







前言:核心知识点总结
1. 回溯针对的是什么问题?
能够用回溯解决的问题,都有一个共同特点,就是过程可以抽象为一颗多叉树,其实使用回溯最难的部分就是如何将问题抽象为多叉树,只要这一部分解决,后面都是套路
大概就是如果一个题,可以理解为从一个选择集合中,选取一些元素来组成结果,那么就能尝试使用回溯
注意:文中的path和track是一个意思都表示当前选择过的路径,不同时期写的代码导致变量名不一样而已
回溯法,一般可以解决如下几种问题:
- 一、组合子集问题:N个数里面按一定规则找出k个数的集合,或者找出子集
组合和子集问题结构一样,只是何时将path加入res有区别而已
- 二、排列问题:N个数按一定规则全排列,有几种排列方式
由于每层都要取遍所有元素,因此要使用一个used数组去重
- 三、切割问题:一个字符串按一定规则有几种切割方式
和子集组合问题一样,只是选取加入path的方法不一样
- 四、棋盘问题:N皇后,解数独等等
每次都对整个棋盘进行操作







如何解决:
通过暴力搜索
2. 去重和剪枝
虽说回溯是暴力搜索,但是完全遍历所有可能性,会出现重复结果,如果我们先得到结果,然后对结果使用set来去重,复杂度会很高,效率低下,因此一般都是在遍历的过程中进行去重的

根据上面的图,我们将为了使得去重的逻辑更加清晰,将去重分为两部分:树枝去重和树层去重
(1)树枝去重
树枝其实就是指path,我们保证path中,对已经选择过的元素不进行重复选择,如果我们涉及到要对之前选择过的元素进行重复选择,那么就要用一个used数组来对path中的值进行标定,使得树枝(path)中不重复
最典型的就是排列问题:

(2)树层去重-非常重要
1.如果不要求重复选择之前使用过的元素,我们就可以在对每层处理时,跳过选择集合中所有处理过的元素,也即是从一个新的起点start开始
比如子集/组合问题:
2.在每一层中,选择要进行回溯处理的元素时,如果选择集合里有相同的元素,就可能造成这一层中,一颗子树是另一颗子树的子集,要进行这样的去重,一般有两种方法
1:如果结果对顺序没有任何要求,那么就先对选择集合进行排序,将相同的元素放到一起,每次只选择所有相同元素中的第一个,具体操作就是判断当前选择是否和上一次的选择相同,如果相同就跳过,代码实现如下:

2.如果对顺序要求敏感,那就每一层单独使用一个set来存放选择过的元素,用set来去重,代码实现如下:

(3)剪枝
这个就比较灵活了,需要结合实际情况具体分析,有些时候我们遍历得到的结果不重复,但是可能走到某一步我们就知道按这样的路径走下去结果肯定是错的,也就没有必要走完这条路,需要提前终止
比如这里要求count==n,如果某一步我们发现count > n就可以提前终止了

3.细节问题
1:回溯的变量于数组放在外部和放在递归中的具体区别-引出隐式回溯
结论:
显式回溯:
for(int i=start;i<s.size();i++){
if(!isvalid(s,start,i))break;
track.push_back(s.substr(start,i-start+1));
track.push_back(".");
count++;
backtracking(s,i+1);
count--;
track.pop_back();
track.pop_back();
}隐式回溯:
(注意能这样写的,没有进行显式的撤销,是因为我们传入的count必须是传值调用,也就是每次传入都复制一份进行处理,而不是只对同一个count进行处理)
for(int i=start;i<s.size();i++){
if(!isvalid(s,start,i))break;
track.push_back(s.substr(start,i-start+1));
track.push_back(".");
backtracking(s,count+1,i+1);
track.pop_back();
track.pop_back();
}两者是一样的,只是有时候push_back这样的操作不能写为隐式,就只能写为显式,本质上没有任何差别
详细解释:
问题引入:
在93. 复原 IP 地址 - 力扣(LeetCode)中由于需要计算点的个数,引入count计数,于是发现count的两种写法:
1:count为外部变量,设定初值0,不放入递归中:
for(int i=start;i<s.size();i++){
if(!isvalid(s,start,i))break;
track.push_back(s.substr(start,i-start+1));
track.push_back(".");
count++;
backtracking(s,i+1);
count--;
track.pop_back();
track.pop_back();
}2:count放入递归中,传入初值0
for(int i=start;i<s.size();i++){
if(!isvalid(s,start,i))break;
track.push_back(s.substr(start,i-start+1));
track.push_back(".");
count++;
backtracking(s,i+1,count);
count--;
track.pop_back();
track.pop_back();
}接着开始探究内外部的影响
想起了二叉树中求所有路径的一题,实现代码如下:
class Solution {
public:
vector<string> res;
void traverse(TreeNode* root,string s){
if(!root){
return;
}
s += to_string(root->val);
if(!root->left && !root->right){
res.push_back(s);
return;
}
//注意要输出后再放->,因为最后一位是数字
s += "->";
traverse(root->left,s);
traverse(root->right,s);
}
vector<string> binaryTreePaths(TreeNode* root) {
string tmp;
traverse(root,tmp);
return res;
}
};
我发现这里和上面存在区别那就是在外部修改了,然后把参数传入内部,并没有回收就达到了回溯的效果
对比这两题,其实就能弄明白回溯时外部变量和内部变量的区别
首先我们观察求路径的题目,可以发现s没有使用&,也就是说每个递归里面的s变化是相互独立的,这一点非常非常重要,当我们在前序修改s时,其实相当于对所有递归进行一次同样的修改,因此如果把对s的操作放到中序,其他不变,就会出错,因为没有对左子树进行s的更改,这也是复原ip中我出错的地方
我一味参考求路径的代码写出如下代码:
for(int i=start;i<s.size();i++){
if(!isvalid(s,start,i))break;
track.push_back(s.substr(start,i-start+1));
track.push_back(".");
count++;
backtracking(s,track,i+1,count);
}这其实就和我刚刚分析的将操作放在的中序一样,这里相当于放在除后序外的所有序中,首先每个递归的更改不一样,其次我们指向更改一次,但是由于每一次要经历n次孩子节点,也就要进入n次递归函数,那么我们其实对track修改了n次而不是一次,理解到这一点就不难写出隐藏参数的递归了:
由于vector不能一次push两个元素进入,所有改用string进行处理,写出如下代码:
for(int i=start;i<s.size();i++){
if(!isvalid(s,start,i))break;
backtracking(s,track+s.substr(start,i-start+1)+".",i+1,count+1);
}并且注意递归中不能给要回溯的结构加&:
void backtracking(string& s,string track,int start,int count)理解到这一步我们在回过头去看复原ip中对count进行处理的两种方法其实都等价,因为都是每次进递归之前++,出递归之后--,这两种写法本质一样,都属于显式的递归
2:为什么每次pop_back能够准确pop我们想要丢掉的元素
其实解决上一个问题,这一个问题也能理解了,每次回溯都是按照如下图示进行:

