







创作原因
现在写电赛题,题目有识别数字的要求。但使用设备openmv使用模板匹配的算法帧率很低,且识别效果不是很好,于是我们就想到了利用神经网络训练模型来识别数字
正文部分
内容介绍
本文内容是基于openmv使用Edge Impulse训练大模型。
这篇文章的介绍会很详细,从数据集的采集到数据的上传再到模型的训练以及最后的模型的导出, 都会有较为详细的介绍,适合此前没有任何模型训练经验且使用openmv的朋友进行学习
步骤一:图像采集
唤起数据采集器
打开IDE后
依次点击:工具/数据集编辑器/新数据集
在这里我选择在桌面上新建一个文件夹来存放新采集的数据集
这时在IDE左上角会出现数据集编辑器
新建数据集文件
这个时候点击左侧的新建文件夹
就是在我们的数据集中新建文件夹
我们需要根据我们的分类来创建文件夹
我需要做的是识别数字,所以我的第一个分类的文件夹名称就叫number_1
数据采集
在连接了openmv有图像显示之后
点击左边的照片图标进行拍照(也就是数据采集)
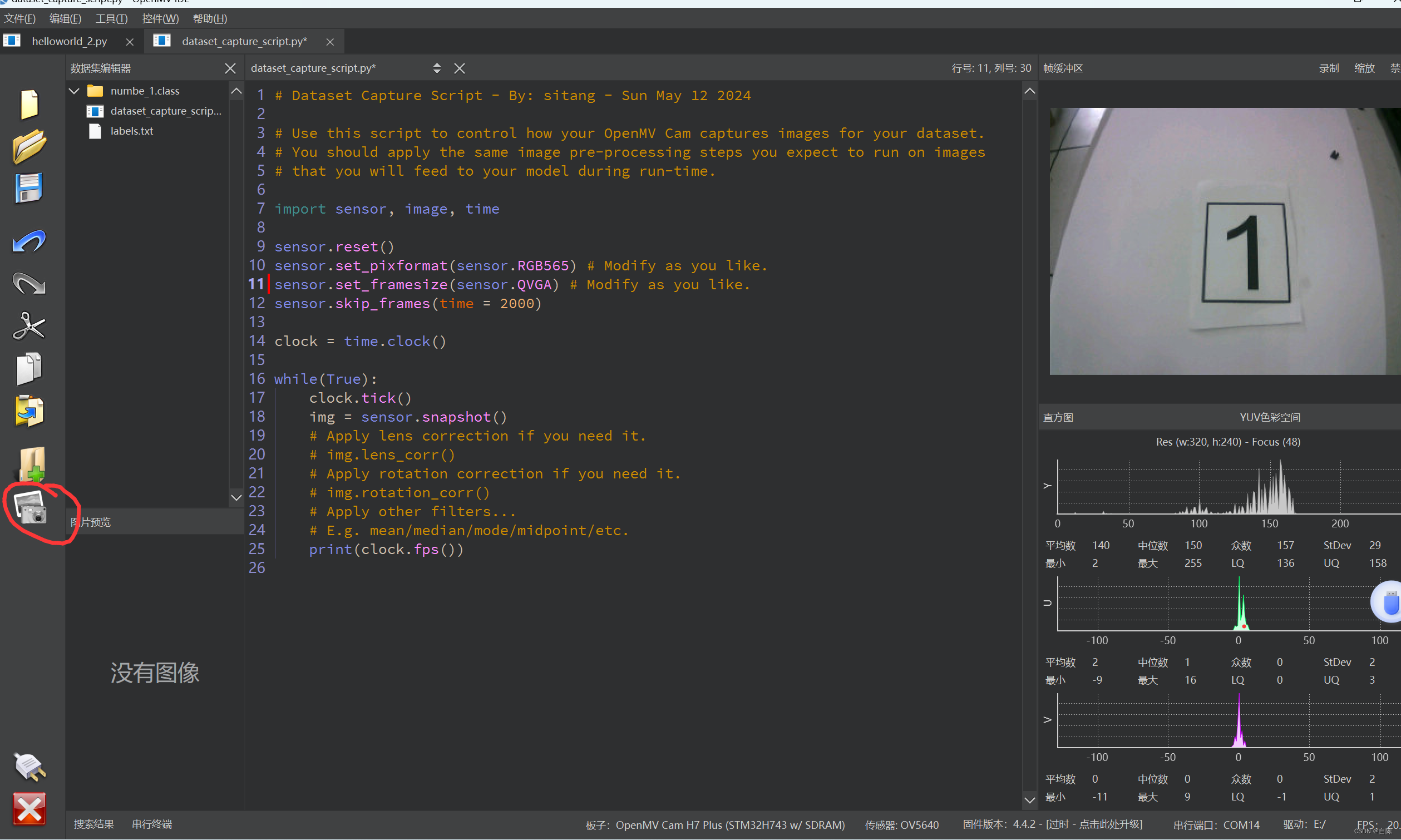
由于感觉图片光线比较暗,所以我开了一下补光灯

虽然感觉开了之后也没有什么用,但至少有点心理作用
再次回到数据采集的正题,这一个1,我们就浅浅地拍三十张照片吧
接下来就是拍照的过程,在这个过程中,需要注意的是:考虑可能出现的情况进行多角度的照片拍摄
拍照的过程比较枯燥,没有什么好说的点,埋头苦干就行了,这里跳过
步骤二:数据上传
Edge Impulse的注册
完成了图像采集之后
就需要把采集的数据集上传到EDGE IMPULSE的网站上进行在线的训练
首先登录EDGE IMPULSE的官网
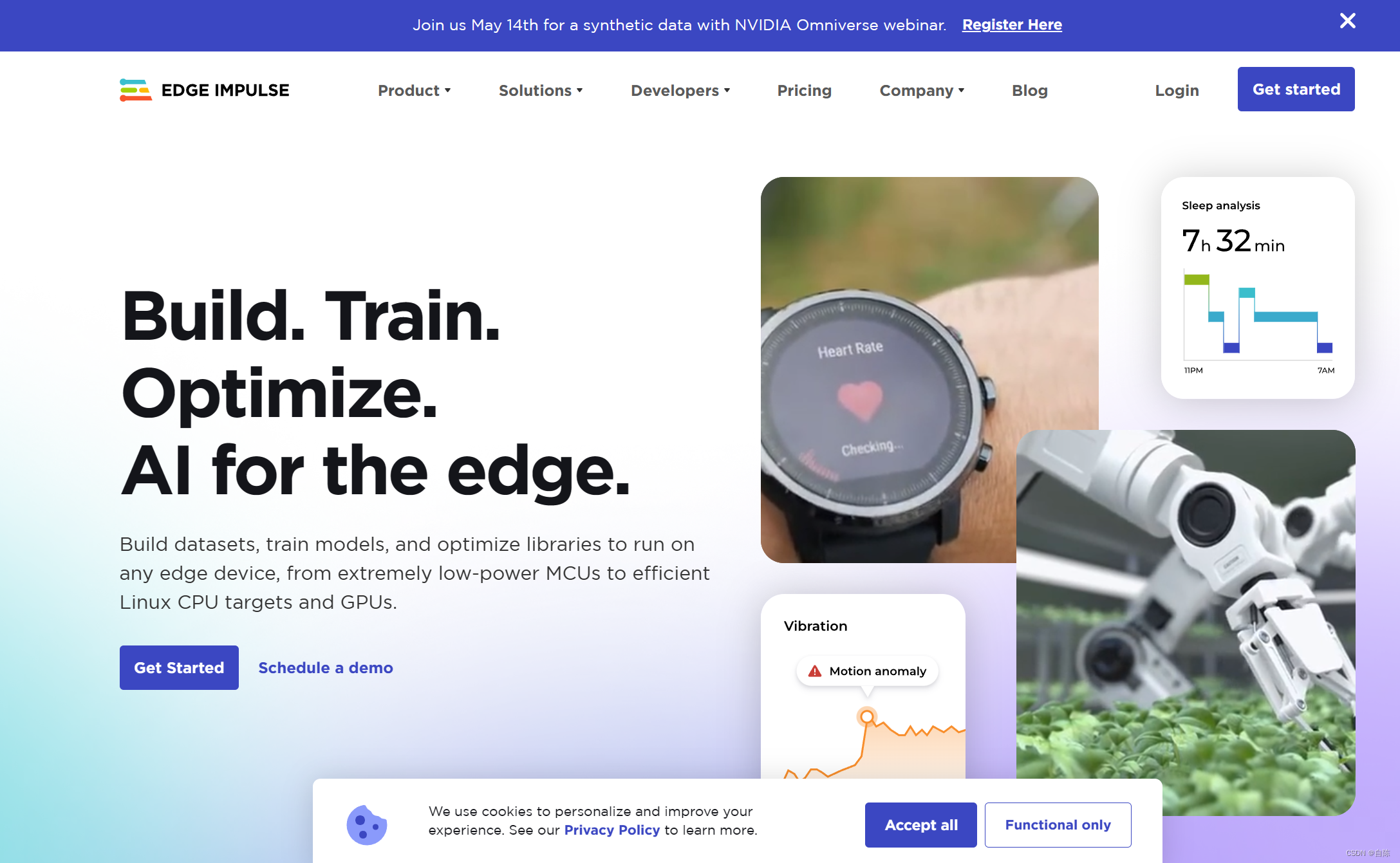
