







 超级会员免费看
超级会员免费看
 本文介绍了如何使用Google Colab免费GPU资源进行YOLO V8模型的自定义数据集训练。首先,文章阐述了Colab的特点和访问方法,然后详细讲解了如何在Colab中创建新笔记本、设置GPU环境、准备Google Drive资源文件。接着,作者展示了训练代码的编写过程,包括安装ultralytics库、获取当前路径和编写训练脚本。最后,提到了防止Colab因超时中断的解决方案。
本文介绍了如何使用Google Colab免费GPU资源进行YOLO V8模型的自定义数据集训练。首先,文章阐述了Colab的特点和访问方法,然后详细讲解了如何在Colab中创建新笔记本、设置GPU环境、准备Google Drive资源文件。接着,作者展示了训练代码的编写过程,包括安装ultralytics库、获取当前路径和编写训练脚本。最后,提到了防止Colab因超时中断的解决方案。
笔者在前面几篇文章中详细介绍了用于YOLO模型训练所需要的资源准备、标签标注等工作。现在笔者就来向大家介绍依托yoloV8使用相关的标签素材做训练的具体方法和步骤。
为了开展训练,我们需要使用GPU资源,在python环境中提前安装好英伟达显卡对应版本的CUDA和用于开展模型训练的torch,这样才能调用GPU资源。
总体而言,CUDA的torch的安装是比较复杂的,需要充分结合现有的硬件条件做适配,本文笔者不做详细介绍,将在后续详细展开来讲。本文笔者向大家推荐一款免费的GPU资源,非常便于我们做模型训练,而且环境搭建非常便捷,那就是Google公司推出的Colab工具。
1、Colab介绍
Colab 是一个由 Google Research 团队开发的在线平台,可以让你在浏览器中编写和运行 Python 代码,无需任何配置,免费使用 GPU 和 TPU,还可以方便地与其他人共享你的工作。Google Colab 适合进行机器学习、数据分析和教育等目的。其主要特点有:
• 零配置:你只需要一个 Google 账号和一个浏览器,就可以开始使用 Google Colab,无需安装任何软件或硬件。
• 免费的计算资源:你可以使用 Google 的云端服务器,包括 GPU 和 TPU,来运行你的代码,加速你的机器学习项目。