那么每一次进入一个孩子后,在准备出来的时候正好trace的末尾元素是之前放入的元素;
可以从最底层理解,到了最底层会立即返回,那么肯定能够pop掉之前放入的元素,又因为我们只在队尾操作,后入先出,那么在快要进入某一个后序位置时,前面放入的元素都被pop掉了,此时队尾仍然是这个位置在前序是放入的元素!
一.回溯理论与框架
1.2 基本思路与框架
1.2.1 回溯思路
回溯法解决的问题都可以抽象为树形结构,是的,我指的是所有回溯法的问题都可以抽象为树形结构!
因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度,都构成的树的深度。
递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
1.2.2 框架
回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
如图:
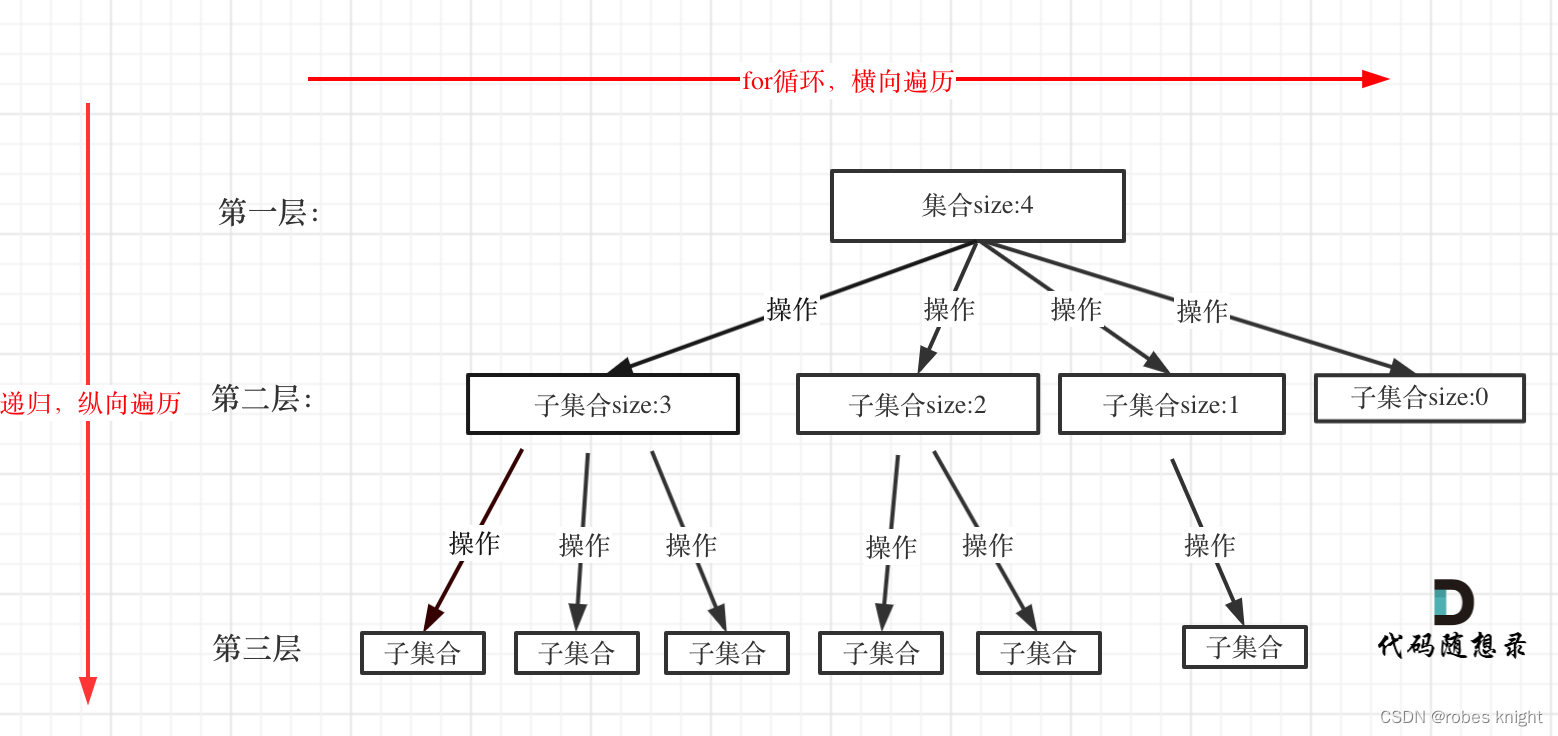

用二叉树的思想进行前后序理解
先进行层序遍历,可以理解为之前二叉树一层只有两个节点(当前节点的两个子树),这里一层有n个节点(当前选择后可以还能进行的n种选择)!!!
伪代码框架:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
(选择是否处理)
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}1.3 经典题目结合理解
1.3.1 全排列问题
抽象树构建:
1:不含重复值说明,不用考虑重复值造成的重复
2:全排列指之前用过的值不能再用了
3:不同顺序代表不同结果说明每次层序遍历时可以在整个数据中进行遍历(去除used)
4:全排列说明结果中元素个数和nums的大小一样,也就是只收集下图中第3层(0,1,2,3)的节点的排列值
used数组的作用:排除无效值,留下有用的可选择值

