







一、BFS框架
1. bfs和dfs在运行逻辑上的区别
DFS就是回溯,每次先搜索到底,然后再回溯搜索其他路径
优点:效率高,时间复杂度低
BFS把当前能做的所有选择都选一遍,先选当前的选择,选完了再往后推进
优点:如果所有路径权重一样,那么能够选出最短路
2. 算法框架
有一种问题是:
让你在一幅「图」中找到从起点 start 到终点 target 的最近距离,这个例子听起来很枯燥,但是 BFS 算法问题其实都是在干这个事儿
其实在二叉树中就已经提到过bfs和dfs,dfs就是前中后序遍历,而bfs就是二叉树的层序遍历(只是注意二叉树没有环,所以不需要用visited数组来判断访问过的点)
其实bfs比dfs更好理解,因为不是递归,不过就是写起麻烦且效率低:
整体框架如下:
int BFS(Node start, Node target) {
queue<Node> q;
set<Node> visited;
q.push(start);
visited.insert(start);
while (!q.empty()) {
int size = q.size();
for (int i = 0; i < size; i++) {
Node cur = q.front();
q.pop();
if (cur == target)
return step;
for (Node x : cur.adj()) {
if (visited.find(x) == visited.end()) {
q.push(x);
visited.insert(x);
}
}
}
}
// 如果走到这里,说明在图中没有找到目标节点
}时间复杂度:
为O(V+E),其中V为顶点数,E为边数,需要访问所有的顶点和边才能完成遍历
空间复杂度:
在最坏情况下,即当图为完全二叉树时,BFS算法需要存储的元素数量达到O(V)级别,因此也是O(V)。
主体思想为:
1:先用一个容器(用任何容器都可以,不同容器对应不同的出入顺序,但是都能一个进一个出,只是出的顺序是顺时针还是逆时针的区别,这一点不影响代码的整体逻辑,这里选用的是使用比较广泛的队列,其实栈和数组也没问题)
2:先往队列中放入一个元素保证队列不为空,由于第一个点可以类似于根节点,所以当第一个点放入后第一层就满了(树里面的概念,对于图问题会意即可),此时得到本层的size
3:在for循环中遍历本层的所有节点的所有孩子(邻居),记得要把本层节点弹出,当遇到visited没有访问过的就进行操作,并记得将节点也放入队列中
4:由于遍历了本层的所有节点的孩子(邻居),且本层节点全部弹出,孩子全部加入到队列中,所以第一个for循环结束后q.size()仍然是本层节点数目
3. 典型场景
我们需要做这样一件事,通过start对当前位置的四个方向进行搜索
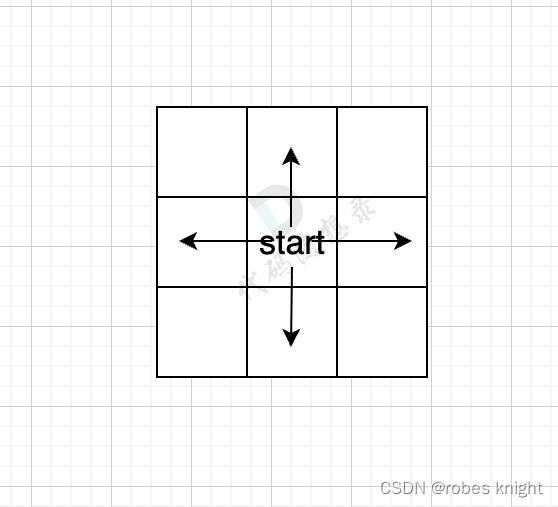
到达边界即终止,如果没有障碍,如图:
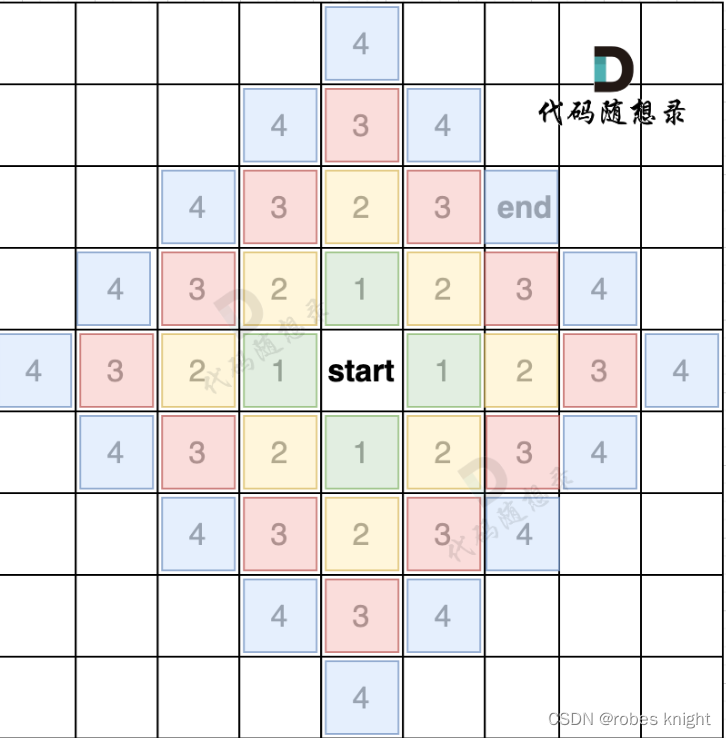
如果有障碍,如图:

具体代码如下(没有障碍版):
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向
// grid 是地图,也就是一个二维数组
// visited标记访问过的节点,不要重复访问
// x,y 表示开始搜索节点的下标
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
queue<pair<int, int>> que; // 定义队列
que.push({x, y}); // 起始节点加入队列
visited[x][y] = true; // 只要加入队列,立刻标记为访问过的节点
while(!que.empty()) { // 开始遍历队列里的元素
pair<int ,int> cur = que.front(); que.pop(); // 从队列取元素
int curx = cur.first;
int cury = cur.second; // 当前节点坐标
for (int i = 0; i < 4; i++) { // 开始想当前节点的四个方向左右上下去遍历
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1]; // 获取周边四个方向的坐标
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 坐标越界了,直接跳过
if (!visited[nextx][nexty]) { // 如果节点没被访问过
que.push({nextx, nexty}); // 队列添加该节点为下一轮要遍历的节点
visited[nextx][nexty] = true; // 只要加入队列立刻标记,避免重复访问
}
}
}
}可以是看出,在实际使用中,出了之前说的一些注意点,还要注意我们实现选择每个节点的多个孩子(主要是可以放入循环中自动多次实现)