如果之前没有账户,点击Login

再在登录界面选择注册
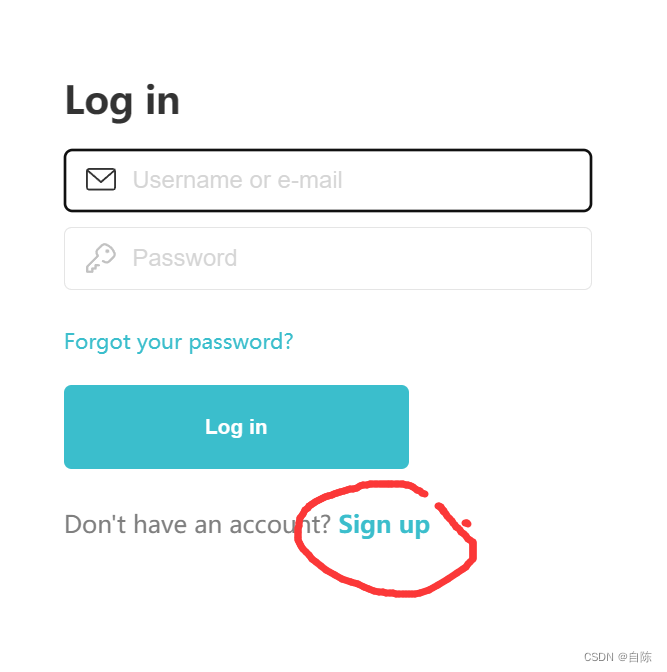
填完所有信息,点击Sign up之后,会给你发送一个邮件

点击右键给出链接,会跳转到登录界面
然后填写你的用户名和密码,点击登录
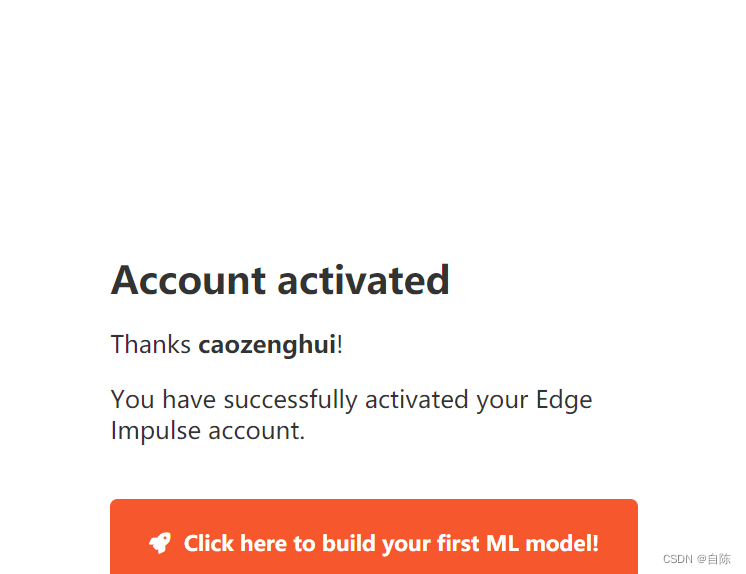
账号激活完成
通过Keys实现数据集传输
然后我新建了一个名字是number的工程

目前新建工程中并没有数据集,我们点击Keys
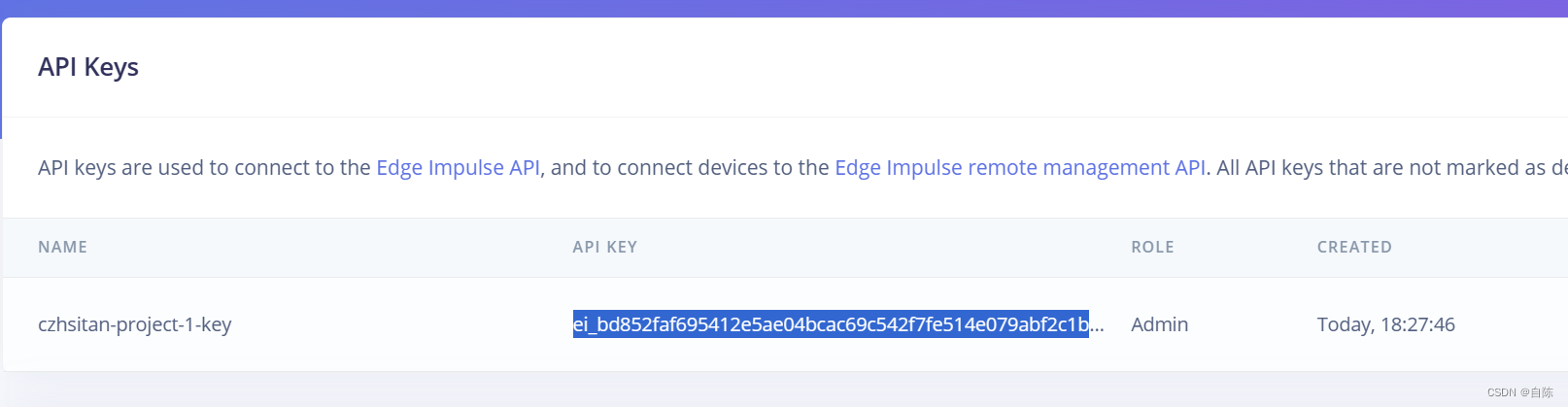
我们选择API Key,然后复制API KEY
注意在这里显示的API KEY可能不完整,可以通过缩放屏幕来使他显示完全
我们要拿API KEY来做什么呢?
