







一、transformer架构
Transformer由论文《Attention is All You Need》提出,Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
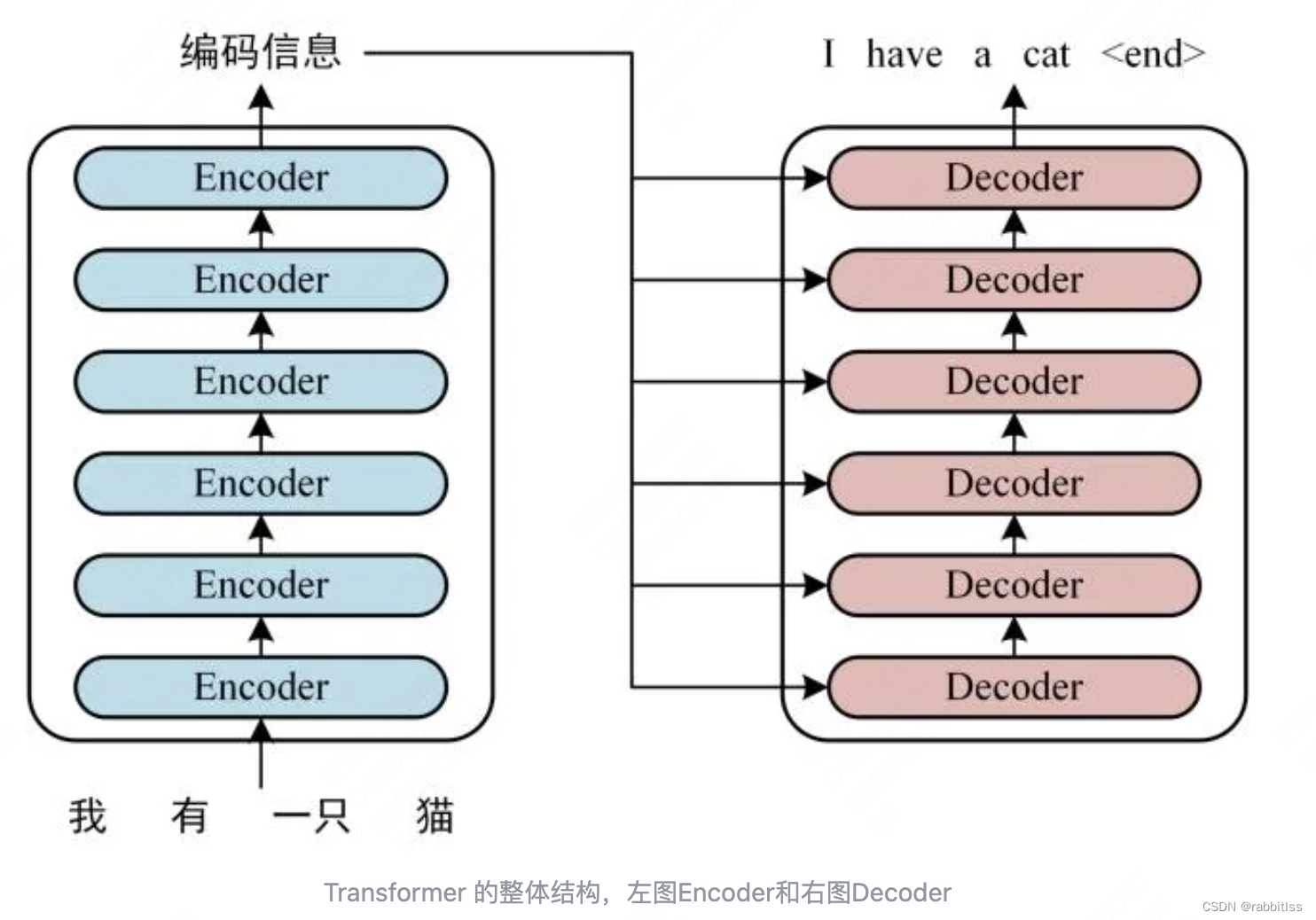
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,单词向量矩阵用表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
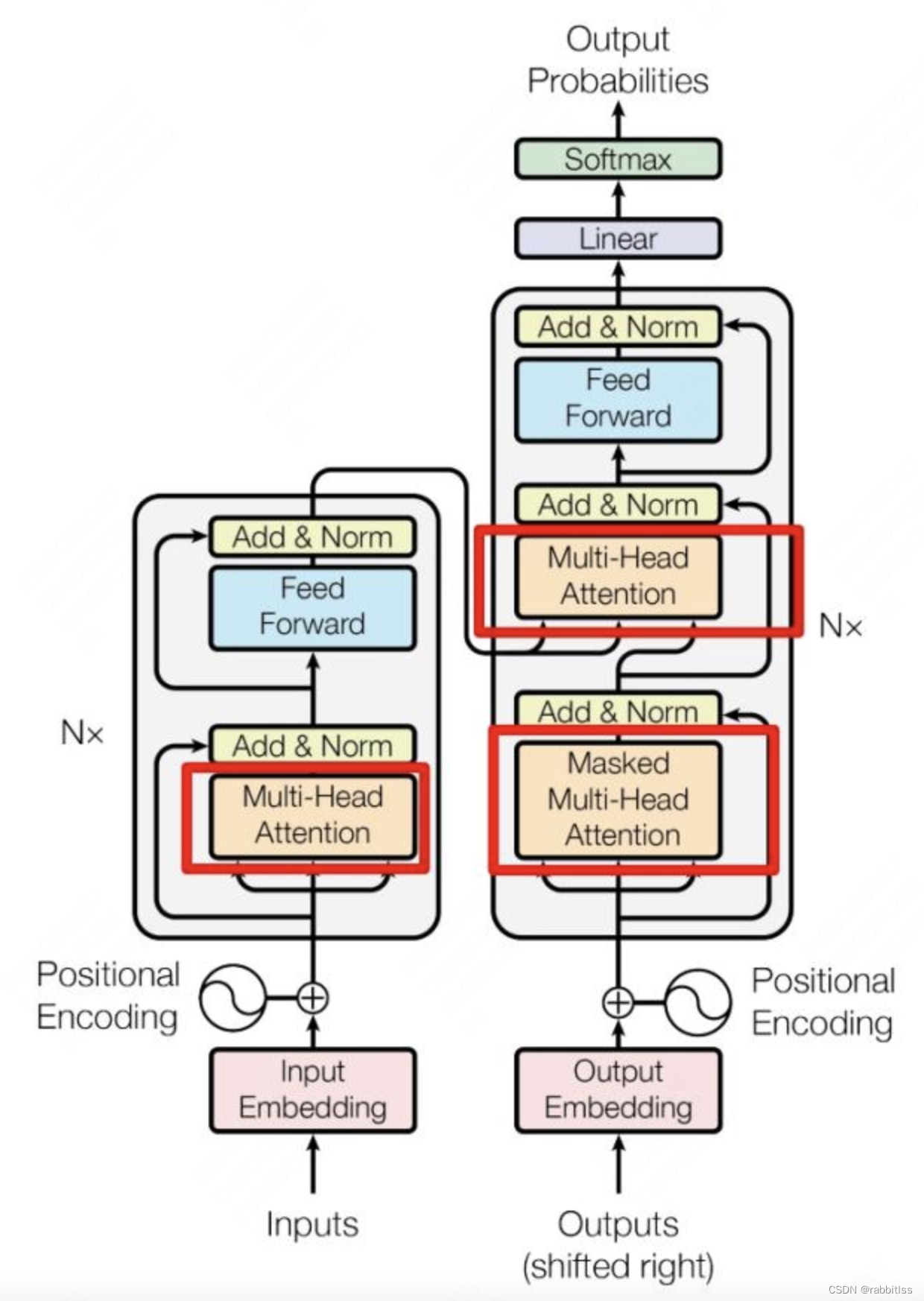
上图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
二、GPT模型
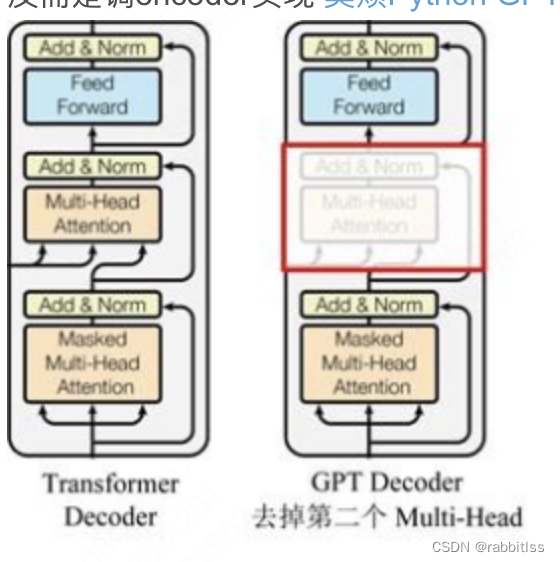
