







🌈🌈🌈往期内容精选:
💖【数学建模】数据拟合与插值技术全解析:从线性插值到Logistic模型实战-CSDN博客
💖【数学建模】熵权法——基于2021全国大学生数学建模C题供应商评价数学建模实战-CSDN博客
💖基于PyTorch的MLP模型的MNIST手写数字识别的Python代码-CSDN博客
主成分分析(PCA)详解:从理论到实践的全面指南
💖引言
在数据科学和经济学研究中,我们常面临高维数据(如各省市的GDP、消费水平、固定资产投资等指标)的分析难题。高维数据不仅增加了计算复杂度,还可能存在多重共线性和信息冗余。主成分分析(PCA)通过降维技术,将多个相关变量转化为少数几个独立的主成分,保留数据核心信息,简化分析流程。例如,通过PCA可从20个经济指标中提取4个主成分,解释85%以上的原始数据方差,助力决策者快速识别区域经济差异。
📚一、主成分分析(PCA)
🚀1.1、概念
PCA(Principal Components Analysis)即主成分分析技术[1],又称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。 在统计学中,主成分分析PCA是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用于减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。
🚀1.2、应用场景
- 数据降维:通过正交变换保留高方差主成分,将高维数据映射至低维空间,实现信息高效浓缩,便于可视化,理解数据特征。
- 噪声消除:剔除低方差主成分(通常为尾部成分),过滤噪声与冗余信息,保留数据核心特征。
- 多重共线性消除:当多个特征之间存在较高的相关性时,生成不相关的主成分,解决共线性问题,增强模型鲁棒性。
🚀1.3、使用条件
任何方法都有适用条件,PCA也不例外。
-
异常值考虑:
PCA基于数据的方差和协方差来确定主成分的方向。异常值会极大地影响数据的方差和协方差结构,导致主成分方向偏移,无法准确反映数据的真实结构。 -
线性程度检验(二选一即可):
- KMO检验:
KMO值需 > 0.6(0.8-0.9为理想范围)。 - Bartlett球形检验:需拒绝原假设(P值<0.05),表明变量间存在显著相关性。
- KMO检验:
注意事项:PCA适合处理线性结构数据,若数据存在复杂非线性关系,需结合核方法(Kernel PCA)或者考虑使用t-SNE等降维方法。
📚二、数学原理
- 1、假设有 n 个样本,m 个指标,则可构成大小为 n × n 的样本矩阵 x:
x = [ x 11 x 12 ⋯ x 1 m x 21 x 22 ⋯ x 2 m ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n m ] = ( x 1 , x 2 , ⋯ , x m ) \mathbf{x} = \begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1m} \\ x_{21} & x_{22} & \cdots & x_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{nm} \end{bmatrix} = (\mathbf{x}_1, \mathbf{x}_2, \cdots, \mathbf{x}_m ) x= x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1mx2m⋮xnm =(x1,x2,⋯,xm)
-
2、对数据进行列标准化后,求协方差矩阵:
- 标准化
按列计算均值:
x
ˉ
j
=
1
n
∑
i
=
1
n
x
i
j
,
\quad \bar{x}_j = \frac{1}{n} \sum_{i=1}^{n} x_{ij},
xˉj=n1i=1∑nxij,
标准差:
S
j
=
∑
i
=
1
n
(
x
i
j
−
x
ˉ
j
)
2
n
−
1
\quad \quad S_j = \sqrt{\frac{\sum_{i=1}^{n} (x_{ij} - \bar{x}_j)^2}{n-1}}
