






目录
4.3.3划分训练集和测试集初始化并训练高斯朴素贝叶斯分类器
4.1.1基本概念
朴素贝叶斯是一种基于贝叶斯定理与特征条件独立假设的分类方法。它通过计算给定数据的后验概率来做出分类决策,即对于一个新的样本,朴素贝叶斯会计算它属于每个类别的概率,并将概率最大的类别作为预测结果。
4.1.2一般流程
- 准备工作:收集训练数据集,数据集中的每个样本都包含多个特征和一个类标记。
- 概率计算:根据训练数据计算每个类别的先验概率,即每个类别在数据中出现的概率。
- 概率计算:计算每个特征在每个类别下的条件概率。
- 应用模型:对于新的未知类别的样本,利用学到的概率和贝叶斯定理计算其后验概率。
- 进行预测:选择后验概率最大的类别作为该样本的预测类别。
4.1.3公式
贝叶斯公式是一个在概率论和统计学中非常重要的概念,它描述了两个条件概率之间的关系。
贝叶斯公式的核心在于,它可以让我们在已知某事件发生的条件下,计算另一事件发生的概率。具体来说,贝叶斯公式可以表示为:
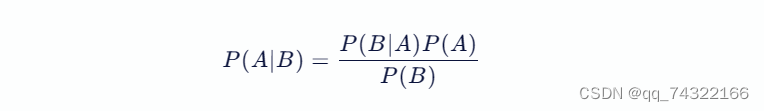
4.1.4贝叶斯的优缺点
优点:
- 易于实现:贝叶斯算法的逻辑简单,它基于贝叶斯公式,只需通过简单的计算即可完成模型的构建。
- 分类效率高:在分类过程中,由于其对特征独立性的假设,时空开销较小,涉及到的存储也仅仅是二维的。
- 预测速度快:对于待预测样本进行预测时,过程简单且速度快,特别是在邮件分类等问题上,预测可以通过分词后的概率乘积快速完成。
- 多分类问题有效:在面对多分类问题时,贝叶斯算法同样表现出色,复杂度不会大幅上升。
- 小样本学习效果好:在独立分布假设成立的情况下,即使需要的样本量较少,贝叶斯分类器也能取得很好的效果。
缺点:
- 属性独立性假设:朴素贝叶斯算法假设各特征之间相互独立,这在实际应用中往往不成立,可能会影响分类精度。
- 零频率问题:如果某个类别的特征在测试集中出现,但在训练集中未出现过,直接计算条件概率会得到零,导致预测失效。虽然通过平滑技术可以缓解这一问题,但仍是一个需要注意的缺陷。
- 概率结果含义:尽管朴素贝叶斯算出的概率结果用于比较是可行的,但其实际物理含义可能并不准确。
4.2.案例:判断西瓜好坏
西瓜数据集如下:
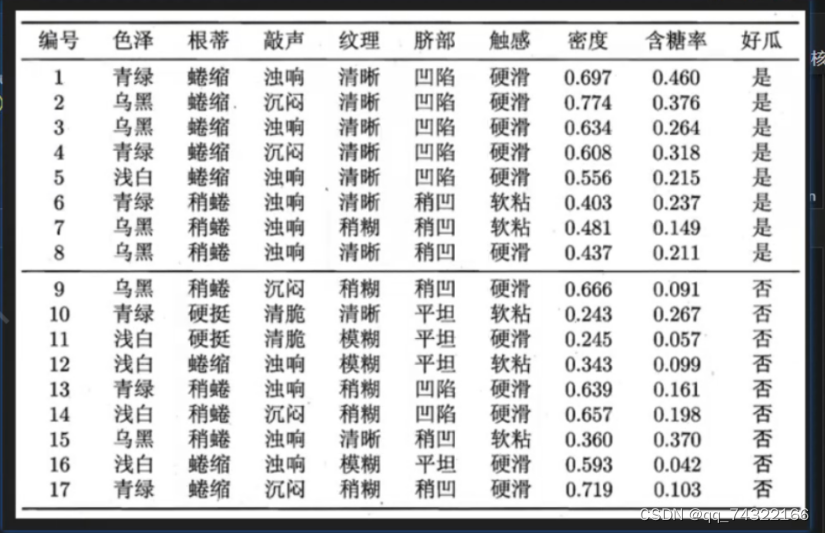
计算概率:

4.3.实例:判断苹果的优劣
4.3.1准备数据
苹果的数据集如下:

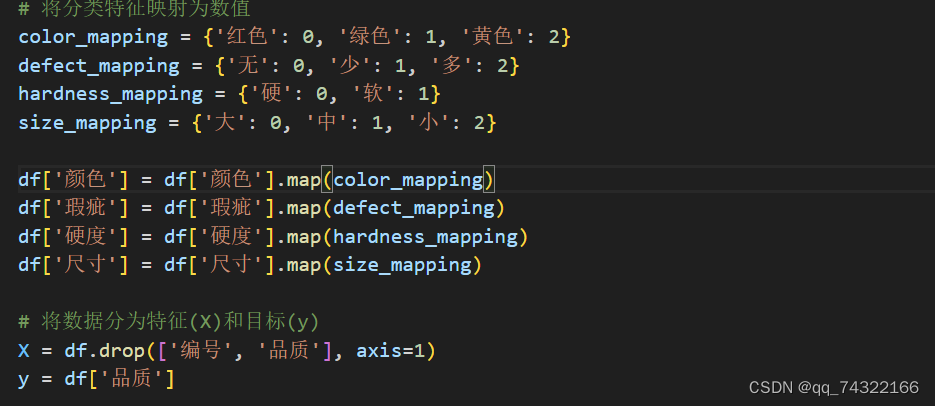
4.3.2数据预处理
4.3.3划分训练集和测试集初始化并训练高斯朴素贝叶斯分类器