GPT 使用 Transformer的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention:
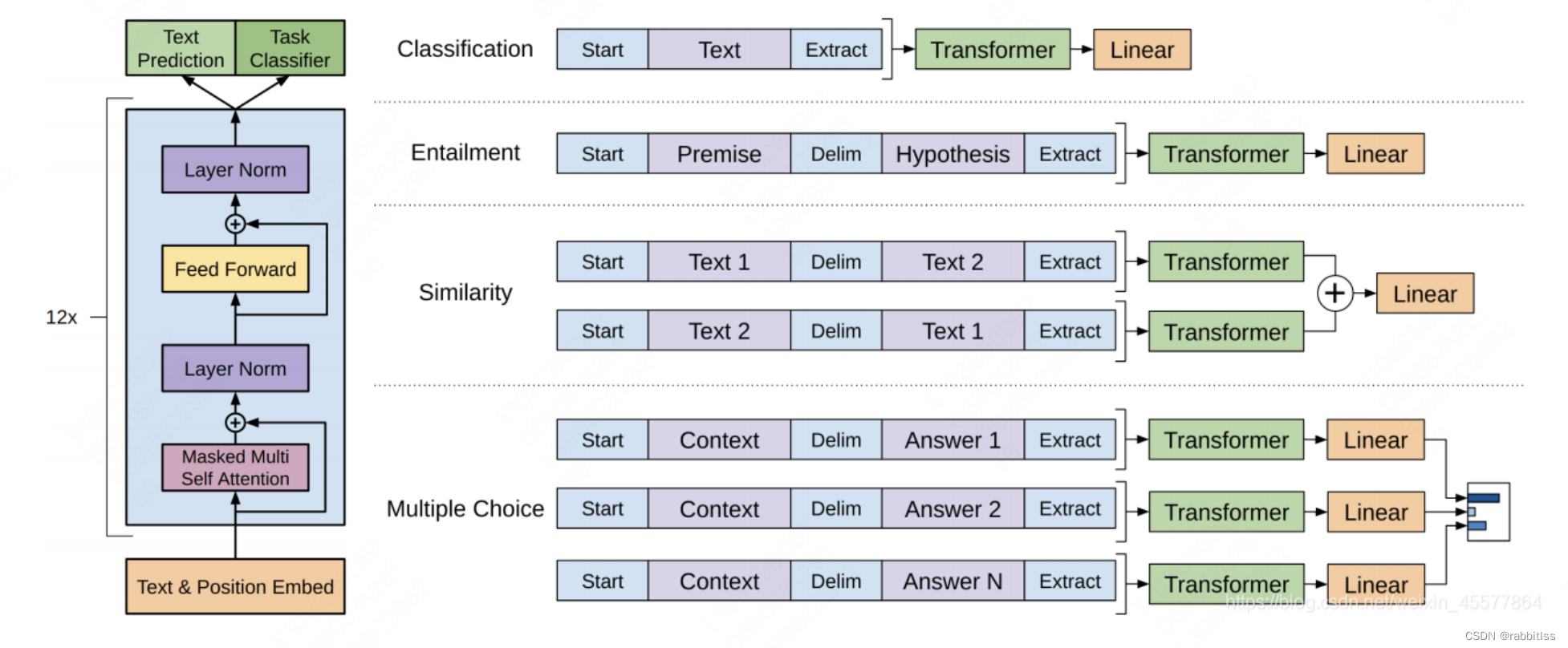
无监督的预训练和有监督的下游任务精调,核心结构:中间部分主要由12个Transformer Decoder的block堆叠而成:
三、Qwen大模型架构
1、tokenizer层
分词算法是NLP大模型最基础的组件,基于Tokenizer可以将文本转换成独立的token列表,进而转换成输入的向量成为计算机可以理解的输入形式。token化的方法有很多,按词,按句,按Bi-Gram。我们应该选择什么样的token化方式?其实每种都有自己的优缺点,在大模型之前使用按词的方式的比较常见,但是有了大模型之后,基本都是按字来了。
2、embedding
embedding 一般是指将一个内容实体映射为低维向量,从而可以获得内容之间的相似度。OpenAI 的 embedding 是计算文本与维度的相关性,默认的 ada-002 模型会将文本解析为 1536 个维度。用户可以通过文本之间的 embedding 计算相似度。
