务舱、头等舱)和中转类型(全部、直飞)进行筛选 。
- 详细信息查看:点击“更多信息”可查看具体航段的舱位、机型、航司等详情 。
- 航线地图展示:根据所选出发地和目的地,绘制直观的航线地图 。
3.1.3 设计要点
注重用户体验的直观性和操作的便捷性,对于最近查询的数据进行缓存以提高查询效率 。同时需要考虑元数据查询的性能效率。
3.2 票价分析模块
3.2.1 设计目标:
通过多维度的时间和价格分析,帮助用户理解机票价格的趋势和分布,辅助购票决策。
3.2.2 核心功能:
3.2.2.1 票价趋势分析:
票价趋势分析主要帮助用户分析合适买票最便宜,可能是一年某个月、一个月的某个周、一周的某天、一天的某个小时票价最低。同时帮助分析票价低的原因。
- 航线选择:通过选择框进行触发与到达城市的选择。
- 折线图趋势展示:以折线图形式直观展示,并支持悬浮查看具体数据 。
- 多颗粒度展示:提供多种维度、颗粒度组合的展示:年-月、年-周、周-日、日-小时
- 集成智能预测:提供原始数据的趋势展示,同时提供人工智能的趋势预测
要点:
- 年-月、年-周趋势表可以通过同一张图选择来切换
- 需要考虑数据只有4-10月的问题,对于缺失数据:头尾则直接截取、中间则跳过,便于图形美观展示。
3.2.2.2 票价分布分析:
该功能主要帮助用户分析航段的票价分布情况,一般来说正态分布是一个合理的分布,同时提供预算选择与概率的计算。
- 价格分布图:统计前面所选航段,展示该行段的韩版票价分布情况。
- 预算计算:根据用户设定的预算,计算对应预算的购票成功率。
要点:
- 票价的选择以固定步长进行滑动选择,固定的步长便于Mysql数据的存储。
- 预算选择默认选择最大值,然后再自行滑动选择,避免预设预算值过大。
3.2.2.3 票价热力图:
热力图直观展示主要数据城市间的票价情况。
- 热力图:热力图为触发-到达的有向热力图,需要考虑方向,以价格为热力指标
- 详细数据展示:悬浮展示具体方向和价格。
要点:
1.同机场到通机场或者同城市内的机场一般没数据,注意处理票价为0.
3.3 城市分析模块
3.3.1 设计目标:
从地理维度和机场运营角度深入分析航班数据,揭示城市间的航线热度和机场繁忙程度。
3.3.2 核心功能:
3.3.2.1 城市航线热力图:
航线热力图主要展示航线的繁忙程度。
- 航线热力图:通过地图、颜色深度展示航线繁忙程度。
- 中转城市展示:不仅展示主要城市的直飞航线,中转城市航线也包含。
3.3.2.2 城市税费与票价排名:
- 税费排行:计算并展示各城市作为出发地的平均税费排名(支持绝对值或比率排名)。
- 根据城市作为出发或到达地的平均票价进行排名(柱状图展示)。
3.3.2.3 热门城市词云:
统计作为目的地的航班到达次数,以词云图形式展示最热门城市,字体大小反映热门程度 。配合航线热力图分析热门城市。
3.3.2.4 单机场分析:
聚焦特定机场,展示其航班吞吐量的双折线图(按月/周颗粒度)。以及显示到达该机场最多的7个城市的排名 。可以帮助分析城市一年的航班变化、分析淡旺季,到达排名帮助分析
3.4 航司分析模块
3.4.1 设计目标:
聚焦航空公司维度,分析各航司的市场表现、价格策略和机型分布。
3.4.2 核心功能:
3.4.2.1 航司票价排名:
柱状图按照顺序展示各航空公司平均票价的排名,进行横向对比 。
3.4.2.2 航司份额:
统计各航空公司的航班数排名,并绘制饼图展示市场份额占比 。
3.4.2.3 机型份额:
统计各机型的航班数排名,并展示前15个机型的横向对比,绘制饼图展示份额 。
3.4.2.4 航司价格走势分析:
用户选择一家或两家航空公司进行对比 。展示选定航司在年-月、年-周、周-日、日-小时等时间维度上的价格变化趋势,支持双折线图对比 。
4 工程与开发实践
本段以我实际开发流程为例说明展示
4.1 整体页面结构搭建
整体四个页面,页面间需要进行相互导航。
页面根目录写下app.py模块负责项目入口和路由控制
import streamlit as st
from mypages import home, price_analysis, city_analysis, airline_analysis
# 页面设置
st.set_page_config(page_title="航班分析系统", layout="wide")
# 导航栏
PAGES = {
"首页": home,
"票价分析": price_analysis,
"城市机场分析": city_analysis,
"航司分析": airline_analysis
}
st.sidebar.title("导航")
page = st.sidebar.radio("NVG", list(PAGES.keys()))
# 页面渲染
PAGES[page].app()
