






目录
局部响应归一化(Local Response Normalization):
一、介绍
AlexNet 是一种经典的卷积神经网络(Convolutional Neural Network,CNN),由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 2012 年提出。它在 ImageNet 图像识别挑战赛中取得了显著的突破,并成为了深度学习的重要里程碑之一。
AlexNet 主要用于图像分类任务,特别是在大规模图像数据集上的分类任务。AlexNet 的架构和设计思想也被广泛应用于其他计算机视觉任务,例如目标检测、语义分割和人脸识别等。
二、AlexNet是怎样工作的
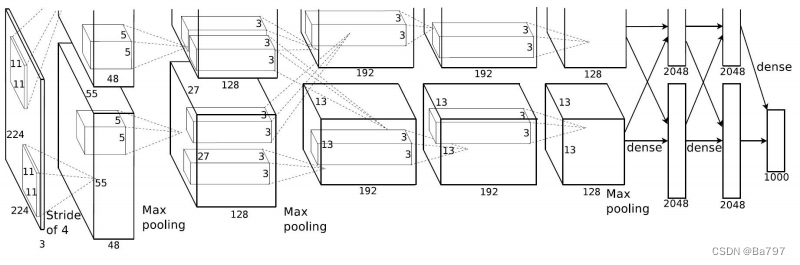
如图:该网络结构是由五个卷积层和三个全连接层构成,参数如下图所示

-
网络结构:
- 输入层:接受输入图像的像素值。
- 卷积层(Convolutional Layers):由五个卷积层组成,每个卷积层后面紧跟一个池化层(Pooling Layers)。
- 全连接层(Fully Connected Layers):由三个全连接层组成,最后一个全连接层输出网络的分类结果。
- 输出层:使用 softmax 函数进行多类别分类。
-
卷积层和池化层:
- 卷积层通过使用不同的滤波器提取图像的特征。AlexNet中使用了较大的滤波器尺寸(例如 11x11、5x5),以捕获更大范围的特征。
- 卷积层之后是池化层,用于降低特征图的维度,减少计算量,并增加模型的平移不变性。AlexNet使用最大池化(Max Pooling)操作,通过在每个池化区域中选择最大值来提取最显著的特征。
-
激活函数:
- AlexNet 使用了修正线性单元(Rectified Linear Unit,ReLU)作为激活函数。相比于传统的 Sigmoid 或者 Tanh 函数,ReLU 函数具有更好的收敛性和计算效率。
-
局部响应归一化(Local Response Normalization):
- 在每个卷积层的后面,AlexNet 使用局部响应归一化层来增强模型的泛化能力。这个操作通过对局部区域内的响应值进行归一化,使得高响应的神经元被抑制,同时增强其他神经元的响应。
-
Dropout:
- 为了减少过拟合,AlexNet 在全连接层中引入了 Dropout 技术。Dropout 随机地将一部分神经元的输出置为零,从而防止网络过度依赖某些特定的神经元,增强模型的泛化能力。
-
训练:
- AlexNet 使用了标准的反向传播算法进行训练,并采用随机梯度下降(SGD)来更新网络参数。
- 为了加速训练过程,AlexNet 使用了 GPU 进行计算,并通过数据增强技术对训练图像进行随机裁剪、翻转等操作,增加了数据的多样性。
三、 代码示例(CIFAR-10 数据集)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 定义AlexNet模型
class AlexNet(nn.Module):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(192 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 加载CIFAR-10数据集
transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = datasets.CIFAR10(r'E:\project\pose\data\data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(r'E:\project\pose\data\data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False)
# 训练函数
def train(model, train_loader, optimizer, criterion, device):
model.train()
epoch_loss = 0
num_correct = 0
total = 0
for X, y in train_loader:
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
_, predicted = outputs.max(1)
total += y.size(0)
num_correct += predicted.eq(y).sum().item()
train_loss = epoch_loss / len(train_loader)
train_acc = num_correct / total
return train_loss, train_acc
# 测试函数
def test(model, test_loader, criterion, device):
model.eval()
test_loss = 0
num_correct = 0
total = 0
with torch.no_grad():
for X, y in test_loader:
X, y = X.to(device), y.to(device)
outputs = model(X)
loss = criterion(outputs, y)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += y.size(0)
num_correct += predicted.eq(y).sum().item()
test_loss = test_loss / len(test_loader)
test_acc = num_correct / total
return test_loss, test_acc
# 训练模型
num_epochs = 10
batch_size = 128
learning_rate = 0.001
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AlexNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=5e-4)
# 记录训练指标
train_loss = []
train_acc = []
for epoch in range(num_epochs):
train_loss_epoch, train_acc_epoch = train(model, train_loader, optimizer, criterion, device)
train_loss.append(train_loss_epoch)
train_acc.append(train_acc_epoch)
print(f"Epoch {epoch + 1}/{num_epochs} - Loss: {train_loss_epoch:.4f} - Acc: {train_acc_epoch:.2f}%")
# 保存模型
torch.save(model.state_dict(), 'alexnet.pth')
# 绘制训练损失和准确率曲线
plt.plot(train_loss, label='Train loss')
plt.legend()
plt.show()
plt.plot(train_acc, label='Train accuracy')
plt.legend()
plt.show()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