代码实现:
class Solution {
public:
vector<vector<int>> res;
void backtrack(vector<int>& nums,vector<int> track,vector<bool>& used){
if(track.size()==nums.size()){
res.push_back(track);
return;
}
for(int i=0;i<nums.size();i++){
if(used[i]==true)continue;
used[i] = true;
track.push_back(nums[i]);
backtrack(nums,track,used);
track.pop_back();
used[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<bool> used(nums.size(),false);
vector<int> track;
backtrack(nums,track,used);
return res;
}
};1.3.3 N皇后问题
我们先思考如何将n皇后抽象为n叉树:
我们可以把棋盘列看着树的深度,行看作树的宽度
但是我们可以发现棋盘和前面问题的差别,棋盘是一层下面堆另一层,而全排列是每个节点下面都是另一层,那么思考方式会存在一点差别
我们将一行看作一个节点,这一行的n个格子看着n个选择,那么每次传入递归的便不是一个节点而是保存当前层(行)的数组,我们对这个行数组进行操作即可

同时当一个二维数组存满就可以返回(存满n行)
判断是否选择的操作:
n皇后和全排列的第二个区别在于,判断是否满足选择条件,全排列中只有使用过的将其排除就行了,但是在n皇后中,我们的判断手段不一样,需要判断横纵斜向8个方向是否有皇后放置,这一点的处理需要我们单独使用一个函数(isvalid())实现
bool isvalid(vector<string>& board,int n,int row,int col){
for(int i = 0;i < n;i++){
if(board[row][i]=='Q')return false;
}
for(int i = 0;i < row;i++){
if(board[i][col]=='Q')return false;
}
for(int i = row - 1,j = col - 1;i >=0&&j >= 0;i--,j--){
if(board[i][j]=='Q')return false;
}
for(int i = row - 1,j = col + 1;i >=0&&j < n;i--,j++){
if(board[i][j]=='Q')return false;
}
return true;
}观察代码中发现只判断了当前行,上方一列,左上方和右上方,没有判断左下方右下方和下方,这是因为我们后面部分没有放置,还判断不了,其次,只有将当前行及其以前的行处理好了,等处理完所有行,自然整个棋盘也处理好了
代码实现:
class Solution {
public:
vector<vector<string>> res;
void backtrack(vector<string>& board,int n,int row){
if(row == n){
res.push_back(board);
return;
}
for(int i = 0;i<n;i++){
if(isvalid(board,n,row,i)){
board[row][i] = 'Q';
backtrack(board,n,row+1);
board[row][i] = '.';
}
}
}
bool isvalid(vector<string>& board,int n,int row,int col){
for(int i = 0;i < n;i++){
if(board[row][i]=='Q')return false;
}
for(int i = 0;i < row;i++){
if(board[i][col]=='Q')return false;
}
for(int i = row - 1,j = col - 1;i >=0&&j >= 0;i--,j--){
if(board[i][j]=='Q')return false;
}
for(int i = row - 1,j = col + 1;i >=0&&j < n;i--,j++){
if(board[i][j]=='Q')return false;
}
return true;
}
vector<vector<string>> solveNQueens(int n) {
vector<string> board(n,string(n,'.'));
backtrack(board,n,0);
return res;
}
};二、排列组合子集问题
无论是排列、组合还是子集问题,简单说无非就是让你从序列 nums 中以给定规则取若干元素,主要有以下几种变体:
- 形式一、元素无重不可复选,即
nums中的元素都是唯一的,每个元素最多只能被使用一次,这也是最基本的形式。
以组合为例,如果输入 nums = [2,3,6,7],和为 7 的组合应该只有 [7]。
- 形式二、元素可重不可复选,即
nums中的元素可以存在重复,每个元素最多只能被使用一次。
以组合为例,如果输入 nums = [2,5,2,1,2],和为 7 的组合应该有两种 [2,2,2,1] 和 [5,2]。
- 形式三、元素无重可复选,即
nums中的元素都是唯一的,每个元素可以被使用若干次。
以组合为例,如果输入 nums = [2,3,6,7],和为 7 的组合应该有两种 [2,2,3] 和 [7]。
当然,也可以说有第四种形式,即元素可重可复选。但既然元素可复选,那又何必存在重复元素呢?元素去重之后就等同于形式三,所以这种情况不用考虑。
上面用组合问题举的例子,但排列、组合、子集问题都可以有这三种基本形式,所以共有 9 种变化。
除此之外,题目也可以再添加各种限制条件,比如让你求和为 target 且元素个数为 k 的组合,那这么一来又可以衍生出一堆变体,怪不得面试笔试中经常考到排列组合这种基本题型。
但无论形式怎么变化,其本质就是穷举所有解,而这些解呈现树形结构,所以合理使用回溯算法框架,稍改代码框架即可把这些问题一网打尽。
2.1 子集与组合
2.1.1 子集(元素无重不可复选)

抽象为树结构:
有点类似排列的思想,先确定一个值,然后再选择剩下的值,但是和排列不一样,这是选择子集,那么不同顺序表示同一个集合,因此不仅是当前树枝(根到当前节点的一条路径)上使用过的值不能再使用了,在其他树枝(根到同一层其他节点的路径)上使用过的值也不能再使用了,也就是排列问题上进行裁剪

裁剪得到子集树:

虽说子集树是排列树的裁剪,但是直接在排列树上进行裁剪很麻烦,这里有一个很巧妙的方法进行子集树的选择列表筛选
思路分析:
对比上图,既然一个子集只能出现在一个树枝上,那么我们让其出现在前面的树枝上,也就是说每次都从当前已经选择元素后面的元素进行选择,因此我们定义一个start来存放当前遍历到了那个元素,这里有一个误区,我们会想到每次递归让当前start+1,但是实际我们需要考虑到同一层后面的元素,当遍历到后面元素时,我们的start也要变,也就是说我们在横向和纵向遍历时都要考虑使start+1,横向遍历时i++就起到了+1的效果,纵向遍历把传入参数+1可以达到效果,因此在递归中传入i+1;
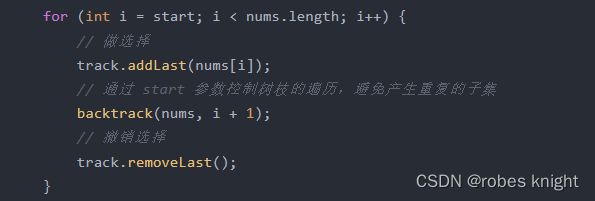
for (int i = start; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
// 通过 start 参数控制树枝的遍历,避免产生重复的子集
backtrack(nums, i + 1);
// 撤销选择
track.removeLast();
}整体代码实现:
注意这里没有写终止条件,因为start== nums.size时,不会进入for循环,也就不会进入递归,自动结束了
class Solution {
public:
vector<vector<int>> res;
vector<int> track;
void backtrack(vector<int>& nums,int start){
res.push_back(track);
// if(start== nums.size())return;
for(int i = start;i < nums.size();i++){
track.push_back(nums[i]);
// backtrack(nums,start+1);
backtrack(nums,i+1);
track.pop_back();
}
}
vector<vector<int>> subsets(vector<int>& nums) {
backtrack(nums,0);
return res;
}
};2.1.2 组合(元素无重不可复选)

抽象树结构:
我们知道组合问题就是子集问题的子集,因此同用一颗n叉树
我们要做的就是在子集问题中选择符合要求的组合,此题中选择个数=k的子集即可
代码实现:
注意1-n,所以start也是1-n变化
class Solution {
public:
vector<vector<int>> res;
vector<int> track;
void backtrack(int n,int k,int layer){
if(track.size() == k){
res.push_back(track);
}
for(int i = layer;i <= n;i++){
track.push_back(i);
backtrack(n,k,i+1);
track.pop_back();
}
}
vector<vector<int>> combine(int n, int k) {
backtrack(n,k,1);
return res;
}
};2.1.3 子集/组合(元素可重不可复选)-涉及去重
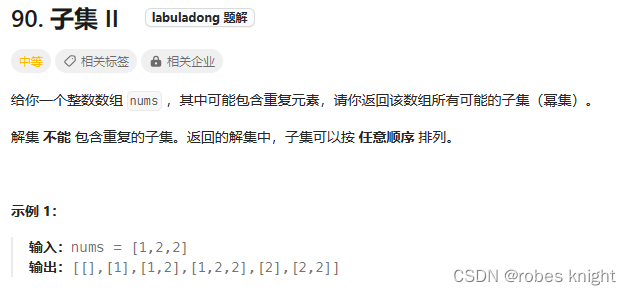
首先这是子集相关问题,所以我们使用如图的子集树进行抽象:
其次,由于nums中含有重复元素,那么我们要进行裁剪,为了方便理解,将重复的元素做上标号,我们发现即便是通过start排除了前面元素,也会出现如[1,2]和[1,2']的重复

我们想做的是如下裁剪,这里有一种做法是,先进行排序使得重复元素挨在一起,然后将多条重复元素路径只保留第一条(相同路径中的第一条,不是整个选择列表的第一条)
具体代码如下:
这里i > start并不是保留所有选择的第一条的意思,因为我们要求取i-1,那么i就应该从start+1开始也就是i > start;这里容易理解错误,特此解释!
for (int i = start; i < nums.length; i++) {
// 剪枝逻辑,值相同的相邻树枝,只遍历第一条
if (i > start && nums[i] == nums[i - 1]) {
continue;
}
track.addLast(nums[i]);
backtrack(nums, i + 1);
track.removeLast();
}整体代码实现:
class Solution {
public:
vector<vector<int>> res;
vector<int> track;
void backtracking(vector<int>& nums,int start){
res.push_back(track);
for(int i = start;i<nums.size();i++){
if(i > start && nums[i]==nums[i-1])continue;
track.push_back(nums[i]);
backtracking(nums,i+1);
track.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());
backtracking(nums,0);
return res;
}
};2.1.4 组合总和(元素无重可复选)

首先我们要想到基本的子集树:
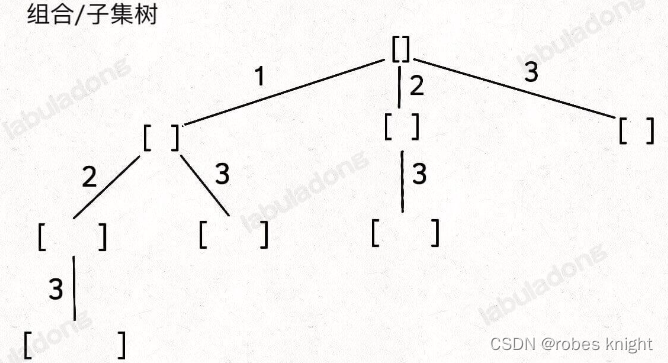
其次,这里可以重复选择,首先我们要理解重复选择的意义,也就是当前节点选择过的东西,在孩子节点中仍能够选择,同时为了保证子集结果不重复,要对当前层进行和前文一样的限制
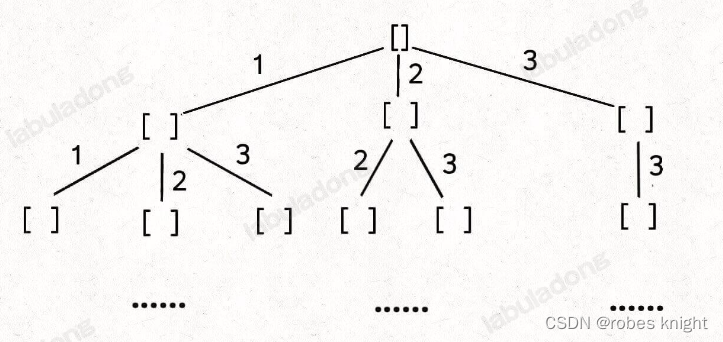 回顾我们在2.1.1中说的,i+1的意义,我们要满足对孩子节点不限制,对同层节点限制,就需要把i+1改为i:
回顾我们在2.1.1中说的,i+1的意义,我们要满足对孩子节点不限制,对同层节点限制,就需要把i+1改为i:
整体代码:
lass Solution {
public:
vector<vector<int>> res;
vector<int> track;
int sum = 0;
void backtracking(vector<int>& candidates,int target,int start){
if(sum == target){
res.push_back(track);
return;
}
if(sum > target)return;
for(int i = start;i < candidates.size();i++){
track.push_back(candidates[i]);
sum += candidates[i];
backtracking(candidates,target,start+1);
sum -= candidates[i];
track.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
backtracking(candidates,target,0);
return res;
}
};2.2 排列
2.2.1 排列(元素无重不可复选)
见1.3.1全排列问题
2.2.2 排列(元素可重不可复选)