同时配置下面文件目录和文件,需要注意的是,这里的mypages最好不要使用pages作为文件夹,否则Streamlit会自动构造小字导航与上面设置的导航冲突,此外上面PAGES字典设置的盗汗需要与页面模块对应。
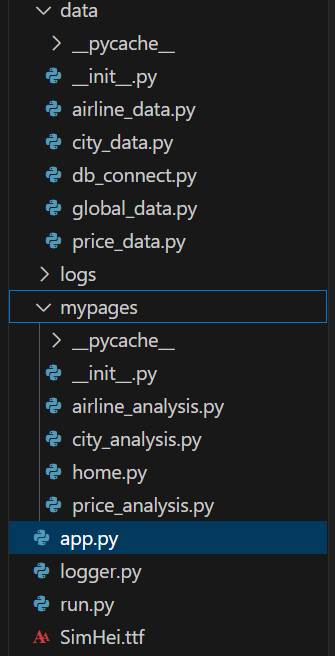
目录结构说明:
>data:数据层文件夹,负责数据库连接和数据加载以及初处理
>logs:日志文件存储
>mypages:展示层文件夹,负责前端页面的编写
app.py:前端入口与路由管理
logger.py:日志定义与实例化模块
run.py:执行文件,主要用于执行命令行命令来启动前端服务器
4.2 Mock数据页面敏捷开发
搭建好整体的架构后,开始进行页面的编写,需要注意的是,在当时做项目时我们是并行开发的,也就是统一设计好大概的页面图表,然后数据处理端先进行初步的清洗和Airflow流程编写和一些基础的数据的计算,同时我先把整体的页面进行编写,再最后确认需要的数据表格。因此初期搭建页面是没有真实数据的,所以此时我们就需要mock数据。
Mock数据其实就是在数据层把应该是从数据库读取的逻辑改成通过一些集合、数组、随机数来生成数据。
下面以票价分析为例展示早期模拟数据开发
4.2.1 展示层搭建
4.2.1.1 页面布局
我们设计布局为:
最上层两个下拉条选择出发与到达城市,往下以3:2:2的占比防止年-月(周)趋势变化图、周-日、日-小时三个趋势图;再往下为1:1比例的分布图和热力图。

Streamlit的布局处理主要为横向的管理,通过colums来进行块的横向比例划分和块的定义,而纵向比例则通过图表块的高度来控制,例:
城市选择栏:
这里通过selectbox来进行内容的选择,同时selectbox能够通过文字输入来匹配内容
col_dep, col_arr = st.columns(2)
with col_dep:
dep_city = st.selectbox("出发机场", ["全部"] + all_cities, index=0)
with col_arr:
arr_city = st.selectbox("到达机场", ["全部"] + all_cities, index=0)
三张趋势图:
col_main, col_dow, col_hour = st.columns([3, 2, 2])
#月\周平均票价趋势图
with col_main:
……
#一周票价变化趋势
with col_dow:
……
#每日小时票价趋势
with col_hour:
4.2.1.2 具体图表
下面以月\周平均票价趋势图为例:
我们预设的效果是这样的:图表上方为标题行,同时为了避免颗粒度选择额外占据一行,其与标题并列,下方图表则是一个折线图。
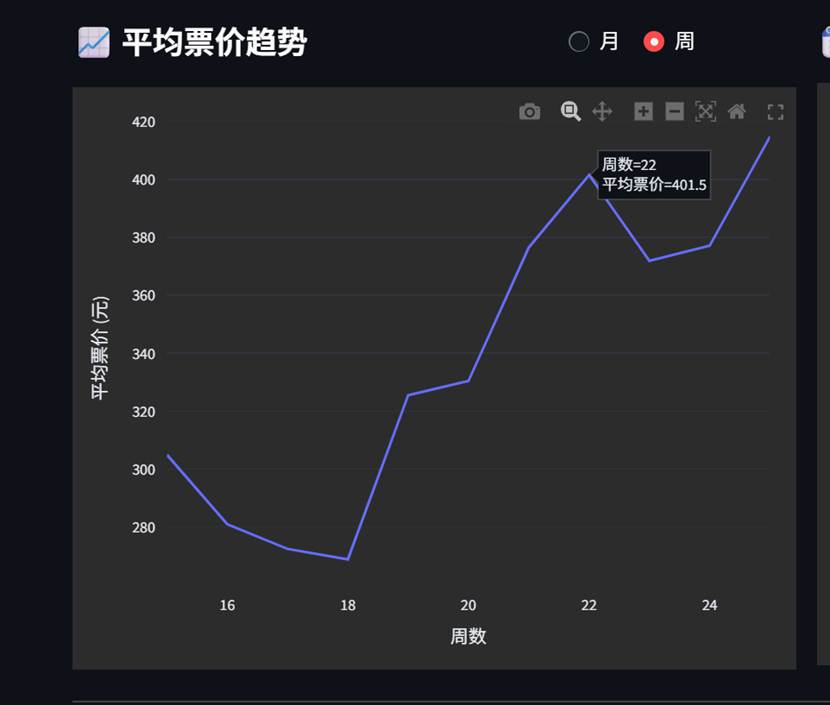
类似处理整体的横向关系,我们通过st.colums实现整体比例控制:
title_col, spacer_col, radio_col = st.columns([4, 1, 3])
with title_col:
st.markdown("#### \U0001F4C8 平均票价趋势")
with radio_col:
granularity = st.radio("颗粒度", ["月", "周"], horizontal=True, label_visibility="collapsed", key="gran")
这里通过radio来进行按钮的选择,捕获一个granularity值来给后面获取数据进行选择。目前来说,我们以及由页面最上方的出发与到达城市得到了起始地和目的地,现在又得到了颗粒度,就可以进行数据的获取了,这里就需要使用数据层定义的函数:
df_main = get_monthly_or_weekly_trend(dep_city, arr_city, granularity)
展示曾不需要考虑这个其如何获取数据,只需要关注得到的数据格式,接下来我们就可以画表了:
if granularity == "月":
df_main.rename(columns={"month_of_year": "月份", "avgTotalFare": "平均票价"}, inplace=True)
else:
df_main.rename(columns={"week_of_year": "周数", "avgTotalFare": "平均票价"}, inplace=True)
x_col = "月份" if granularity == "月" else "周数"
fig_main = px.line(df_main, x=x_col, y="平均票价", template='plotly_dark')
fig_main.update_layout(
xaxis_title=x_col,
yaxis_title="平均票价 (元)",
font=dict(color="white"),