• 互动式编程:你可以在 Google Colab 中创建和编辑 Jupyter 笔记本,使用 Python 语言和丰富的库来实现你的想法,还可以添加文本、图片、视频等多媒体元素来丰富你的内容。
• 协作和共享:你可以与其他人实时地编辑和评论同一个笔记本,还可以通过链接或电子邮件来分享你的笔记本,让更多人看到你的成果。
2、Colab访问
正常来说,我们是无法访问Colab的。笔者在这里向大家介绍通过远程桌面功能访问服务器,从而实现对Colab的调用。
以腾讯云为例,登陆腾讯云后,在控制台中,选择轻量应用服务器。如下图所示:
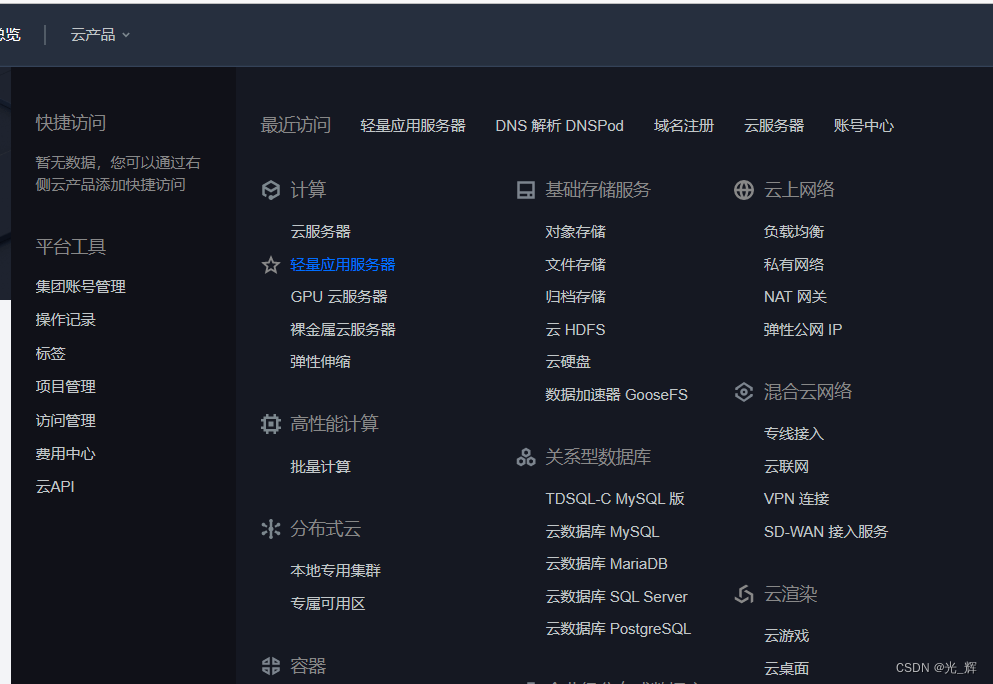
之后点击页面的新建,便可得到如下所示的页面,读者可以参照笔者的选择来设置,如下图所示。
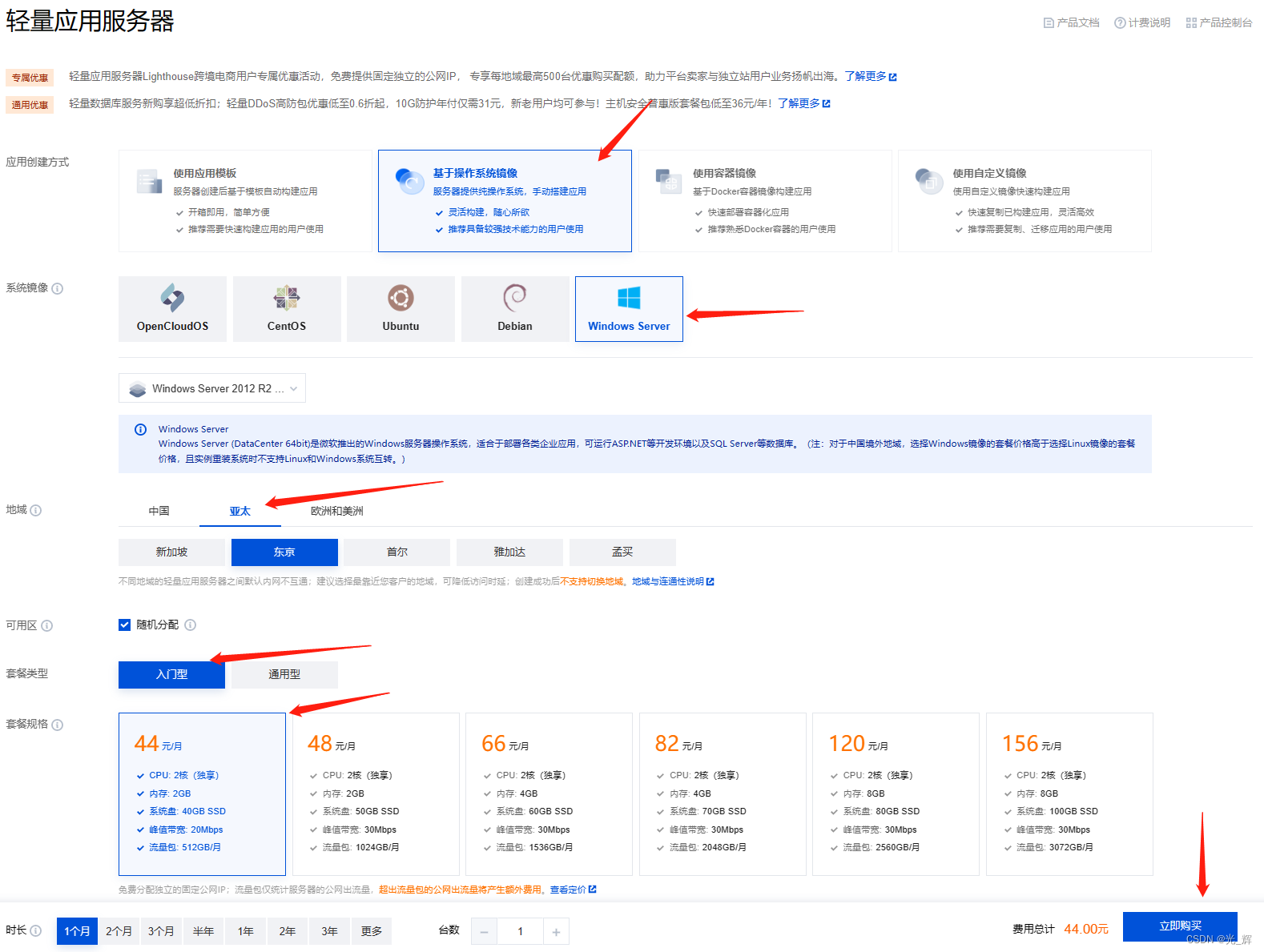
如上面的图中所示,笔者在腾讯云中申请建立了一台位于日本东京的windows server服务器,价格为44元/月,配置为CPU2核,2GB内存、40GB SSD硬盘、峰值带宽20Mbps、流量为512GB/月。总体而言,这个配置的服务器完全满足我们开展各类研究分析工作的日常需求了,我们选择在境外的虚拟服务器,主要是可以依托他做为跳板机部署python环境,一方面可以更快的访问下载各类python的第三方依赖包,快速满足开发所需,另一方面也可直接访问github等国际知名的代码仓库,及时查看当前主流的开源代码,再者也可直接访问GoogleColab等免费资源工具。
待腾讯云的虚拟服务器开通后,我们便可通过windows电脑自带的远程桌面工具连接远程服务器,登录后就和操作自己本地电脑一样,通过浏览器访问https://colab.google/来访问Colab了,如下图所示。
3、新建Colab笔记本
注册、登陆Colab后,点击右上角的“New Notebook"后,便可得到下图所示的页面。我们可以看到这个页面和在Python开发中常用的Jupyter Notebook是基本一样的,事实上使用方法也是一样的。其中左侧为环境资源列表,可以点击左数第三个按键加载自己的Google Drive文件。如果我们将标注的素材放在Google Drive中,便可直接调用。如何在GoogleDrive中存放训练所需的文件,笔者将进一步做说明。
