




前言
这是第10个任务,本次任务主要是一下几个方面:
- Transformer的原理
- BERT的原理
- 利用预训练的BERT模型将句子转换为句向量,进行文本分类
本文主要接受Transformer 原理,2017年,Google发表论文《Attention is All You Need》,提出经典网络结构Transformer,全部采用Attention结构的方式,代替了传统的Encoder-Decoder框架必须结合CNN或RNN的固有模式。并在两项机器翻译任务中取得了显著效果。该论文一经发出,便引起了业界的广泛关注,同时,Google于2018年发布的划时代模型BERT也是在Transformer架构上发展而来。
Transformer原理
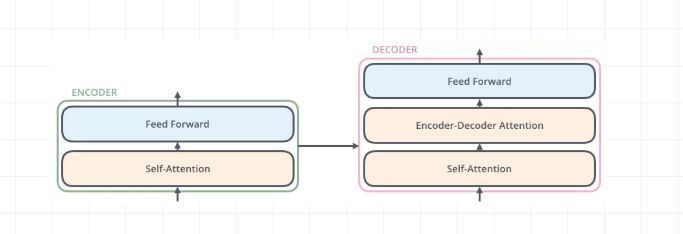
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。通俗结构图如下所示:
![]()
将上述图浓缩一下就是如下图,其中灰色长方形框框就是 Encoder和Decoder都如下所示:
再通俗一点的图,可能你在其他博客里看到的图,如下所示:
Position Embedding(位置向量)
在本文中,Embedding操作不是普通的Embedding而是加入了位置信息的Embedding,我们称之为Position Embedding。因为在本文的模型中,已经没有了循环神经网络这样的结构,因此序列信息已经无法捕捉。但是序列信息非常重要,代表着全局的结构,因此必须将序列的分词相对或者绝对position信息利用起来,每个时刻的输入是Word Embedding+Position Embedding。位置信息的计算公式如下:
P E p o s , 2 i = s i n ( p o s 1000 0 2 i d m o d e l ) PE_{pos,2i}=sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \\ PEpos,2i=sin(10000dmodel2ipos)
P E p o s , 2 i + 1 = c o s ( p o s 1000 0 2 i d m o d e l ) PE_{pos,2i+1}=cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) PEpos,2i+1=cos(10000dmodel2ipos)