上述代码中,我们使用dir来定义一个数组实现
二、题型演练
1. 二叉树的最小高度
此题在二叉树章节做过,不多赘述,具体代码如下:
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> que;
vector<vector<int>> res;
TreeNode* cur = root;
if(root == nullptr) return res;
que.push(cur);
while(!que.empty()){
vector<int> res1;
int size = que.size();
while(size--){
//处理当前节点
cur = que.front();
que.pop();
res1.push_back(cur->val);
//使用队列进行遍历
if(cur->left)que.push(cur->left);
if(cur->right)que.push(cur->right);
}
res.push_back(res1);
}
return res;
}
};此处引入是为方便理解bfs的框架:
可以看到此代码第一眼看上去还是和给出框架有些差别,但是仔细分析发现,其实和给出的框架如出一辙
1:给出框架内有两个for循环,用于遍历所有节点的孩子,这里只有一层循环,因为每个二叉树节点只有两个孩子,这一句便是第二层循环的简化
if(cur->left)que.push(cur->left);
if(cur->right)que.push(cur->right);2:由于二叉树没有环,所以不需要使用visited数组进行去重判断,然后对比其余操作也都几乎一样
2. 打开转盘锁

这一题其实才体现bfs的思想,因为集齐众多条件
1:首先我们分析如何转换为bfs问题,那么我们要先确定每一次拨动锁盘能够进行的选择,我们每次可以拨动四个位置总共八种选择。其次我们只需要把当前的锁的状态看作是1.3中的一个点即可
2:我们要如何做出选择,也就是定义八种转动锁盘的操作
我们其实只需要定义锁盘每一位向上和向下拨动即可,八种选择就是每一位执行这两种操作而已,写出如下代码:
string up(string s,int j){
if(s[j]!='9')s[j]+=1;
else s[j]='0';
return s;
}
string down(string s,int j){
if(s[j]!='0')s[j]-=1;
else s[j]='9';
return s;
}3:我们如何排除死亡数字,其实这里的死亡数字就是1.3中的障碍坐标,只是由于每一数字都是一个字符串,我们不能直接定位,需要用一个数据结构来查询是否遇到了障碍,存放障碍其实用什么都行,但是查询时使用比如数组会非常麻烦,那么我们考虑使用set(因为不需要返回查询结果的下标,不使用map)
同时遍历过的位置其实也是不能再次遍历的,所以和死亡数组是一个性质,我们直接放在一起即可
4:如何判断最短选择次数,因为每条路径都是相对权重(长度),所以bfs第一次访问到的target时就是最短路径,问题时在何时进行计数,一开始我错误的将sum++放在了取cur的时候
string cur = q.front();q.pop();
sum+=1;
if(cur == target)return sum;但其实这样严重重复了,并不是一共取了多少个节点路径就是多少,我们路径应该实在每一圈结束后更新,也就是在第一个大的for循环后(可以理解位二叉树的每一层)
5:其余部分参考走格子问题和二叉树问题,整体代码如下:
class Solution {
public:
string up(string s,int j){
if(s[j]!='9')s[j]+=1;
else s[j]='0';
return s;
}
string down(string s,int j){
if(s[j]!='0')s[j]-=1;
else s[j]='9';
return s;
}
int openLock(vector<string>& deadends, string target) {
int sum = 0;
queue<string> q;
unordered_set<string> visited;
for(int i=0;i<deadends.size();i++)visited.insert(deadends[i]);
q.push("0000");
if(visited.find("0000")!=visited.end())return -1;
visited.insert("0000");
while(!q.empty()){
int size = q.size();
for(int i = 0;i < size;i++){
for(int j = 0;j<4;j++){
string up_str = up(cur,j);
string down_str = down(cur,j);
