







简介
比赛:https://www.kaggle.com/competitions/sorghum-id-fgvc-9
数据集是在TERRA-REF实验期间捕获的RGB图像的精选子集,按高粱的品种标记。这些数据可用于开发和评估各种植物表型模型,这些模型试图回答与是否存在理想性状有关的问题(例如,“这种植物是否表现出水分胁迫的迹象?”)。在这场比赛中,我们关注的问题是:“这张图中显示的是什么品种?”
一共有100种类别。
1.加载框架
!pip install fastai
from fastai.vision.all import *
import pandas as pd
2.数据集分析
文件结构

train_images目录下存储了用于训练的图片,train_cultival_mapping.csv有两列,第一列为训练图片的文件名,第二列为其类别
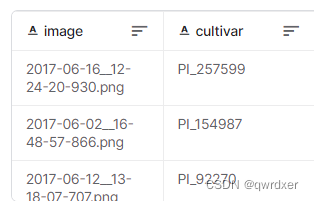
我们的构造数据集的思路是: 加载csv文件,构造DataBlock ,根据第一列的文件名获取输入(X) ,根据第二列的类别获取标签(Y)。
3.构造DataBlock
构建Learner
train_dir="/kaggle/input/sorghum-id-fgvc-9/" #
df=pd.read_csv(train_dir+"train_cultivar_mapping.csv")#读取CSV
df = df[~df['image'].str.contains('.DS_Store')] #去掉带.DS_Store的行
db = DataBlock(blocks=(ImageBlock, CategoryBlock),
splitter=RandomSplitter(valid_pct=0.1), #验证集占10%
get_x=ColReader('image', pref=str(train_dir+'train_images')+ os.path.sep),#文件名加上绝对路径
get_y=ColReader('cultivar'),# 类别
item_tfms = Resize(224),#将图片转为224x224
batch_tfms=aug_transforms()) #批处理