Sj=n−1∑i=1n(xij−xˉj)2
标准化数据:
X
i
j
=
x
i
j
−
x
ˉ
j
S
j
\quad \quad X_{ij} = \frac{x_{ij} - \bar{x}_j}{S_j}
Xij=Sjxij−xˉj
公式原始样本矩阵经过标准化变化:
X
=
[
X
11
X
12
⋯
X
1
n
X
21
X
22
⋯
X
2
m
⋮
⋮
⋱
⋮
X
n
1
X
n
2
⋯
X
n
m
]
=
(
X
1
,
X
2
,
⋯
,
X
m
)
\quad \mathbf{X} = \begin{bmatrix} X_{11} & X_{12} & \cdots & X_{1n} \\ X_{21} & X_{22} & \cdots & X_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ X_{n1} & X_{n2} & \cdots & X_{nm} \end{bmatrix} = (\mathbf{X}_1, \mathbf{X}_2, \cdots, \mathbf{X}_m)
X=
X11X21⋮Xn1X12X22⋮Xn2⋯⋯⋱⋯X1nX2m⋮Xnm
=(X1,X2,⋯,Xm)
- 计算协方差
计算标准化样本的协方差矩阵:
R
=
[
r
11
r
12
⋯
r
1
m
r
21
r
22
⋯
r
2
m
⋮
⋮
⋱
⋮
r
m
1
r
m
2
⋯
r
m
m
]
\mathbf{R} = \begin{bmatrix} r_{11} & r_{12} & \cdots & r_{1m} \\ r_{21} & r_{22} & \cdots & r_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ r_{m1} & r_{m2} & \cdots & r_{mm} \end{bmatrix}
R=
r11r21⋮rm1r12r22⋮rm2⋯⋯⋱⋯r1mr2m⋮rmm
r i j = 1 n − 1 ∑ k = 1 n ( X k i − X ˉ i ) ( X k j − X ˉ j ) = 1 n − 1 ∑ k = 1 n X k i X k j r_{ij} = \frac{1}{n-1} \sum_{k=1}^{n} (X_{ki} - \bar{X}_i)(X_{kj} - \bar{X}_j) = \frac{1}{n-1} \sum_{k=1}^{n} X_{ki} X_{kj} rij=n−11k=1∑n(Xki−Xˉi)(Xkj−Xˉj)=n−11k=1∑nXkiXkj
也可以直接计算:
R
=
∑
k
=
1
n
(
x
k
i
−
x
ˉ
i
)
(
x
k
j
−
x
ˉ
j
)
∑
k
=
1
n
(
x
k
i
−
x
ˉ
i
)
2
∑
k
=
1
n
(
x
k
j
−
x
ˉ
j
)
2
\mathbf{R} = \frac{\sum_{k=1}^{n} (x_{ki} - \bar{x}_i)(x_{kj} - \bar{x}_j)}{\sqrt{\sum_{k=1}^{n} (x_{ki} - \bar{x}_i)^2 \sum_{k=1}^{n} (x_{kj} - \bar{x}_j)^2}}
R=∑k=1n(xki−xˉi)2∑k=1n(xkj−xˉj)2∑k=1n(xki−xˉi)(xkj−xˉj)
-
3、计算 R 的特征值和特征值向量:
-特征值
λ 1 ≥ λ 2 ≥ ⋯ ≥ λ p ≥ 0 , \lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_p \geq 0, λ1≥λ2≥⋯≥λp≥0,
R 是半正定矩阵,且tr ( R ) = ∑ k = 1 p λ k = p \quad \mathbf{R} \text{是半正定矩阵,且} \text{tr}(\mathbf{R}) = \sum_{k=1}^{p} \lambda_k = p R是半正定矩阵,且tr(R)=k=1∑pλk=p
表示矩阵的迹等于其特征值之和,且这个和等于 p。R 是一个半正定矩阵,其特征值不可能为负。