if(visited.find(up_str)==visited.end()){
visited.insert(up_str);
q.push(up_str);
}
if(visited.find(down_str)==visited.end()){
visited.insert(down_str);
q.push(down_str);
}
}
}
sum+=1;
}
return -1;
}
};三、BFS优化-双向BFS
1.双向bfs概念
传统的 BFS 框架就是从起点开始向四周扩散,遇到终点时停止;而双向 BFS 则是从起点和终点同时开始扩散,当两边有交集的时候停止。
为什么这样能够能够提升效率呢?其实从 Big O 表示法分析算法复杂度的话,它俩的最坏复杂度都是 O(N),但是实际上双向 BFS 确实会快一些,我给你画两张图看一眼就明白了:
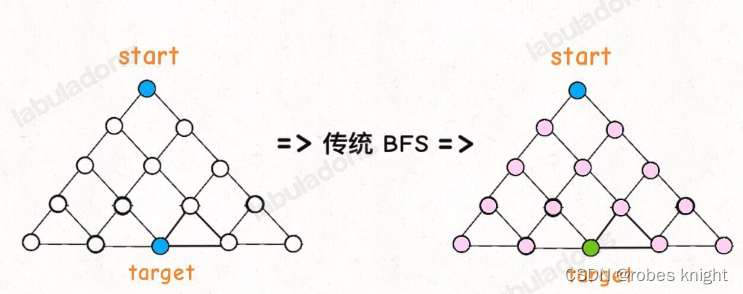
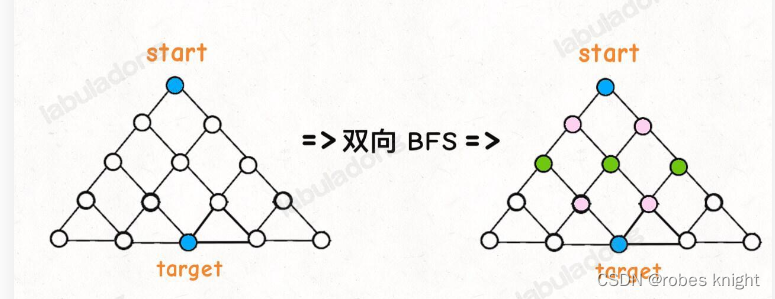
从两端收集路径,碰头后汇总为总路径
同时我们可以发现双向队列优化的一个必要条件:
必须知道终点位置
2.代码实现
代码实现是通过set存放节点,当两个set有交集碰头时就结束搜索
具体如下:
#include <vector>
#include <string>
#include <unordered_set>
#include <queue>
using namespace std;
class Solution {
public:
string up(string s, int j) {
if (s[j] != '9') s[j] += 1;
else s[j] = '0';
return s;
}
string down(string s, int j) {
if (s[j] != '0') s[j] -= 1;
else s[j] = '9';
return s;
}
int openLock(vector<string>& deadends, string target) {
unordered_set<string> dead(deadends.begin(), deadends.end());
unordered_set<string> begin, end, visited;
begin.insert("0000");
end.insert(target);
if (dead.find("0000") != dead.end() || dead.find(target) != dead.end()) return -1;
int sum = 0;
while (!begin.empty() && !end.empty()) {
// 交换begin和end,总是扩展较小的集合
if (begin.size() > end.size()) swap(begin, end);
unordered_set<string> temp;
for (auto it = begin.begin(); it != begin.end(); it++) {
string cur = *it;
if (end.find(cur) != end.end()) return sum;
visited.insert(cur);
for (int j = 0; j < 4; j++) {
string up_str = up(cur, j);
string down_str = down(cur, j);
if (visited.find(up_str) == visited.end() && dead.find(up_str) == dead.end()) {
temp.insert(up_str);
}
if (visited.find(down_str) == visited.end() && dead.find(down_str) == dead.end()) {
temp.insert(down_str);
}
}
}
swap(begin, temp);
sum++;
}
return -1;
}
};
我们从起点和终点两个位置,分别建立一个bfs,在同一个while中,进行交替更新,这样就能同时从两个点进行搜索了
如何进行更新?
代码中并没有显式的对begin和end的更新,但是我们声明了一个中间变量temp,类似层序遍历,每次temp搜集当前的最优set(begin)中的所有可选择点,然后通过swap的方式和begin进行交换,将数据存储在begin中
如果begin不是最优的,就会交换赋值给end
那么何时停止呢?
因为set中会存放接下来要检索的k个节点,那么如果两个set有交集,就代表两次搜索相交了,这时可以停下了















 1839
1839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