其中:
- pos代表的是第几个词,单词的位置。
- i代表embedding中的第几维,表示单词的维度。
即奇数位置用余弦编码,偶数位置用正弦编码,最终得到一个512维的位置向量。位置编码是不参与训练的,而词向量是参与训练的。作者通过实验发现,位置编码参与训练与否对最终的结果并无影响。
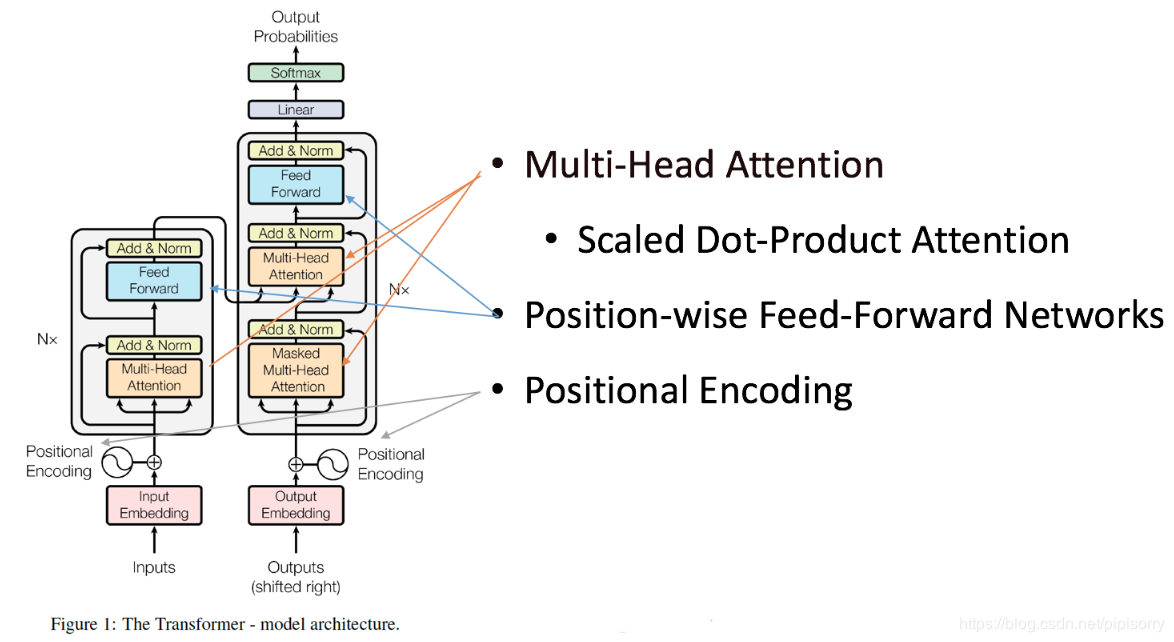
Encoder
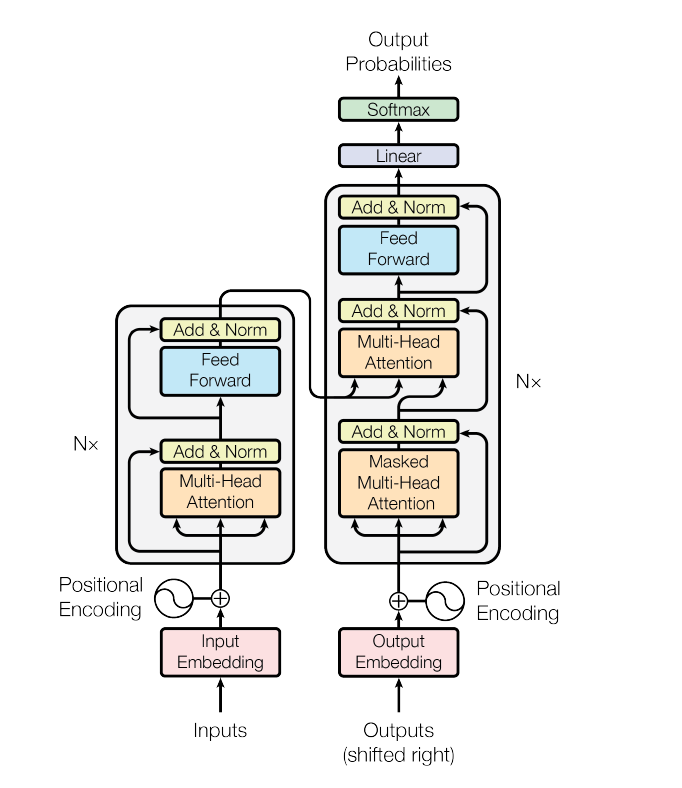
Encoder由N=6个相同的layer组成,每一个layer就是上图左侧的单元,最左边有个“N”参数,这里N=6。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism(左图中橙色部分)和fully connected feed-forward network(左图中蓝色部分)。其中每个sub-layer都加了residual connection和normalisation,因此可以将sub-layer的输出表示为:
s u b _ l a y e r _ o u t p u t = L a y e r N o r m ( x + ( S u b L a y e r ( x ) ) ) sub\_layer\_output = LayerNorm(x+(SubLayer(x))) sub_layer_output=LayerNorm(x+(SubLayer(x)))
接下来按顺序解释一下这两个sub-layer。
Multi-head self-attention
普通attention机制可由如下表示:
a t t e n t i o n _ o u t p u t = A t t e n t i o n ( Q , K , V ) attention\_output = Attention(Q,K,V) attention_output=Attention(Q,K,V)
第一部就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量 Q Q Q、一个键向量 K K K和一个值向量 V V V。这三个向量是通过词嵌入与三
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















 到【灌水乐园】发言
到【灌水乐园】发言