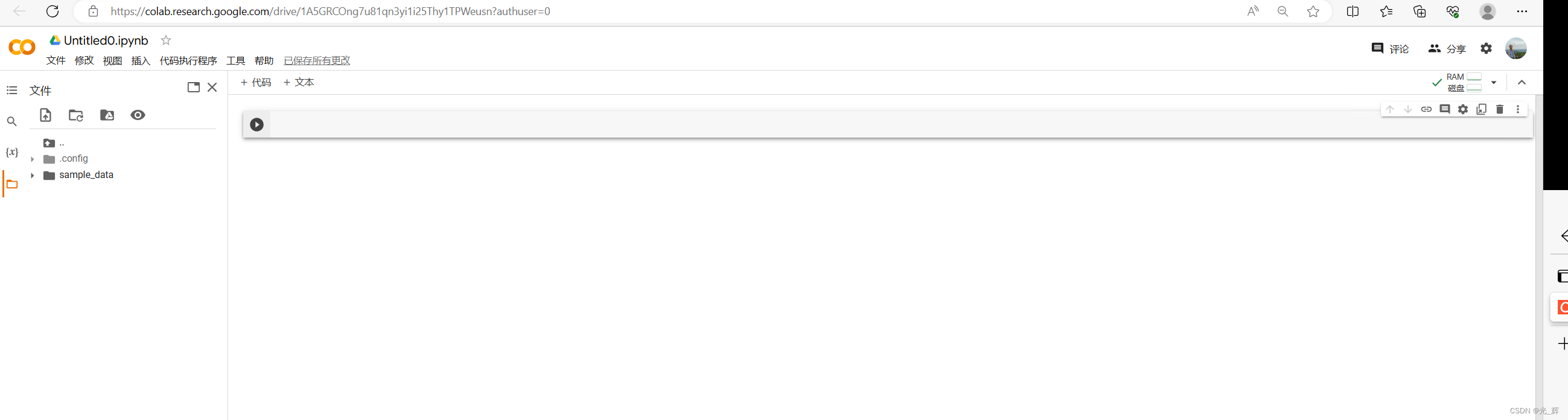
为了实现对前期人工标注的图片进行训练,笔者将以Colab工具为示例,一步步操作并编写代码,指导您完成自己的图像目标识别算法训练工作。
为了实现对图片的训练,我们需要将环境切换为GPU的资源。点击左上角的“修改”-“笔记本设置”,可以得到如下图所示的界面。选择T4 GPU即可。
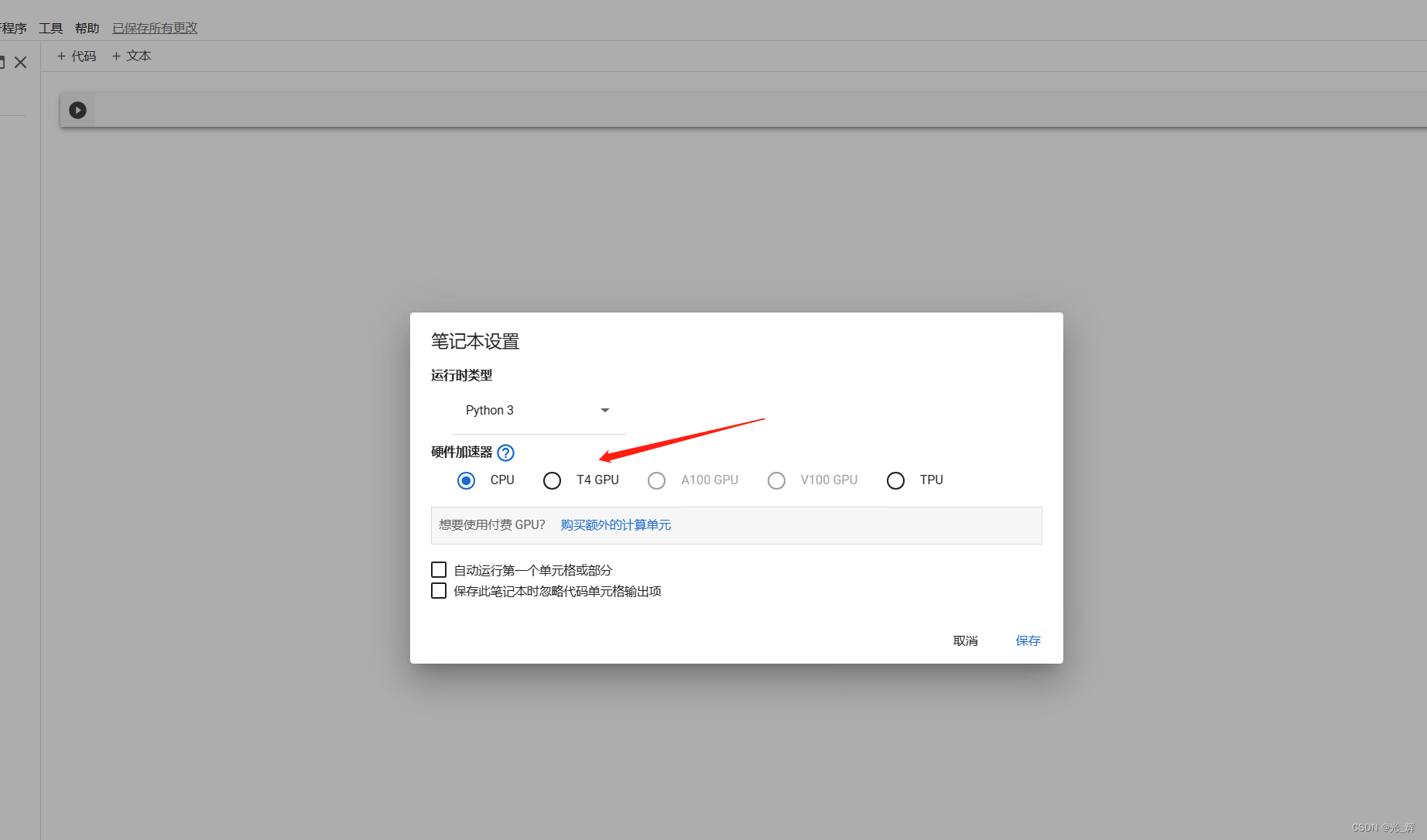
选择完成后,等待右上角提示的“正在分配”,等待期显示已经连接,便可证明我们在Colab中已经完成了GPU资源环境的搭建。
4、Google Drive资源文件准备
为了高效调用Colab,我们需要将所需训练的图片上传到Google Drive中,便于快速实现Colab搭建的GPU环境访问所需的文件资源,从而执行训练代码。
对于YOLO V8而言,为了开展训练,读者可以参照笔者的经验做法来存放所需的文件。需要特别说明的是,文件的存放模式,在用本地设备做训练的时候也是一样的,只是存放介质不同而已,其格式和内容均需按照下文所描述的开展。
将您需要做训练的文件上传到Google Drive的指定文件目录中,其中,图片、标签文档的存放格式和要求如下图所示。
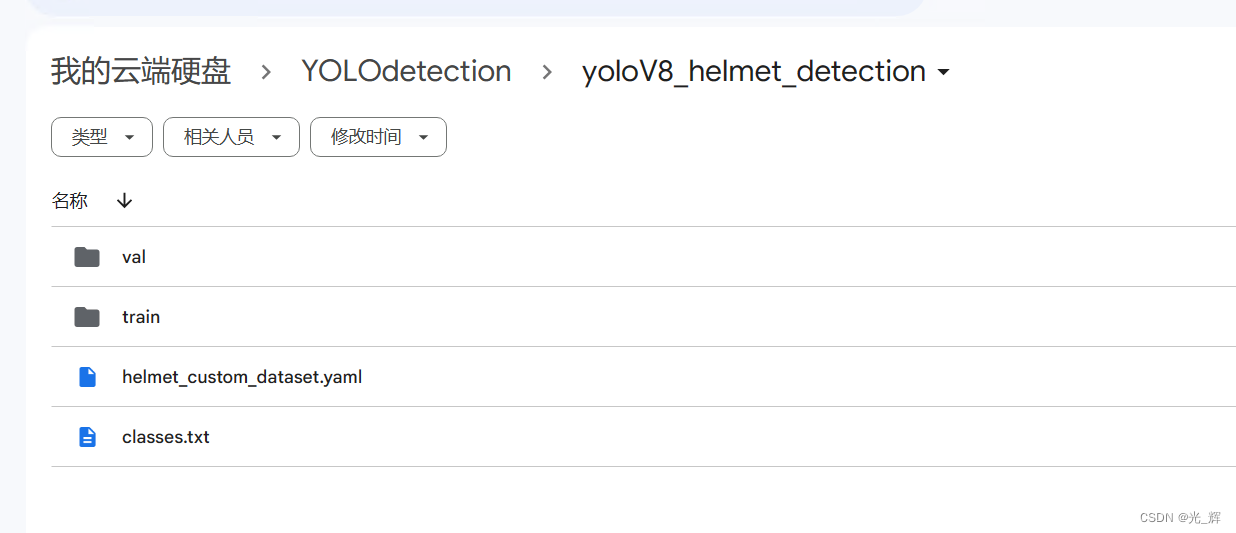
在根目录下包含的文件何文件夹包括:
(1)“val”文件夹
用于存放验证所需的图片和标签。该文件夹中包含“labels”“images”两个文件夹,其中“images”文件夹存放用于验证时所需要使用的图片,“labels”文件夹存放“images”文件夹中图片所对应的txt格式标签文件。其中用于验证的图片占总图片数量的比例可灵活调整,一般为20%。
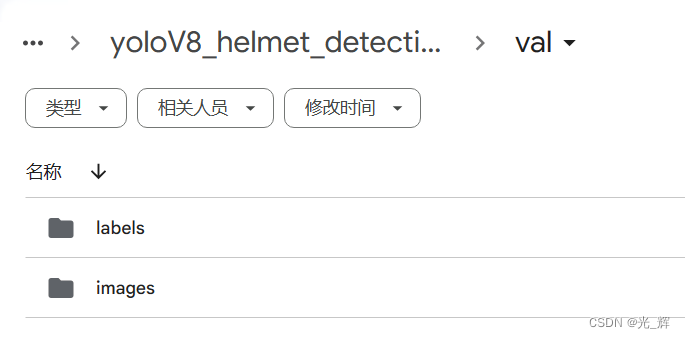
(2)“train”文件夹
用于存放训练所需图片和标签。该文件夹也包含“labels”“images”两个文件夹,其中“images”文件夹存放用于验证时所需要使用的图片,“labels”文件夹存放“images”文件夹中图片所对应的txt格式标签文件。如下图所示:

(3)yaml文件