4.开始训练
首先获取Dataloader
dls=db.dataloaders(df)# 加载数据集
可以查看一下数据
dls.show_batch()

创建Learner
learn = vision_learner(dls, resnet18, metrics=error_rate)# 构造learner 这里默认会使用预训练完成的ResNet18,并设置卷积层为不可训练的状态
我们可以使用learn.summary()来查看模型是否可训练
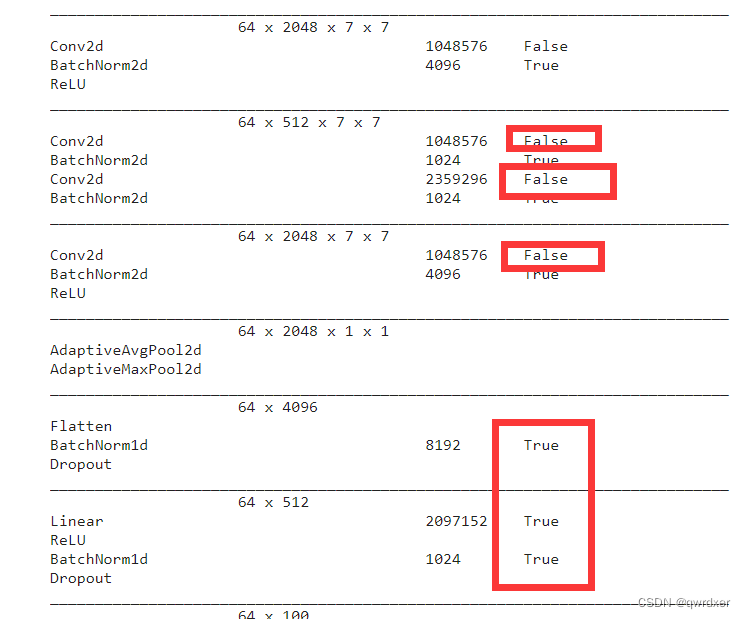
开始训练,因为类别的变化我们要先将ResNet50的全连接层训练一下来适应这个数据集,首先训练8轮, fit_one_cycle会在训练中对超参数进行自动的变化。
learn.fit_one_cycle(8,cbs=[SaveModelCallback(fname='best_model'),ShowGraphCallback()])
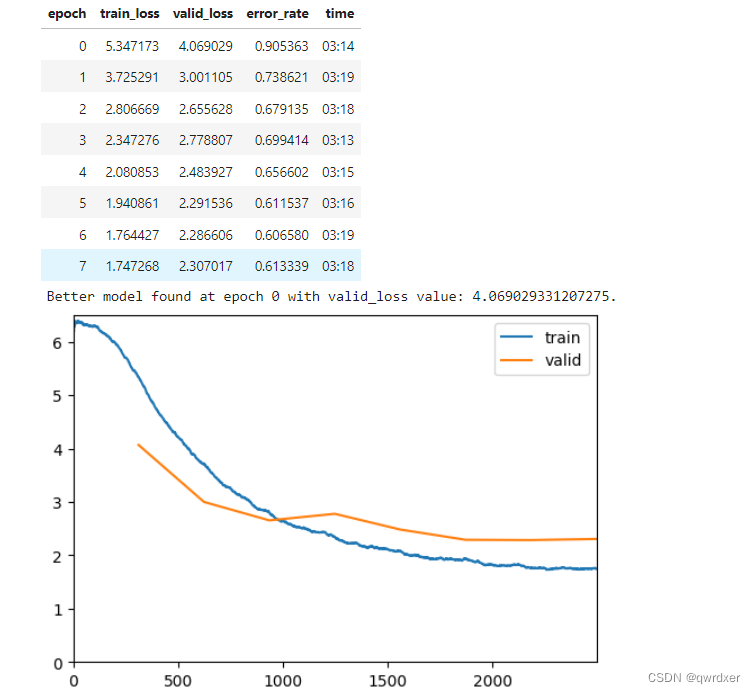
因为只对全连接层进行训练,所以效果并不太好,接下来对卷积层进行训练
learn.unfreeze()#让卷积层可以训练
learn.lr_find()#查找合适的学习率
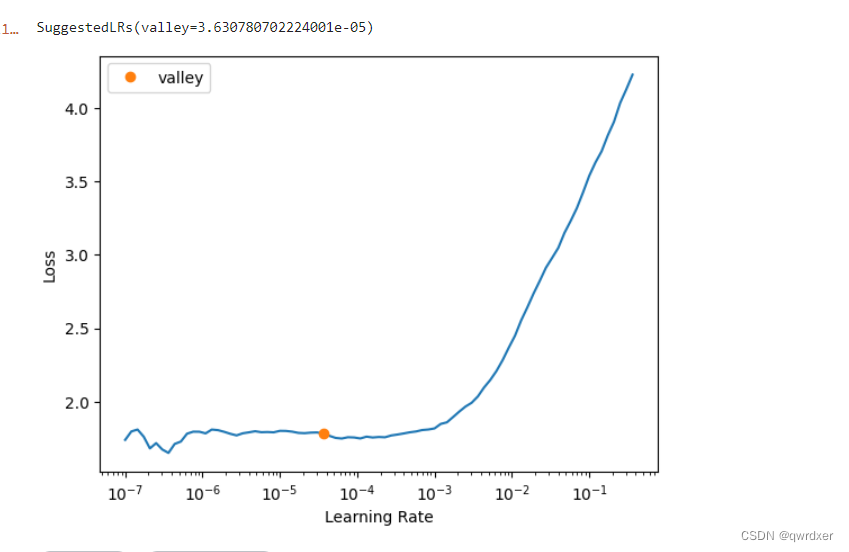
使用指定的学习率区间进行再次训练
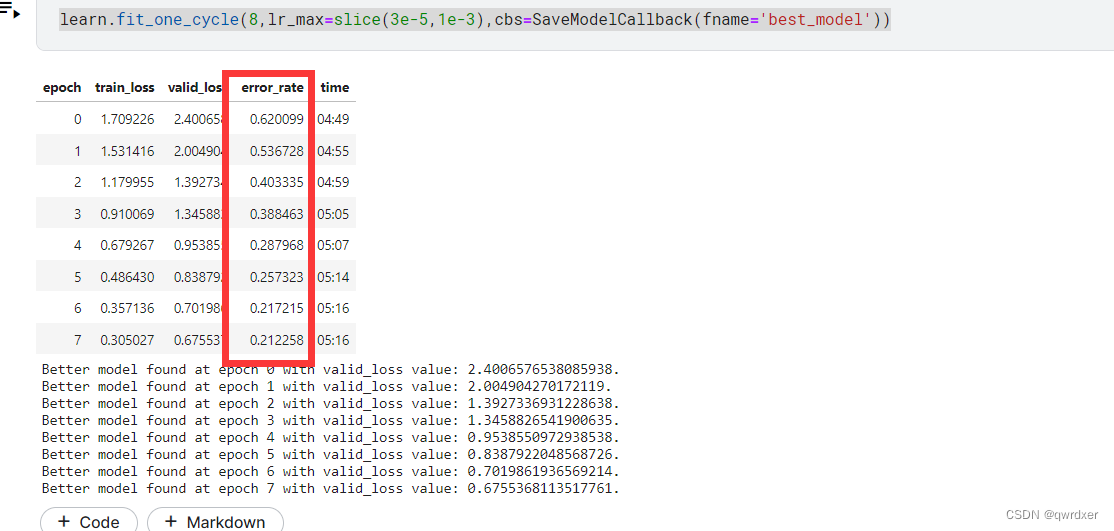
learn.fit_one_cycle(8,lr_max=slice(3e-5,1e-3),cbs=SaveModelCallback(fname='best_model'))
5.报错
训练时有个报错,上面的代码已经修改好了,这里记录一下
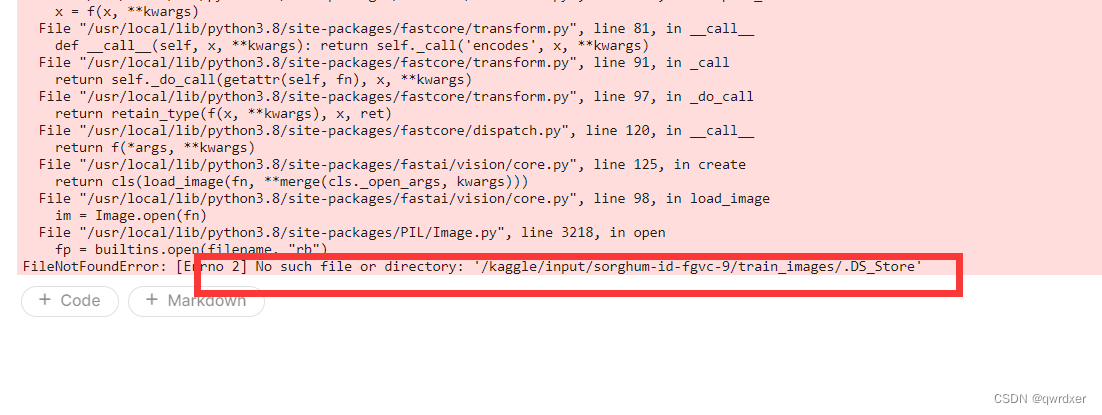
经检查是train_cultivar_mapping.csv中包含了不是标签的行。
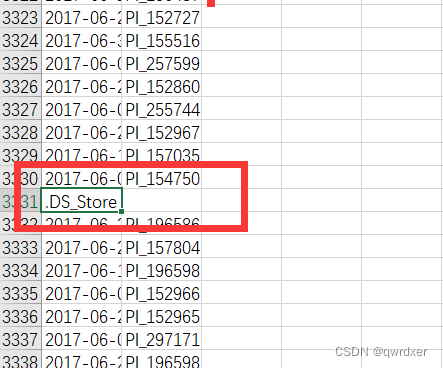
使用如下语句去掉这行即可。
df = df[~df['image'].str.contains('.DS_Store')] #去掉带.DS_Store的行