特征向量: a 1 = [ a 11 a 21 ⋮ a p 1 ] , a 2 = [ a 12 a 22 ⋮ a p 2 ] , ⋯ , a p = [ a 1 p a 2 p ⋮ a p p ] \text{特征向量:} \mathbf{a}_1 = \begin{bmatrix} a_{11} \\ a_{21} \\ \vdots \\ a_{p1} \end{bmatrix}, \mathbf{a}_2 = \begin{bmatrix} a_{12} \\ a_{22} \\ \vdots \\ a_{p2} \end{bmatrix}, \cdots, \mathbf{a}_p = \begin{bmatrix} a_{1p} \\ a_{2p} \\ \vdots \\ a_{pp} \end{bmatrix} 特征向量:a1= a11a21⋮ap1 ,a2= a12a22⋮ap2 ,⋯,ap= a1pa2p⋮app
- 4、计算主成分贡献率率以及累计贡献率:
贡献率
=
λ
i
∑
k
=
1
p
λ
k
\text{贡献率} = \frac{\lambda_i}{\sum_{k=1}^{p} \lambda_k}\quad
贡献率=∑k=1pλkλi
累加贡献率
=
∑
k
=
1
i
λ
k
∑
k
=
1
p
λ
k
,
(
i
=
1
,
2
,
⋯
,
p
)
\text{累加贡献率} = \frac{\sum_{k=1}^{i} \lambda_k}{\sum_{k=1}^{p} \lambda_k}, \quad (i = 1, 2, \cdots, p)
累加贡献率=∑k=1pλk∑k=1iλk,(i=1,2,⋯,p)
注意:相关系数是协方差的标准化形式,用于消除量纲的影。
- 5、写出主成分:
一般取累计贡献率超过 90% 的特征值所对应的第一、第二、…、第 m(m ≤ p )个主成分。
第 i 个主成分: F i = a 1 i X 1 + a 2 i X 2 + ⋯ + a p i X p \text{第 } i \text{ 个主成分:} F_i = a_{1i} X_1 + a_{2i} X_2 + \cdots + a_{pi} X_p 第 i 个主成分:Fi=a1iX1+a2iX2+⋯+apiXp
📚三、案例分析:各省市自治区经济发展
本文以各省市自治区经济发展数据如下图作为案例,分析PCA降维方法的使用。为方便复现结尾提供了数据下载链接。

🚀3.1、结果展示
📘3.1.1、使用python计算代码过程
检验结果和协方差矩阵展示,运行第一个代码块即可得到结果

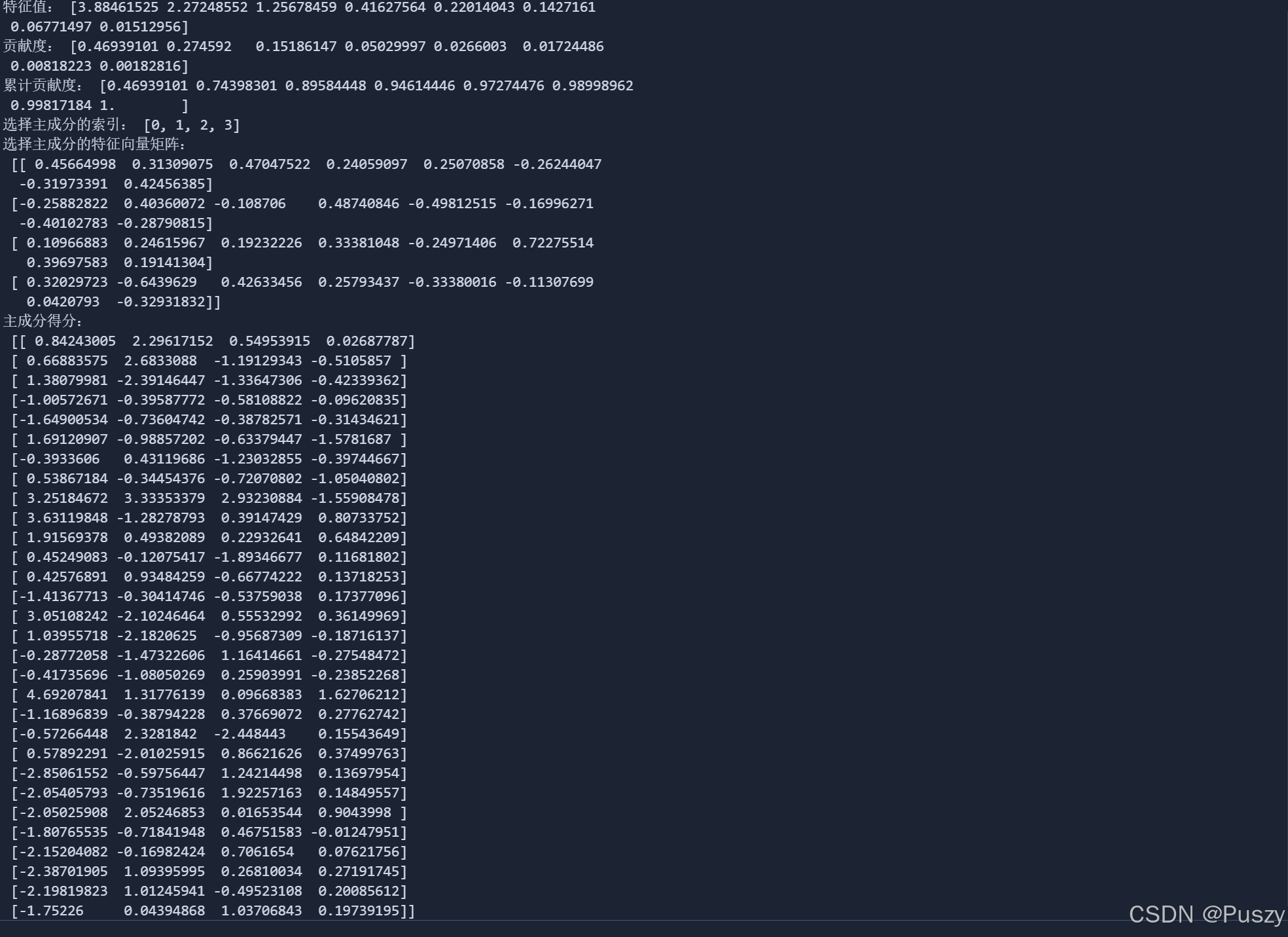
主成分分析后的结果展示,运行代码块2后可以得到

📘3.2.2、使用sklearn库代码简化过程
🚀3.2、代码展示
📘3.2.1、使用python计算代码过程代码展示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
from factor_analyzer.factor_analyzer import calculate_kmo
from sklearn.preprocessing import StandardScaler
# 读取数据
data = pd.read_excel('./data/表1 各省市自治区经济发展数据.xlsx')
data.dropna(inplace=True)
data
# 数据预处理
data = data.drop(['Unnamed: 0'], axis=1)
# 适合性检验(Bartlett && KMO
df_check = data
# Bartlett 球状检验
chi_square_value, p_value = calculate_bartlett_sphericity(df_check)
print("Bartlett=", chi_square_value, p_value)
# KMO检验(>0.6为好,越靠近1越好)
kmo_all, kmo_model = calculate_kmo(df_check)
print("KMO=", kmo_all)