helmet_custom_dataset.yaml 这个文件是用来配置自定义数据集的参数的,例如数据集的路径、类别数、类别名等。简单来说,我们需要在这个文件中指定以下内容:
• train: 你的训练集图片的路径,可以是一个文件夹、一个文本文件或一个列表
• val: 你的验证集图片的路径,同上
• nc: 你的数据集中的类别数
• names: 你的数据集中的类别名,用列表表示
如下图所示:
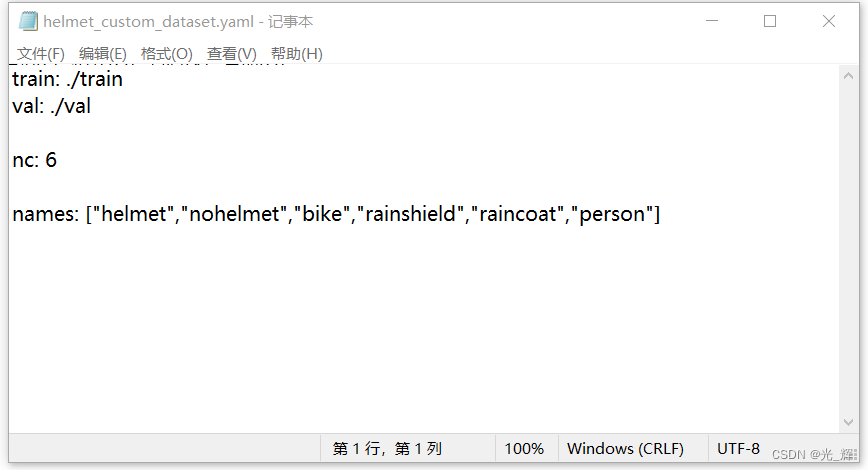
在上面这个图片示例中,train的路径为根目录下的“train”文件夹,val的路径为根目录下的“val”文件夹,nc数据集类型个数为6个,这6个类型数据的names分别为"helmet",“nohelmet”,“bike”,“rainshield”,“raincoat”,“person”,也就是我们在打标签的时候标注的六类标签,顺序从左至右开始,和前期做标签标注时的顺序一致,这6类标签用列表的形式写入yaml文档。
(4)classes文档
这个文档中按顺序记录了我们在标注时的标签名称,也就是通过这个文件告诉YOLO V8在训练时要训练识别哪些类型。classes.txt文档的内容应于前期做标注时的predefined_classes.txt内容一致。
5、训练代码编写
当我们将标签文件准备好后,便可开展模型的训练工作了。第一步就是通过左侧加载Google Drive文件资源。之后便可以逐行在Colab中编写脚本代码了。
(1)安装ultralytics库
需要输入以下命令来再Colab的虚拟环境中安装YOLO V8的ultralytics库。
!pip install ultralytics
也可以指定具体版本:
!pip install ultralytics==8.0.124
建议您在具体项目上,可以指定版本,因为当你的本地电脑ultralytics版本与Colab安装的ultralytics版本不一致的时候,训练生成的pt格式模型文件是不能使用的。
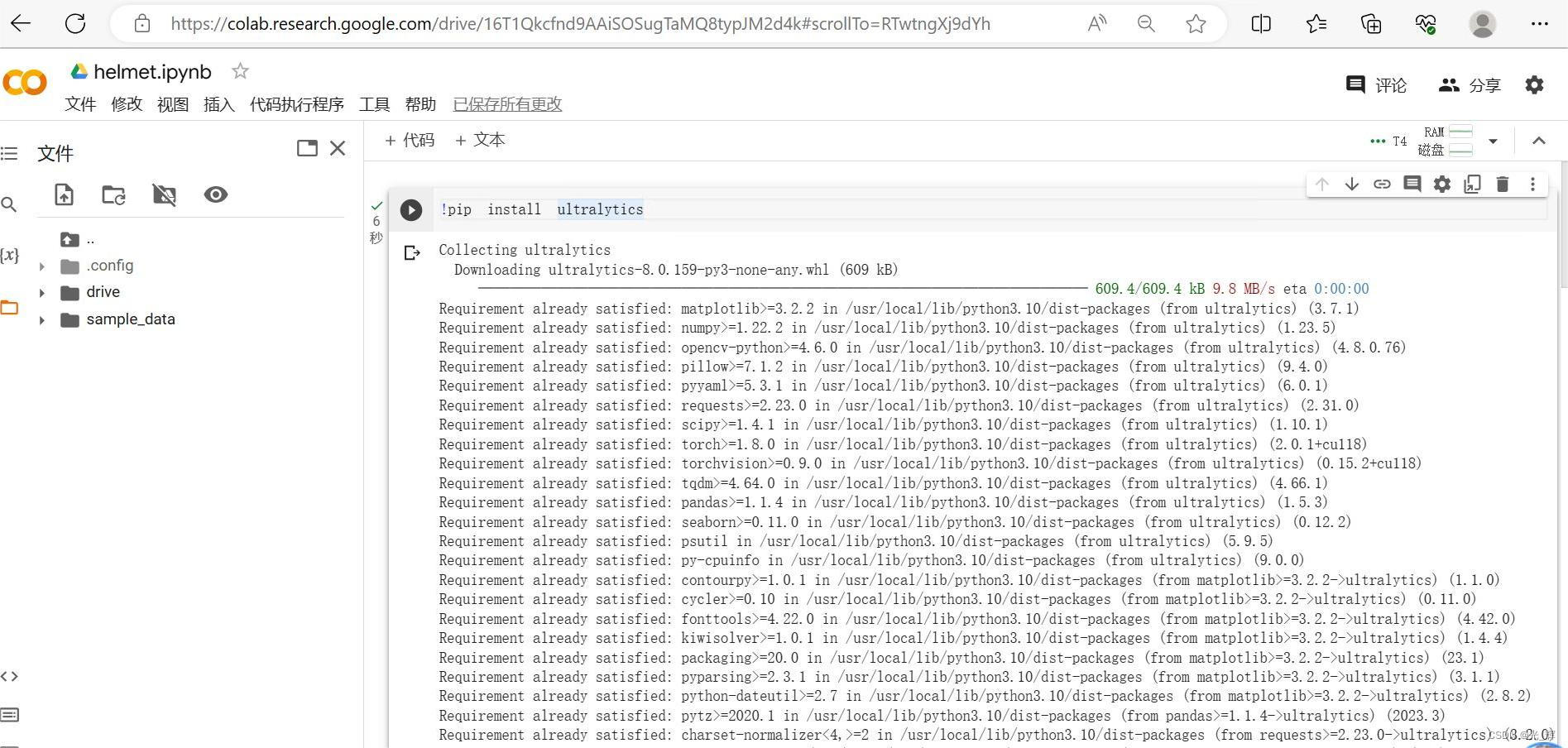
正常来说,在建立这个笔记本的时候,已经设置了GPU,对应的在安装ultralytics库的时候也会对应的安装相应版本的torch的GPU版本。在此,我们可以通过以下命令验证,
查看英伟达显卡的版本信息: 可输入以下命令