预测
from glob import glob
import random
test_dir="test"
test_list = glob(os.path.join(test_dir,"*")) #获取测试集的图片名
test_dl = dls.test_dl(test_list)# 使用dls的test_dl来加载测试集
preds=learn.get_preds(dl=test_dl) #进行预测
观察结构,第一维度为样本,第二维度为分类
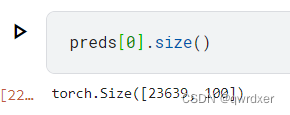
查看下标为1的样本的预测值
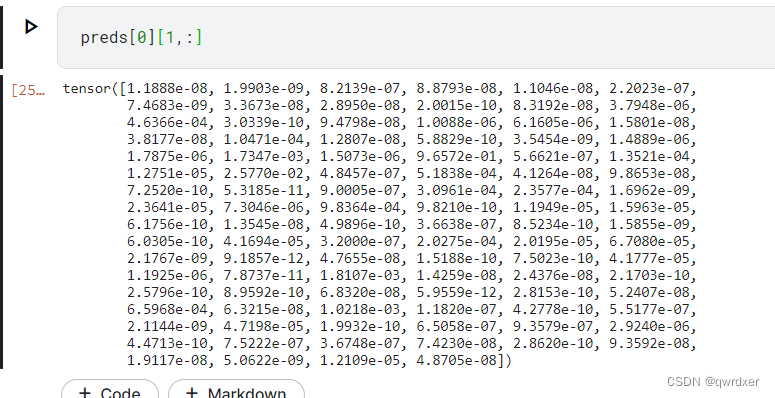
preds[0][1,:]
思路:获取最大值所在的下标,然后通过dataloder自带的字典来将其转换成标签。
import numpy as np
np_preds=np.array(preds[0][:])
max_indices = np.argmax(np_preds, axis=1)#获取下标
results = [dls.vocab[i] for i in max_indices]#通过Dataloader的字典来获取对应的标签
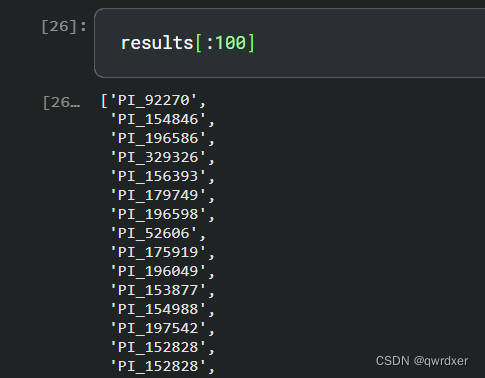
现在我们有了test_list和它对应的预测值results
test_images= [test_i.split(‘/’)[-1] for test_i in test_list] #去除test_list的路径信息只保留图片名字
submissions = pd.DataFrame(list(zip(test_images, results)), columns = [‘filename’, ‘cultivar’])
submissions.to_csv(‘submission.csv’, index = False)#保存在/kaggle/working/submission.csv















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