Qwen的Embedding与GPT类似。具体代码解析下一task再补充。
3、hidden stage
词汇经过tokenizer后,然后经过Embedding层变成一个词向量,称之为一个hidden_stage.
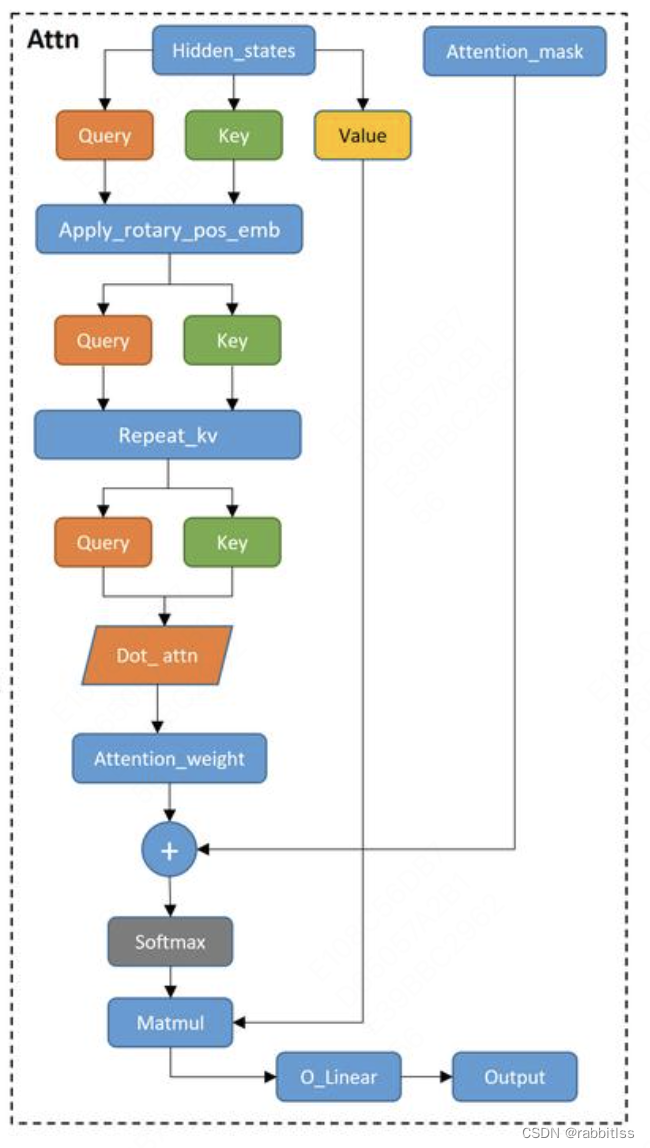
4、attention
注意力机制图如下:
self-attention
我们先来了解一下self-attention(自注意力机制),下图是一个self attention 的结构:
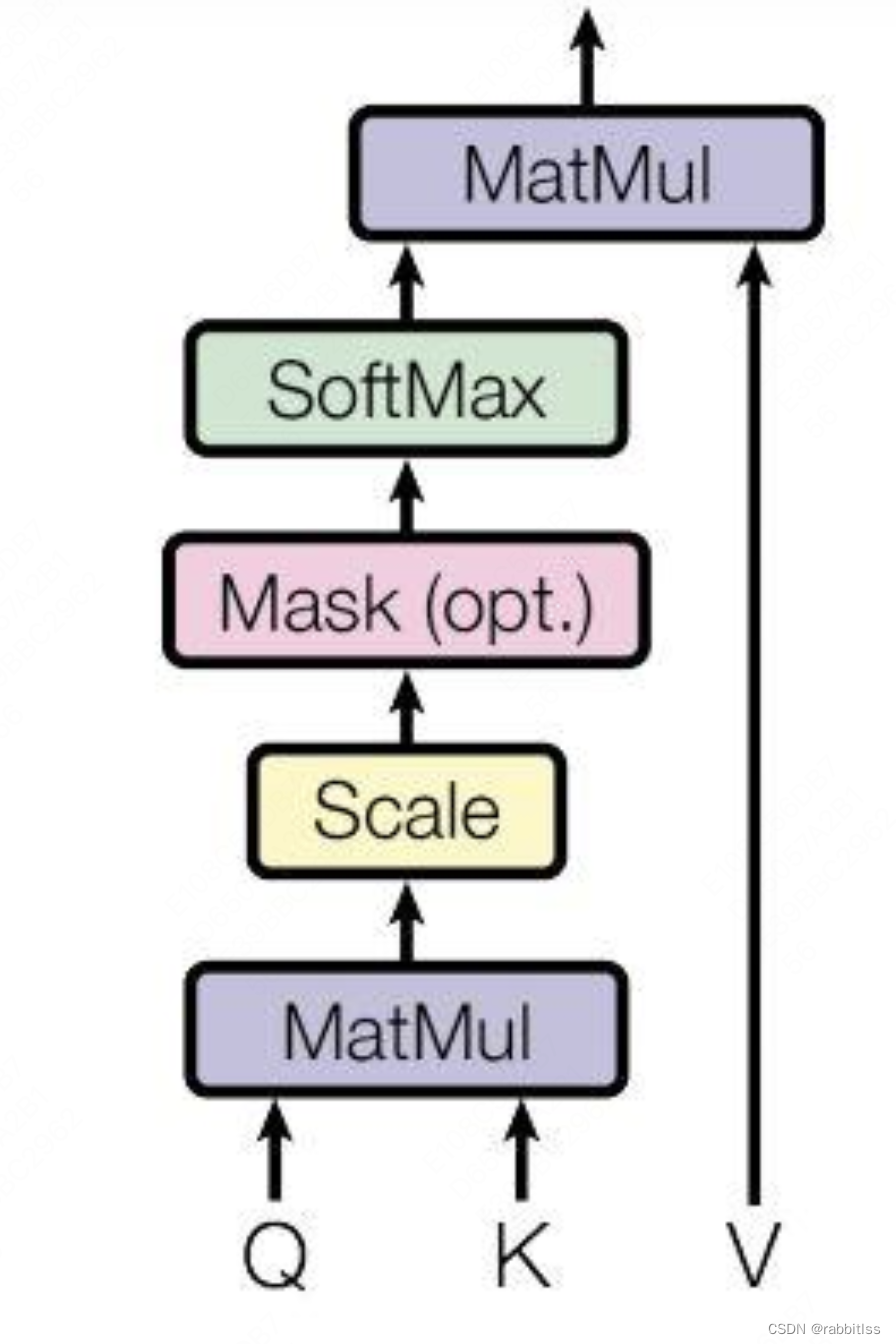
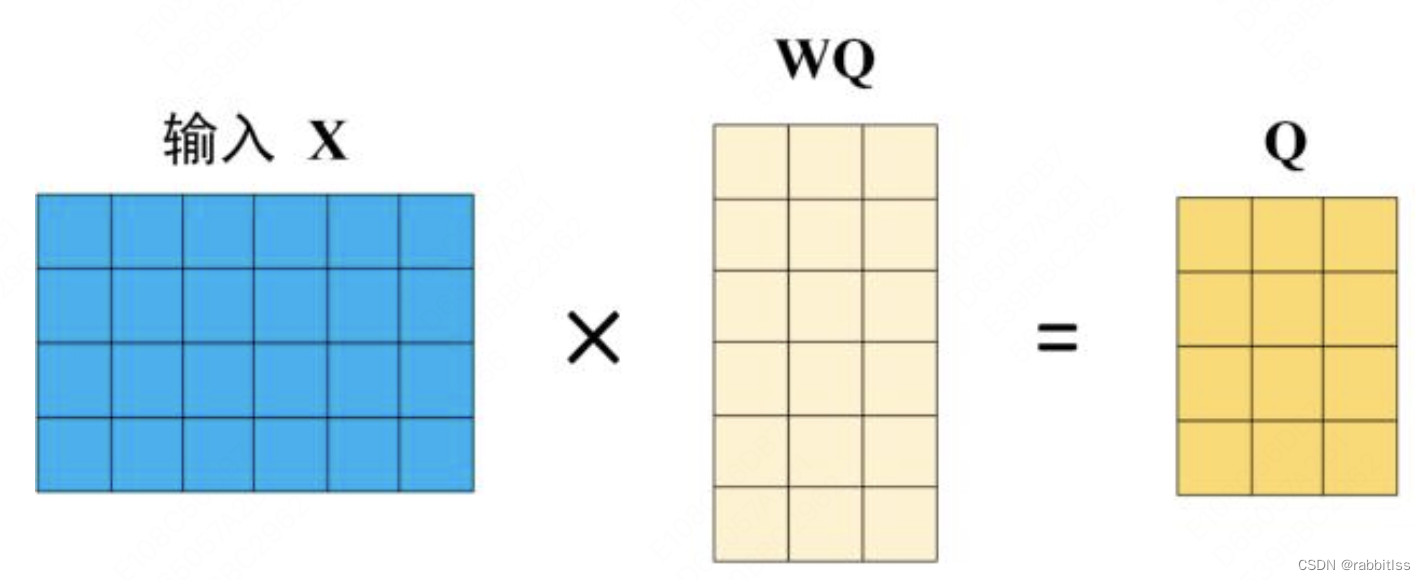
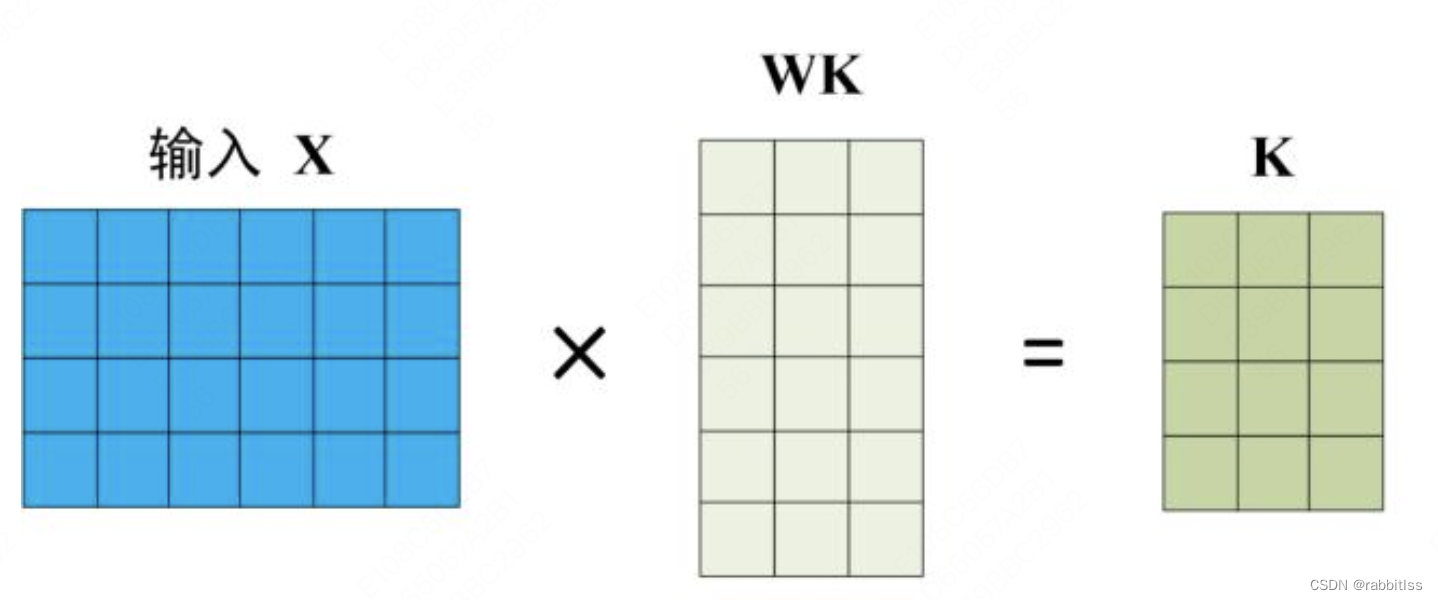
在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。Q、K、V的计算:
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
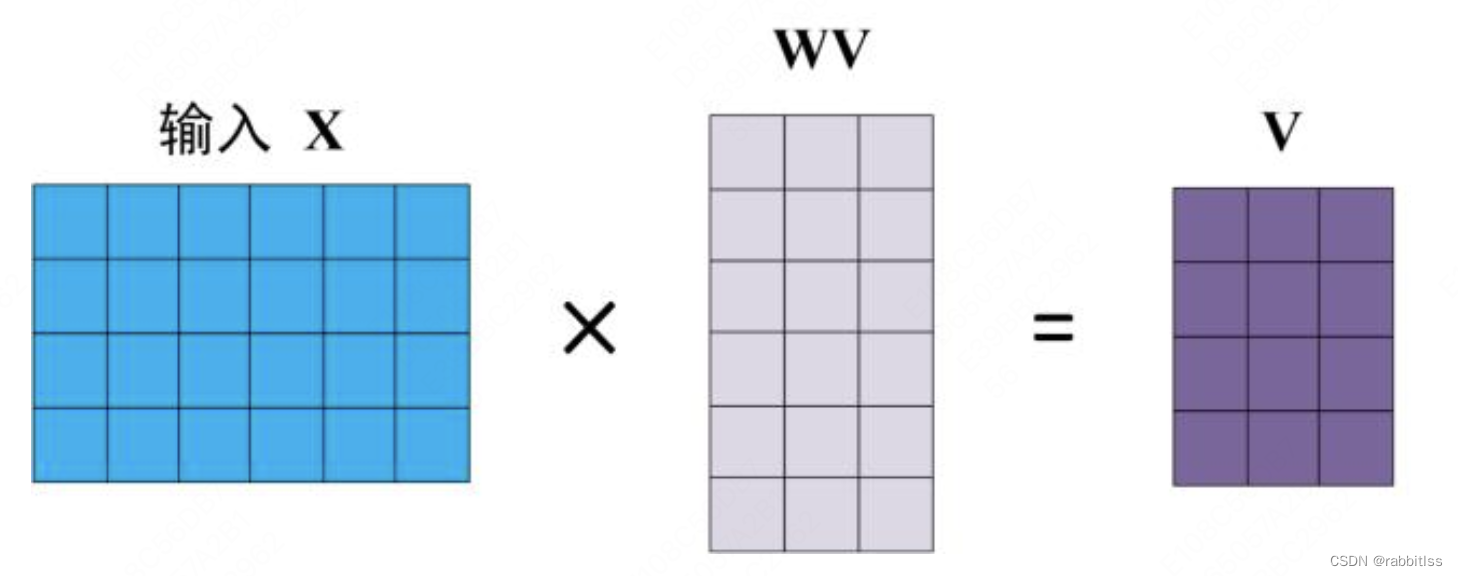
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了:

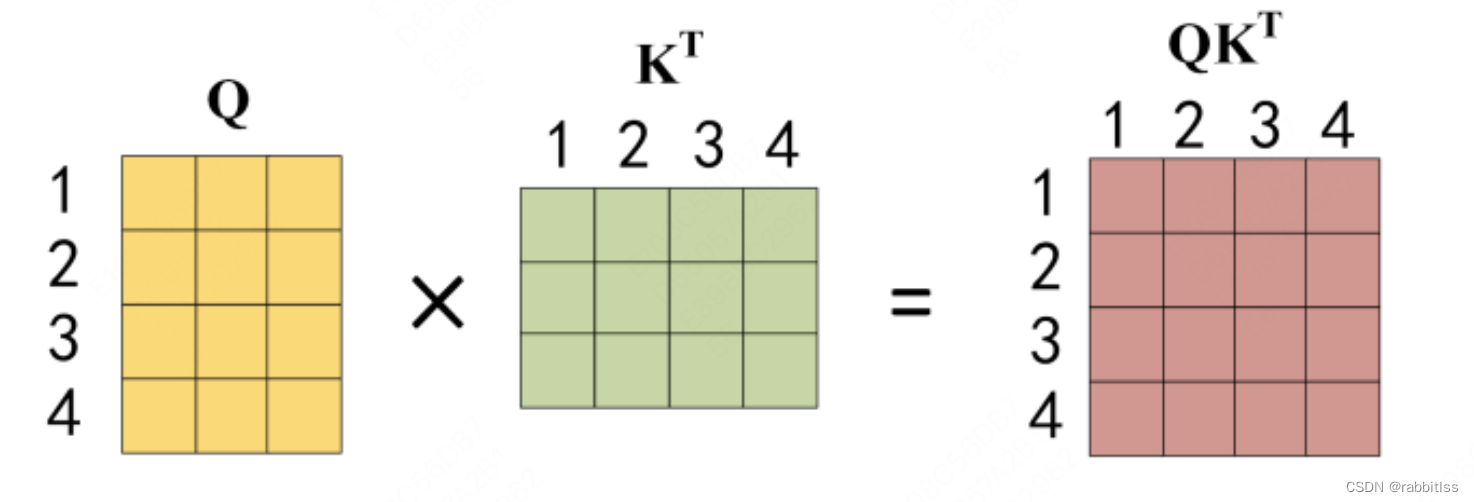
公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以
的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q乘以
,1234 表示的是句子中的单词。
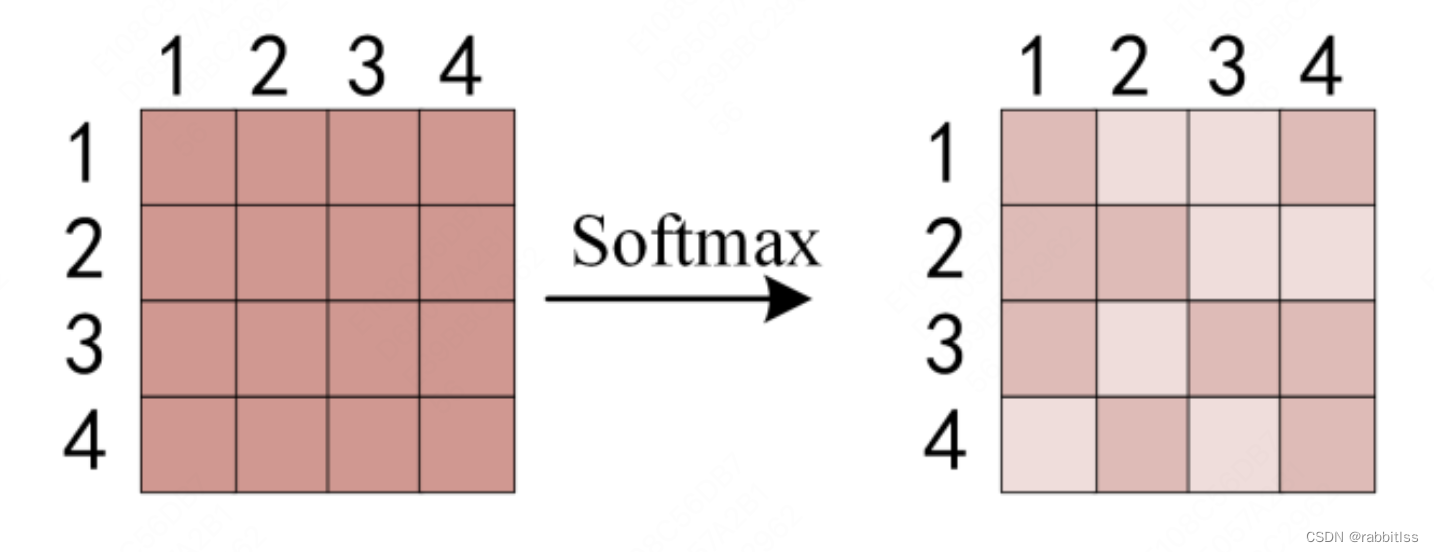
接着再使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1.
