






1. 传统 TTS

传统 TTS 系统通常分为前端和后端两个部分,每个部分负责不同的任务。
前端(Frontend)
- 文本预处理:将输入的文本清洗、分词、规范化,使其适合语音合成。
- 文本清洗:去除无关字符、标点符号等。
- 分词:将文本分解为单词或短语。
- 规范化:将数字、日期、时间等转换为可读的形式。
- 音素序列生成:将文本转换为音素(音标)序列。
- 音素化:将文本转换为音素。
- 韵律分析:确定音素的发音时长、音高和音强等。
后端(Backend)
- 声学特征生成:将音素序列转换为声学特征(如梅尔频谱图)。
- 声学模型:使用统计模型(如 HMM、GMM)生成声学特征。
- 波形生成:将声学特征转换为最终的波形音频。
- 声码器:使用声码器(如 WaveNet、Griffin-Lim、HiFi-GAN)生成波形。
2. 基于深度学习的端到端 TTS

基于深度学习的端到端 TTS 系统通过一个统一的模型完成从文本到语音的整个过程,简化了传统 TTS 系统的复杂性。
优点
- 简化架构:整个过程由一个模型完成,减少了多个独立模块的复杂性。
- 一致性:训练和生成过程更加一致,提高了模型的性能和稳定性。
- 高质量:生成的语音质量更高,更自然。
缺点
- 泛化能力:在处理低资源语言和新领域时,泛化能力可能不足。
- 风格控制:控制语音的情感和风格较为困难。
- 低资源语言:对于低资源语言,训练数据不足可能导致性能下降。
常见模型
- Tacotron 2:基于注意力机制的端到端 TTS 模型,生成高质量的语音。
- FastSpeech 2:基于 Transformer 的 TTS 模型,支持多说话人和情感合成。
- HiFi-GAN:基于生成对抗网络(GAN)的声码器,生成高质量的波形音频。
3.结合大模型的 TTS
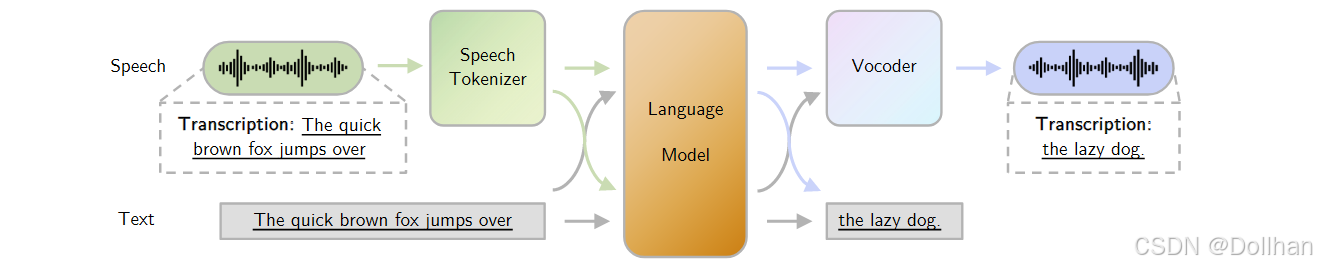
结合大模型的 TTS 系统利用大规模语言模型(LLM)和语音识别(ASR)技术,进一步提升了 TTS 系统的性能和灵活性。
框架
- ASR + LLM + TTS:这种框架结合了语音识别、大规模语言模型和语音合成技术,形成了一个强大的多模态系统。
- ASR(Automatic Speech Recognition):将语音转换为文本。
- LLM(Large Language Model):处理文本内容,生成自然语言响应。
- TTS(Text-to-Speech):将生成的文本转换为语音。
体系结构
- SpeechLM:这是一种多模态的大模型,可以处理语音和文本两种模态的数据。
- 多模态处理:相同的内容可以在语音和文本模态中使用,这意味着任何输入模态都会产生相同结果的任何输出模态。
- 一致性:确保输入和输出内容的一致性,提高系统的鲁棒性和可靠性。
优点
- 多模态处理:能够处理多种模态的数据,提供更丰富的交互体验。
- 高质量生成:结合大规模语言模型,生成的语音更加自然、流畅。
- 灵活性:支持多种应用场景,如智能客服、语音助手、内容生成等。
挑战
- 计算资源:大规模模型需要大量的计算资源,部署成本较高。
- 数据需求:需要大量的多模态数据进行训练,数据获取和标注成本较高。
- 模型复杂性:模型的复杂性增加,调试和优化难度较大。
应用场景
- 智能客服:
- 结合 ASR 和 TTS,提供全语音交互的客服系统。
- 语音助手:
- 利用 LLM 处理复杂的用户请求,生成自然的语音响应。
- 内容生成:
- 生成高质量的语音内容,如有声书、新闻播报等。
- 教育和培训:
- 为学生提供个性化的语音教学材料,提高学习效果。

















 3320
3320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