抽象n叉树:
元素不重复的全排列如下:

但是由于元素可重复,那么就需要先进行排序,然后将重复元素只选择一次,我们借由子集问题一般会这样写出代码:
for(int i = 0;i < nums.size();i++){
if(used[i]||(i >0&&nums[i]==nums[i-1))continue;
track.push_back(nums[i]);
used[i]=true;
backtracking(nums,used);
used[i]=false;
track.pop_back();
}但是在排列中由于每次都是对整个nums进行选择,但是我们要清楚nums[i]==nums[i-1]只是进行重复元素去重,但是没有加限制到底是树枝去重还是树层去重,如果不加限制的话,会将所有重复情况去除
如果使用上述代码,结果如下,因为所有重复情况都不出现,也就是说节点中不存在含相同元素的情况,那么最终就结果就不会出现任何一个满足要求的有重复值的结果(这里四个结果都有重复值,所以一个都不存在)

实际上树枝上是可以选择相同元素的,数层上不能选择
原因:我们在树枝上选择相同元素后,由于track在不断增大,同一树枝上是不会重复的,但是要是树层上如果出现重复,会导致右边树枝里面的元素为左边树枝里面元素的子集,从而出现重复
也就是说,我们需要将去重限制在树层上
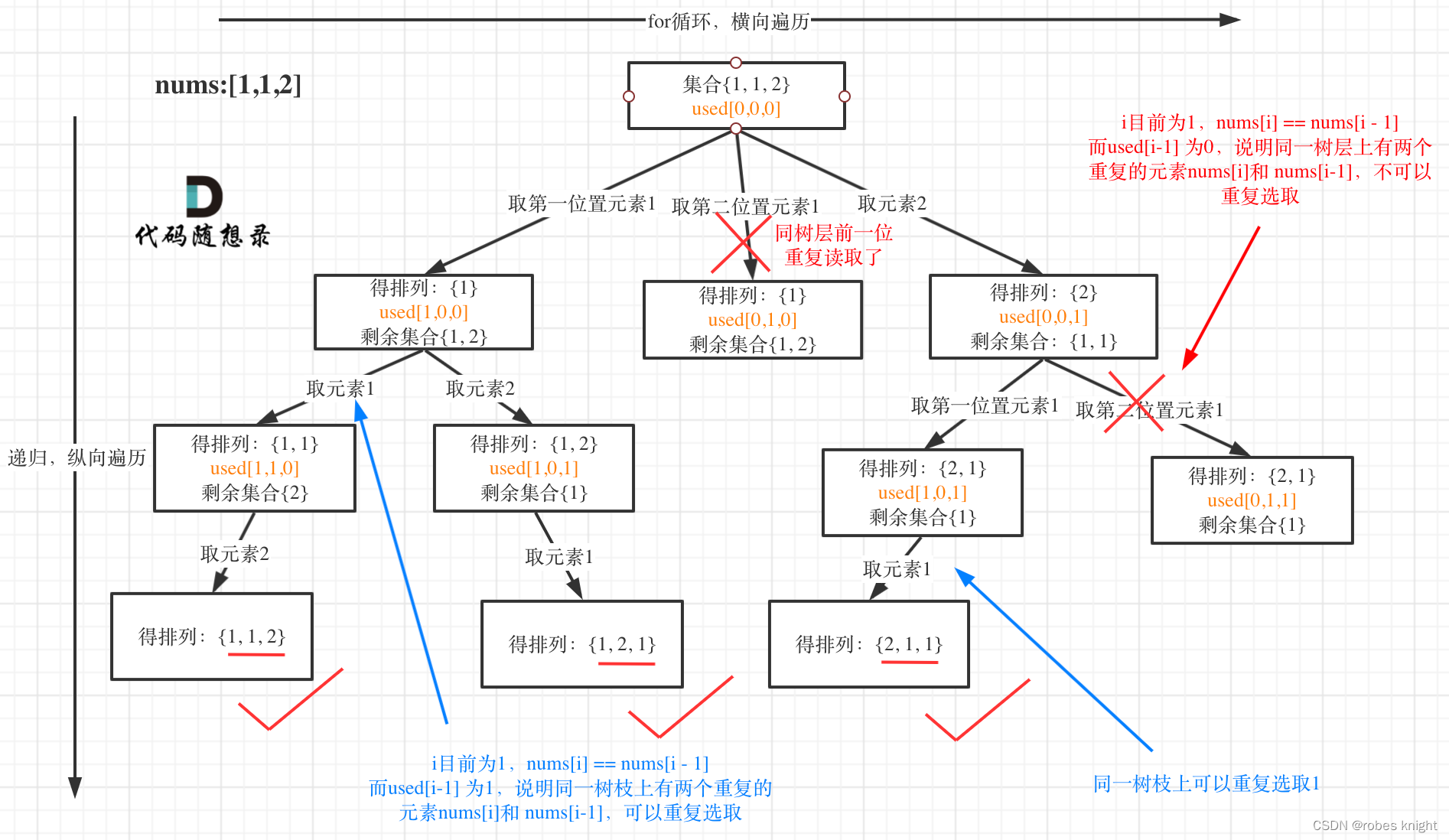
重点说明:
// used[i - 1] == true,说明同一树枝nums[i - 1]使用过
// used[i - 1] == false,说明同一树层nums[i - 1]使用过先分析同层,每次used从一个孩子到另一个孩子时,会经过回溯,那么used[i-1]就会从true变回false,所以此时表示统一树层使用过;
对于树枝上,当前节点使用了used[i]后,下一个孩子使用used[i+1],之前的used[i]仍然是true,所以used[i-1]==true表示,树枝上使用过(准确来说是第一个孩子于父节点的关系)
回到正题,我们应该如何进行树层去重呢,答案是只需要遍历到当前使用过的树层节点就跳过即可
(这里我们发现即便使用used[i-1]==true,也能通过,因为虽然是进行的树枝的去重,但是我们保留了树层,也就是说树枝树层选择一方去重即可!!!因此我们可以把上文当作对树层去重的理解,实际上树层去重效果更高)
代码实现:
class Solution {
public:
vector<vector<int>> res;
vector<int> track;
void backtracking(vector<int>& nums,vector<bool>& used){
if(track.size()==nums.size()){
res.push_back(track);
return;
}
for(int i = 0;i < nums.size();i++){
if(used[i]||(i >0&&nums[i]==nums[i-1]&& !used[i - 1]))continue;
track.push_back(nums[i]);
used[i]=true;
backtracking(nums,used);
used[i]=false;
track.pop_back();
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(),nums.end());
vector<bool> used(nums.size(),false);
backtracking(nums,used);
return res;
}
};2.2.3 排列(元素无重可复选)
leetcode上没有这种题目,因为太简单了,不重复不用进行重复元素去重,可重复选择,不用对已选择元素去重,那么就如下即可
// 回溯算法核心函数
void backtrack(int[] nums) {
// base case,到达叶子节点
if (track.size() == nums.length) {
// 收集叶子节点上的值
res.add(new LinkedList(track));
return;
}
// 回溯算法标准框架
for (int i = 0; i < nums.length; i++) {
// 做选择
track.add(nums[i]);
// 进入下一层回溯树
backtrack(nums);
// 取消选择
track.removeLast();
}2.3 分割
分割问题可以看作子集问题,但是如果我们完全用子集问题的思路处理分割问题,那么在处理一下比较特殊的分割问题时,会难以解决
三、回溯的应用
3.1.1 递增子序列-set去重- 不打乱顺序
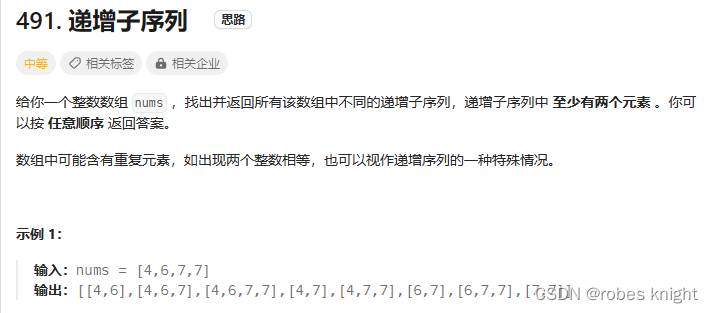
此题主要难点在于如何进行去重,因为我们不能通过先排序的方法进行去重,有些nums不是升序,如果先排一次序,那么就会导致结构被破坏