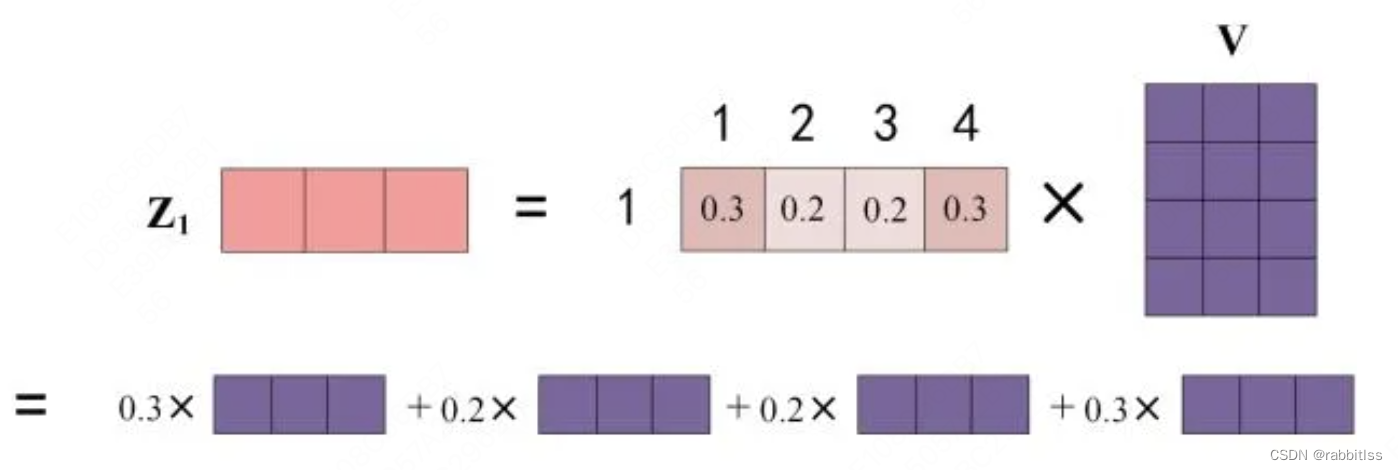
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z:
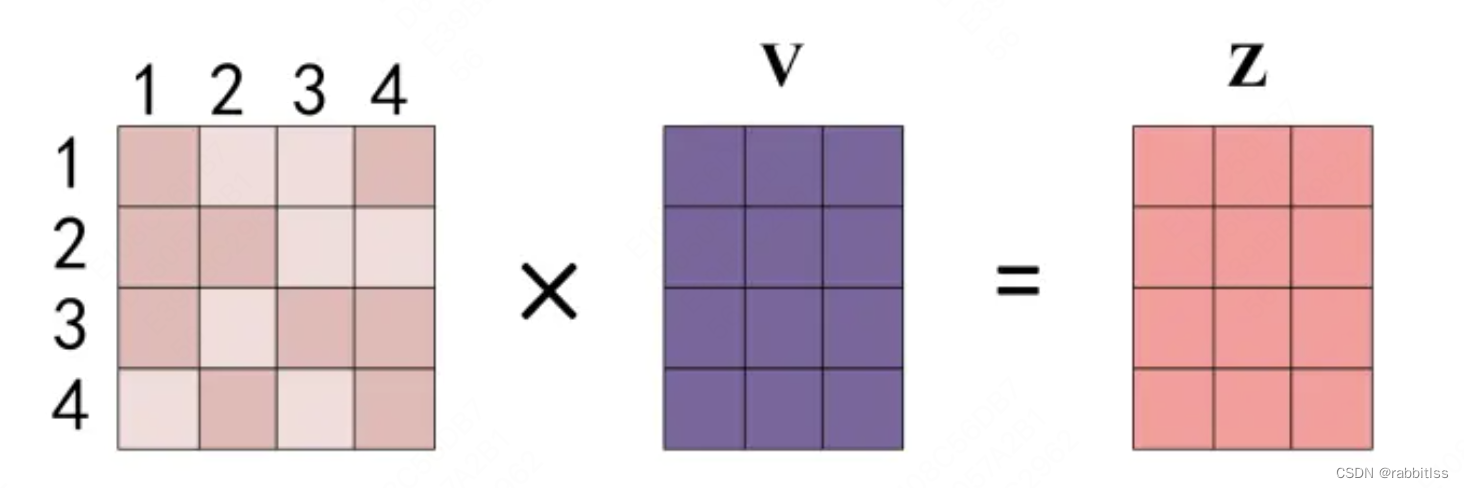
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 等于所有单词 i 的值 。根据 attention 系数的比例加在一起得到,如下图所示:
multi-head attention
然后我们来看multi-head attention, Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图:
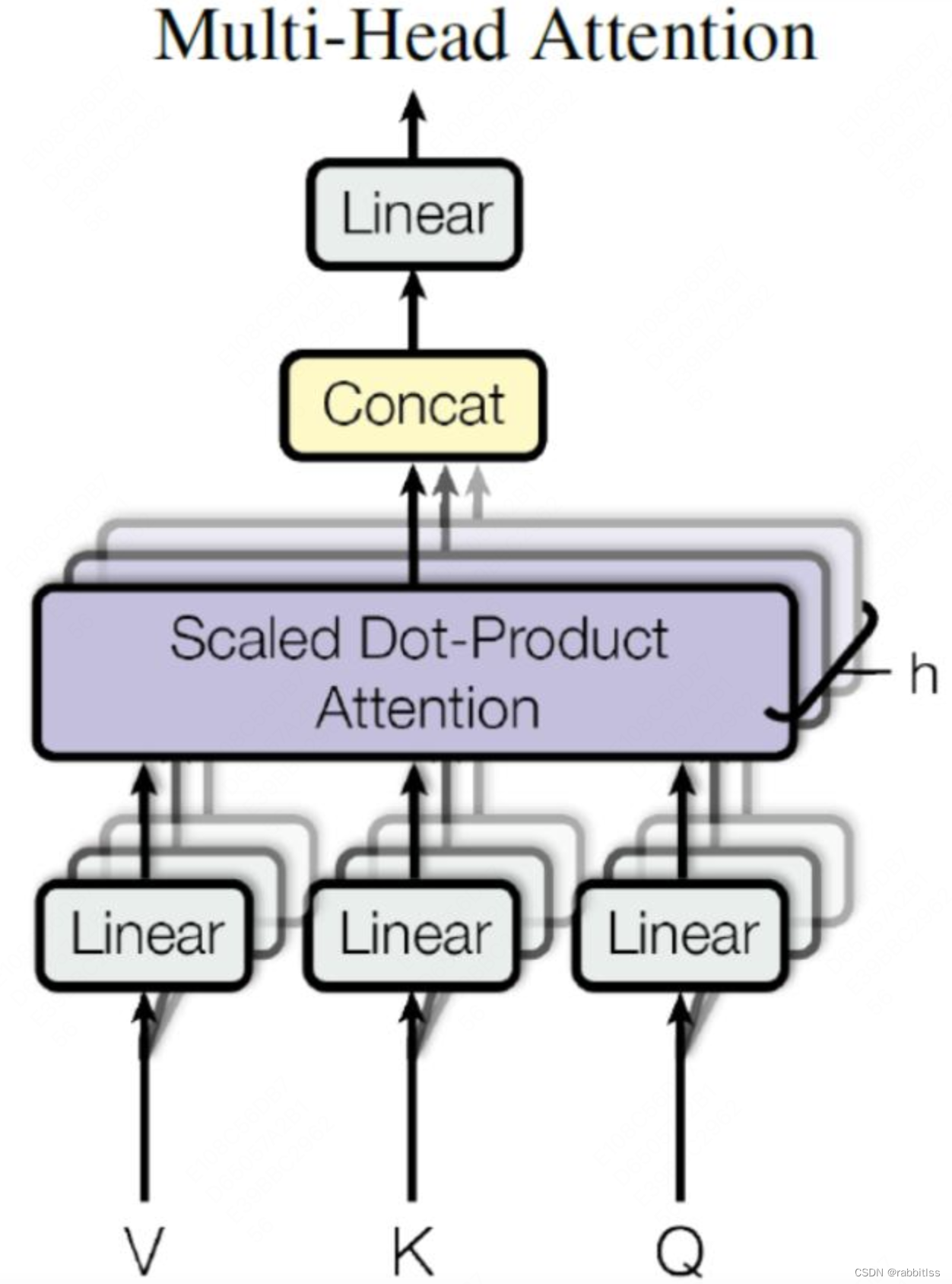
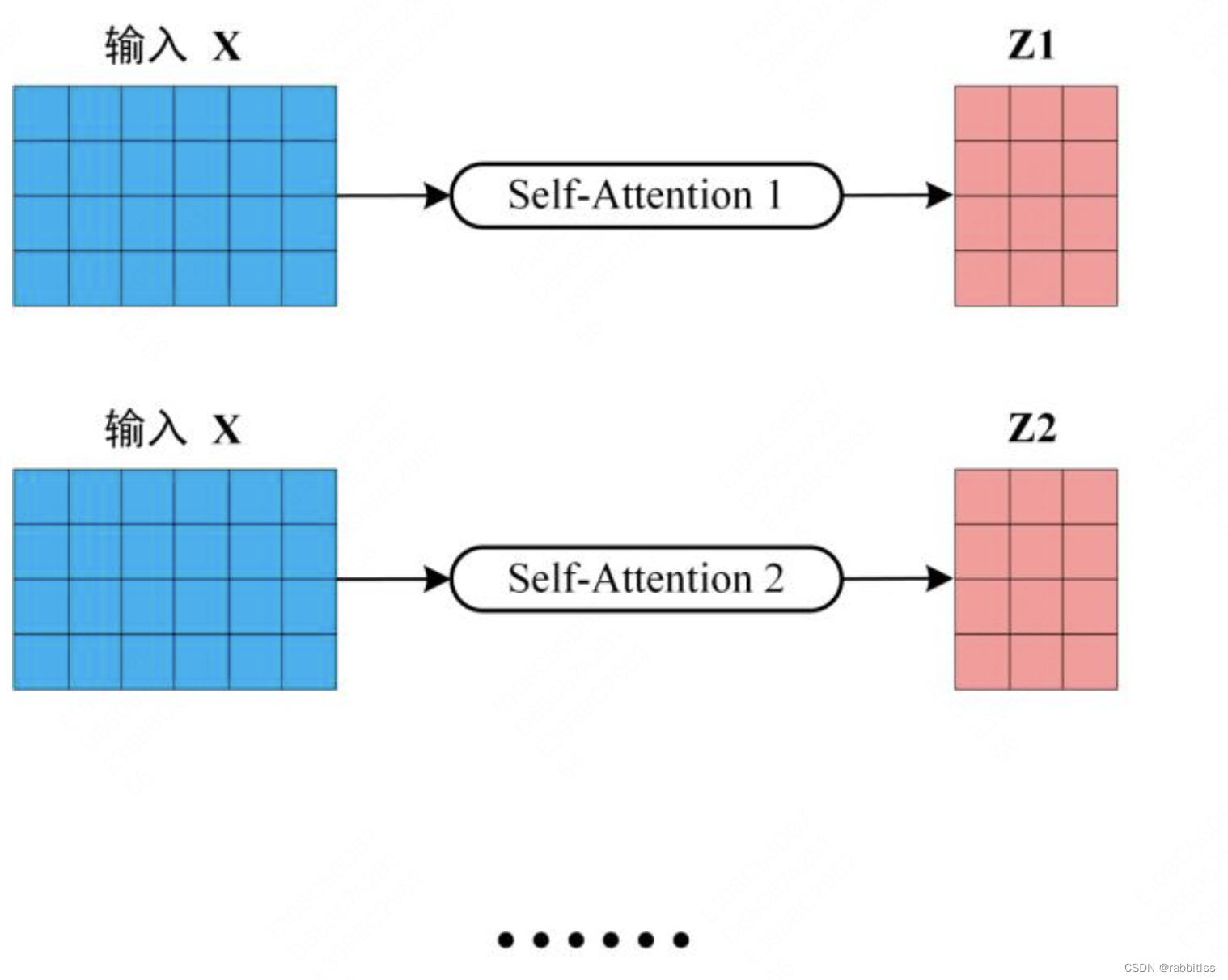
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。
得到 8 个输出矩阵 到 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
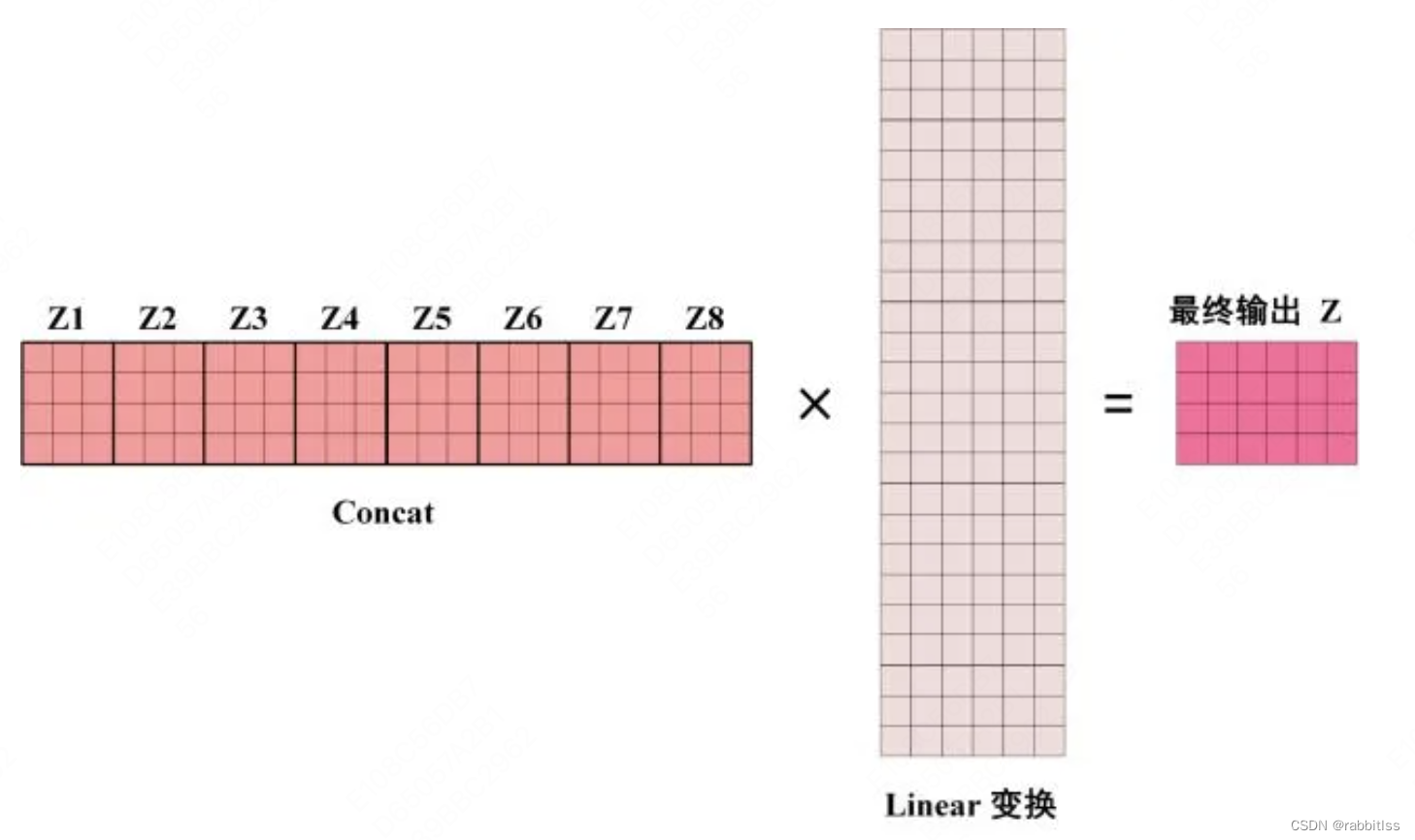
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
旋转编码RoPE机制
旋转位置编码_rotary_pos_emb,通过这种编码方式,不仅可以为Token添加绝对位置的信息,还能添加到相对位置的信息,具体公式如下:

RoPE机制通过在计算注意力权重时引入旋转编码,使模型在处理长序列时更具优势。具体来说,RoPE将位置信息编码到Query和Key向量中,通过在这些向量上应用旋转变换,使得注意力分数中包含了位置信息。这种方法使得模型能够更好地捕捉序列中的相对位置关系。具体代码在下一个task补上。
