







数学建模笔记—— 主成分分析
主成分分析
1. 基本原理
在实际问题研究中,多变量问题是经常会遇到的。变量太多,无疑会增加分析问题的难度与复杂性,而且在许多实际问题中,多个变量之间是具有一定的相关关系的。因此,人们会很自然地想到,能否在相关分析的基础上,用较少的新变量代替原来较多的旧变量,而且使这些较少的新变量尽可能多地保留原来变量所反映的信息?
一个简单的例子:
例如,某人要做一件上衣要测量很多尺寸,如身长、袖长、胸围、腰围、肩宽、肩厚等十几项指标,但某服装厂要生产一批新型服装绝不可能把尺寸的型号分得过多?
我们可以把多种指标中综合成几个少数的综合指标,做为分类的型号,将十几项指标综合成3项指标,一项是反映长度的指标,一项是反映胖瘦的指标,一项是反映特殊体型的指标。
1.1 主成分分析方法
在分析研究多变量的课题时,变量太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,将重复的变量(关系紧密的变量)删去多余,建立尽可能少的新变量,使得这些新变量是两两不相关的,且这些新变量在反映课题的信息方面尽可能保持原有的信息。设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上用来降维的一种方法。
1.2 数据降维
降维是将高维度的数据(指标太多)保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。
降维优点:
- 使得数据集更易使用
- 除噪声
- 降低算法的计算开销
- 使得结果容易理解
1.3 主成分分析原理
PCA的主要目标是将特征维度变小,同时尽量减少信息损失。就是对一个样本矩阵,**一是换特征,**找一组新的特征来重新标识;**二是减少特征,**新特征的数目要远小于原特征的数目。
通过PCA将n维原始特征映射到k维(k<n)上,称这k维特征为主成分。需要强调的是,不是简单地从n维特征中去除其余n-k维特征,而是重新构造出全新的k维正交特征,且新生成的k维数据尽可能多地包含原来n维数据的信息。例如,使用PCA将20个相关的特征转化为5个无关的新特征,并且尽可能保留原始数据集的信息。
怎么找到新的维度呢?实质是数据间的方差够大,通俗地说,就是能够使数据到了新的维度基变换下,坐标点足够分散,数据间各有区分。
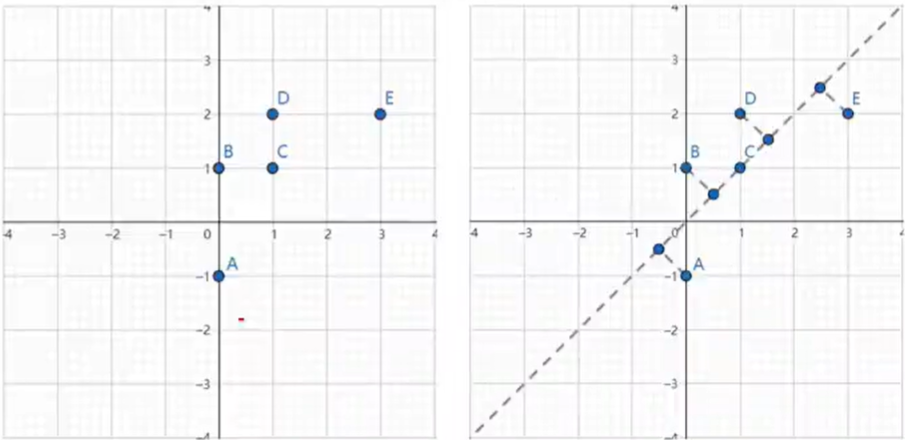
如图所示的左图中有5个离散点,降低维度,就是需要把点映射成一条线。将其映射到右图中黑色虚线上则样本变化最大,且坐标点更分散,这
条黑色虚线就是第一主成分的投影方向。
PCA是一种线性降维方法,即通过某个投影矩阵将高维空间中的原始样本点线性投影到低维空间,以达到降维的目的,线性投影就是通过矩阵变换的方式把数据映射到最合适的方向。
降维的几何意义可以理解为旋转坐标系,取前k个轴作为新特征。
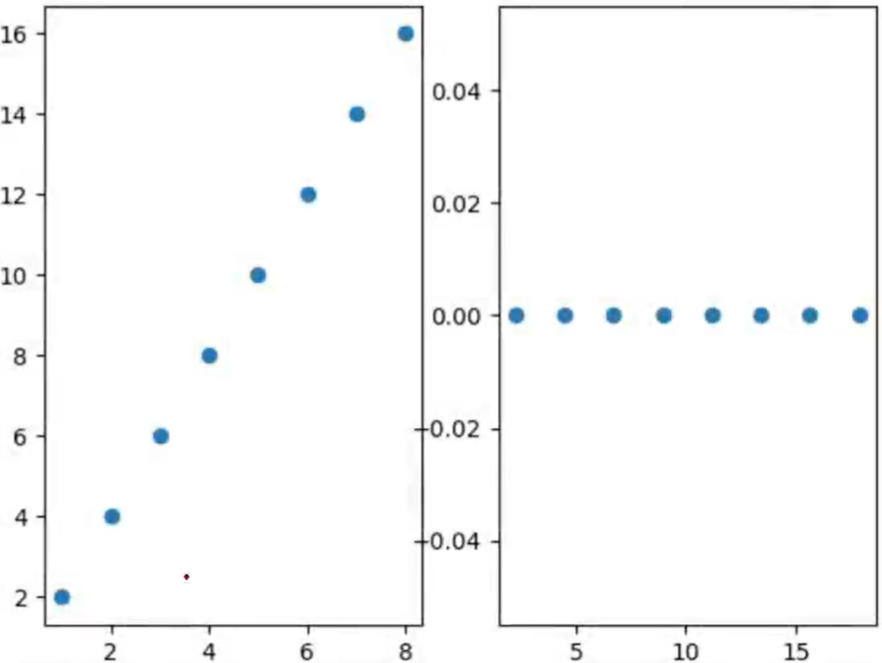
对于下图所示的情况,我们发现这些数据都几乎排列在一条直线上,并且在x轴方向和y轴方向的方差都比较大。但是如果把坐标轴旋转一定角度,使得这些数据在某个坐标轴的投影的方差比较大,便可以用新坐标系下方差较大的一个坐标轴坐标作为主成分。对于左图,数据为(1,2)、(2,4)…旋转坐标轴后,坐标为 ( 5 , 0 ) 、 ( 2 5 , 1 ) … … (\sqrt5,0)、\begin{pmatrix}2\sqrt5,1\end{pmatrix}\ldots\ldots (5,0)、(25,1)……这样主成分就是新坐标系下变量 x x x的数值 5 、 2 5 . . . . . . \sqrt{5}、2\sqrt{5}...... 5、25......