我的错误解法,想先通过双指针将nums过滤为只剩下升序的部分,然后用老办法解决,写出如下代码:
class Solution {
public:
vector<vector<int>> res;
vector<int> trace;
void backtracking(vector<int>& nums,int start){
if(trace.size()>1){
res.push_back(trace);
}
for(int i = start;i <nums.size();i++){
if(start < i && nums[i]==nums[i-1])continue;
trace.push_back(nums[i]);
backtracking(nums,i+1);
trace.pop_back();
}
}
void build(vector<int>& nums){
int l=0,r=1;
while(r<nums.size()){
if(nums[l]> nums[r])r++;
else{
l++;
nums[l]=nums[r];
r++;
}
}
nums.resize(l+1);
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
if(nums.empty())return res;
build(nums);
for(int i = 0;i<nums.size();i++)
cout<<nums[i]<<endl;
backtracking(nums,0);
return res;
}
};运行后发现很多例子不能通过,因为比如1,2,3,1,1我过滤后会只剩1,2,3,但其实1,1,1也算一种升序(题目给出的要求),也就是说我们不能再靠排序来进行去重了,需要改变去重方法
首先回顾元素重复的子集问题的去重,我们知道,当nums中元素有重复时,我们去重是指对树层去重,这里重写的去重方式也是针对树层去重
这里的树层去重其实非常简单,我们不要被递归回溯的思想套牢了,要想对树层操作,只需要每一层(整个递归的逻辑就是在一层中)都重新定义一个结构,然后不将这个结构传入下一层即可,所有我们可以在每一层定义一个set,遍历每个孩子节点时都记录在当前层的set里面就行,有如下代码:
unordered_set<int> used_set;
for(int i = start;i <nums.size();i++){
// if((start&&nums[i]<nums[start-1])||(used_set.find(nums[i])!=used_set.end()))continue;
if(used_set.find(nums[i])!=used_set.end())continue;
trace.push_back(nums[i]);
used_set.insert(nums[i]);
backtracking(nums,i+1);
trace.pop_back();
}同时这题要求升序排列,那么对于不够成升序的元素,我们也要去重,因为有当前的trace,所以我们只需要将选择中小于trace末尾元素的部分去除即可,写出如下代码:
unordered_set<int> used_set;
for(int i = start;i <nums.size();i++){
if((!trace.empty()&&nums[i]<trace.back())||(used_set.find(nums[i])!=used_set.end()))continue;
trace.push_back(nums[i]);
used_set.insert(nums[i]);
backtracking(nums,i+1);
trace.pop_back();
}整体代码如下:
class Solution {
public:
vector<vector<int>> res;
vector<int> trace;
void backtracking(vector<int>& nums,int start){
if(trace.size()>1){
res.push_back(trace);
}
unordered_set<int> used_set;
for(int i = start;i <nums.size();i++){
if((!trace.empty()&&nums[i]<trace.back())||(used_set.find(nums[i])!=used_set.end()))continue;
trace.push_back(nums[i]);
used_set.insert(nums[i]);
backtracking(nums,i+1);
trace.pop_back();
}
}
vector<vector<int>> findSubsequences(vector<int>& nums) {
backtracking(nums,0);
return res;
}
};3.2 电话号码字母组合