答案是,我们要使用API KEY来实现与OpenMv IDE的联通
点击工具,依次选择:数据集编辑器/Export/Upload to Edge Impulse by API Key

选择之后跳出来一个弹窗
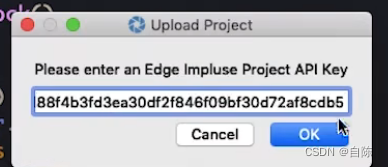
把复制的API KEY输入进去
然后会让你选择上传时训练集和数据集的比例
选择这个参数的意义在于,会在你上传的数据(照片中)选择你选择的训练集比例
用于训练模型,数据集比例的照片用来最后测试训练效果
这个值一般选默认的百分之八十和百分之二十就可以
注意一点,采集图片时尽量让背景简单,复杂的背景会在一定程度上影响模型训练的结果
接下来,等待上传成功
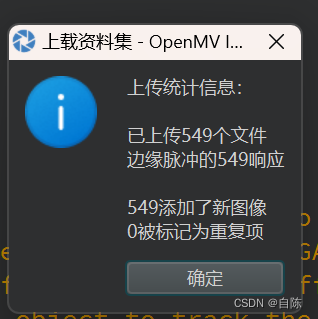
上传成功
步骤三:模型训练
模型创建
数据上传完成之后,来到这个界面
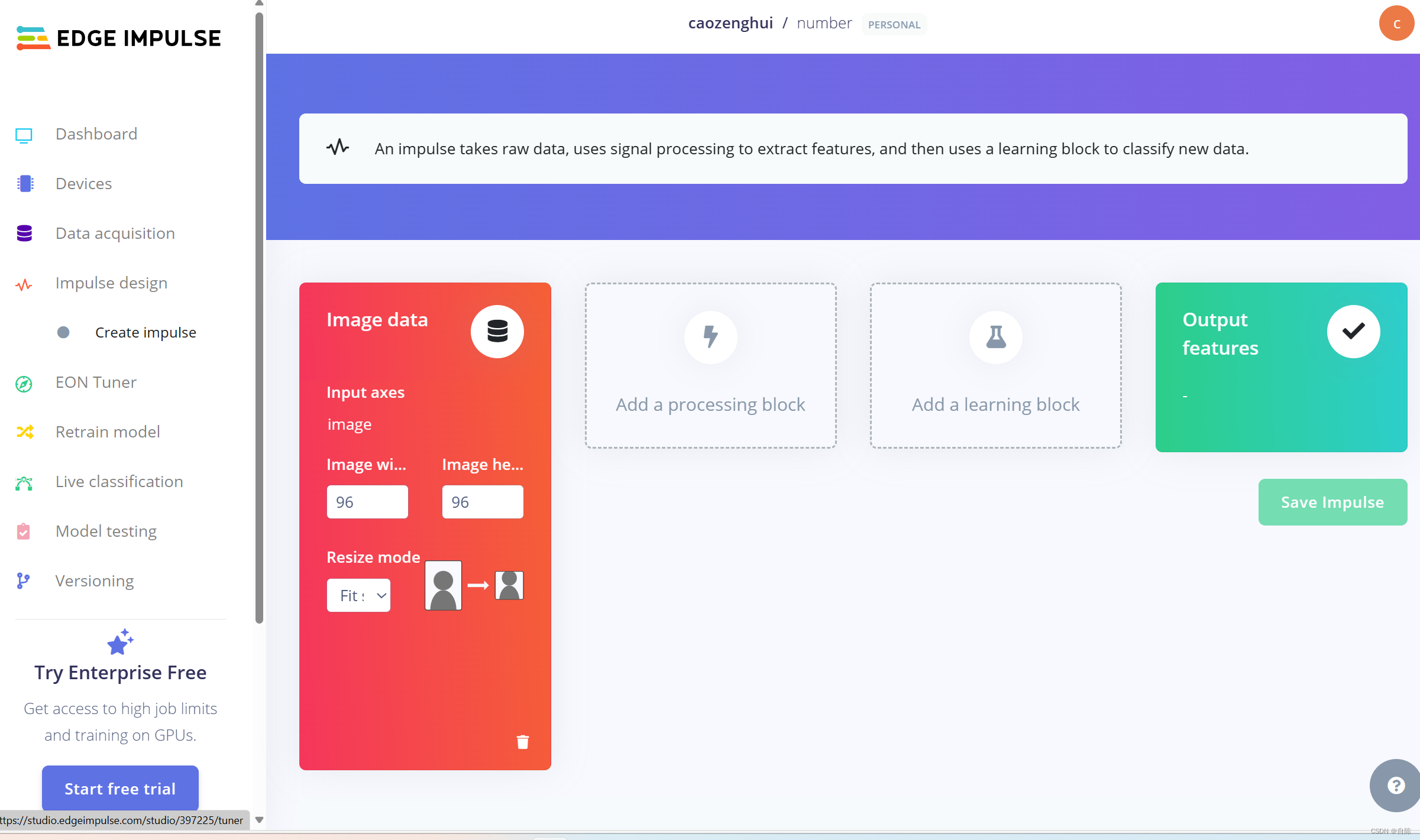
