










文章目录
- Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
- ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
- A Close Look at Spatial Modeling: From Attention to Convolution
- DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
- DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
论文链接:https://arxiv.org/abs/2212.11548
代码链接:https://github.com/TaoWangzj/LLFormer
-
Transformer block里面修改了 attention,先在H维度计算,再在W维度计算。
-
Transformer block里修改了FFN; 两个分支都使用 GELU 激活,然后互相给另外一个分支添加门控,这样就进一步增强了FFN的非线性建模能力。
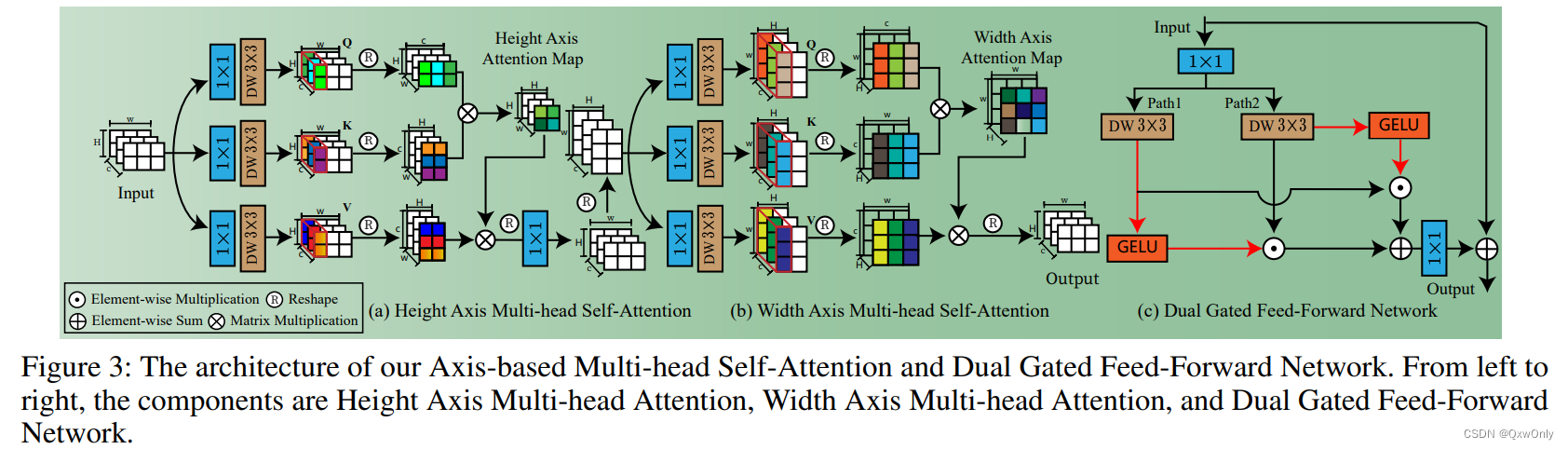
-
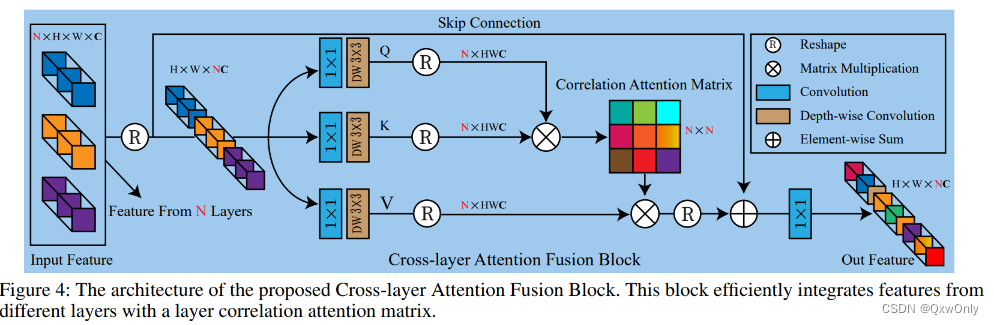
添加了 cross-layer attention 。作者通过 attention 运算,计算一个3x3的相似性矩阵,给输入的特征进行加权。输入的三组特征里,强调重要的、抑制不重要的。
ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
论文链接:https://openreview.net/pdf?id=ZK6lzx0jqdZ
代码链接:https://github.com/sunny2109/ShuffleMixer
本文引入了一种通道分裂和混洗操作来有效地执行通道映射的特征混合。同时为了更好地探索混洗混合器层的跨组特征之间的局部连通性,在所提出的超分设计中使用了MBConv。