!nvcc -V
当然,我们在colab中需要输入“!”,这是colab的语法要求。当我们在本地电池查看英伟达显卡版本等信息时,只需要打开cmd终端,直接输入nvcc -V就可以了。换句话讲,我们可以理解为在colab环境中,如果需要其在terminal中运行的命令,便在前面增加“!”即可。
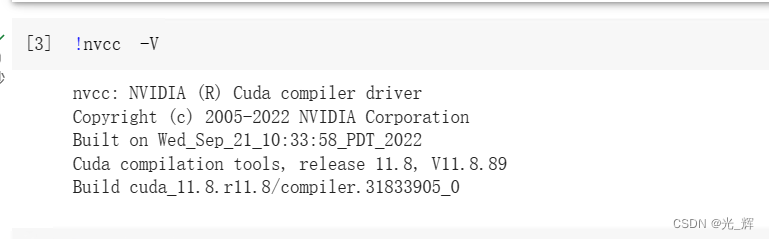
查看显卡的CUDA版本、显卡型号等信息:可以输入以下命令。
!nvidia-smi
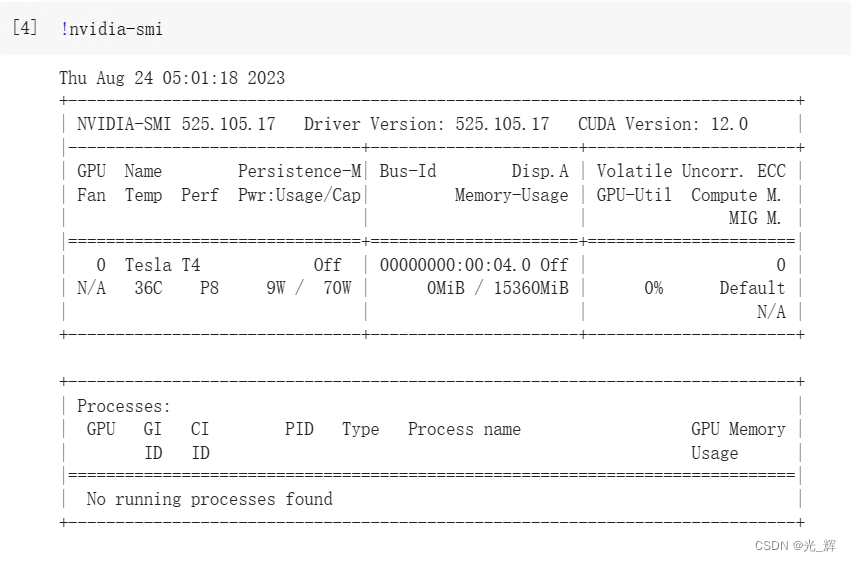
查看torch的版本。可以输入以下代码。
import torch
torch.__version__
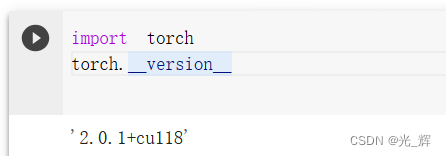
可以看到,这里我们在安装ultralytics库的时候,已经自动为我们安装了torch的支持CUDA的GPU版本。
查看torch调用GPU资源是否正常,可以输入以下代码。
import torch
torch.cuda.is_available()
torch.cuda.get_device_name(0)

(2)获取当前路径
可以通过输入以下命令,来获取当前路径,从而支撑下步相关文件资源的调取。
import os
HOME = os.getcwd()
print(HOME)
输入以上代码并执行后,将得到/content的输出,也就是说我们代码脚本的根目录是content文件夹。
(3)编写训练脚本
训练脚本的示例如下,您可以直接参考本示例开展项目训练。
from ultralytics import YOLO
# Load a model
# model = YOLO('yolov8s.yaml') # build a new model from YAML
# model = YOLO('yolov8s.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8s.yaml').load('yolov8s.pt') # build from YAML and transfer weights
# Train the model
model.train(data='/content/drive/MyDrive/YOLOdetection/yoloV8_helmet_detection/helmet_custom_dataset.yaml', epochs=100, imgsz=640)