开始模型的创建
首先是对图像的处理
它训练的时候会将图像变成长宽等比例的一个图像,我们选择默认的96*96就可以
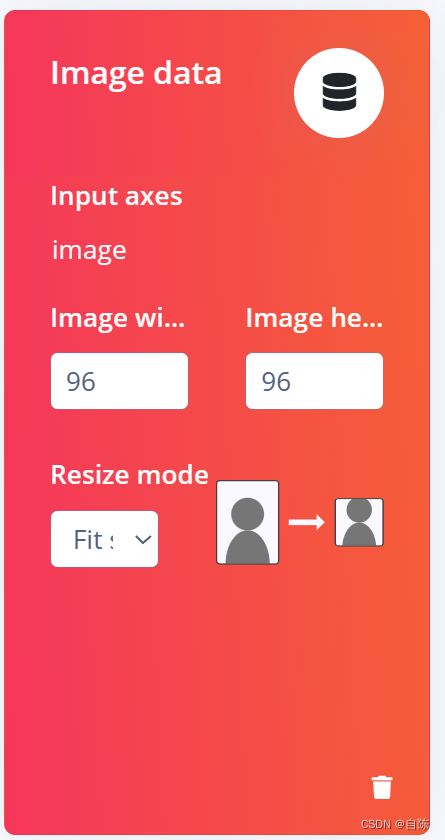
然后我们再选择创建模块

这里是选择你要分类的类型,可以选择图像、声音、类型之类的选项,我们openmv就默认选择视频就可以
然后我们再添加下一个模块

选择进行学习的模块
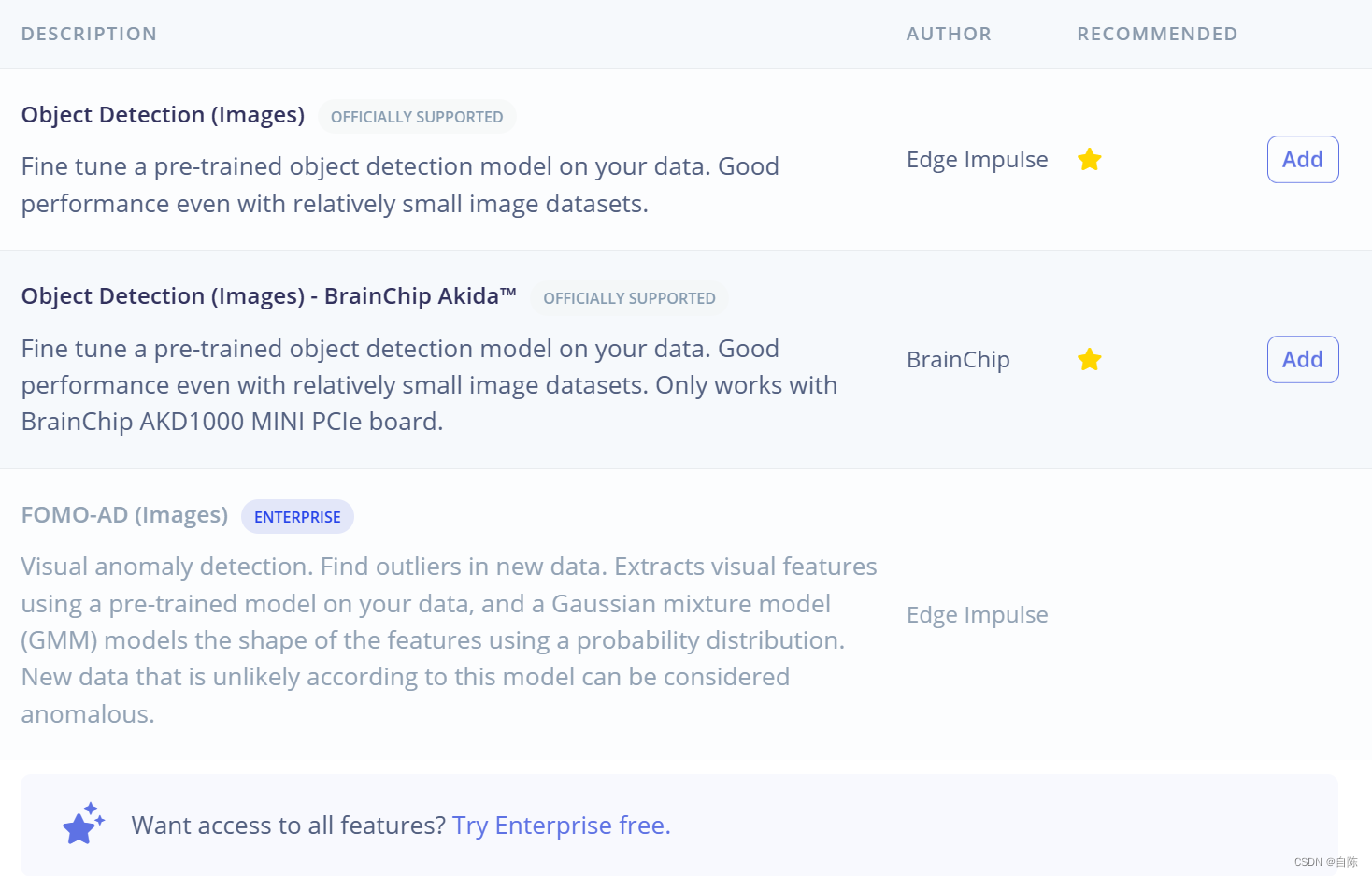
这里我们选第一个
至于选择的理由嘛,它是两个带星号(推荐)的方法之一,而且另一个方法根据说明只能用于某个芯片
然后发现我建立的模型识别不出来特征
后来和罗俊棋开腾讯会议发现问题是上传的数据集没有打上标签
现在就解决这个没有标签的问题
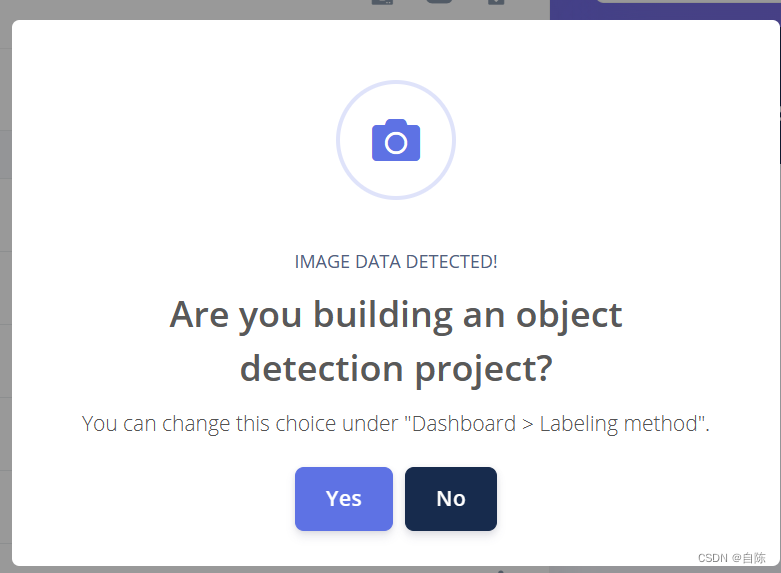