margin=dict(t=20, b=20, l=20, r=20),plot_bgcolor='#2c2c2c', paper_bgcolor='#2c2c2c', font_color='white'
)
st.plotly_chart(fig_main, use_container_width=True, height=280)
其中:
-
- 前面granularity的处理主要是根据选择的颗粒度进行表列的重命名配合折线图展示。
- px.line()是Plotly Express库中用于生成折线图的函数,其中表示使用df_main为数据源,x坐标为x_col,y坐标为重命名后的“平均票价”,表格主题为'plotly_dark'深色主题
- fig_main.update_layout()用于更新整体布局,其中先是横纵坐标确认、font为字体设置、margin为图表四个方向的间隔、然后是三个颜色设置,目前来看其实有重复。
- 最终通过st.plotly_chart()来把图表渲染到Streamlit的app中,而height就是前面所说的图表块的高度控制。
这样就完成了一个图表,其它的柱状图、地图等会后面详细说明。
4.2.2 数据层模拟
根据上面的图,其实可以看出,就是需要一个dataframe对象,主要包含两列数据,一个是月(周)数,一个是票价,由此我们就可以完成上面的get_monthly_or_weekly_trend(dep_city, arr_city, granularity)函数:
def get_monthly_or_weekly_trend(dep_city, arr_city, granularity):
cities = get_city_list()
data = []
for time_unit in range(1, 13) if granularity == "月" else range(1, 53):
for dep in cities:
for arr in cities:
if dep != arr:
if dep_city != "全部" and dep != dep_city:
continue
if arr_city != "全部" and arr != arr_city:
continue
data.append({
"出发城市": dep,
"到达城市": arr,
"{}".format("月份" if granularity == "月" else "周数"): time_unit,
"平均票价": np.random.randint(400, 1800)
})
return pd.DataFrame(data).groupby(
"月份" if granularity == "月" else "周数"
)["平均票价"].mean().reset_index()
需要注意的是,目前mock的数据是以国内的城市来处理,最后面都会换成真实的美国的三十五个主要城市十六个主要机场的数据。
4.3 数据库接入
完成整体页面的搭建后,数据处理部分也基本完成了初步的数据处理,我们可以开始进行数据库的接入和针对性的优化了
4.3.1 数据库连接定义
本项目中主要用到了两个远程数据库:Mysql和Hive,其中Mysql主要用于三个大分析模块的计算好的数据,而Hive主要是首页的机票原始数据需要用到。
数据库的连接主要就是要考虑两个问题:连接与查询。无论是mysql还是hive的连接其实都是需要ip、端口、账号、数据库这些信息,而包括hive查询都可以使用sql语句,下面是具体实现:
class ConnectMySQL:
def __init__(self):
mysql_conf = {
"host": "192.168.101.219",
"port": 3306,
"user": "linux",
"password": '123',
"database": "hive"
}
# 创建SQLAlchemy连接引擎
self.engine = create_engine(f"mysql+pymysql://{mysql_conf['user']}:{mysql_conf['password']}@{mysql_conf['host']}:{mysql_conf['port']}/{mysql_conf['database']}")
self.conn = pymysql.connect(**mysql_conf, charset='utf8')
self.cursor = self.conn.cursor(cursor=pymysql.cursors.DictCursor)
def close(self):
self.cursor.close()
sel 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









