








 该专栏为热销专栏榜 第23名
该专栏为热销专栏榜 第23名 超级会员免费看
超级会员免费看


 本文介绍了在线学习深度强化学习(ORL)算法,旨在解决数据稀缺问题,提升机器人对自我了解和控制能力。ORL利用蒙特卡洛树搜索,结合基于物理和规则的奖励函数,实现数据收集和策略学习。通过增量学习,模型能快速适应新任务,具有高效和灵活性。文章还探讨了未来的发展趋势和挑战。
本文介绍了在线学习深度强化学习(ORL)算法,旨在解决数据稀缺问题,提升机器人对自我了解和控制能力。ORL利用蒙特卡洛树搜索,结合基于物理和规则的奖励函数,实现数据收集和策略学习。通过增量学习,模型能快速适应新任务,具有高效和灵活性。文章还探讨了未来的发展趋势和挑战。
文章目录
- 在线学习的深度强化学习——Online Reinforcement Learning for Learning
- 在线学习的深度强化学习
- 在线学习的深度强化学习——Online Reinforcement Learning for Learning
- 1.简介
- 2. 背景介绍
- 3. 基本概念术语说明
- 4. 核心算法原理和具体操作步骤以及数学公式讲解
- 5. 具体代码实例和解释说明
- 6. 未来发展趋势与挑战
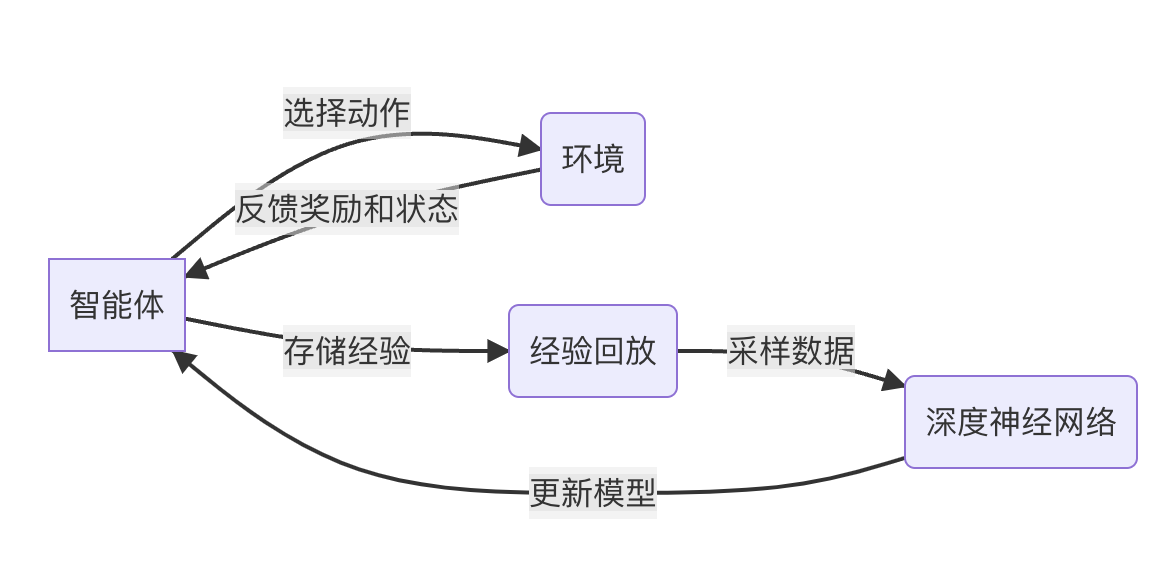
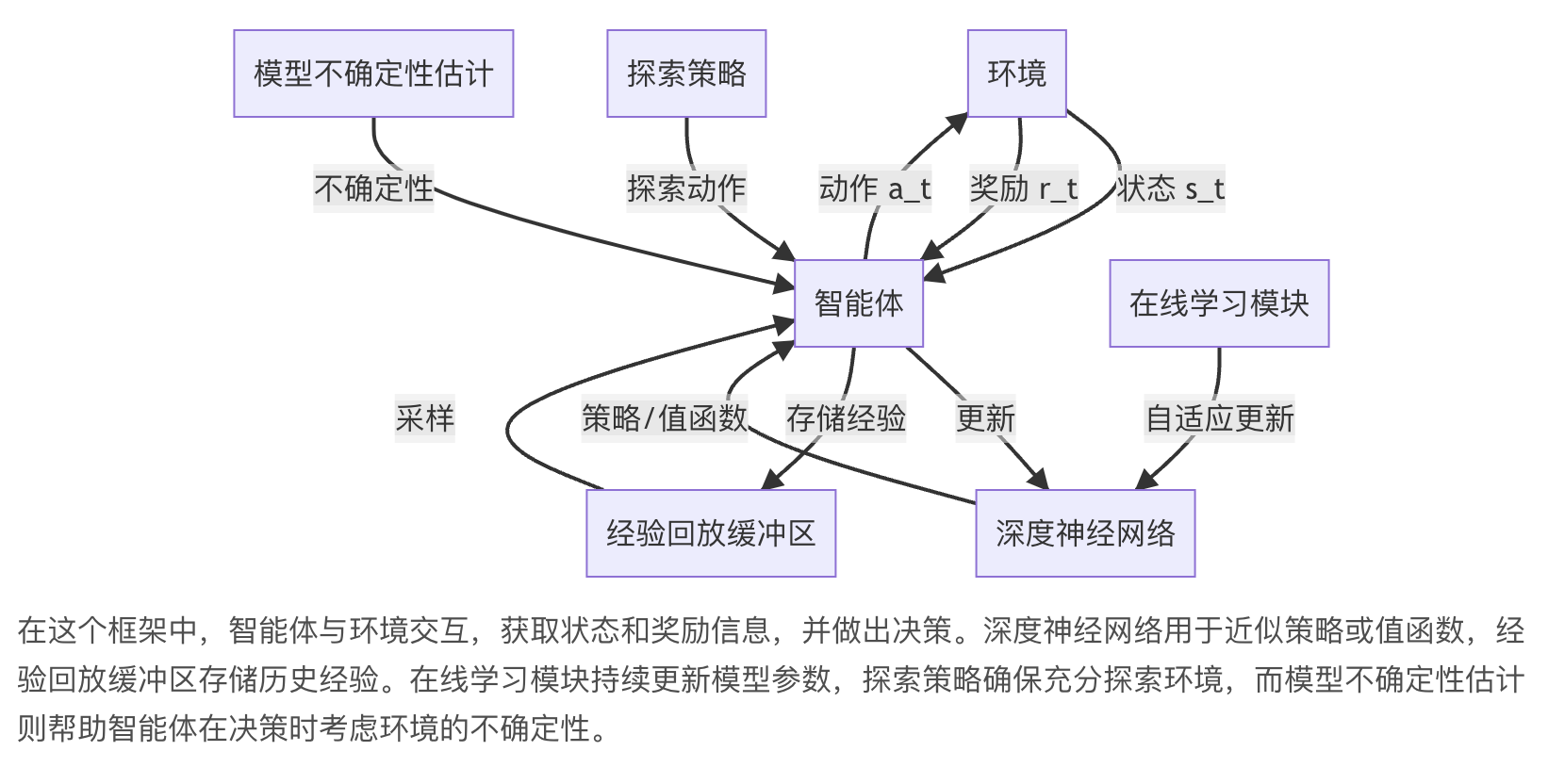
在线学习的深度强化学习——Online Reinforcement Learning for Learning
关键词:深度强化学习、在线学习、策略优化、探索与利用、自适应算法、连续决策、实时交互
1. 背景介绍
在人工智能和机器学习领域,深度强化学习(Deep Reinforcement Learning,DRL)已经成为一个备受关注的研究方向。传统的强化学习方法在处理高维状态空间和复杂决策问题时往往力不从心,而深度强化学习通过结合深度学习的强大表示能力,极大地扩展了强化学习的应用范围。然而,在实际应用中,我们常常面临着动态变化的环境和持续输入的数据流,这就要求学习算法能够实时地适应新的情况,不断调整和优化决策策略。
在线学习(Online Learning) 作为机器学习的一个重要分支,专门解决在连续数据流中进行实时学习和预测的问题。
将在线学习的思想引入深度强化学习,形成了一个新的研究方向——在线深度强化学习(Online Deep Reinforcement Learning)。
这种方法能够在不断变化的环境中持续学习,实时更新模型,从而在动态场景中表现出色。
本文将深入探讨在线学习的深

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3266
3266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











