







 本文详细介绍了Self-Attention模型的结构,包括位置编码的引入,以及多头注意力机制,重点讨论了Transformer模型中的编码器和解码器设计,以及BERT和GPT-3在预训练和任务适应上的差异。
本文详细介绍了Self-Attention模型的结构,包括位置编码的引入,以及多头注意力机制,重点讨论了Transformer模型中的编码器和解码器设计,以及BERT和GPT-3在预训练和任务适应上的差异。
Self-Attention
模型结构
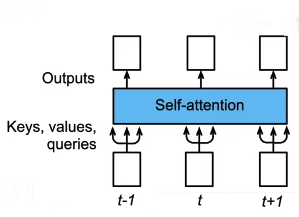
上图架构以 batch_size 为 1,两个时间步的 X 为例子,计算过程如下:
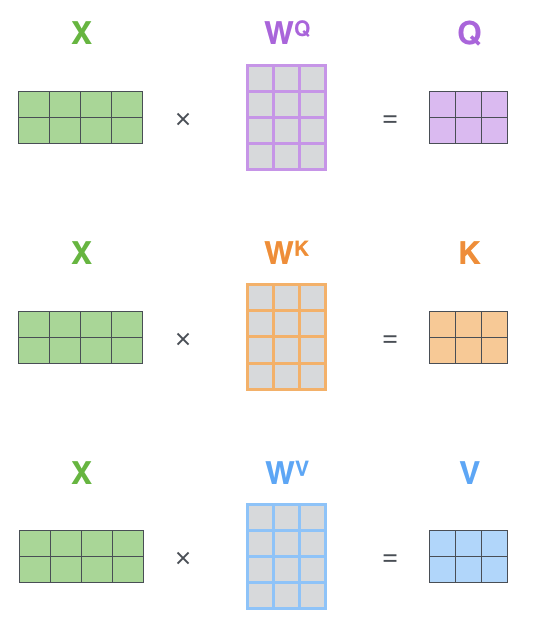
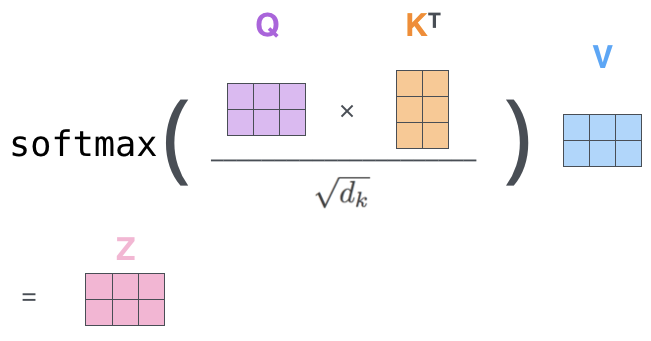
位置编码
根据 self-attention 的模型结构,改变 X 的输入顺序,不影响 attention 的结果,所以还需要引入额外的位置信息,即位置编码。

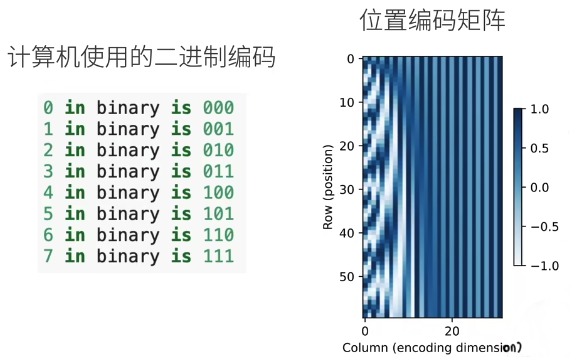
图里计算机二进制编码的低位和位置编码矩阵的前面几列对应。
除了上面捕获绝对位置信息之外,上述的位置编码还允许模型学习得到输入序列中相对位置信息。 这是因为对于任何确定的位置偏移δ,位置 i+δ 处的位置编码可以线性投影位置 i 处的位置编码来表示。
代码
#@save
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3161
3161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