#将结果存到云端存储上
import shutil
shutil.copytree('/content/runs/detect', '/content/drive/MyDrive/Colab Notebooks/yolov8')
如下图所示:
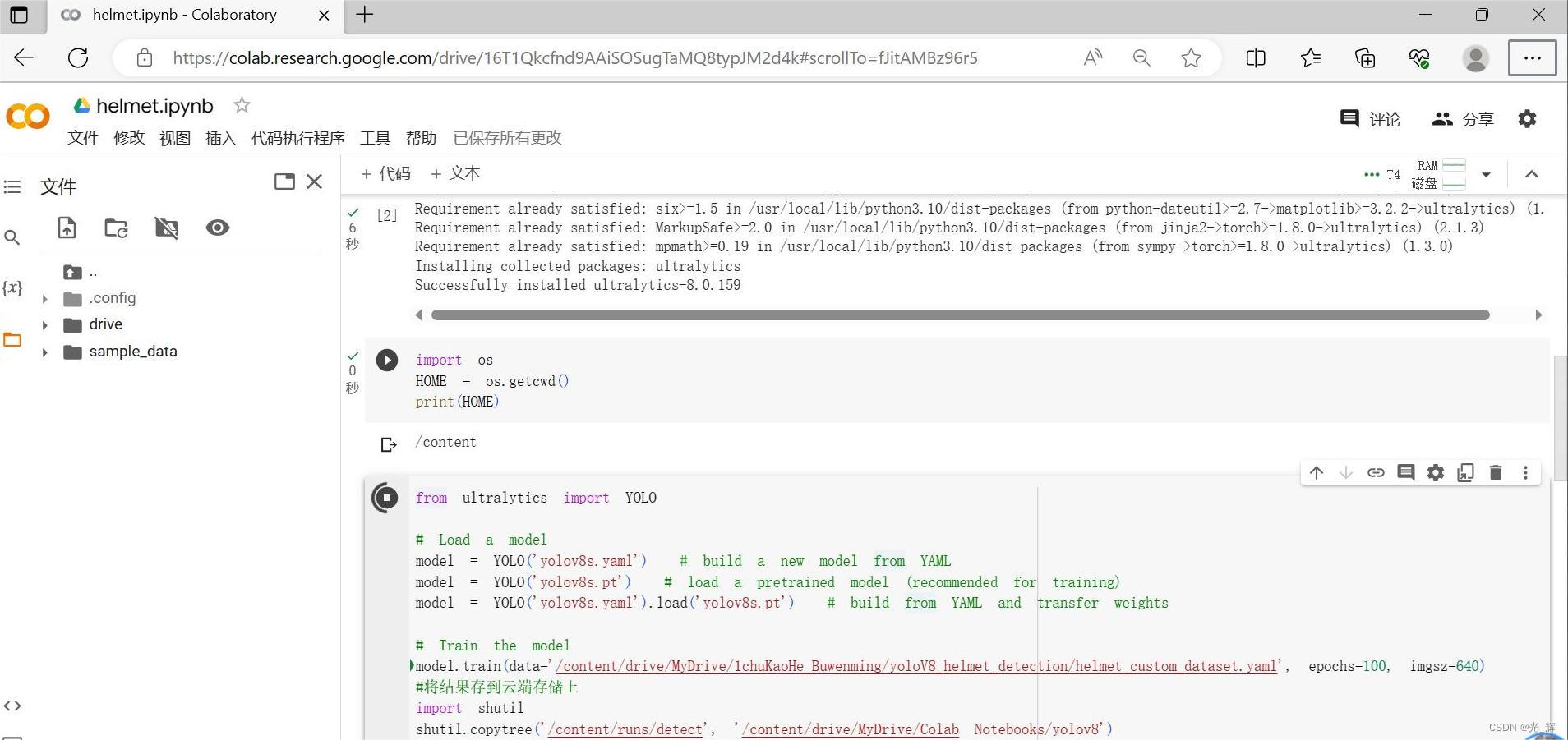
上面这段代码的意思是:
• 从 ultralytics 包中导入 YOLO 类,这是一个用于实现 YOLOv8 算法的类,可以用来构建、加载和训练目标检测模型
• 加载一个模型,有三种方式:
• model = YOLO(‘yolov8s.yaml’):这个命令是根据 yolov8s.yaml 文件中的配置,创建一个新的模型,这个模型没有经过任何训练,所以不能用于预测或评估,只能用于训练自己的数据集。
• model = YOLO(‘yolov8s.pt’):这个命令是直接加载一个预训练好的模型,这个模型已经在 COCO 数据集上训练过了,所以可以用于预测或评估任何图片或视频,也可以用于在自己的数据集上进行微调训练。
• model = YOLO(‘yolov8s.yaml’).load(‘yolov8s.pt’):这个命令是先根据 yolov8s.yaml 文件中的配置,创建一个新的模型,然后将 yolov8s.pt 文件中的权重转移过来,这样相当于用预训练好的权重初始化了新的模型,这个模型也可以用于预测或评估任何图片或视频,也可以用于在自己的数据集上进行微调训练。
这三个命令不能同时使用,只能选择其中一个。如果你想要创建一个新的模型,并用预训练好的权重初始化它,你可以使用第三个命令。如果你想要直接使用预训练好的模型,你可以使用第二个命令。如果你想要从零开始训练一个新的模型,你可以使用第一个命令。
• 训练模型,使用 train 方法,传入以下参数:
• data:指定自定义数据集的配置文件的路径,这里是 ‘/content/drive/MyDrive/YOLOdetection/yoloV8_helmet_detection/helmet_custom_dataset.yaml’,这个文件中包含了数据集的路径、类别数、类别名等信息