这个问题看着像是子集问题,其实更像棋盘问题,因为每一次我们进行的选择都是不一样的,并不是像子集问题一样使用同样的选择列表;N皇后问题也是如此,每次选择的都是其中的一列,而不是所有列(后面做到解数独我们会发现N皇后这么做是为了简化操作,如果每次都为了简化不必要操作才从上次遍历过的行之后开始,其实也可以每次都对整个棋盘遍历,但是效率低),这里我们抽象一个广义的棋盘出来,0-9当作行,每个数字对应的字母为行中的元素,写出如下代码:
string lettermap[10]={
"",
"",
"abc",
"def",
"ghi",
"jkl",
"mno",
"pqrs",
"tuv",
"wxyz",
};其余操作和N皇后非常类似,完整代码如下:
class Solution {
public:
vector<string> res;
string track;
string lettermap[10]={
"",
"",
"abc",
"def",
"ghi",
"jkl",
"mno",
"pqrs",
"tuv",
"wxyz",
};
void backtracking(string& digits,int k){
if(track.size()==digits.size()){
res.push_back(track);
return;
}
int num = digits[k] - '0';
for(int i = 0;i < lettermap[num].size();i++){
track.push_back(lettermap[num][i]);
backtracking(digits,k+1);
track.pop_back();
}
}
vector<string> letterCombinations(string digits){
track.clear();
res.clear();
if(digits.size()==0)return res;
backtracking(digits,0);
return res;
}
};
3.3 分割回文串

属于子集问题一类,此题重点在于如何判断回文串,我们使用双指针可以写出一个简单的判断子集是否回文的代码,如下:
bool isPalindrome(string s,int l,int r){
int size = (r-l)/2 + l;
for(int i = l,j=r;i<=size;i++,j--){
if(s[i]!=s[j])return false;
}
return true;
}其余部分和一般的子集问题很相似,值得注意的是我们对子段的处理,因为前文都是处理单个元素,这里是处理一段,听上去不一样,但其实代码一样,其中要重点关注截取子段的代码,代码如下:
for(int i = start;i<s.size();i++){
if(!isPalindrome(s,start,i))continue;
track.push_back(s.substr(start,i-start+1));
backtracking(s,i+1);
track.pop_back();
}完整代码如下:
class Solution {
public:
vector<vector<string>> res;
vector<string> track;
bool isPalindrome(string s,int l,int r){
int size = (r-l)/2 + l;
for(int i = l,j=r;i<=size;i++,j--){
if(s[i]!=s[j])return false;
}
return true;
}
void backtracking(string& s,int start){
if(start >= s.size()){
res.push_back(track);
return;
}
for(int i = start;i<s.size();i++){
if(!isPalindrome(s,start,i))continue;
track.push_back(s.substr(start,i-start+1));
backtracking(s,i+1);
track.pop_back();
}
}
vector<vector<string>> partition(string s) {
res.clear();
track.clear();
backtracking(s,0);
return res;
}
};3.4 复原ip地址

本体也属于子集问题,因为涉及到对子段的处理,所以更像分割回文串问题,我们按照回文串思想做题即可,主要区别在于:
1.判断条件不同
我们需要判断一段数据是否满足ip段的条件,主要有三个条件,1:;首位不能为0(除非是单个0),2:位数在1-3,3:一段的值在0-255之间(这部分处理很精妙),有如下代码:
bool isvalid(string s,int l,int r){
if(s[l]=='0'&&l!=r)return false;
if(r-l>=3 || r - l<0)return false;
int value=0;//一定记得初始化
for(int i =l;i <=r;i++){
if(s[i]>'9'||s[i]<'0')return false;
value = value*10 + (s[i]-'0');//太妙了!!!!
if(value > 255 || value <0)return false;
}
return true;
}2.终止条件不同
这里既不是单纯判断放入track数据段数据数量,也不是遍历到选择列表末尾,而是判断当放入四个数据后且达到列表末尾就终止,为了判断有多少次放入,我们还使用了count来进行计数,有如下代码:
void backtracking(string& s,int start,int& count){
if(count == 4 && start==s.size()){
string tmp;
for(int i = 0;i <track.size();i++){
tmp+=track[i];
}
tmp.pop_back();
res.push_back(tmp);
return;
}
if(count > 4)return;
for(int i=start;i<s.size();i++){
if(!isvalid(s,start,i))break;
track.push_back(s.substr(start,i-start+1));
track.push_back(".");
count++;
backtracking(s,i+1,count);
count--;
track.pop_back();
track.pop_back();
}有完整代码如下:
class Solution {
public:
vector<string> res;
vector<string> track;
bool isvalid(string s,int l,int r){
if(s[l]=='0'&&l!=r)return false;
if(r-l>=3 || r - l<0)return false;
int value=0;//一定记得初始化
for(int i =l;i <=r;i++){
if(s[i]>'9'||s[i]<'0')return false;
value = value*10 + (s[i]-'0');//太妙了!!!!
if(value > 255 || value <0)return false;
}
return true;
}
void backtracking(string& s,int start,int& count){
if(count == 4 && start==s.size()){
string tmp;
for(int i = 0;i <track.size();i++){
tmp+=track[i];
}
tmp.pop_back();
res.push_back(tmp);
return;
}
if(count > 4)return;
for(int i=start;i<s.size();i++){
if(!isvalid(s,start,i))break;
track.push_back(s.substr(start,i-start+1));
track.push_back(".");
count++;
backtracking(s,i+1,count);
count--;
track.pop_back();
track.pop_back();
}
}
vector<string> restoreIpAddresses(string s) {
int count = 0;
backtracking(s,0,count);
return res;
}
};四、复杂回溯
4.1 解数独