A Close Look at Spatial Modeling: From Attention to Convolution
论文链接:https://arxiv.org/pdf/2212.12552.pdf
代码链接:https://github.com/ma-xu/FCViT
本文为了降低注意力的计算,从Q*K 的注意力计算方法变为计算CHW特征矩阵和pooling后的矩阵相乘,得到注意力矩阵。
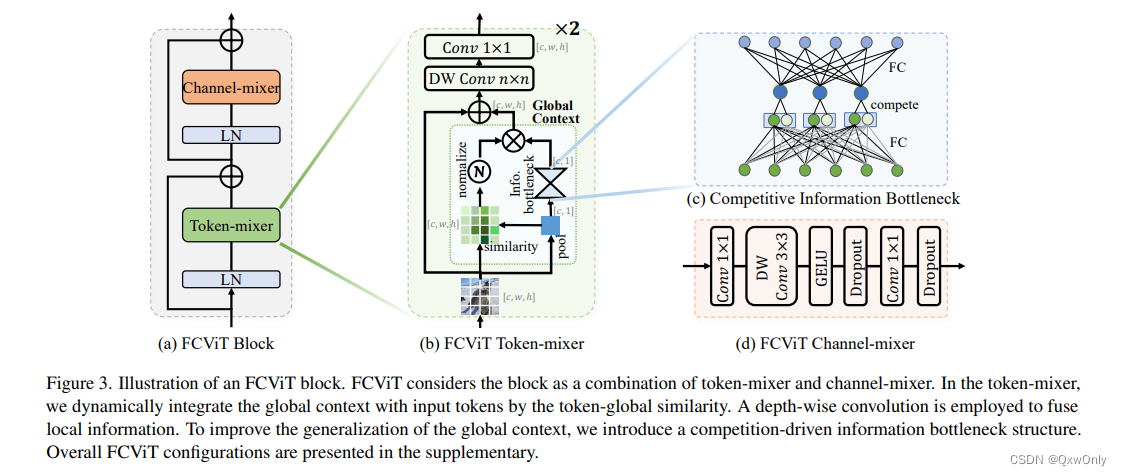
DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
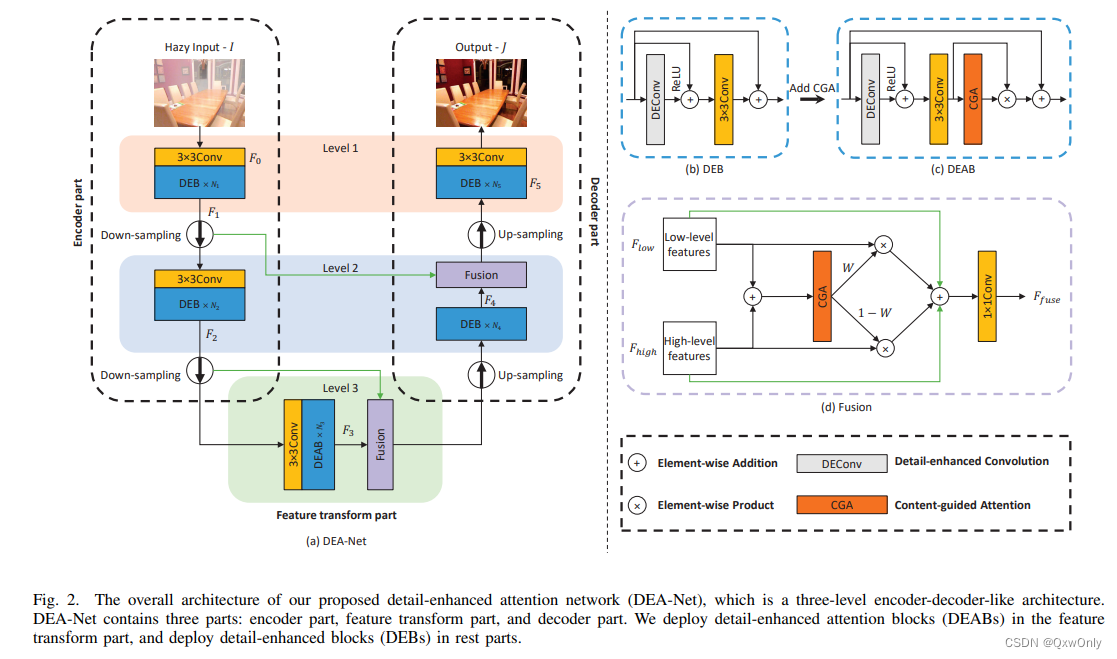
本文提出了一个由细节增强卷积(DEConv)和内容引导注意力(CGA)组成的细节增强注意力块(DEAB),以促进特征学习,提高去雾化性能。
- 具体来说,DEConv将先验信息整合到正常的卷积层中,以提高表示和概括能力。然后,通过使用重新参数化技术,DEConv被等效地转换为一个没有额外参数和计算成本的普通卷积。
- 通过为每个通道分配独特的空间重要性图(SIM),CGA可以参加编码在特征中的更多有用信息。
- 此外,还提出了一个基于CGA的混合融合方案,以有效地融合特征并帮助梯度流动。
论文链接:https://arxiv.org/pdf/2301.04805v1.pdf
代码链接:https://github.com/cecret3350/DEA-Net
DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
论文链接:https://arxiv.org/pdf/2212.13504v1.pdf
代码链接:https://github.com/mindflow-institue/daeformer
本文设计了一种新的高效的双重注意机制来捕获输入特征向量的完整空间和通道上下文。同时提出了一种跳过连接交叉注意(SCCA)模块,用于自适应地融合来自编码层和解码层的特征。















 2425
2425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