找到问题所在了 ,在我的数据集刚上传的时候是有标签的,接下来会弹出一个弹窗, 这个弹窗必须选择no,不然你的标签就会被去除
解决问题后继续模型的搭建
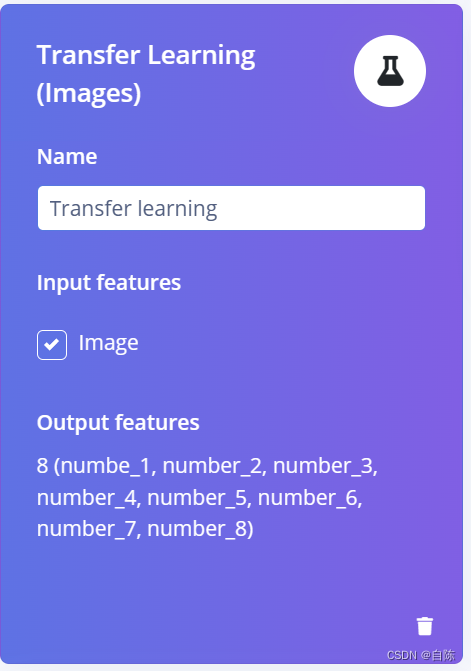
学习方法选择迁移训练
到此模块选择完毕,可以看见,一共有八个feature,都是我数据集分类的名称

点击保存,显示保存成功
图像特征提取
下一步选择image,对我们呢的图像做DSP预处理

我们需要选择是RGB还是灰度图,这里选择RGB即可,具体的根据需求来
在后来模型训练的时候,我发现RGB的模型训练效果不好,然后就换了Grascale,训练效果很好,选择根据需求
DSP图像预处理它会把每一张图片生成一些features

选完之后点击保存,就会自动跳到下一个界面
在这个界面我们只需要点击Generate features就可以了
就是对图片做预处理
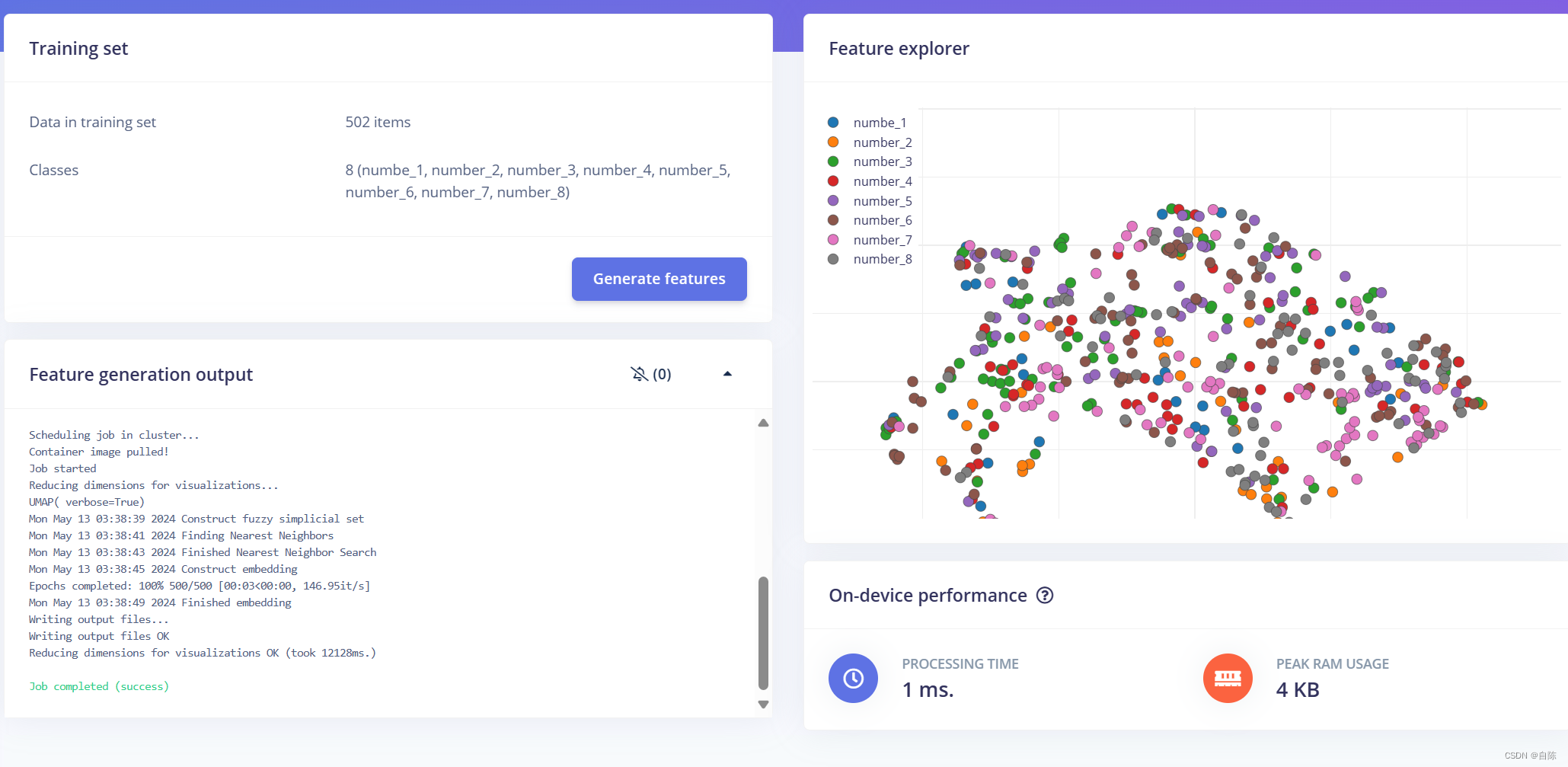