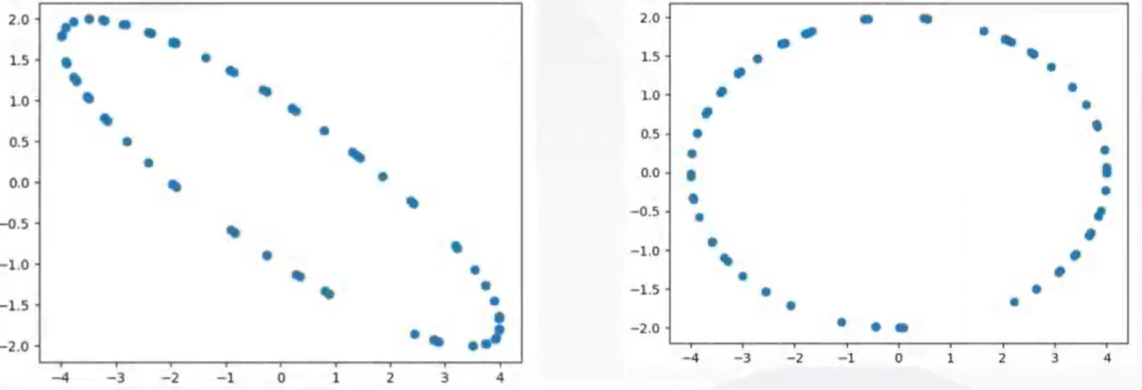
对于大多数情况,数据各个变量基本服从正态分布,所以变量为2的数据散点分布大致为一个椭圆,变量为3的散点分布大致为一个椭球,p个变量的数据大致分布在一个超椭圆。而通过旋转坐标系,使得超椭圆的长轴落在一个坐标轴上,其次超椭圆另一个轴也尽量落在坐标轴上。这样各个新的坐标轴上的坐标值便是相应的主成分。
例如,对于图示的数据,在x轴和y轴的方差都很大,所以可以旋转坐标系,使得椭圆两个轴尽量落在坐标轴上。这样,我们便以散点在新坐标系下的x坐标作为第一主成分(因为x方向方差最大),y轴的坐标为第二主成分。
主成分分析的理论推导较为复杂,需要借助投影寻踪,构造目标函数等方法来推导,在多元统计的相关书籍中都有详细讲解。但是其结论却是十分简洁。所以,如果只是需要实际应用,了解主成分分析的基本原理与实现方法便足够了。
降维的代数意义可以理解为:
m × n m\times n m×n阶的原始样本 X X X,与 n × k n\times k n×k阶矩阵 W W W做矩阵乘法运算 X × W X\times W X×W,即可得到 m × k m\times k m×k阶低维矩阵 Y Y Y,这里的 n × k n\times k n×k阶矩阵 W W W就是投影矩阵。
1.4 主成分分析思想
假设有 n n n个样本, p p p个指标,则可构成大小为 n × p n\times p n×p的样本矩阵 x : x: x:
x = [ x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n p ] = ( x 1 , x 2 , ⋯ , x p ) x=\begin{bmatrix}x_{11}&x_{12}&\cdots&x_{1p}\\x_{21}&x_{22}&\cdots&x_{2p}\\\vdots&\vdots&\ddots&\vdots\\x_{n1}&x_{n2}&\cdots&x_{np}\end{bmatrix}=\begin{pmatrix}x_1,x_2,\cdots,x_p\end{pmatrix} x=
x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1px2p⋮xnp
=(x1,x2,⋯,xp)
假设我们想找到新的一组变量 z 1 , z 2 , ⋅ ⋅ ⋅ , z m ( m ≤ p ) z_1,z_2,\cdotp\cdotp\cdotp,z_m(m\leq p) z1,z2,⋅⋅⋅,zm(m≤p),且它们满足:
{ z 1 = l 11 x 1 + l 12 x 2 + ⋯ + l 1 p x p z 2 = l 21 x 1 + l 22 x 2 + ⋯ + l 2 p x p ⋮ z m = l m 1 x 1 + l m 2 x 2 + ⋯ + l m p x p \begin{cases}z_1=l_{11}x_1+l_{12}x_2+\cdots+l_{1p}x_p\\z_2=l_{21}x_1+l_{22}x_2+\cdots+l_{2p}x_p\\\vdots\\z_m=l_{m1}x_1+l_{m2}x_2+\cdots+l_{mp}x_p\end{cases} ⎩
⎨
⎧z1=l11x1+l12x2+⋯+l1pxpz2=l21x1+l22x2+⋯+l2pxp⋮zm=lm1x1+lm2x2+⋯+l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









