









对应于上一篇博客的BP神经网络的初步介绍中的七、BP反向传播的详细推导
博主写博客旨在向他人学习过程的基础上整理的知识点,便于自己理解,以后复习也可以常看看。如果有错,望指出,博主定会虚心接受,细心改正。
一、MSE损失函数推导
两层的神经网络计算图
绿色代表权重参数 w j k w_{jk} wjk,橙色代表基底参数 b j b_j bj。可见虽然网络图上只是简单几条线,计算图还是蛮复杂的。
现在我们在计算图箭头上标出对应的偏导数(只标出了一部分)。

上面计算图上每一个节点关于前一个节点的偏导数都可以求得,根据求导的链式法则,想要求损失函数C关于某一节点的偏导数,只需要“把该节点每条反向路径上的偏导数做乘积,再求和”即可。(
w
j
k
,
b
j
w_{jk},b_j
wjk,bj分别对应绿色和橙色的节点)
正向传播的基本公式:

反向传播的四个公式





至此就得到了反向传播的4个公式。
二、交叉熵损失函数推导
在学习吴恩达老师的deeplearning.ai课程中,学到了不少东西,然后有些地方没有想得特别透彻,尤其是在推到正向和反向传播的时候,应该没有特别具体的推导过程,所以我在这里借鉴一下网上博客推导过程,写得比较具体。
首先对于正向传播和反向传播向量化的关键公式如下:

1.推导dW
此处省略了上下标。但是表达的意思不变。
由 Z = W X + b Z = WX+b Z=WX+b我们就能够知道如下的式子
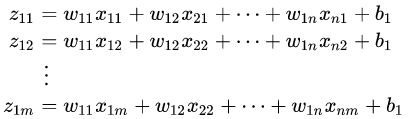
通过上面的公式,我们采用微分的方式得到下面:
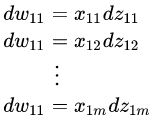
上面一共有m个式子,然后我们全部相加起来,就得到了

采用同样的方式,我们就能得到 d W dW dW的公式:
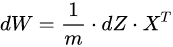
2.推导db
我们根据 Z = W X + b Z=WX+b Z=WX+b这个公式就能推导出下面的一系列的公式:
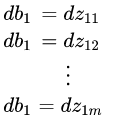
对上面的公式相加,改写一下就得到下面的公式:
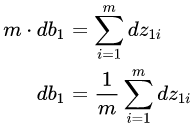
将前面的公式应用到第l层的时候

3.推导dZ

下面附上吴恩达老师推导时,维度的图片。如图片的右上角可知:

总结权重跟偏置的维度如下:
w
[
l
]
w^{[l]}
w[l] :
(
n
[
l
]
,
n
[
l
]
−
1
)
(n^{[l]},n^{[l]-1})
(n[l],n[l]−1) 横:当前层的神经元个数,纵:上一层的神经元数。
b
[
l
]
b^{[l]}
b[l] :
(
n
[
l
]
,
1
)
(n^{[l]},1)
(n[l],1)
d
w
[
l
]
dw^{[l]}
dw[l] :
(
n
[
l
]
,
n
[
l
]
−
1
)
(n^{[l]},n^{[l]-1})
(n[l],n[l]−1)
d
b
[
l
]
db^{[l]}
db[l] :
(
n
[
l
]
,
1
)
(n^{[l]},1)
(n[l],1)
参考:
[1] 吴恩达深度学习课程
[2] https://www.jianshu.com/p/cdfeee1d434e
[3] https://blog.csdn.net/LucyGill/article/details/64920840
[4] https://blog.csdn.net/jack__linux/article/details/89227669















 2204
2204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