repeat-kv
在标准的多头自注意力机制中,输入的特征会被投影成 Query (Q), Key (K) 和 Value (V),然后分成多个头独立计算注意力。每个头都有自己的 Q, K 和 V,并在每个头内部进行自注意力计算。这种方法虽然有效,但计算量较大,特别是对于大规模模型和长序列数据。repeat-kv 技术主要是通过重复使用键 (K) 和值 (V) 来优化计算。在这种技术中,K 和 V 在每个分组之间是共享的,而查询 (Q) 仍然是独立计算的。这可以与卷积神经网络和全连接神经网络进行对比。
在 CNN 中,卷积层代替了全连接层,卷积层中的卷积核实现了权重共享。每次特征提取时,它们都使用相同的卷积核参数进行卷积运算,并通过反向传播来更新这些权重。同时,每个卷积层有多个卷积核,每个卷积核维护着自己的权重矩阵。这里的每个卷积核可以类比为不同分组中的 K 和 V 矩阵。通过这种方式,相较于全连接神经网络,CNN 大大减少了参数量。repeat-kv 技术在多头自注意力机制中起到了类似卷积核的作用,通过共享 K 和 V 矩阵,减少了重复计算的次数,从而优化了计算效率和参数量。
attention mask
举个例子,在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作。
下面的描述中使用了类似 Teacher Forcing 的概念,不熟悉 Teacher Forcing 的童鞋可以参考以下上一篇文章Seq2Seq 模型详解。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “” 预测出第一个单词为 “I”,然后根据输入 “ I” 预测下一个单词 “have”。

Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 ( I have a cat) 和对应输出 (I have a cat ) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 “ I have a cat ”
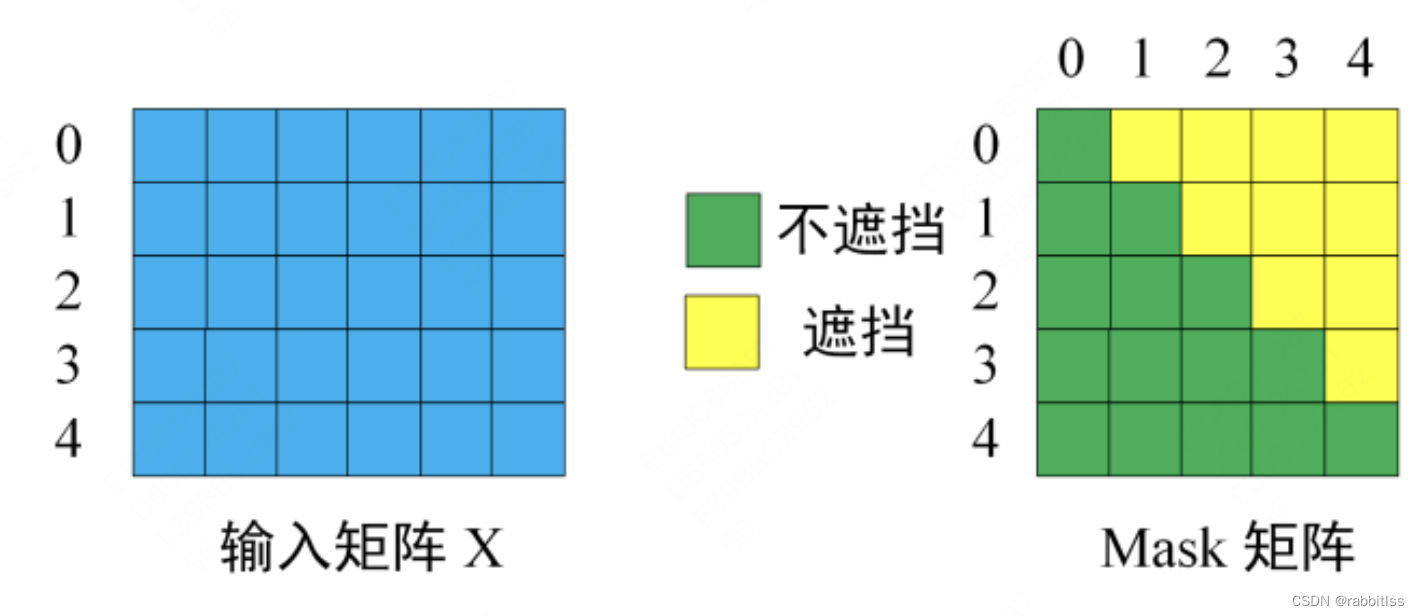
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “ I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
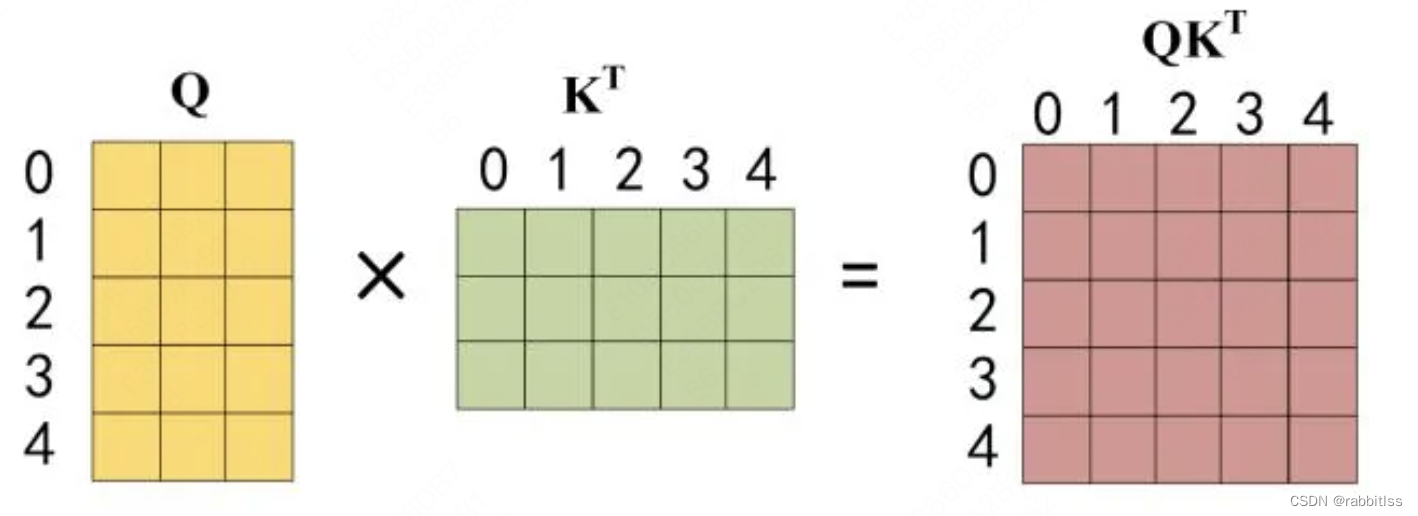
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 的乘积 。
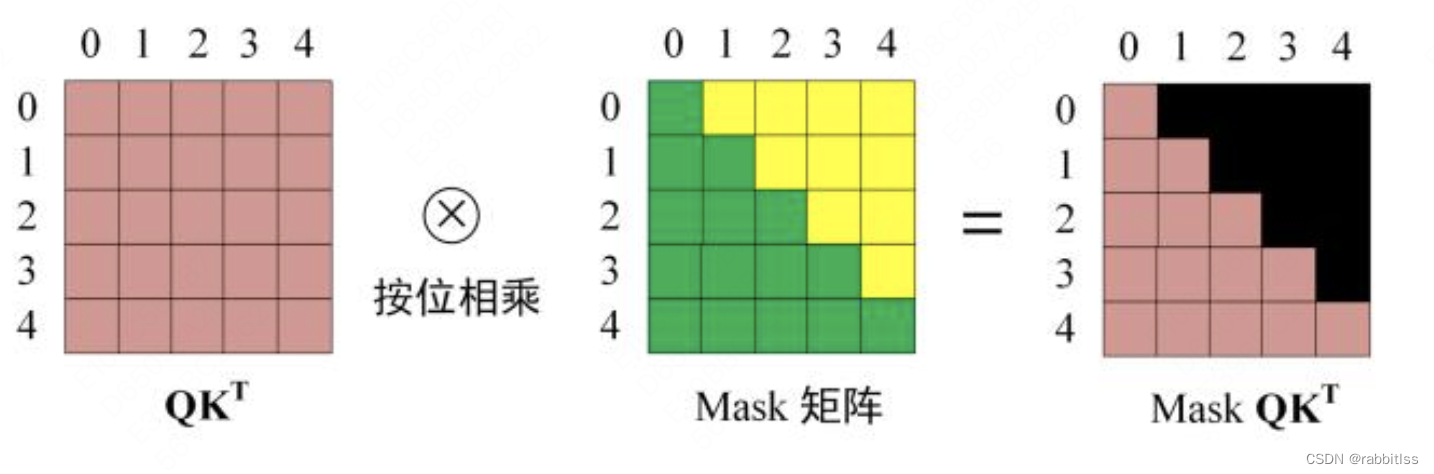
第三步:在得到
之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
得到 Mask 之后在 Mask 进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
第四步:使用 Mask 与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 是只包含单词 1 信息的。
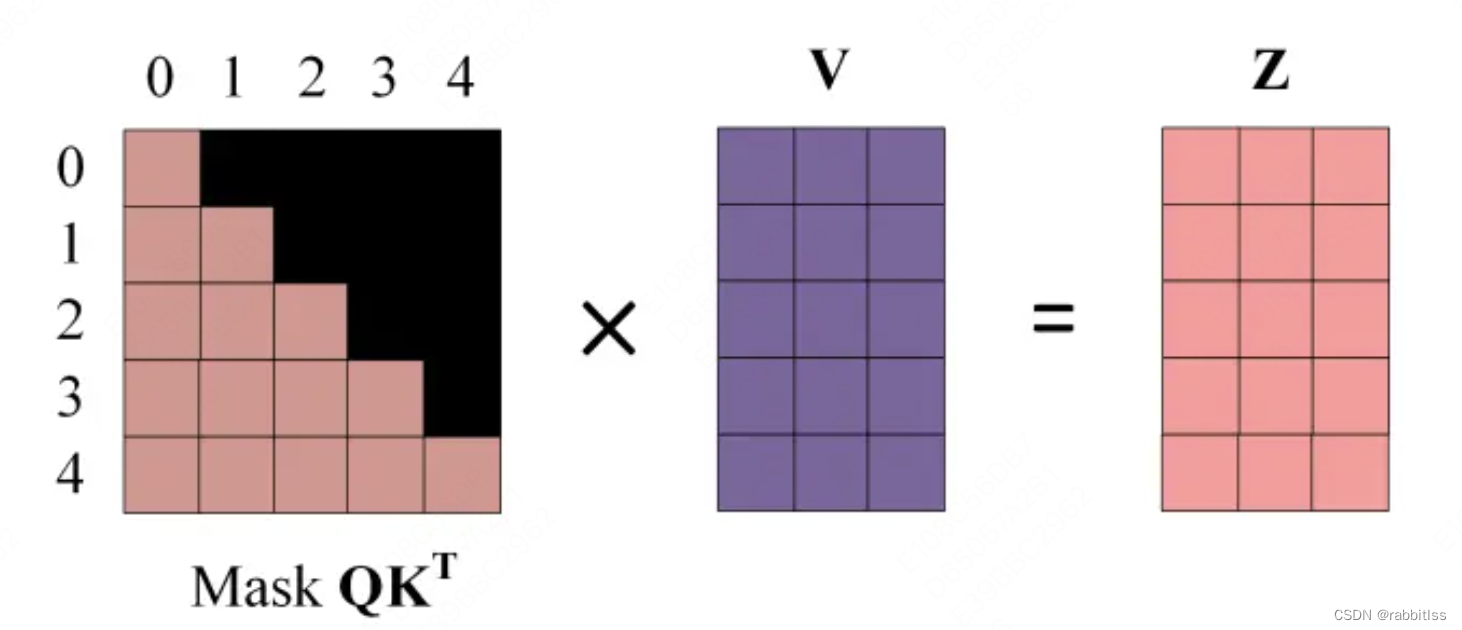
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵
,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出
然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