# 主成分分析
#标准化
data = data.apply(lambda x: (x - x.mean()) / x.std(), axis=0)
scaler=StandardScaler()
nor_data=scaler.fit_transform(data)
#相关系数矩阵
nor_data= pd.DataFrame(nor_data)
nor_cor_data=nor_data.corr()
nor_cor_data
#求相关系数矩阵的特征值和特征向量
nor_cor_data=nor_cor_data.values
featValue, featVec= np.linalg.eig(nor_cor_data.T) #求解系数相关矩阵的特征值和特征向量
featValue, featVec
#对特征值进行排序
featValue = sorted(featValue)[::-1]
print('特征值',featValue)
#求特征值的贡献度
print(np.sum(featValue))
gx = featValue/np.sum(featValue)
print('贡献度',gx)
#求特征值的累计贡献度
lg = np.cumsum(gx)
print('累计贡献度',lg)
#选出主成分
#设置阈值
line=0.95
k=[i for i in range(len(lg)) if lg[i]<=line]
k = list(k)
print('选择主成分的索引',k)
#选出主成分对应的特征向量矩阵
selectVec = np.matrix(featVec.T[k]).T
selectVec=selectVec*(-1)
print('选择主成分的特征向量矩阵',selectVec)
#求主成分的得分
finalData = np.dot(nor_data,selectVec)
print('主成分得分',finalData)
📘3.2.2、使用sklearn库代码简化过程
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 读取数据
data = pd.read_excel('./data/表1 各省市自治区经济发展数据.xlsx')
data.dropna(inplace=True)
# 数据预处理
data = data.drop(['Unnamed: 0'], axis=1)
# 标准化
scaler = StandardScaler()
nor_data = scaler.fit_transform(data)
# 主成分分析
pca = PCA()
pca.fit(nor_data)
# 输出结果
print("特征值:", pca.explained_variance_)
print("贡献度:", pca.explained_variance_ratio_)
print("累计贡献度:", pca.explained_variance_ratio_.cumsum())
# 选择主成分(假设选择累计贡献度达到 95% 的主成分)
line = 0.95
k = [i for i, cum_var in enumerate(pca.explained_variance_ratio_.cumsum()) if cum_var <= line]
print("选择主成分的索引:", k)
# 获取主成分的特征向量
selectVec = pca.components_[:len(k)]
print("选择主成分的特征向量矩阵:\n", selectVec)
# 计算主成分得分
finalData = pca.transform(nor_data)[:, :len(k)]
print("主成分得分:\n", finalData)
📚参考链接
清风数学建模学习笔记——主成分分析(PCA)原理详解及案例分析_x10为生均教育经费对以上指标数据做主成分分析,并提取主成分-CSDN博客



















 4913
4913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