此题第一眼看上去和N皇后很像都属于棋盘问题,但是又似乎有点不同,于是我开始尝试使用N皇后思路进行解决,这里我们要重新理一下N皇后的思路:
一开始我认为N皇后是将每一行当作一个节点,然后选择这一行的元素,这种思路其实有点问题,比较局限,因为N皇后其实也相当于每次都对整个棋盘进行选择,但这里存在两个细节
1:每次为从上次最后更新的位置继续往下走,我们才进行一个行计数,只是为了优化效率。
2:每次在一个棋盘中我们都只放一个元素,但是由于每一行正好只能放一个元素,导致了每次我们放完之后都会跳到下一行。
这两点让我觉得N皇后每次选择是在一行内而不是在整个棋盘内,这是错误的!
所以在发现这一点后认为数独问题和N皇后很像,因此准备使用N皇后思想解题
1.首先我们需要写出判断函数
要考虑的条件有当前点的行,列,已经当前点所属的九宫格里面的数之和,对于行和列很好书写代码,但是所属九宫格,如果没有巧妙的解决办法只能写出全部9个for循环,非常麻烦
因此我们采用一种比较巧妙的方法处理九宫格归属,只需要通过当前点推到所属9宫格的起点即可,代码如下:
bool isvalid(vector<vector<char>>& board,char value,int x,int y){
for(int i = 0;i <9;i++)
if(board[x][i]!='.'&&board[x][i]==value)return false;
for(int i = 0;i <9;i++)
if(board[i][y]!='.'&&board[i][y]==value)return false;
int row = (x/3)*3;
int col = (y/3)*3;
for(int i = row;i<row+3;i++)
for(int j = col;j <col+3;j++){
if(board[i][j]!='.'&&board[i][j]==value)return false;
}
return true;
}2.其次需要使用一个num来计算当前遍历到那里了,也就是从上次处理完的能放元素的点开始操作,写下来如下代码:
bool backtracking(vector<vector<char>>& board,int num){
if(num == 80)return true;
int row = num/9;
int col = num%9;
for(int i = row;i < 9;i++){
if(i == row)
for(int j = col;j < 9 ;j++){
if(board[i][j]!='.')continue;
for(char k = '0';k < '9';k++){
if(!isvalid(board,k,i,j))continue;
board[i][j] = k;
if(backtracking(board,nums+1))return true;
board[i][j] = '.';
}
return false;
}
else
for(int j = 0;j < 9;j++){
if(board[i][j]!='.')continue;
for(char k = '0';k < '9';k++){
if(!isvalid(board,k,i,j))continue;
board[i][j] = k;
if(backtracking(board,num+1))return true;
board[i][j] = '.';
}
return false;
}
}
return true;
}运行后发生段错误,访问了非法内存,分析发现是由于每次num不应该+1,而是+最近两次空白的距离,如果我只+1,那么遍历完整个board后也不能将num=80,那么就会访问到越界内存从而报错
我想在此基础上更改,但是发现一个关键问题,很难找到最近两次的空白的距离,因为并没有办法在递归函数中一下就找到下一个空白位置,所以这种做法很难实现
bool返回值+整张棋盘遍历:
因此选择不适用num的方案,也就是每次都遍历整个棋盘,这样虽然复杂度更高,但是操作逻辑要简单很多.
我们在遍历各个孩子的时候,因为我只需要得到一种方案即可,因此当在一个孩子中发现了正确路径时,不能像一般回溯那样继续递归其他孩子,而是直接return离开当前层,但是我们需要判断条件来区分正确孩子和错误孩子的不同处理,所以我们用返回true表示找到了正确路径,用:
if(backtracking(board))return true;来区分正确孩子(路径)和错误孩子(路径),同时我们要知道在哪里返回false
答案就是当我们把1-9都遍历也没有发现正确孩子(没有返回true),就返回false
另外这里没有终止条件,我们需要思考什么时候终止,首先我们思考终止的时候是什么样的,明显就是整张棋盘都被填满了,那么在j那一轮循环中每一个数都会被跳过,因此最终能够结束i,j两层for循环而不触及中间的return,所以我们只需要在最后面两次for结束后添加一个终止后的操作即可,也就是添加return true;
最终有如下代码:
bool backtracking(vector<vector<char>>& board){
for(int i = 0;i < 9;i++){
for(int j = 0;j < 9 ;j++){
if(board[i][j]!='.')continue;
for(char k = '1';k <= '9';k++){
if(!isvalid(board,k,i,j))continue;
board[i][j] = k;
if(backtracking(board))return true;
board[i][j] = '.';
}
return false;
}
}
return true;
}整体代码如下:
class Solution {
public:
bool isvalid(vector<vector<char>>& board,char value,int x,int y){
for(int i = 0;i <9;i++)
if(board[x][i]!='.'&&board[x][i]==value)return false;
for(int i = 0;i <9;i++)
if(board[i][y]!='.'&&board[i][y]==value)return false;
int row = (x/3)*3;
int col = (y/3)*3;
for(int i = row;i<row+3;i++)
for(int j = col;j <col+3;j++){
if(board[i][j]!='.'&&board[i][j]==value)return false;
}
return true;
}
bool backtracking(vector<vector<char>>& board){
for(int i = 0;i < 9;i++){
for(int j = 0;j < 9 ;j++){
if(board[i][j]!='.')continue;
for(char k = '1';k <= '9';k++){
if(!isvalid(board,k,i,j))continue;
board[i][j] = k;
if(backtracking(board))return true;
board[i][j] = '.';
}
return false;
}
}
return true;
}
void solveSudoku(vector<vector<char>>& board) {
backtracking(board);
}
};4.2 重新安排行程-DFS相关
















 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