attention层的代码解析下一个task补上。
5、MLP
经过了Attention层后,我们来到了下一个子层,即MLP层。首先我们先看一下它的结构图:
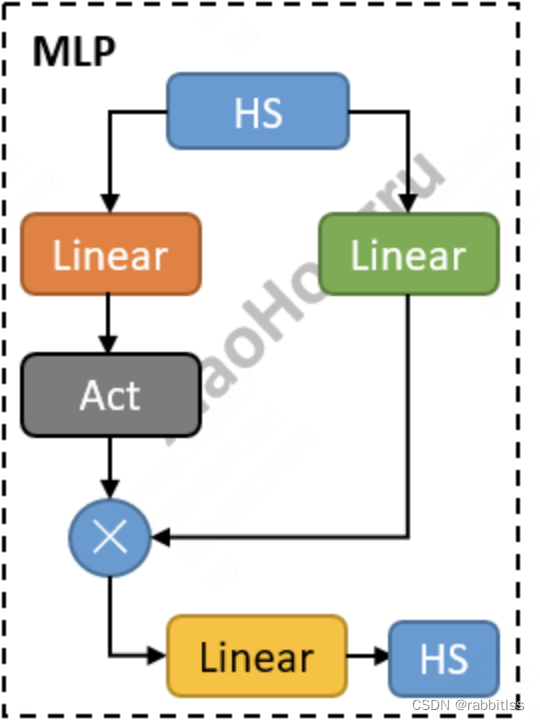
在我们transformer中的这一层被称为前馈全连接层,使用的是两层全连接神经网络。但是全连接神经网络有一个缺点,那就是只能线性拟合,对于非线性特征拟合效果不算太好。而MLP则是借助了LSTM中的门值的思想,通过添加一个激活函数,引入非线性变化。从而提高了模型对非线性数据特征抽取能力。
这里的HS经过了Linear层后,经过了一个Act层,这里的Act代指激活函数,常见的有ReLU, Sigmoid等,得到一个类似门值的矩阵(可以理解为权重矩阵), 在和另一边经过绿色部分的linear拟合的数据做乘积,从而引入了非线性能力。后面再经过一个线性层对特征进行抽取,最后输出。
6、RMSNorm
RMSNorm的公式为:

其中x是层的输入的hidden_state, w(i)表示的是hidden_state的最后一个维度的值,n 表示上面输入的最后一个维度的数量, 最后一个参数表示是很小的数,防止除0。
RMSNorm通过计算输入向量每个元素的平方和的均值,再取平方根,进行归一化。这种方式不改变输入的均值,而是基于输入向量的范数来进行标准化。
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片: ![]()
居中的图片: 
居中并且带尺寸的图片: ![]()
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6005
6005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