• epochs:指定训练的轮数,这里是 100
• imgsz:指定输入图片的大小,这里是 640
• 将结果存到云端存储上,使用 shutil 包中的 copytree 方法,将 ‘/content/runs/detect’ 文件夹下的所有内容复制到 ‘/content/drive/MyDrive/Colab Notebooks/yolov8’ 文件夹下,这样就可以在 Google Drive 中查看训练结果了。
之所以要及时将结果拷贝到云端存储,主要是因为Colab在空闲状态下会自动腾退资源。当我们在做训练的时候,虽然已经调用了GPU资源,但速度依然是很慢的,为此,我们很难在电脑前一直等待,为了避免训练结束后我们不在现场及时下载,导致资源被回收从而白白训练模型文件的尴尬处境,笔者建议在计算结束后,将生成的run文件夹及时复制到云端存储。
(4)CLI命令行实现
上文中介绍了使用python脚本代码实现使用YOLO v8对自定义数据集的训练,当然,如果您对YOLO v8有了解的话,我们知道在官网的介绍中很多都是通过CLI命令行的形式实现的,为此笔者也给大家举示例演示说明。
在CLI命令行实现的过程中,我们可以使用以下代码实现。
!yolo task=detect mode=train model=yolov8s.pt data=./drive/yovoV8Mask/mask_custom_dataset.yaml epochs=25 imgsz=640 plots=True
当然,这里只是一个笔者前期制作口罩检测识别时候的一个示例,与本文所提到的在公安交管领域的模型训练无关,只是示例说明其训练的CLI语句。

执行上面的命令,我们也可实现训练的工作,其运行情况与代码实现没有区别。
6、Colab防中断
在项目训练中,由于程序运行的时间往往比较长,这就造成我们没有办法一种定在电脑跟前。对于Colab而言,如果页面长时间没有交互,就会自动释放资源,这就造成即便我们的程序可能才跑到一半就被中断了。一般而言,如果colab和用户没有任何交互的情况下,那么30分钟就会自动断开。为了解决这个问题,笔者多长查询,推荐读者采用以下办法。