当特征创建完之后,image的部分就完成了,我们进入下一个部分
对机器学习方法的一些参数进行设置
机器学习参数设置
第一个参数是训练的轮数
第二个参数是训练的速率,越大训练越快,但是这个参数过高过低都会导致训练效果不好
接下来就是是否勾选数据增强,它可以在训练的过程中随机地变换数据,它可以让你训练更多地轮数而且不会过拟合,这样可以提高训练的准确度
第三个参数是置信度
三个参数都选择默认值就可以

然后就可以开始训练了
训练结果如下,效果还是可以的
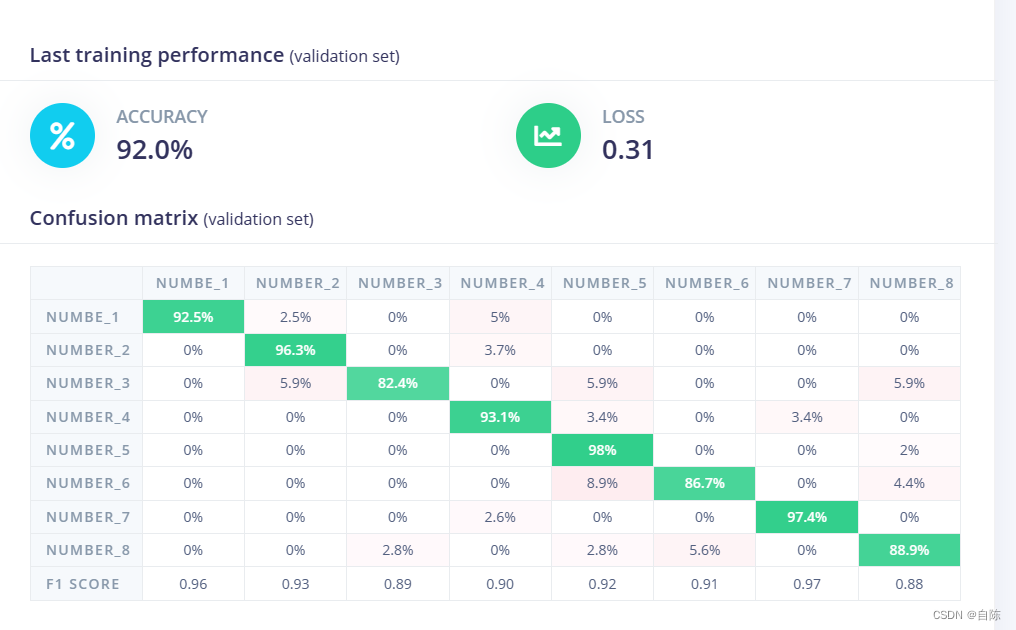
模型训练完成之后,你也可以选择在Versioning保存当前训练出来的模型版本
当然你也可以不保存
保存之后,以后也可以使用这个模型
比如当你新上传了数据集,重新训练出的模型就会把之前的模型覆盖掉
也许之后训练的模型效果没有之前的效果好,也就有了保存训练出的模型的必要

步骤四:模型导出