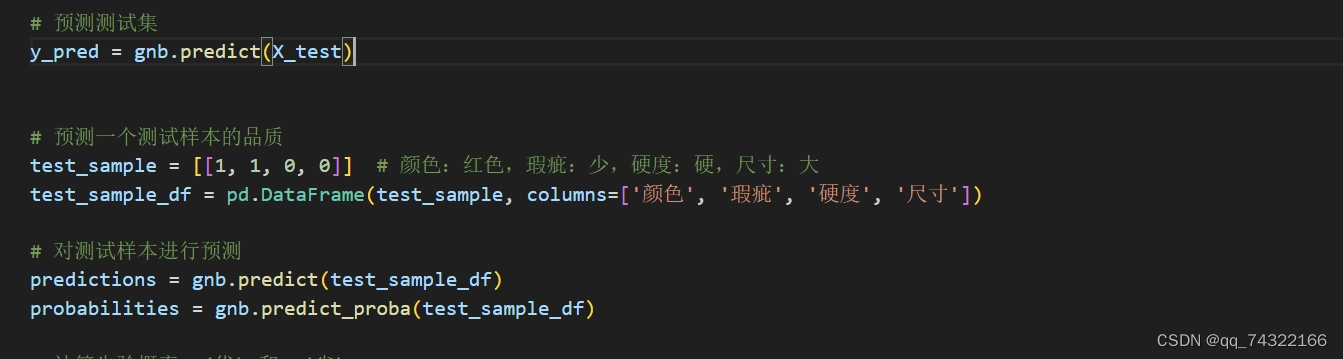
4.3.4预测测试样本
4.3.5计算测试样本的概率
4.3.6计算p(红色|优)的概率

4.3.7实验结果
先验概率:一共有20个苹果,优的有9个,劣的有11个,所以p(优)=9/20=0.45,p(劣)=11/20=0.55

测试样本的预测结果:样本的特征为颜色:红色,瑕疵:少,硬度:硬,尺寸:大,概率0.91774283 >0.08225717,所以预测结果为优。

p(红色|优)的概率:

4.4.1完整代码
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report, confusion_matrix
# 定义数据
data = {
}
# 创建DataFrame
df = pd.DataFrame(data)
# 将分类特征映射为数值
color_mapping = {'红色': 0, '绿色': 1, '黄色': 2}
defect_mapping = {'无': 0, '少': 1, '多': 2}
hardness_mapping = {'硬': 0, '软': 1}
size_mapping = {'大': 0, '中': 1, '小': 2}
df['颜色'] = df['颜色'].map(color_mapping)
df['瑕疵'] = df['瑕疵'].map(defect_mapping)
df['硬度'] = df['硬度'].map(hardness_mapping)
df['尺寸'] = df['尺寸'].map(size_mapping)
# 将数据分为特征(X)和目标(y)
X = df.drop(['编号', '品质'], axis=1)
y = df['品质']
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化并训练高斯朴素贝叶斯分类器
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# 预测测试集
y_pred = gnb.predict(X_test)
# 预测一个测试样本的品质
test_sample = [[1, 1, 0, 0]] # 颜色:红色,瑕疵:少,硬度:硬,尺寸:大
test_sample_df = pd.DataFrame(test_sample, columns=['颜色', '瑕疵', '硬度', '尺寸'])
# 对测试样本进行预测
predictions = gnb.predict(test_sample_df)
probabilities = gnb.predict_proba(test_sample_df)
# 计算先验概率 p(优) 和 p(劣)
prior_good = len(df[df['品质'] == '优']) / len(df)
prior_bad = len(df[df['品质'] == '劣']) / len(df)
print("先验概率 p(优) =", prior_good)
print("先验概率 p(劣) =", prior_bad)
print("预测结果:", predictions)
print("概率:", probabilities)
# 计算在训练集中,品质为优且颜色为红色的样本数
red_and_good = len(df[(df['品质'] == '优') & (df['颜色'] == 0)])
# 计算在训练集中,品质为优的样本数
good = len(df[df['品质'] == '优'])
# 计算p(红色|优)
p_red_given_good = red_and_good / good
print("p(红色|优) =", p_red_given_good)
4.5.1实验小结
通过这个实验,学习了如何使用高斯朴素贝叶斯分类器进行预测。首先创建了一个包含颜色、瑕疵、硬度、尺寸和品质特征的数据集。然后将分类特征映射为数值,并将数据分为特征(X)和目标(y)。接下来将数据分为训练集和测试集,并使用训练集训练高斯朴素贝叶斯分类器。最后对测试集进行预测,并计算先验概率p(优)和p(劣)。在实验过程中,还对一个测试样本进行了预测,并计算了其概率,还计算了在训练集中,品质为优且颜色为红色的样本数,以及品质为优的样本数,从而得到了p(红色|优)的值。
















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