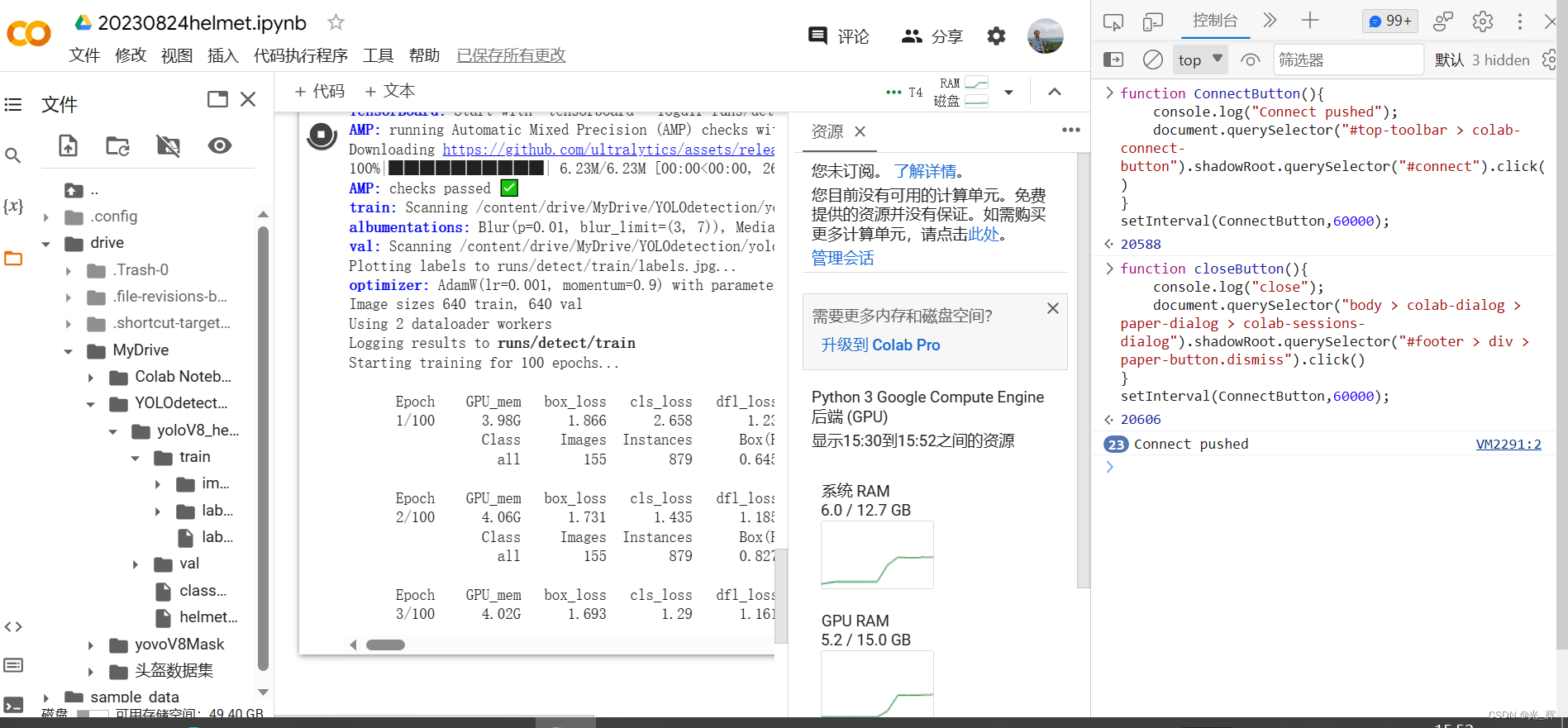
在浏览器的Colab页面调出开发者模式,选择控制台,右键清空控制台,或者按tap件,再下方输入指令代码:
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
第一行代码是定义一个名为ConnectButton的函数,这个函数的作用是模拟点击Colab页面上的连接按钮,从而保持Colab的运行状态。这个函数首先打印出一个“Connect pushed”的信息,然后使用document.querySelector方法来选择页面上的连接按钮元素,并调用它的click方法。
• 第二行代码是使用setInterval方法来定时执行ConnectButton函数,每隔60000毫秒(即60秒)就执行一次。这样就可以每分钟自动点击一次连接按钮,防止Colab因为超时而断开连接。
之后可以过一会再输入以下代码
function closeButton(){
console.log("close");
document.querySelector("body > colab-dialog > paper-dialog > colab-sessions-dialog").shadowRoot.querySelector("#footer > div > paper-button.dismiss").click()
}
setInterval(ConnectButton,60000);
• 第一行代码是定义一个名为closeButton的函数,这个函数的作用是模拟点击Colab页面上的关闭按钮,从而关闭Colab的对话框。这个函数首先打印出一个“close”的信息,然后使用document.querySelector方法来选择页面上的关闭按钮元素,并调用它的click方法。
• 第二行代码是使用setInterval方法来定时执行closeButton函数,每隔60000毫秒(即60秒)就执行一次。这样就可以每分钟自动点击一次关闭按钮,防止Colab弹出不必要的对话框。
输入这两行代码后再直行程序,如下图所示

















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