模型训练好之后,我们现在要做的事就是导出训练好的模型
导出OpenMV需要的文件
由于我们是要把模型导出到openmv上,所以我们点击Deployment选择Search deployment options
在给出的选项中选择openmv
然后就可以点击build了
当build完成之后,会自动地把生成的文件下载
把导出文件应用于OpenMV
把下载的文件夹解压之后,出来了三个文件
把这三个文件复制到openmv的内置flash中,打开其中的.py文件
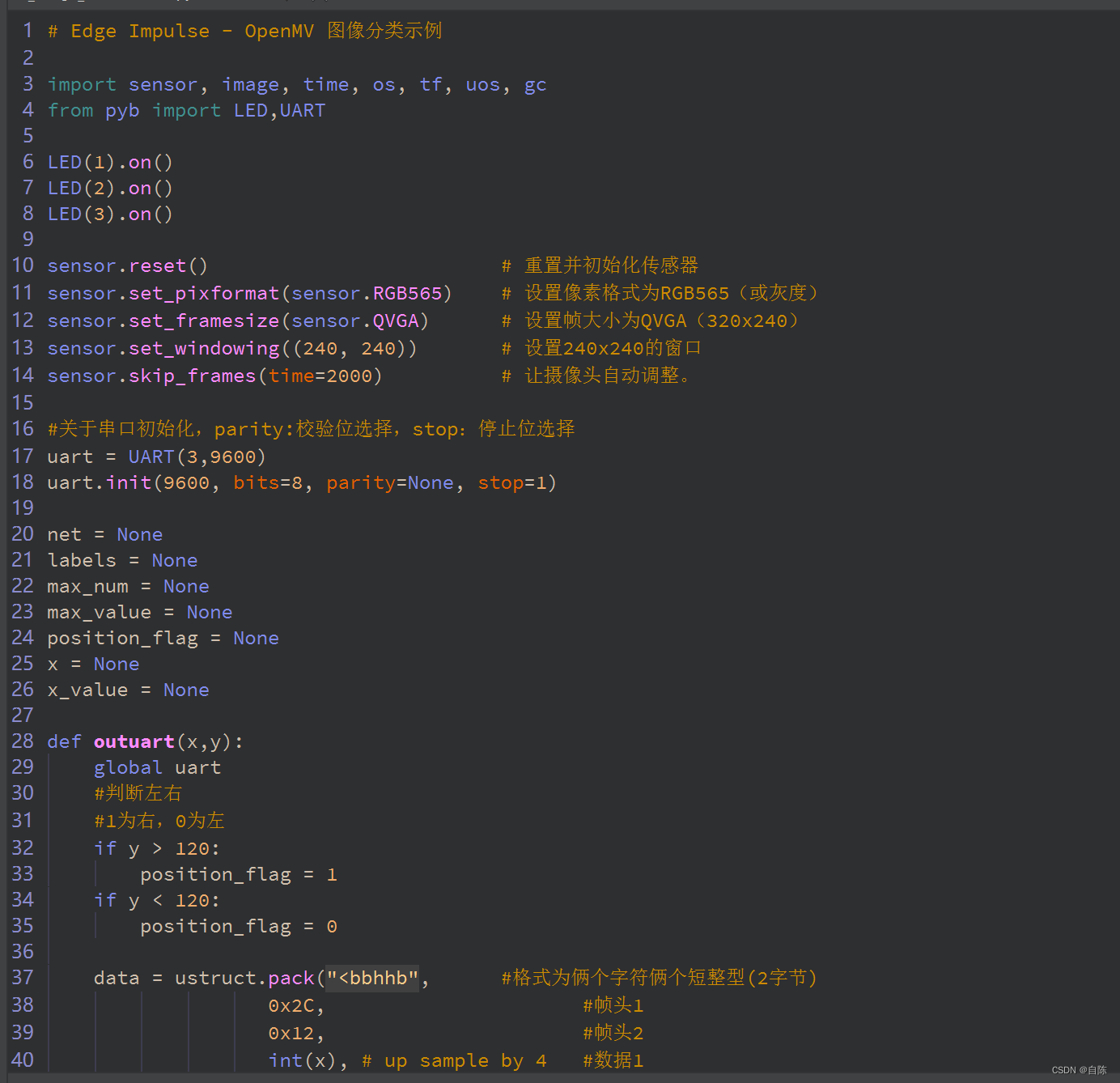
就可以开始使用代码了
结语
这篇文章就到这里,祝各位也许在熬夜,也许在疲惫的”道友“们生活愉快。
你们说,我们能走多远呢?加油吧

















 6357
6357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









